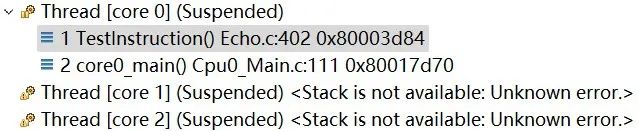
本文约13,200字,建议收藏阅读
作者 | 林Nova
出品 | 汽车电子与软件
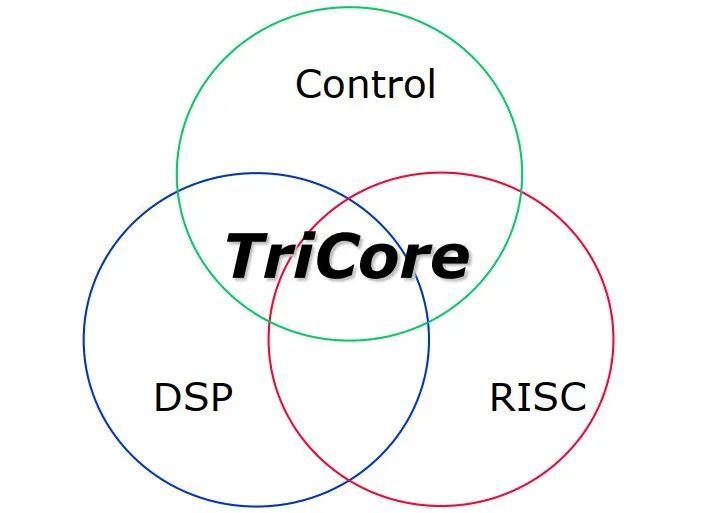
32位架构
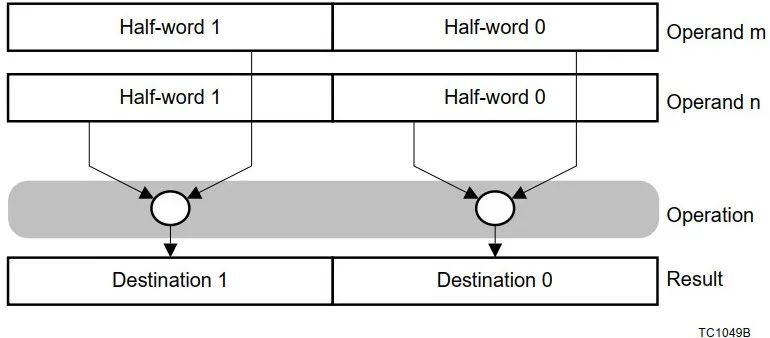
单指令多数据(SIMD)打包数据操作(2x16位或4x 8位操作数)
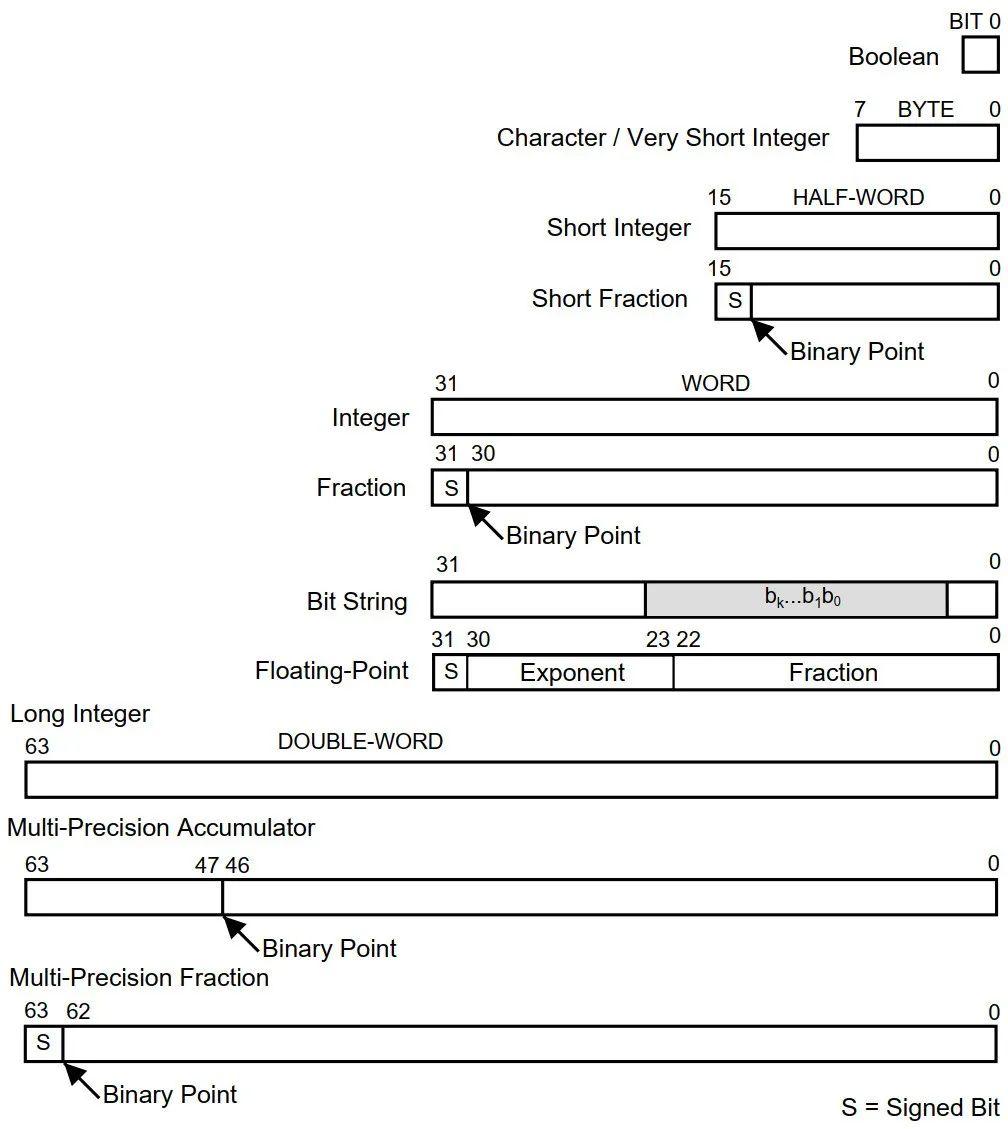
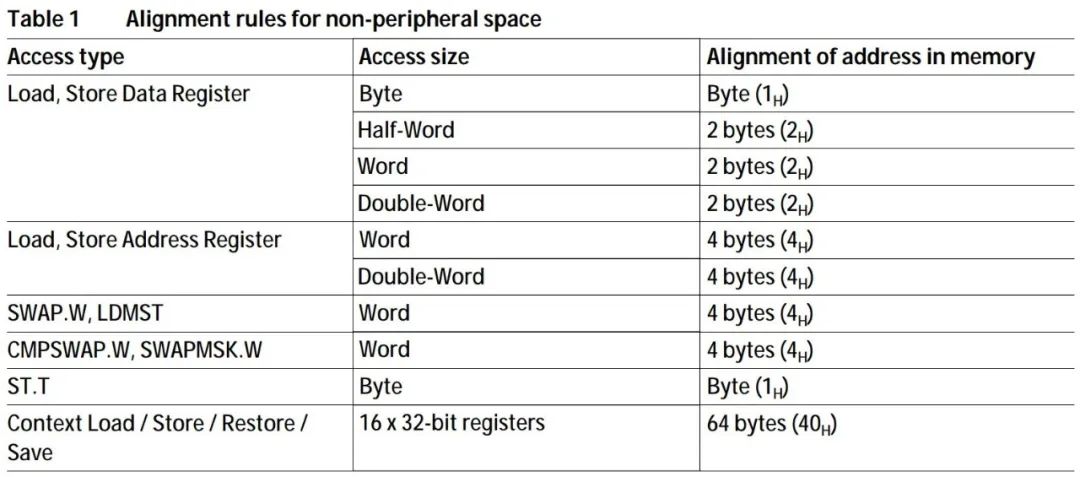
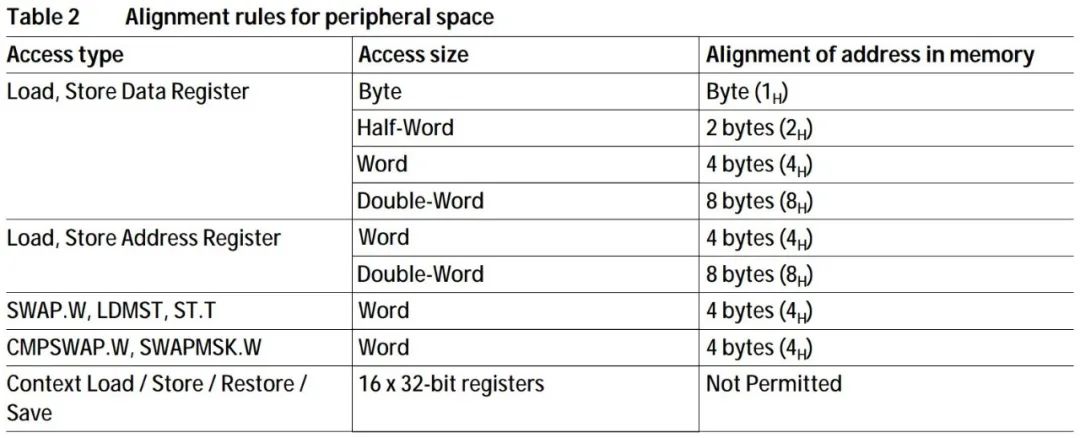
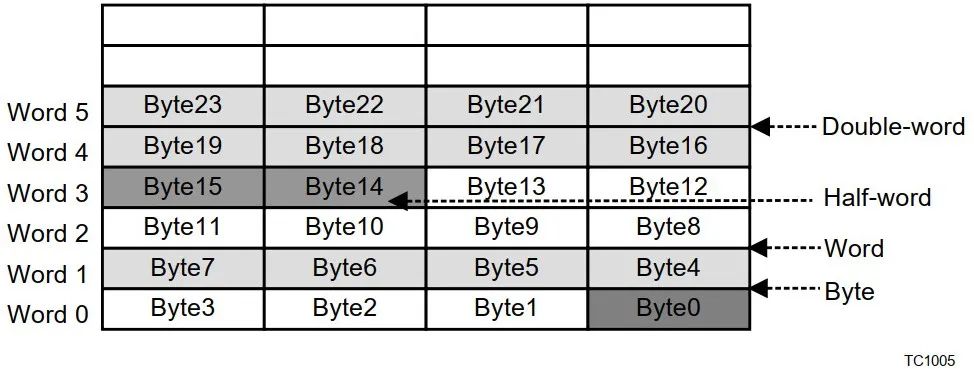

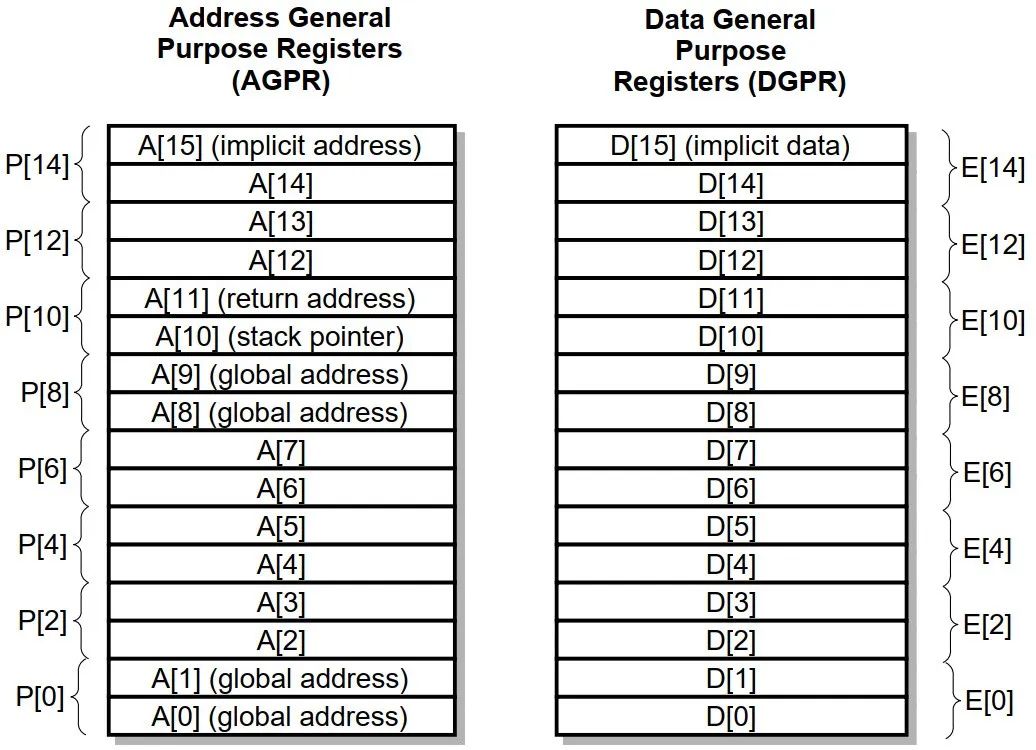
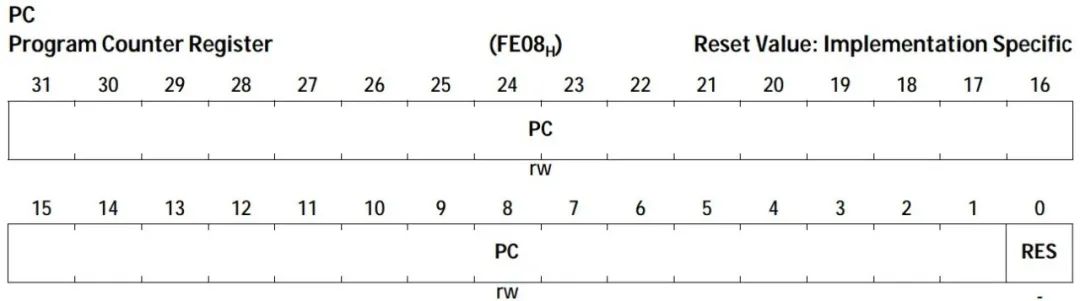


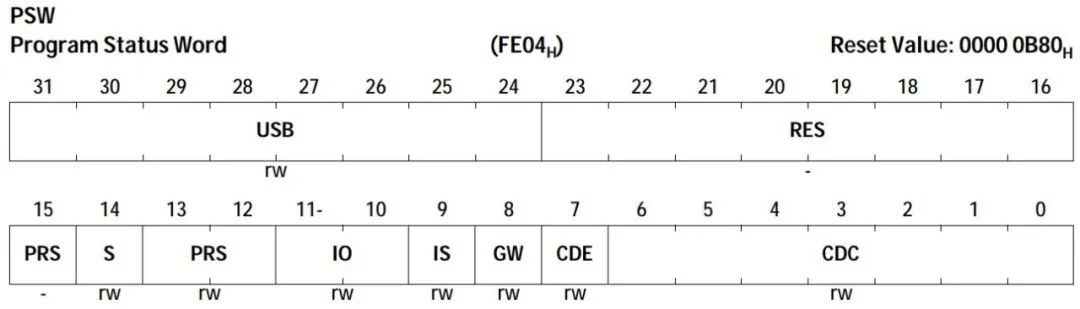

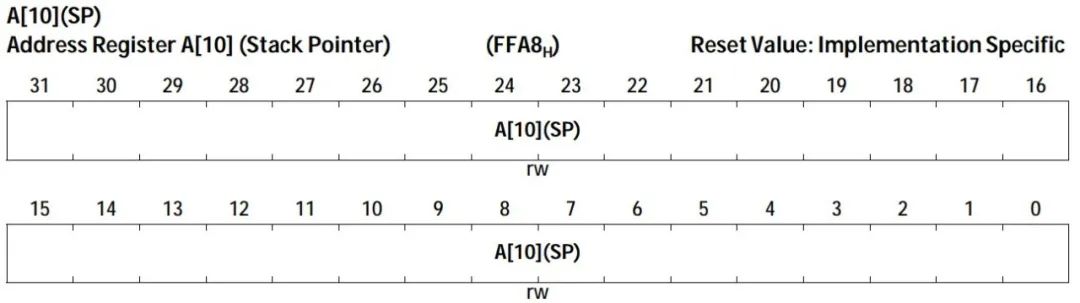


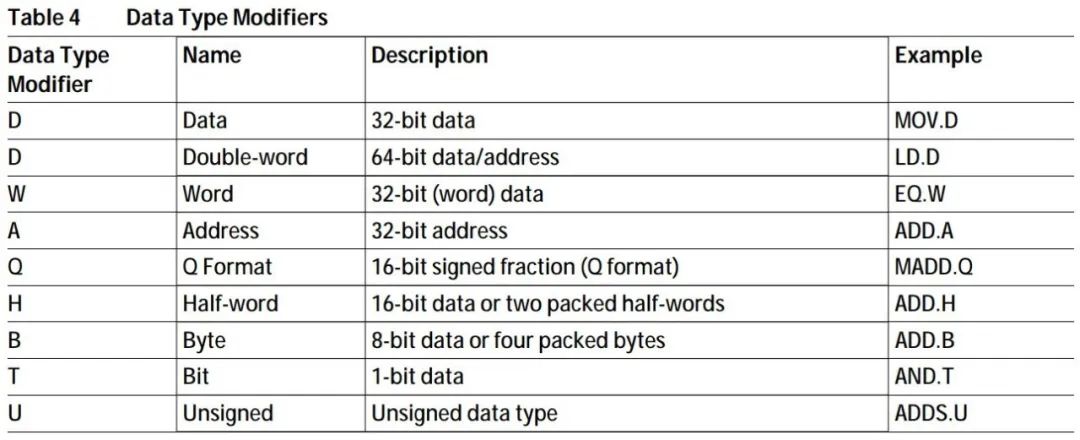




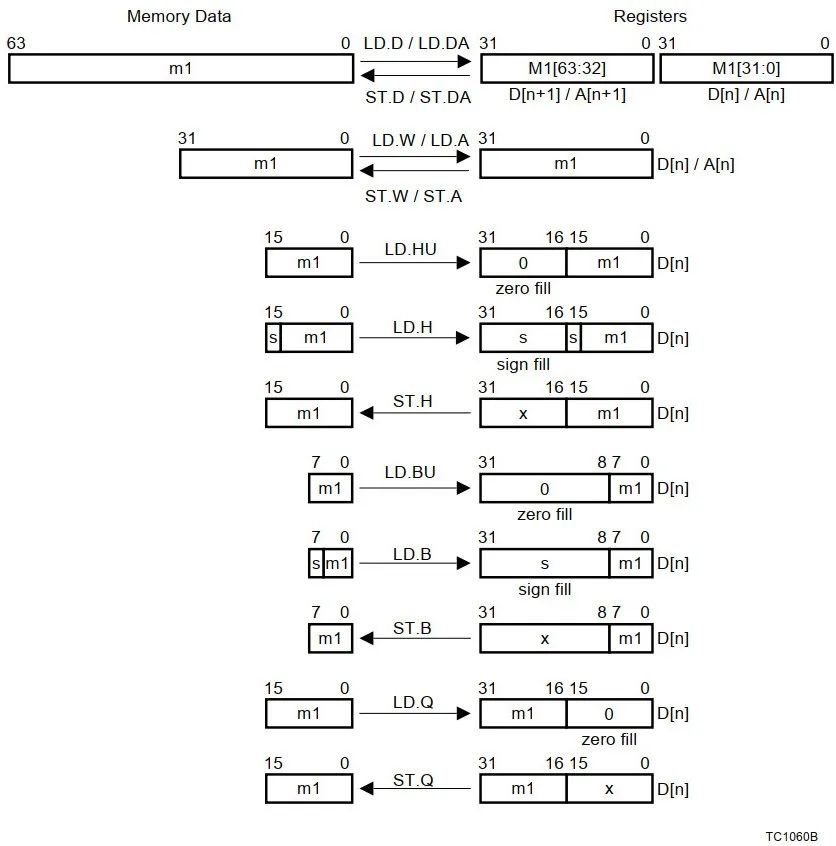
Assembly language LD.A A0, [A15] //将A15指向的内存中的4字节数据,取到A0中,A表示操作数为地址寄存器 LD.BU D5, [A0] //将A0指向的内存中的一字节无符号数据,取到D5中,B表示Byte,1字节,U表示无符号 |
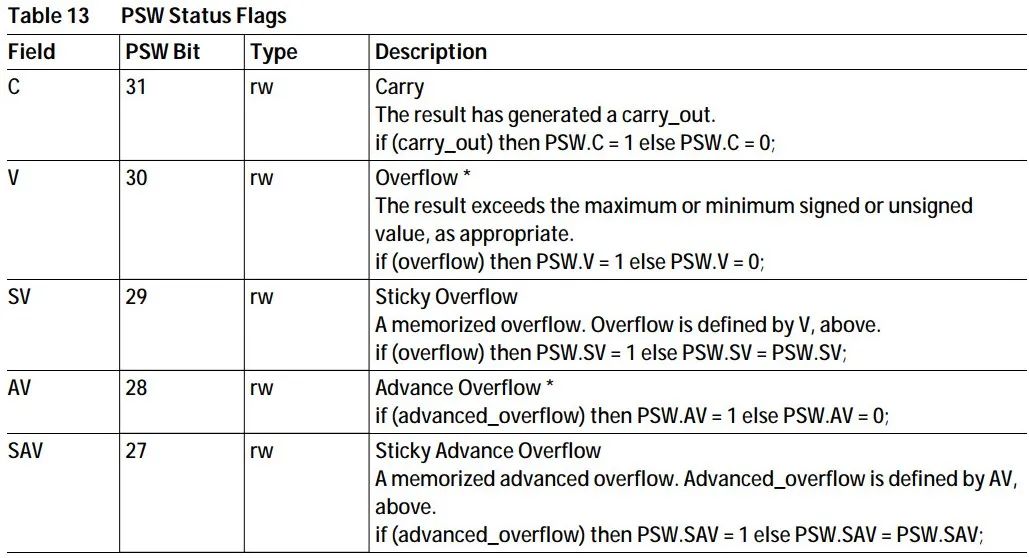
ADD D0, D1, D2 //计算D1+D2的值,结果存到D0中,溢出位舍弃,如255+1=0(uint8) ADD.A A0, A1, A2 //计算地址寄存器A1+A2的值,结果存到A0中,A表示操作数为地址寄存器 ADDX D3, D1, D2 //计算D1+D2的值,结果存到D3中,如果溢出,PSW.C=1,否则PSW.C=0 ADDC D3, D1, D2 //计算D1+D2+PSW.C的值,结果存到D3中,如果溢出,PSW.C=1,否则PSW.C=0 ADDI D3, D1, 858 //计算D1+858的值,结果存到D3中 ADDIH D3, D1, 0x8 //立即数移位加法,计算D1+0x8<<16的值,结果存到D3中,IH表示立即数左移16位 ADDS D3, D1, D2 //计算D1+D2的值,如果溢出则做饱和运算处理,结果存放到D3中 ADDS.U D3, D1, D2 //计算无符号D1+D2的值,如果溢出则做饱和运算处理,结果存放到D3中 |
MUL D3, D1, D2 //计算D1*D2的值,溢出位舍弃,结果存放到D3中 MULS D2, D1, D2 //计算D1*D2的值,溢出则做饱和运算处理,结果存放到D3中 MUL.U E0, D1, D2 //计算无符号D1*D2的值,结果存放到E0(D1+D2)中 |
DIV E[c], D[a], D[b] //计算D[a]/D[b],商存放到E[c][31:0],余数存放到E[c][63:32]中 dividend = D[a]; divisor = D[b]; if (divisor == 0) then { if (dividend >= 0) then { quotient = 0x7fffffff; remainder = 0x00000000; } else { quotient = 0x80000000; remainder = 0x00000000; } } else if ((divisor == 0xffffffff) AND (dividend == 0x80000000)) then { quotient = 0x7fffffff; remainder = 0x00000000; } else { remainder = dividend % divisor quotient = (dividend - remainder)/divisor } E[c][31:0] = quotient; E[c][63:32] = remainder; |
DIV.U E[c], D[a], D[b] //计算无符号D[a]/D[b],商存放到E[c][31:0],余数存放到E[c][63:32]中,U表示无符号 dividend = D[a]; divisor = D[b]; if (divisor == 0) then { quotient = 0xffffffff; remainder = 0x00000000; } else { remainder = dividend % divisor quotient = (dividend - remainder)/divisor } E[c][31:0] = quotient; E[c][63:32] = remainder; |
Assembly language DIV.F D3, D1, D2 //计算浮点数D1/D2的值,结果存放到D3中 |
Assembly language |
Assembly language MIN D3, D1, D2 //比较D1和D2的大小,将较小的存放到D3中 MAX D3, D1, D2 //比较D1和D2的大小,将较大的存放到D3中 |
Assembly language CADD D4, D1, D2, D3 //如果D1非零,则D4=D2+D3,否则D4=D2 CADDN D4, D1, D2, 8 //如果D1为零,则D4=D2+8,否则D4=D2 CSUB D4, D1, D2, D3 //如果D1非零,则D4=D2-D3,否则D4=D2 SEL D4, D1, D2, D3 //如果D1非零,则D4=D2,否则D4=D3 |
Assembly language |
Assembly language |
Assembly language |
Assembly language |
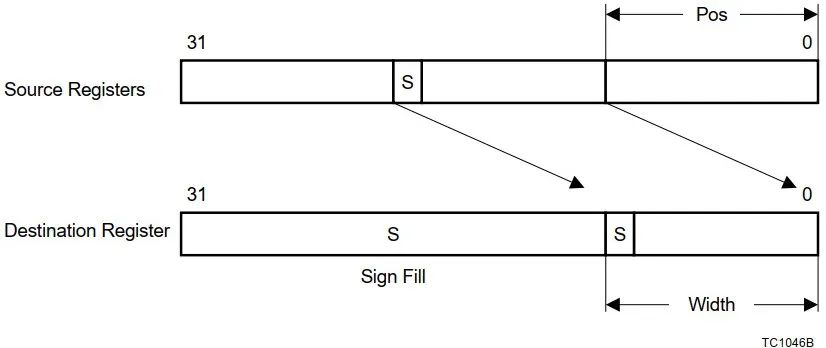
Assembly language |
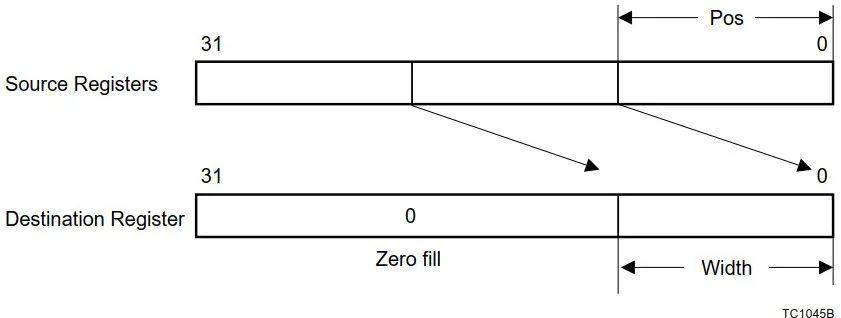
Assembly language |
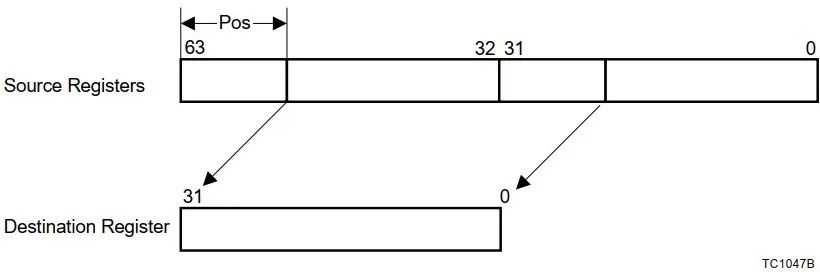
Assembly language |
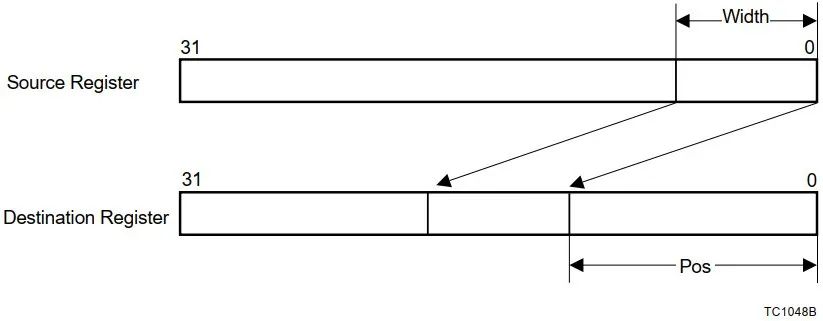
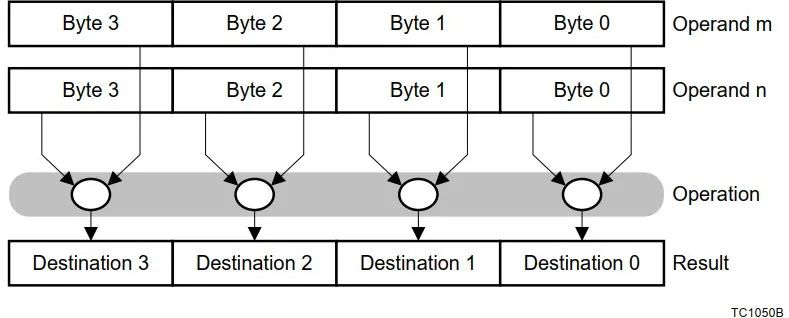
Assembly language |
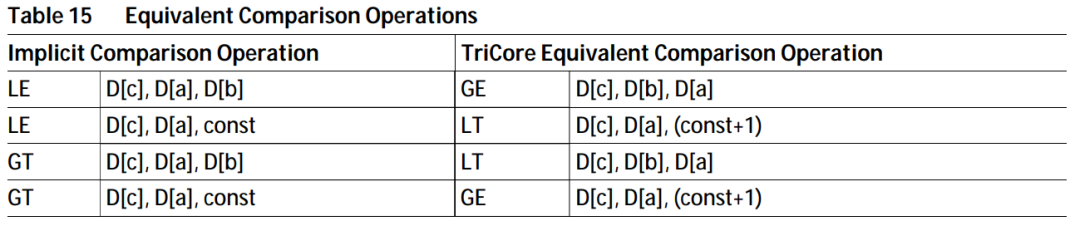
Assembly language LT D3, D1, D2 //D3 = (D1 GE D3, D1, D2 //D3 = (D1>=D2) |
Assembly language |
Assembly language JL foobar //将下一条指令地址写入到返回地址寄存器中,并跳转到foobar CALL foobar //保存高上下文,将下一条指令地址写入到返回地址寄存器中,跳转到foobar |
Assembly language |
Assembly language |
Assembly language |
Assembly language |
Assembly language |
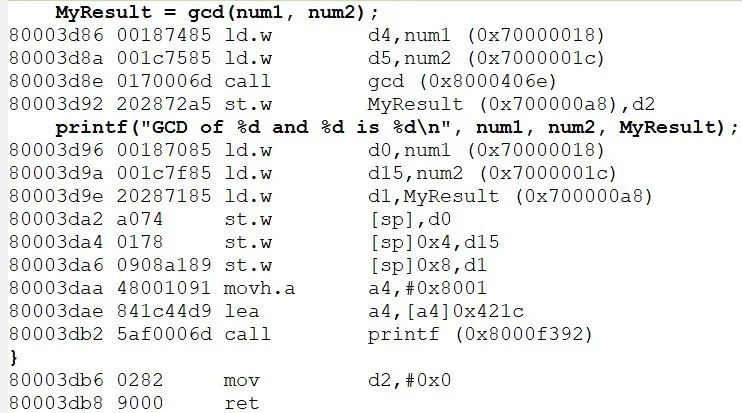
C volatile int num1=15, num2=20; //volatile防止编译器优化 |