·聚焦:人工智能、芯片等行业
欢迎各位客官关注、转发

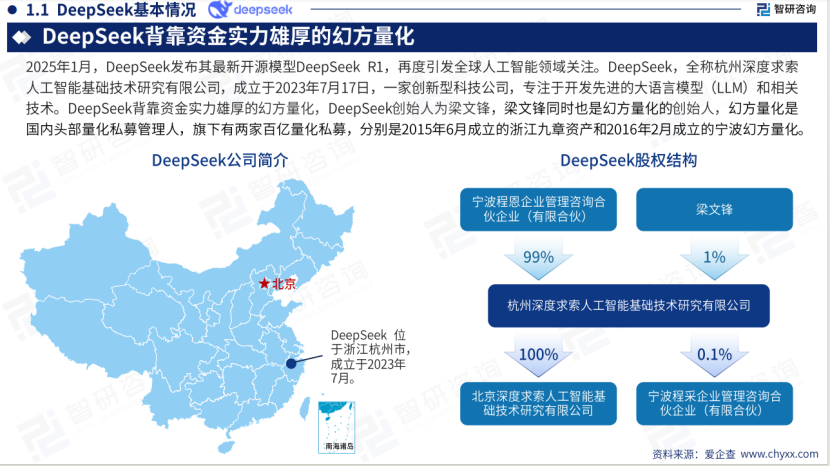
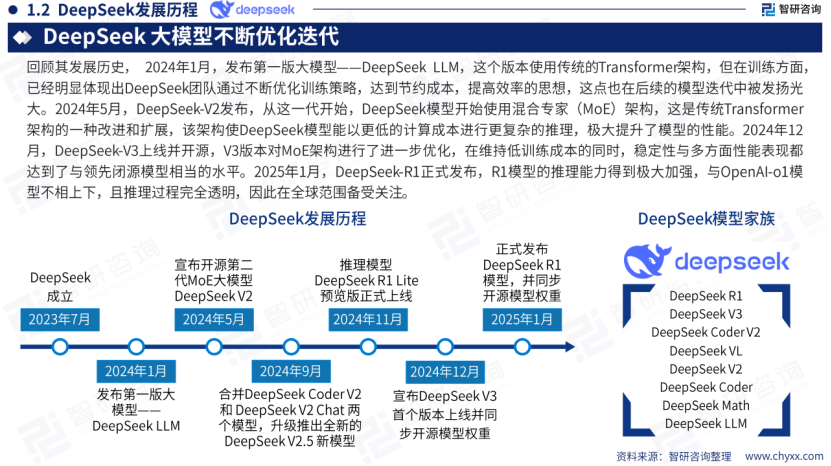
回顾其发展历史,2024年1月,发布第一版大模型—-DeepSeek LLM,这个版本使用传统的Transformer架构,但在训练方面,已经明显体现出DeepSeek团队通过不断优化训练策略,达到节约成本,提高效率的思想,这点也在后续的模型迭代中被发扬光大。
2024年5月,DeepSeek-V2发布,从这一代开始,DeepSeek模型开始使用混合专家(MoE)架构,这是传统Transformer架构的一种改进和扩展,该架构使DeepSeek模型能以更低的计算成本进行更复杂的推理,极大提升了模型的性能。
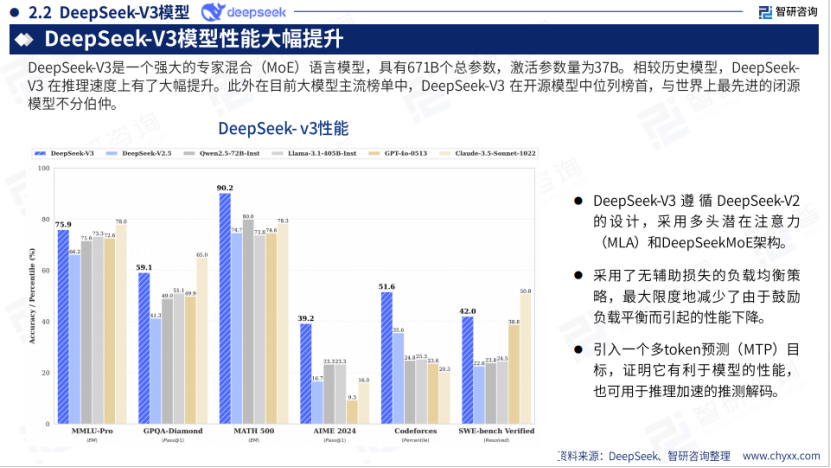
2024年12月,DeepSeek-V3上线并开源,V3版本对MoE架构进行了进一步优化,在维持低训练成本的同时,稳定性与多方面性能表现都达到了与领先闭源模型相当的水平。
2025年1月,DeepSeek-R1正式发布,R1模型的推理能力得到极大加强,与OpenAl-o1模型不相上下,且推理过程完全透明,因此在全球范围备受关注。
从低成本的DeepSeekV2,到超低价格的DeepSeek-V3,再到引起世界广泛关注的DeepSeek-R1,DeepSeek的成功主要依赖于DeepSeek自身深厚的技术积累和持续的技术创新突破。
DeepSeek通过创新的训练方法,如在预训练阶段加入强化学习,用较少的计算资源就达到了接近 GPT-01的性能,这使业界开始反思大算力在AI发展尤其是大模型训练过程中的必要性,部分企业预计会减少对大规模算力基础设施的激进投入。
短期内可能会局部缓解算力压力,但长期来看,随着AI能力的边界扩展(如多模态、复杂推理、通用人工智能)以及应用场景的爆发式扩展,算力需求仍将增长。
另一方面,也为国产显卡和ASIC芯片带来了机会。因为DeepSeek的RL策略对并行计算需求下降40%,这使得国产算力硬件有机会凭借成本和服务优势在市场中占据一席之地。
客户可以根据实际应用场景灵活进行定制化芯片开发,算力市场预计走向多元化发展。
以下是《2025年deepseek技术全景解析》报告部分内容:





公众号后台回复《2025年deepseek技术全景解析》,即可获得全文报告。

本公众号所刊发稿件及图片来源于网络,仅用于交流使用,如有侵权请联系回复,我们收到信息后会在24小时内处理。
推荐阅读:



商务合作请加微信勾搭:
18948782064
请务必注明:
「姓名 + 公司 + 合作需求」