----追光逐电 光引未来----
长期以来,增强YOLO框架的网络架构一直至关重要,但一直专注于基于cnn的改进,尽管注意力机制在建模能力方面已被证明具有优越性。这是因为基于注意力的模型无法匹配基于cnn的模型的速度。本文提出了一种以注意力为中心的YOLO框架,即YOLOv12,与之前基于cnn的YOLO框架的速度相匹配,同时利用了注意力机制的性能优势。YOLOv12在精度和速度方面超越了所有流行的实时目标检测器。例如,YOLOv12-N在T4 GPU上以1.64ms的推理延迟实现了40.6% mAP,以相当的速度超过了高级的YOLOv10-N / YOLOv11-N 2.1%/1.2% mAP。这种优势可以扩展到其他模型规模。YOLOv12还超越了改善DETR的端到端实时检测器,如RT-DETR /RT-DETRv2: YOLOv12- s比RT-DETR- r18 / RT-DETRv2-r18运行更快42%,仅使用36%的计算和45%的参数。
总结:作者围提出YOLOv12目标检测模型,测试结果更快、更强,围绕注意力机制进行创新。
一、创新点总结
作者构建了一个以注意力为核心构建了YOLOv12检测模型,主要创新点创新点如下:
1、提出一种简单有效的区域注意力机制(area-attention)。
2、提出一种高效的聚合网络结构R-ELAN。
作者提出的area-attention代码如下:
class AAttn(nn.Module): """ Area-attention module with the requirement of flash attention. Attributes: dim (int): Number of hidden channels; num_heads (int): Number of heads into which the attention mechanism is divided; area (int, optional): Number of areas the feature map is divided. Defaults to 1. Methods: forward: Performs a forward process of input tensor and outputs a tensor after the execution of the area attention mechanism. Examples: >>> import torch >>> from ultralytics.nn.modules import AAttn >>> model = AAttn(dim=64, num_heads=2, area=4) >>> x = torch.randn(2, 64, 128, 128) >>> output = model(x) >>> print(output.shape)
Notes: recommend that dim//num_heads be a multiple of 32 or 64. """
def __init__(self, dim, num_heads, area=1): """Initializes the area-attention module, a simple yet efficient attention module for YOLO.""" super().__init__() self.area = area
self.num_heads = num_heads self.head_dim = head_dim = dim // num_heads all_head_dim = head_dim * self.num_heads
self.qkv = Conv(dim, all_head_dim * 3, 1, act=False) self.proj = Conv(all_head_dim, dim, 1, act=False) self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
def forward(self, x): """Processes the input tensor 'x' through the area-attention""" B, C, H, W = x.shape N = H * W
qkv = self.qkv(x).flatten(2).transpose(1, 2) if self.area > 1: qkv = qkv.reshape(B * self.area, N // self.area, C * 3) B, N, _ = qkv.shape q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split( [self.head_dim, self.head_dim, self.head_dim], dim=3 )
# if x.is_cuda: # x = flash_attn_func( # q.contiguous().half(), # k.contiguous().half(), # v.contiguous().half() # ).to(q.dtype) # else: q = q.permute(0, 2, 3, 1) k = k.permute(0, 2, 3, 1) v = v.permute(0, 2, 3, 1) attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5) max_attn = attn.max(dim=-1, keepdim=True).values exp_attn = torch.exp(attn - max_attn) attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True) x = (v @ attn.transpose(-2, -1)) x = x.permute(0, 3, 1, 2) v = v.permute(0, 3, 1, 2)
if self.area > 1: x = x.reshape(B // self.area, N * self.area, C) v = v.reshape(B // self.area, N * self.area, C) B, N, _ = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2) v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.pe(v) x = self.proj(x) return x结构上与YOLOv11里C2PSA中的模式相似,使用了Flash-attn进行运算加速。Flash-attn安装时需要找到与cuda、torch和python解释器对应的版本,Windows用户可用上述代码替换官方代码的AAttn代码,无需安装Flash-attn。
R-ELAN结构如下图所示:
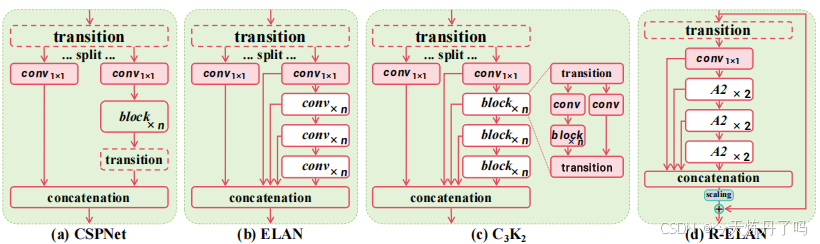
作者基于该结构构建了A2C2f模块,与C2f/C3K2模块结构类似,代码如下:
class AAttn(nn.Module): """ Area-attention module with the requirement of flash attention. Attributes: dim (int): Number of hidden channels; num_heads (int): Number of heads into which the attention mechanism is divided; area (int, optional): Number of areas the feature map is divided. Defaults to 1. Methods: forward: Performs a forward process of input tensor and outputs a tensor after the execution of the area attention mechanism. Examples: >>> import torch >>> from ultralytics.nn.modules import AAttn >>> model = AAttn(dim=64, num_heads=2, area=4) >>> x = torch.randn(2, 64, 128, 128) >>> output = model(x) >>> print(output.shape)
Notes: recommend that dim//num_heads be a multiple of 32 or 64. """
def __init__(self, dim, num_heads, area=1): """Initializes the area-attention module, a simple yet efficient attention module for YOLO.""" super().__init__() self.area = area
self.num_heads = num_heads self.head_dim = head_dim = dim // num_heads all_head_dim = head_dim * self.num_heads
self.qkv = Conv(dim, all_head_dim * 3, 1, act=False) self.proj = Conv(all_head_dim, dim, 1, act=False) self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
def forward(self, x): """Processes the input tensor 'x' through the area-attention""" B, C, H, W = x.shape N = H * W
qkv = self.qkv(x).flatten(2).transpose(1, 2) if self.area > 1: qkv = qkv.reshape(B * self.area, N // self.area, C * 3) B, N, _ = qkv.shape q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split( [self.head_dim, self.head_dim, self.head_dim], dim=3 )
# if x.is_cuda: # x = flash_attn_func( # q.contiguous().half(), # k.contiguous().half(), # v.contiguous().half() # ).to(q.dtype) # else: q = q.permute(0, 2, 3, 1) k = k.permute(0, 2, 3, 1) v = v.permute(0, 2, 3, 1) attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5) max_attn = attn.max(dim=-1, keepdim=True).values exp_attn = torch.exp(attn - max_attn) attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True) x = (v @ attn.transpose(-2, -1)) x = x.permute(0, 3, 1, 2) v = v.permute(0, 3, 1, 2)
if self.area > 1: x = x.reshape(B // self.area, N * self.area, C) v = v.reshape(B // self.area, N * self.area, C) B, N, _ = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2) v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.pe(v) x = self.proj(x) return x
class ABlock(nn.Module): """ ABlock class implementing a Area-Attention block with effective feature extraction. This class encapsulates the functionality for applying multi-head attention with feature map are dividing into areas and feed-forward neural network layers. Attributes: dim (int): Number of hidden channels; num_heads (int): Number of heads into which the attention mechanism is divided; mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2; area (int, optional): Number of areas the feature map is divided. Defaults to 1. Methods: forward: Performs a forward pass through the ABlock, applying area-attention and feed-forward layers. Examples: Create a ABlock and perform a forward pass >>> model = ABlock(dim=64, num_heads=2, mlp_ratio=1.2, area=4) >>> x = torch.randn(2, 64, 128, 128) >>> output = model(x) >>> print(output.shape)
Notes: recommend that dim//num_heads be a multiple of 32 or 64. """
def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1): """Initializes the ABlock with area-attention and feed-forward layers for faster feature extraction.""" super().__init__()
self.attn = AAttn(dim, num_heads=num_heads, area=area) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))
self.apply(self._init_weights)
def _init_weights(self, m): """Initialize weights using a truncated normal distribution.""" if isinstance(m, nn.Conv2d): trunc_normal_(m.weight, std=.02) if isinstance(m, nn.Conv2d) and m.bias is not None: nn.init.constant_(m.bias, 0)
def forward(self, x): """Executes a forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor.""" x = x + self.attn(x) x = x + self.mlp(x) return x
class A2C2f(nn.Module): """ A2C2f module with residual enhanced feature extraction using ABlock blocks with area-attention. Also known as R-ELAN This class extends the C2f module by incorporating ABlock blocks for fast attention mechanisms and feature extraction. Attributes: c1 (int): Number of input channels; c2 (int): Number of output channels; n (int, optional): Number of 2xABlock modules to stack. Defaults to 1; a2 (bool, optional): Whether use area-attention. Defaults to True; area (int, optional): Number of areas the feature map is divided. Defaults to 1; residual (bool, optional): Whether use the residual (with layer scale). Defaults to False; mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2; e (float, optional): Expansion ratio for R-ELAN modules. Defaults to 0.5. g (int, optional): Number of groups for grouped convolution. Defaults to 1; shortcut (bool, optional): Whether to use shortcut connection. Defaults to True; Methods: forward: Performs a forward pass through the A2C2f module. Examples: >>> import torch >>> from ultralytics.nn.modules import A2C2f >>> model = A2C2f(c1=64, c2=64, n=2, a2=True, area=4, residual=True, e=0.5) >>> x = torch.randn(2, 64, 128, 128) >>> output = model(x) >>> print(output.shape) """
def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True): super().__init__() c_ = int(c2 * e) # hidden channels assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
# num_heads = c_ // 64 if c_ // 64 >= 2 else c_ // 32 num_heads = c_ // 32
self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv((1 + n) * c_, c2, 1) # optional act=FReLU(c2)
init_values = 0.01 # or smaller self.gamma = nn.Parameter(init_values * torch.ones((c2)), requires_grad=True) if a2 and residual else None
self.m = nn.ModuleList( nn.Sequential(*(ABlock(c_, num_heads, mlp_ratio, area) for _ in range(2))) if a2 else C3k(c_, c_, 2, shortcut, g) for _ in range(n) )
def forward(self, x): """Forward pass through R-ELAN layer.""" y = [self.cv1(x)] y.extend(m(y[-1]) for m in self.m) if self.gamma is not None: return x + (self.gamma * self.cv2(torch.cat(y, 1)).permute(0, 2, 3, 1)).permute(0, 3, 1, 2) return self.cv2(torch.cat(y, 1))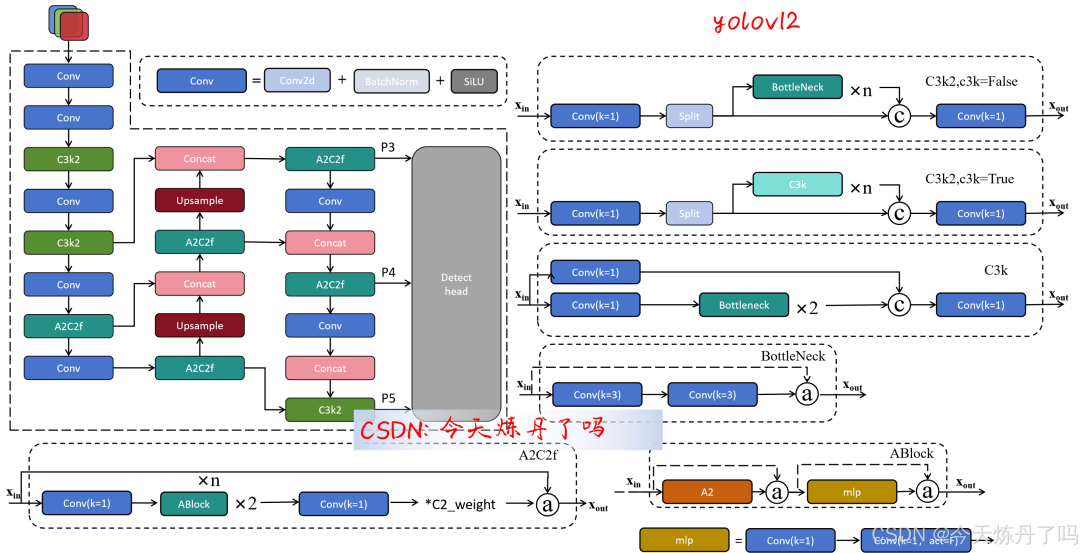
二、使用教程
2.1 准备代码
首先,点击上方链接进入YOLOv12的GitHub仓库,按照图示流程下载打包好的YOLOv12代码与预训练权重文件到本地。
下载完成后解压, 使用PyCharm(或VsCode等IDE软件)打开,并将下载的预训练权重拷贝到解压的工程目录下,下文以PyCharm为例。
2.2 准备数据集
Ultralytics版本的YOLO所需格式的数据集标签为txt格式的文本文件,文本文件中保存的标签信息分别为:类别序号、中心点x/y坐标、标注框的归一化信息,每一行对应一个对象。图像中有几个标注的对象就有几行信息。

下载链接:https://pan.quark.cn/s/f318a977f81c
提取码:LQ68
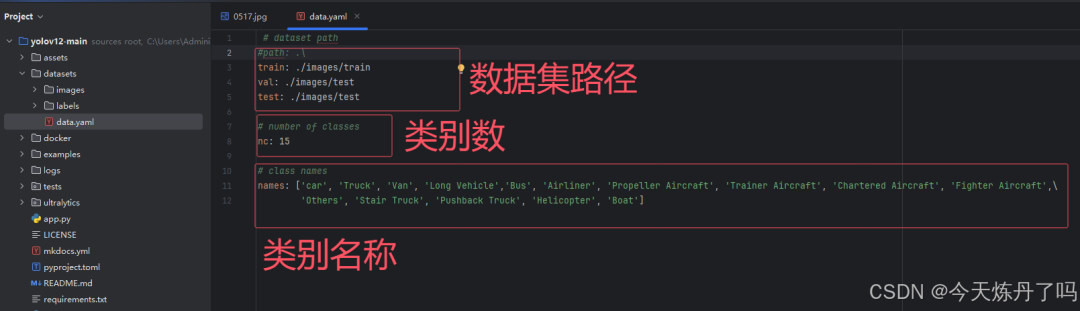
# dataset pathtrain: ./images/trainval: ./images/testtest: ./images/test
# number of classesnc: 15
# class namesnames: ['car', 'Truck', 'Van', 'Long Vehicle','Bus', 'Airliner', 'Propeller Aircraft', 'Trainer Aircraft', 'Chartered Aircraft', 'Fighter Aircraft',\ 'Others', 'Stair Truck', 'Pushback Truck', 'Helicopter', 'Boat']from ultralytics.models import YOLOimport osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
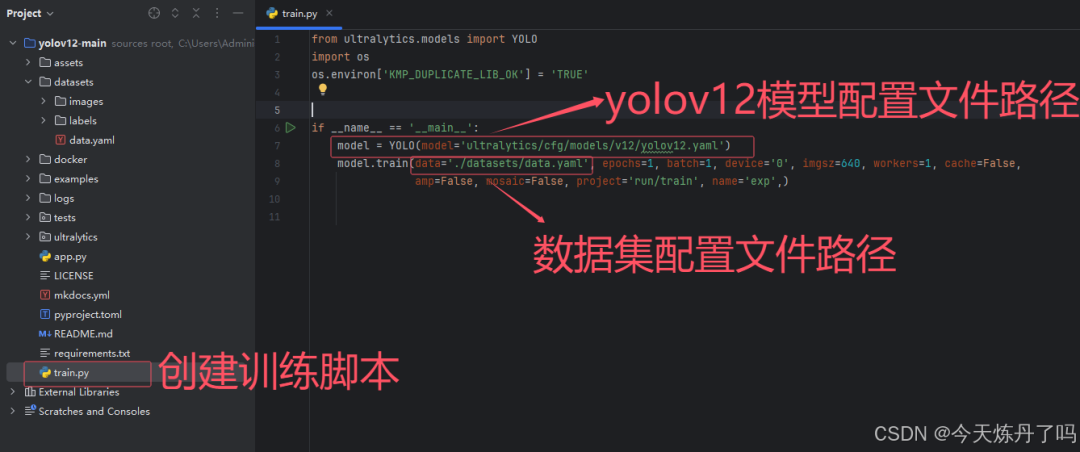
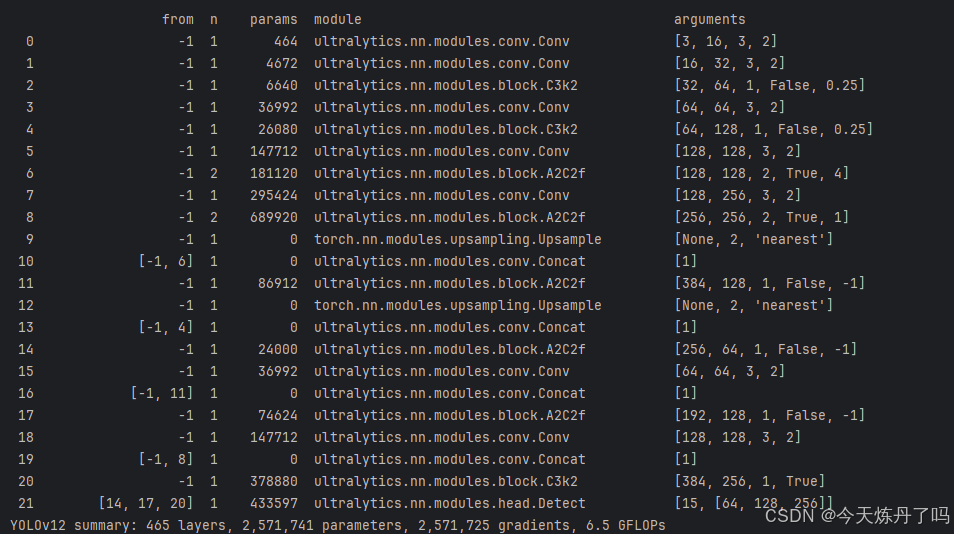
if __name__ == '__main__': model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml') # model.load('yolov8n.pt') model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False, amp=True, mosaic=False, project='runs/train', name='exp')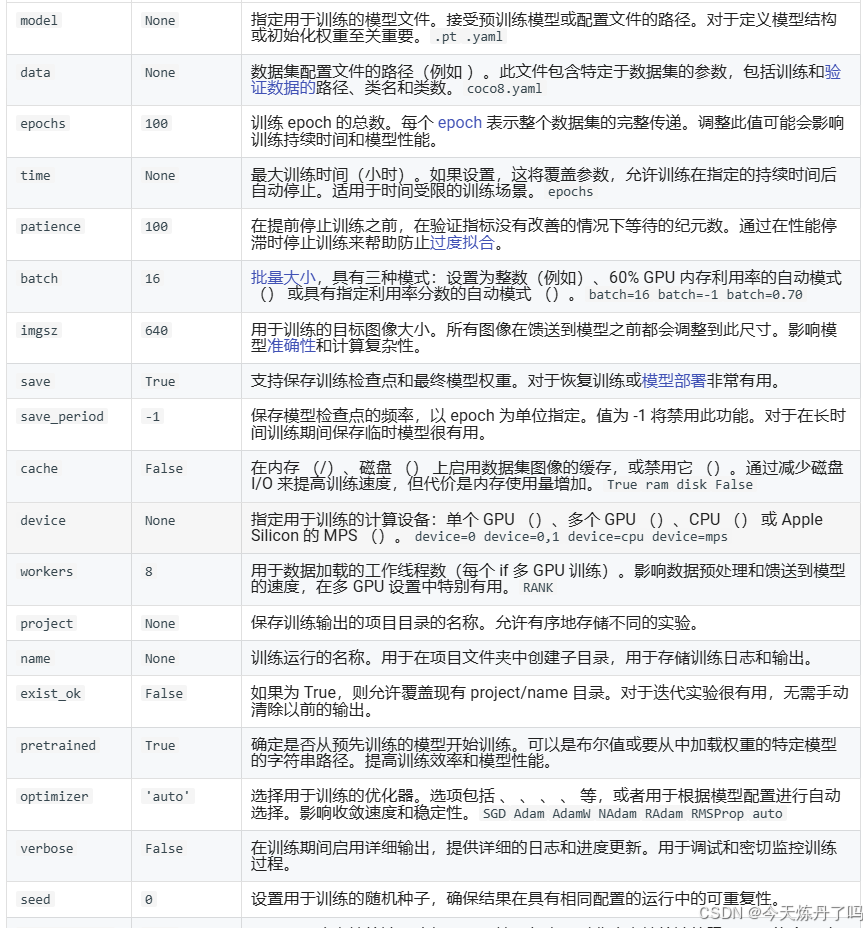
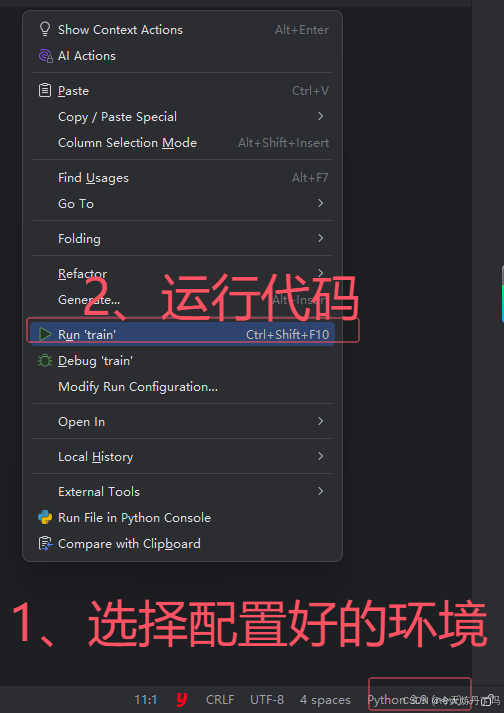
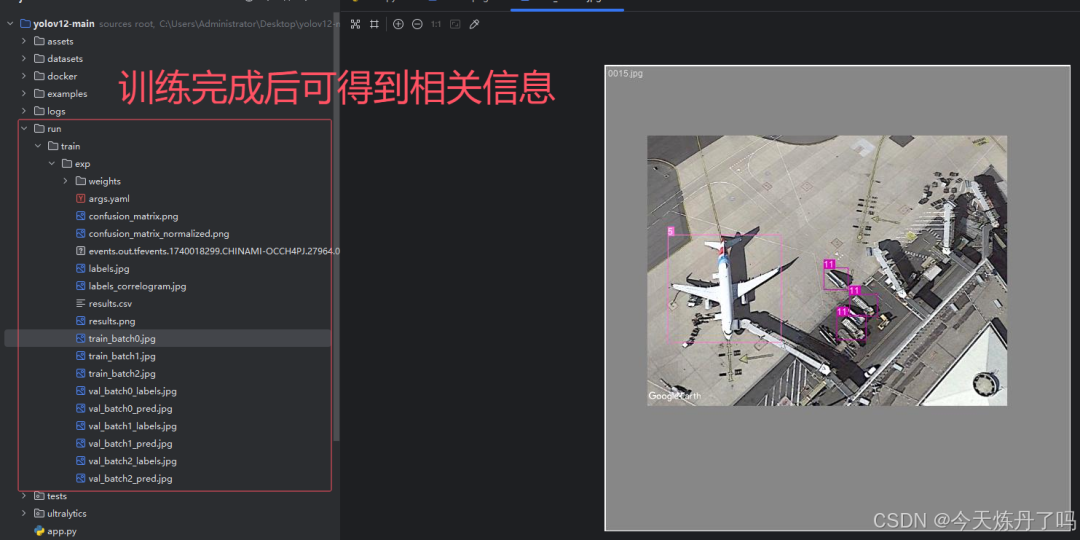
2.4 模型预测
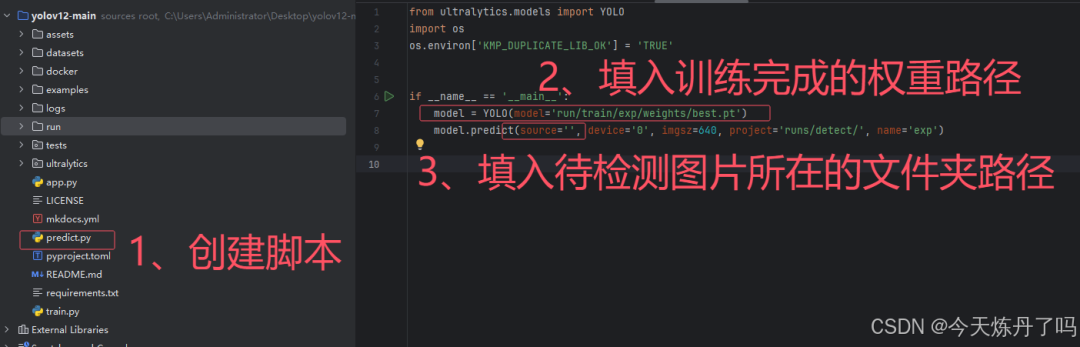
创建detect.py文件,填入训练好的权重路径及要检测的图片信息。
三、小结
浅谈一下YOLOv12的感受,相比前几代的YOLO,v12的改动较小,在结构上删除了SPPF模块,设计了A2C2f模块,在模型的几个位置进行了替换。从作者公布的实验数据来看,模型的计算量和参数量都有一定下降,同时检测性能有一定提升。也不得不感慨,YOLO更新换代的速度越来越快了。要说YOLO那个版本强,那当然是最新的最强。
本文仅用于学术分享,如有侵权,请联系后台作删文处理论文链接:https://arxiv.org/abs/2502.12524
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566