

 本文约6,800字,建议收藏阅读
本文约6,800字,建议收藏阅读作者 | 直观解
出品 | 汽车电子与软件
MCU的网络管理是用网络报文方式实时控制不同车载MCU的状态,暂时不用的MCU可以休眠以节电。随着工作场景变化,不同的MCU或者不同的MCU组被轮番休眠或唤醒。如何用AI和优化算法来实时确定最优的网络管理方案,在保证性能和安全的前提下,最小化需要唤醒的MCU,最小化电耗,是本文的主题。
投资界的一些消息,今年为车辆行业的企业或者项目融资,如果不包括广义AI和大模型的项目,几乎鲜有投资人问津。这固然有资本逐利的原因,也确实有软件定义汽车中数不胜数的优化应用点可以应用人工智能。这些优化应用点,比如mcu的网络管理,车辆热管理,BMS的电池负载均衡,悬挂系统的实时最优悬挂方案,商用车根据路况的实时最佳AMT挡位等等(燃油重卡AMT有十几个挡位),以及自动驾驶中数不清的应用点,原来是靠人为规则、运筹优化算法或者模糊逻辑fuzzy logic来完成,都有一定局限性。最大的局限性来自人为规则或者运筹优化的解决方案池相对于大模型而言,都比较小。
现在是希望利用大模型庞大的数据提取量,在比传统方法高几个数量级或者几十个数量级的解决方案池中,找出更好的解决方案,在激烈竞争中获取优势。
这个好比在alphaGo出现后,一位围棋界人士在中央电视台新闻频道CGTN(现在叫CCTVnews)接受采访所说,“人类几千年无数天才的围棋探索,其实只是一个点,点外面还有无数空间。”
所以对于“解空间特别大的问题,也就是所有可能性特别多的问题”(解空间小的问题原有方法已经够用),现在普遍寄希望于AI大模型能够提出比以前优度更高的最优解,每提高的一点优度都是真金实银的经济效益。
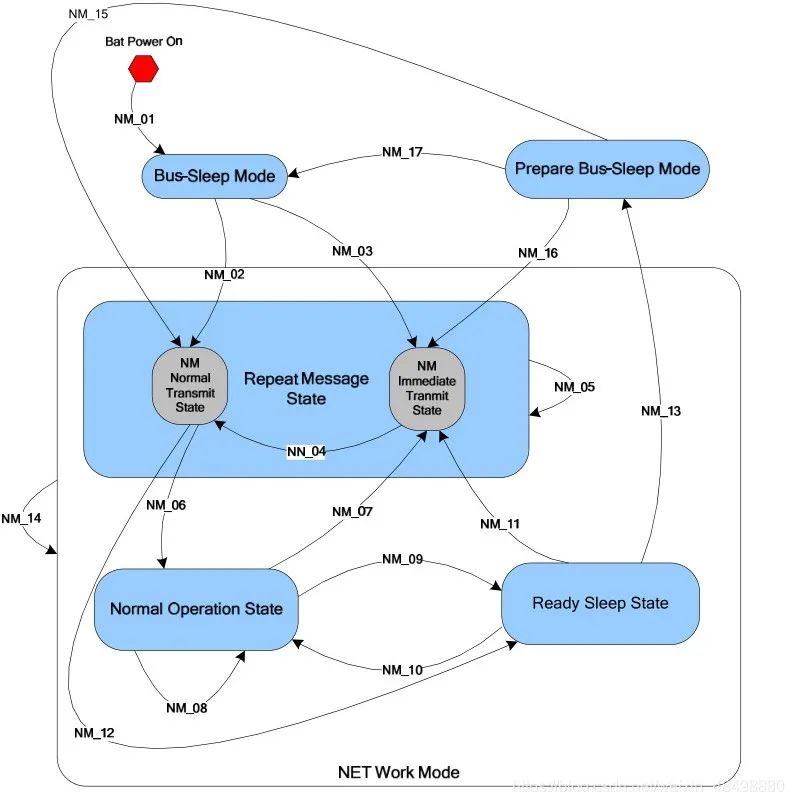
图1 网络管理状态机,图片来自网络
车辆电控MCU的网络管理,就是这样的一个问题。
#01
新能源重卡的MCU(微控制器单元)数量相较于传统燃油车有显著增加,主要由于其复杂的电气系统和智能化需求。根据相关资料,可以总结出以下信息:
1. 传统燃油车与新能源汽车对比:
a. 传统燃油车单车搭载的MCU数量平均在70个左右
b. 新能源汽车尤其是智能电动汽车对MCU的需求大幅增加,单车搭载的MCU数量可达300多个
2. 新能源重卡的具体情况:
a. 目前具体到新能源重卡的数据较少,但可以推测其MCU数量会进一步增加。例如,苇渡科技发布的首款纯电重卡采用了先进的SiC模块MCU,确保了高效能表现。
b. 结合其他类型的新能源车辆数据,考虑到重型卡车的功能复杂性和更高的安全标准,预计每辆新能源重卡可能需要超过300颗甚至更多MCU来支持其各种控制系统,如动力管理、自动驾驶辅助系统(ADAS)、电池管理系统(BMS)等。
网络管理的根本动机就是减小电耗,控制器不需要工作时休眠,需要工作时被唤醒起来。
MCU简化看可以认为只有休眠和工作两种状态,实际上细分多种状态。
状态名称 | 描述 |
正常运行状态 | ECU活跃,进行任务执行和数据传输 |
准备休眠状态 | 完成准备工作,即将进入低功耗模式 |
重复报文状态 | 发送网络管理报文以同步唤醒 |
总线休眠状态 | 网络几乎停止活动,等待唤醒信号 |
预睡眠状态 | 向休眠状态过渡的中间阶段 |
每辆新能源重卡可能需要超过300颗甚至更多MCU,我们假设就是300颗,而且进一步简化就两种状态(实际是五种),解空间=2^300,约等于具体数值大约为2.037035971×10的90次方。
实际上对于熟悉人工智能的读者,会一眼认出这个数字实际也是alphaGO论文对围棋局面总数的估计,不是2的361次方,就是2的300次方。
2^300这样庞大的解空间,虽然会因为各种mcu之间的关联关系而缩小一些,但仍然是以AI为基础的优化方案的好战场。
#02
MCU被唤醒的方式和原因是紧密联系的。
在汽车电子系统中,ECU(电子控制单元)的唤醒方式有多种,每种方式都有其特定的应用场景和特点。笔者在这里讨论了硬线唤醒、本地唤醒、RTC唤醒、网络唤醒以及网络管理在autosar中体现的模块NM。需要说明的,网络管理是一个通用的功能,即使不使用autosar的NM模块,也可以实现网络管理。
硬线唤醒是指通过物理连接的电线信号来唤醒ECU。这种唤醒方式通常与车辆的电源状态相关联,例如KL15硬线信号。当KL15信号从低电平变为高电平时,表示点火开关打开,相应的ECU会被唤醒。
应用场景:硬线唤醒常用于需要即时响应的情况,如点火开关打开时唤醒相关控制器。
优点:简单可靠,不需要复杂的通信协议。
缺点:只能在物理连接的情况下工作,灵活性较差。
本地唤醒是指ECU通过内部或外部传感器信号被唤醒。这些信号可以是硬线信号(如KL15硬线)、硬件传感器(如车门打开、脚踢门等)。当这些触发信号被检测到时,控制器会从休眠状态进入工作状态。
应用场景:适用于需要根据车辆内部或外部环境变化进行操作的场景,如车门打开时唤醒门控模块。
优点:响应速度快,能够迅速处理本地事件。
缺点:依赖于具体的硬件配置,灵活性有限。
RTC(实时时钟)唤醒是指通过配置RTC定时器,在设定的时间点自动唤醒相关控制器。RTC唤醒常用于需要定时执行任务的场景,如电池管理系统(BMS)定期检查电池状态。
应用场景:适用于需要定时执行任务的场景,如定期健康检查、数据上传等。
优点:精确度高,可以在固定时间点唤醒,减少不必要的功耗。
缺点:需要额外的RTC硬件支持,增加了成本。
网络唤醒是指通过总线信号(如CAN、LIN等)唤醒ECU。这种方式允许远程节点发送唤醒指令,使目标ECU从休眠状态恢复到工作状态。网络唤醒通常用于需要远程控制或协同工作的场景。
应用场景:适用于需要远程控制或多个ECU协同工作的场景,如诊断工具通过CAN总线唤醒特定ECU。
优点:灵活性高,可以通过网络远程控制,适合复杂系统的协同工作。
缺点:依赖于网络通信,可能存在延迟或通信失败的风险。
NM(Network Management)是AUTOSAR标准中的一个模块,负责管理和协调网络中的ECU状态。它确保在网络中所有ECU能够在合适的时间进入休眠或唤醒状态,从而优化系统的功耗和性能。
功能:NM模块通过发送和接收特定的网络管理报文来控制ECU的状态转换。例如,当某个ECU需要进入休眠状态时,它会发送休眠请求报文;当需要唤醒时,则发送唤醒请求报文。
应用场景:适用于需要多个ECU协同工作的复杂系统,如整车网络管理。
优点:提高系统的整体效率,减少不必要的功耗。
缺点:增加了系统的复杂性,需要更多的配置和调试。
唤醒方式 | 应用场景 | 优点 | 缺点 |
硬线唤醒 | 需要即时响应的情况 | 简单可靠 | 只能在物理连接的情况下工作 |
本地唤醒 | 根据车辆内外部环境变化操作 | 响应速度快 | 依赖具体硬件配置 |
RTC唤醒 | 定时执行任务 | 精确度高,减少功耗 | 需要额外RTC硬件支持 |
网络唤醒 | 远程控制或协同工作 | 灵活性高,适合复杂系统 | 可能存在延迟或通信失败 |
在以上唤醒方式中,本文关注的是网络唤醒。更具体的,是每隔一段时间,综合全车所有传感器和外界车联网传入的状态数据,比如v2x,作为输入,每种输入代表一种车辆的综合状态,然后判断哪些MCU可以休眠,哪些需要打开,哪些可以预休眠以便随叫随到。
在打开的MCU中,有些是当前就要用到需要打开,有些是基于场景预测提前打开备用。
比如安全气囊系统:虽然安全气囊不会在每次启动车辆时都激活,但MCU会根据车辆的速度、加速度和其他传感器数据预测潜在的碰撞风险,并提前准备好安全气囊系统。如果检测到即将发生碰撞,安全气囊将迅速充气以保护乘客。
此外还有IEB系统。IEB系统(Intelligent Emergency Braking)是一种智能紧急刹车系统,旨在提高车辆的安全性。该系统通过多种传感器(如毫米波雷达、单目或双目摄像头)实时监测车辆前方的情况,在检测到潜在碰撞风险时,会自动采取制动措施以避免或减轻碰撞的严重程度。
比如在车辆从自身的自动驾驶系统目标识别和车联网路况信息都得到前方车辆密集的信息,而且座舱对驾驶员的疲劳检测说明驾驶员疲劳,则会提前激活IEB系统的处理器,因为是擦碰的高风险场景。
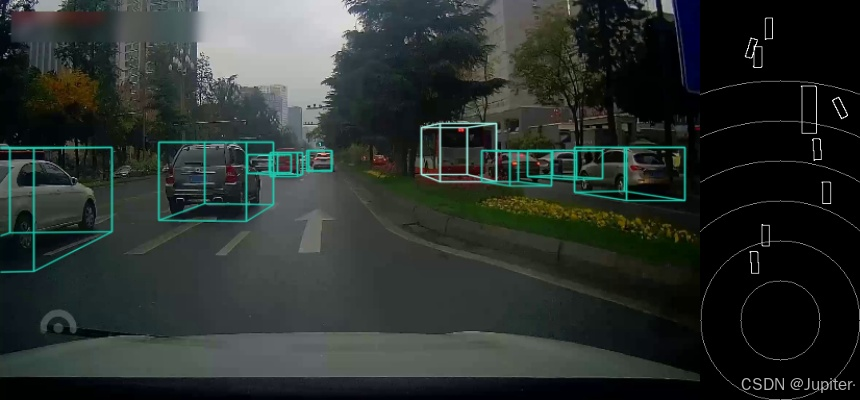
图 2 单目摄像头的车辆3d识别,图片来自CSDN
反过来,如果车辆从自身的自动驾驶系统目标识别和车联网路况信息都得到前方一马平川且道路封闭(也就是不可能出现鬼探头场景),则可以暂时休眠IEB系统的处理器MCU和ABS系统的MCU。
#03
在进一步介绍用AI和优化算法来优化MCU的网络管理之前,我们需要讨论:万一网络管理“错误地”休眠或者唤醒某些MCU,后果是什么?
回答是,主要是会加大电耗,但一般不会造成严重的安全性问题。原因在于休眠的MCU恢复工作的速度非常快。
所以“错误地”休眠某些MCU,在绝大多数场景下,MCU都会通过硬线唤醒及时恢复工作。比如司机踩刹车会硬线唤醒ABS系统,如果ABS在休眠的话。
对应的,“错误地”唤醒某些MCU,只不过会让这些MCU多做一会儿无用功,多费电而已。
具体展开,一般而言MCU从休眠模式唤醒到恢复正常工作所需的时间取决于多种因素,包括所使用的MCU类型、具体的休眠模式以及唤醒源。以下是一些常见的MCU唤醒时间数据和影响因素:
1. 唤醒时间概述:
a. MCU在不同休眠模式下的唤醒时间有所不同。通常,较浅的休眠模式(如Sleep模式)的唤醒时间较短,而深度休眠模式(如Deep Sleep或Stop模式)的唤醒时间较长。
b. 例如,
STM32系列MCU在Stop模式下唤醒后,需要一定时间重新启动时钟和其他外设。
2. 具体唤醒时间数据:
a. AVR系列MCU:当使用外部中断唤醒时,MCU会在中断发生后额外等待四个时钟周期再开始执行中断服务程序。
b. MSP430系列MCU:在某些配置下,唤醒时间可以非常短,例如六时钟周期[。
c. STM32系列MCU:从Stop模式唤醒的时间取决于内部时钟(HSI)的稳定时间,大约为几微秒到几十微秒不等。
3. 影响唤醒时间的因素:
a. 时钟恢复:许多MCU在唤醒时需要重新启动内部时钟,这会增加总的唤醒时间。例如,STM32在从Stop模式唤醒时,需要等待HSI时钟稳定。
b. 外设初始化:部分外设可能需要重新初始化,这也会影响总的唤醒时间。
c. 唤醒源:不同的唤醒源(如外部中断、定时器中断、RTC报警等)对唤醒时间有不同的影响。例如,使用RTC定时唤醒时,唤醒时间相对固定且可预测。而硬线唤醒是最直接最可靠的。比较耗时甚至失败的是通过NM报文的网络唤醒。
4. 优化唤醒时间的方法:
a.选择合适的休眠模式:根据应用需求选择最合适的休眠模式,以平衡功耗和唤醒时间。
b.预配置外设:在进入休眠前预先配置好外设,减少唤醒后的初始化时间。
c.使用快速启动机制:一些MCU提供快速启动选项,可以在更短时间内完成唤醒过程。
然后解释一下MCU通过外部中断唤醒“要等N个时钟周期”,这到底是多少时间呢?取决于MCU芯片的频率,频率越高,每个周期时间越短。
当中断发生时,MCU(微控制器)确实会在响应中断之前额外等待几个时钟周期。这个延迟是由于内部处理机制导致的,具体来说,MCU需要一定的时间来保存当前的执行状态并跳转到中断服务程序(ISR)。对于不同的MCU架构,这个延迟可能会有所不同,比如我们前面提到的,AVR系列的MCU会在中断发生后增加四个时钟周期的延迟。
要计算四个时钟周期的具体时间长度,需要知道MCU的工作频率(即时钟频率)。时钟周期的长度是时钟频率的倒数。例如:
如果MCU的工作频率为1 MHz:
每个时钟周期的时间 = 11,000,000 秒 = 1 微秒 (μs)
四个时钟周期的时间 = 4 × 1 μs = 4 μs
如果MCU的工作频率为16 MHz:
每个时钟周期的时间 = 116,000,000 秒 = 62.5 纳秒 (ns)
四个时钟周期的时间 = 4 × 62.5 ns = 250 ns
如果MCU的工作频率为72 MHz:
每个时钟周期的时间 = 172,000,000 秒 ≈ 13.89 纳秒 (ns)
四个时钟周期的时间 = 4 × 13.89 ns ≈ 55.56 ns
因此,四个时钟周期的具体时间取决于MCU的工作频率。下表总结了不同频率下的四个时钟周期的时间:
MCU工作频率 | 每个时钟周期时间 | 四个时钟周期时间 |
1 MHz | 1 μs | 4 μs |
16 MHz | 62.5 ns | 250 ns |
72 MHz | 13.89 ns | 55.56 ns |
可见硬线唤醒MCU要等待几个时钟周期,但时间很短,几乎不会影响使用。
敏感的读者马上会问一个问题,既然实时唤醒MCU基本不影响使用,那为什么不干脆休眠所有MCU,然后需要时唤醒它们就行了?
回答还是耗电,是能耗效率不高。
MCU的休眠和唤醒机制设计是为了在功耗和性能之间取得平衡。虽然MCU的唤醒时间确实很短,但让MCU一直保持休眠并在需要时通过硬线唤醒就能最省电。理由如下:
1. 功耗与唤醒频率的平衡
尽管MCU从休眠模式唤醒的时间非常短(通常为微秒级),但频繁的唤醒和进入休眠过程本身也会消耗一定的能量。如果唤醒过于频繁,累积的唤醒时间和功耗可能会抵消休眠带来的节能效果。
2. 硬件和软件开销
频繁的休眠和唤醒操作会增加硬件和软件的设计复杂度。例如,需要确保在休眠前正确关闭不必要的外设,并在唤醒后重新配置这些外设。此外,还需要处理各种唤醒源(如GPIO、定时器等)以确保系统能够正确响应外部事件。
3. 应用场景需求
不同的应用场景对功耗和性能有不同的要求。对于一些低功耗应用(如传感器节点、可穿戴设备等),长时间休眠和较少的唤醒次数可能是更合适的选择。而对于需要频繁处理数据或对外部事件做出快速响应的应用(如工业控制、通信设备等),保持MCU在较低功耗的工作模式而不是完全休眠可能更为合适。
总结:
虽然MCU的唤醒时间很短,但在实际应用中,是否让MCU一直保持休眠并在需要时硬线唤醒取决于具体的功耗需求、响应时间要求以及应用场景。为了实现最佳的功耗和性能平衡,通常会在休眠时间和唤醒频率之间进行权衡,并选择适当的唤醒源和技术手段来满足特定应用的需求。
在第三部分容错性分析的基础上,我们可以看到,假设一个模型即使“错误地”唤醒或者休眠一些MCU,主要的影响是电耗,而不是安全性。而且为了绝对确保安全性,OEM可以对一些被判定为critical的MCU人为限制不允许休眠或者至少不能deep sleep。
有这一分析作为心理基础,算法模 型设计者就可以比较大胆地来设计和实现 AI+优化算法 的 算法方案来根据场景(场景由全体传感器数据+车联网传入数据定义)优化全车所有MCU的应该处于哪种状态,并且通过网络管理报文来设置这些状态。
主体方案如下:
1、基于人为逻辑的场景设计场景约束条件(人工操作)
2、用优化算法对细分场景探索满足约束的最佳“休眠-工作”分布方案(也就是决定全车每个MCU应该处于哪种状态),最佳的标准是能耗最小。
3、根据1和2,形成对大模型的训练数据集(每条训练数据是某一场景对应最佳“休眠-工作”分布方案)
4、用基于神经网络的大模型学习“场景--分布方案”对组成的训练数据(3中产生)
5、训练好的大模型在使用中,根据实时场景给出对应的近似最优“休眠-工作”分布方案,可以有一个或者多个。
6、后处理:基于规则约束的判定程序判定大模型在使用中给出的解是否违反关键约束(由于神经网络的不可解释性,这种错误是有可能的),不违反则直接使用;如果违反,则调用实时优化算法,从大模型提供的解出发微调,快速获得高优度的可行解。
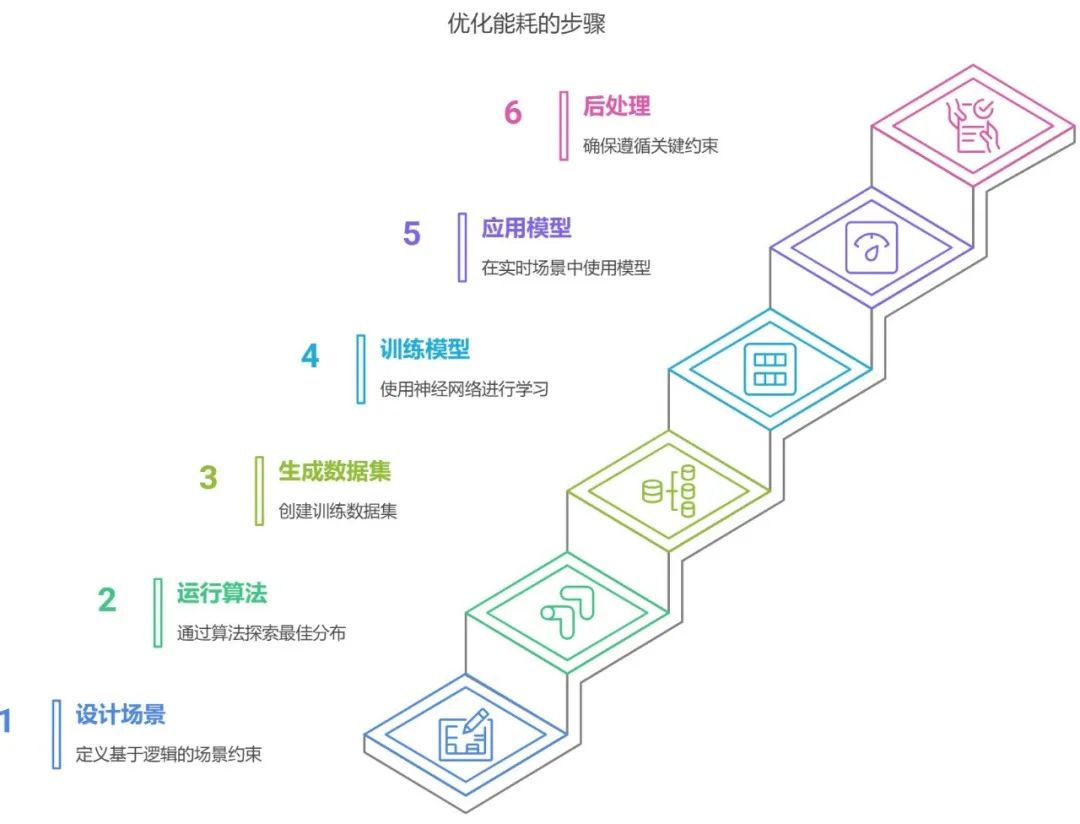
图 3 AI+优化算法优化MCU网络管理的主体方案设计图

图 4 基于神经网络的大模型,左侧输入场景状态数据,右侧输出MCU的最佳状态,图片来自网络。
最后笔者介绍一下确定神经网络合适大小的一个经验法则。
经验法则:一种常用的经验法则是,训练样本的数量应该是模型参数数量的10倍左右。例如,如果模型有100万个参数,则建议至少有1000万个训练样本[9]。
假设我们有一万条某一场景对应最佳“休眠-工作”分布方案的训练数据,那么1000个参数的神经网络基本就够了。
有效控制神经网络的规模,便于后续在嵌入式硬件上部署和运行,因为嵌入式硬件的内存、闪存和计算力都是十分受限的,规模越小功能够用的神经网络比较合适。
#05
必须承认,这件工作的难度和复杂性远超过笔者另一篇文章《通过元启发式算法设计域控制器的最优BOM》
1、首先要求是在比较成熟的车型上应用这种方法,比较成熟的车型上MCU的类型和数量都比较固定。传感器的数量和种类以及车联网传入的数据的类型也比较稳定。
这样才能保证训练出的模型的输入输出比较稳定。
2、其次,筹集原始训练数据是比较大的工程。每一条原始训练数据都是 场景和MCU“休眠-工作”分布方案 的对应。需要细分大量场景,识别场景中MCU“休眠-工作”分布方案的约束条件,并人为探索或者设计实现优化算法来探索满足约束的所有MCU的最佳“休眠-工作”分布方案。积累训练数据的工作量比较大。
克服以上两点后,模型设计,训练模型,以及模型嵌入式部署,后处理检查和优化模型输出的方案,然后NM报文设计把最优MCU“休眠-工作”分布方案通过can线下发给各个MCU。这些都是比较成熟的现有技术,实现起来比较有把握。
虽然存在工作量大成本高的问题,本文提出的思路和方案仍然具有破局的作用。因为现在车辆行业的竞争太过激烈,每一个零件,每一块软件,每一个算法都是激烈争夺的赛场。任何一个能开辟新赛道并应用最新AI技术的生长点都具有挖掘价值,以增强自身的竞争优势。
