NVIDIA Blackwell架构虽然在加速卡、游戏卡上都遭遇诸多波折,但这并不影响NVIDIA对于未来的宏伟规划,不但公布了下一代Rubin架构的具体产品规划,还首次宣布了再下一代架构“Feynman”。

Feynman就是理查德·费曼,美籍犹太裔人,20世纪最伟大的物理学家之一,诺贝尔物理学奖获得者,在量子电动力学、量子计算、纳米技术等领域都有开创性的成就,还撰写了《费曼物理学讲义》、提出了“费曼学习法”,1986年挑战者号航天飞机爆炸失事的根本原因也是他查明的。

NVIDIA这次一共宣布了三款产品,首先是“Blackwell Ultra GB300 NV72”,今年下半年发布,每个节点配备两颗升级版的Blackwell GPU、一颗Grace CPU,搭配多达288GB HBM3e高带宽内存,Dense FP4性能高达15PFlops(每秒1.5亿亿次)。
整台服务器一共72个节点,也就是144颗GPU、72颗CPU、20TB HBM3e、40TB DDR5内存,比上代增加50%,CX8互连带宽14.4TB/s,增加100%。
整机的Dense FP4推理性高达1.1EFlops(每秒110亿亿次),FP8训练性能高达0.36EFlps(36亿亿次),还有新的注意力指令。
NVIDIA表示,联想、戴尔、超微等合作伙伴预计将从2025年下半年开始推出基于Blackwell Ultra的各类服务器。

2026年下半年,我们将迎来全新的Rubin架构,首发服务器产品为“Vera Rubin NV144”,每个节点两颗Rubin GPU搭配一颗全新的Vera CPU。
其中,Rubin GPU搭配288GB容量的下一代HBM4内存,FP4浮点性能跃升到50PFlops(每秒5亿亿次)。
Vera CPU则包含88个自研Arm架构核心,首次支持多线程而达到176线程,彼此之间通过1.8TB/s带宽的NVLink-C2C总线连接在一起。
整台服务器一共144个节点,也就是288颗GPU、144颗CPU、41.5TB HBM4内存(带宽13TB/s),还有75TB的系统内存,NVLink6带宽达260TB/s,CX9总线带宽达28.8TB/s。
FP4推理性能来到3.6EFlops(每秒360亿亿次),FP8训练性能则是1.2EFlops(每秒120亿亿次)。

2027年下半年,我们将看到升级版的“Rubin Ultra NV576”,每个节点包含四颗Rubin GPU、一颗Vera GPU,并升级1TB HBM4e内存,FP4浮点性能高达100PFlops(10亿亿次)。
整机一共多达576个节点,也就是拥有2304颗Rubin GPU、576颗Vera CPU、576TB HBM5e(带宽4.6PB/s),还有365TB系统内存。
NVLink互连总线升级到第七代NVLink7,带宽惊人的1.5PB/s,另外CX9总线带宽115.2TB/s。
FP4推理性能高达15EFlops(每秒1500亿亿次),FP8训练性能5EFlops(每秒500亿亿次)。

至于新的Feynman架构,将在2028年首次登场,搭配下一代HBM内存(HBM5?),但具体细节暂未披露。


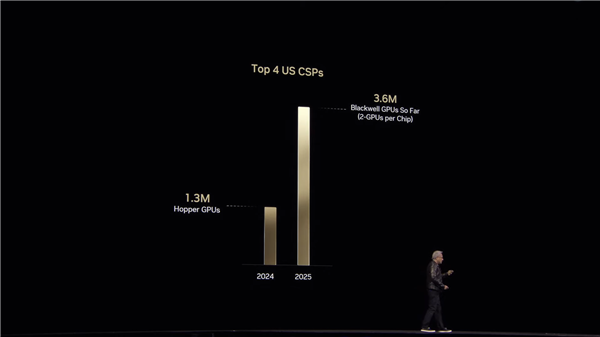
NVIDIA CEO黄仁勋还宣布,NVIDIA今年已经向美国四大云服务提供商售出了超过300万块Blackwell AI GPU。
要知道,这一数字还仅涵盖了美国四大云服务提供商,并没有包括其他AI企业或初创公司。
与上一代Hopper架构相比,Blackwell的销售量几乎增长了三倍,这表明AI硬件的需求正在快速增长。
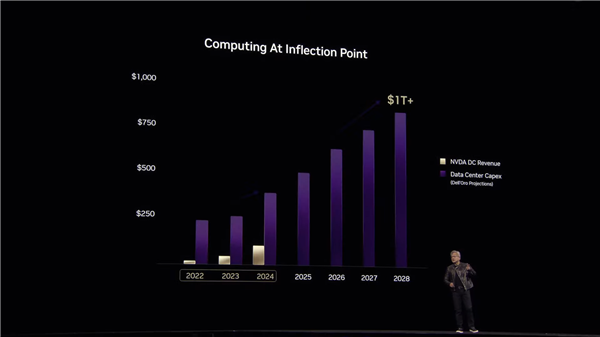
黄仁勋表示,AI计算正处于一个“转折点”,未来对硬件的需求将迅速增长。
NVIDIA预计,到2027年,数据中心的建设成本将达到1万亿美元以上,这几乎是当前水平的四倍。
虽然Blackwell系列遇到了如产量和发货延迟等问题,但该架构仍然得到了行业的广泛采用,随着新产品线如Blackwell Ultra和Vera Rubin的推出,NVIDIA预计其计算收入将大幅增长。
不过在消费级显卡方面,RTX 50系列发布已久,先后推出四款型号,但是缺货、涨价情况依旧普遍存在。
新品刚上市缺货是很正常的事情,毕竟产能需要爬坡,但是RTX 50系列这次格外严重,RTX 5070系列甚至延期发布了都未能缓解。

除了数据中心和游戏,GPU显卡还有一个重要的细分领域,那就是图形工作站。
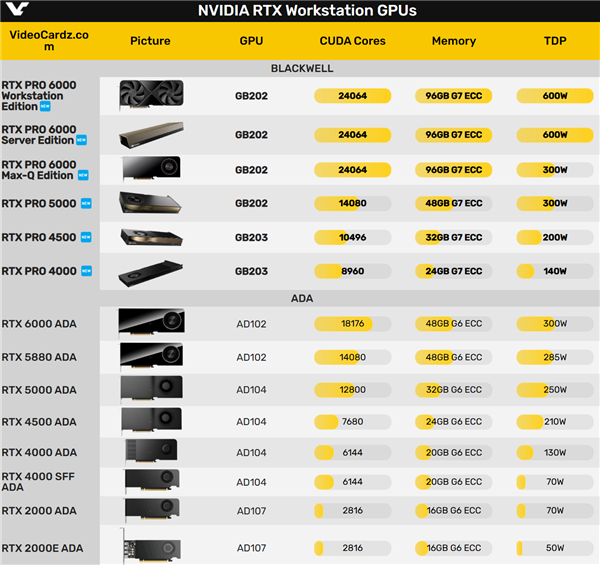
NVIDIA正式发布了基于Blackwell架构的新一代工作站专业显卡,涵盖桌面台式机、笔记本、数据中心,一共有多达12款不同型号,并首次在型号命名中加入了PRO字样。
桌面上一共五款,旗舰级的是RTX PRO 6000,分为工作站版、Max版两个不同版本,都基于GB202核心,有多达24064个CUDA核心,搭配512-bit 96GB GDDR7 ECC显存(单颗容量3GB),等效频率28GHz,规模远超RTX 5090,热设计功耗分别为600W、300W。

其中,RTX PRO 6000工作站版标称单精度浮点性能125TFlops,算下来核心频率2.6GHz,采用开放式双风扇散热,也是全系列唯一这样设计的。


Max-Q版本则略微降低至2.5GHz,并改成了单风扇涡轮式散热,更适合多卡部署。


RTX PRO 5000也是GB202核心,配备14080个CUDA核心(和上代RTX 5880 ADA一模一样)、384-bit 48GB GDDR7 ECC显存(容量没变只是升级类型),功耗300W。
RTX PRO 4500改成了GB203核心,提供10496个CUDA核心,略微少于RTX 5080,比上代RTX 4500 ADA增加了37%之多,而显存有256-bit 32GB GDDR7 ECC,两倍于RTX 5080,比上代增加50%,但功耗仅为200W。
RTX PRO 4000同样是GB203核心,8960个CUDA核心,192-bit 24GB GDDR7 ECC显存,比上代分别增加46%、20%,功耗只有140W。
另外,所有型号都标配四个DisplayPort 2.1b输出接口,没有HDMI。
这样的提升幅度,让挤牙膏的桌面级RTX 50系列情何以堪!
RTX PRO 6000还有个服务器版本,无风扇被动散热,适合密集服务器部署,使用系统级散热。

移动版型号最多有六款,分别叫做RTX PRO 5000、4000、3000、2000、1000、500,但暂未公布具体规格。
当然啦,NVIDIA也没有完全忘记游戏玩家,发布了全新的GeForce 572.83正式版显卡驱动,支持新显卡、新游戏,还为多达61款游戏加入了DLSS Override驱动级支持。
但是,这次没有提及前几个版本驱动反复尝试解决的黑屏问题。
新驱动正式支持即将发布的RTX 5090、RTX 5080、RTX 5070 Ti笔记本,本月底开始陆续发布上市。
支持优化两款新游戏《半条命2 RTXD EMO》、《InZOl》,前者和《战锤40K:暗潮》都已加入DLSS 4,而后者首次落地了NVIDIA ACE数字人。

NVIDIA还针对多达61款游戏,提供了驱动级的DLSSOverride支持,可一键开启,它们分别是:
寂静之地:前路
阿金机器人
救护车生活:救护员模拟
刺客信条:影袭
星轨
法蒂玛阿姨
汽车经销商模拟器:序章-早期岁月
阿尔科诺斯特密码:邪恶觉醒
欺诈2
无序:解谜游戏冒险
异星指令:自治殖民地模拟器
直接接触
龙裔:被放逐者
地牢传承
星战前夜:边境
永恒空间2
最终幻想VII:重生
最终幻想XVI
芬兰小屋模拟器
索利斯堡
芬克融合
地平线:零之曙光完全版
灵动:复刻版
侏罗纪世界:进化2
克里斯塔拉
层层恐惧
遗产:钢铁与魔法
乐高:地平线冒险
如龙:夏威夷的海盗黑帮
阈域核心
失落记录:绽放与狂怒
漫威蜘蛛侠2
地铁:离去
夜莺
忍者龙剑传2:黑之章
地狱已满2
喋血街头4:无悔
康加
死亡回归
法师的复仇
浪人崛起
幸福工厂
血清
斯凯:迷雾之岛
瘦长鬼影:降临
神之浩劫2
星河战队:灭绝
风暴之门
仙剑奇侠传七
无限试驾:太阳王冠
未见之轴
黑池
上古卷轴OL
东京极速赛车
扭矩漂移2
部落3:对手
直到黎明
矢量打击
战锤40K:星际战士2
鸣潮
轩辕剑柒