

 点击上方蓝字关注我们
点击上方蓝字关注我们
微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
OLLama安装
安装Ollama工具,下载地址如下:
https://github.com/ollama/ollama下载与运行llama3大语言对话模型
ollama run llama3.2下载与运行llama-vision3.2多模态视觉大模型
ollama run llama3.2-vision下载与运行llava多模态视觉大模型
ollama run llava运行Ollama支持的模型
使用llama-vision3.2 多模态模型的命令行如下:
ollama run llama3.2-vision命令行使用llama3.2-vision多模态大模型格式如下:
>>>What's in this image? /your_test_image.png亲测发现不支持bmp格式图像,支持jpg跟png。
使用llama3.2-vision多模态实现OCR识别
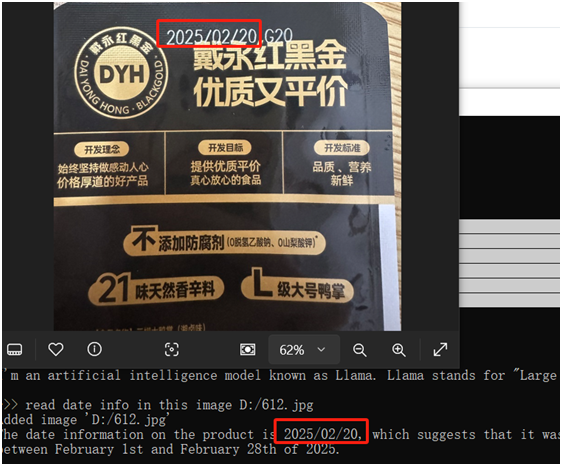
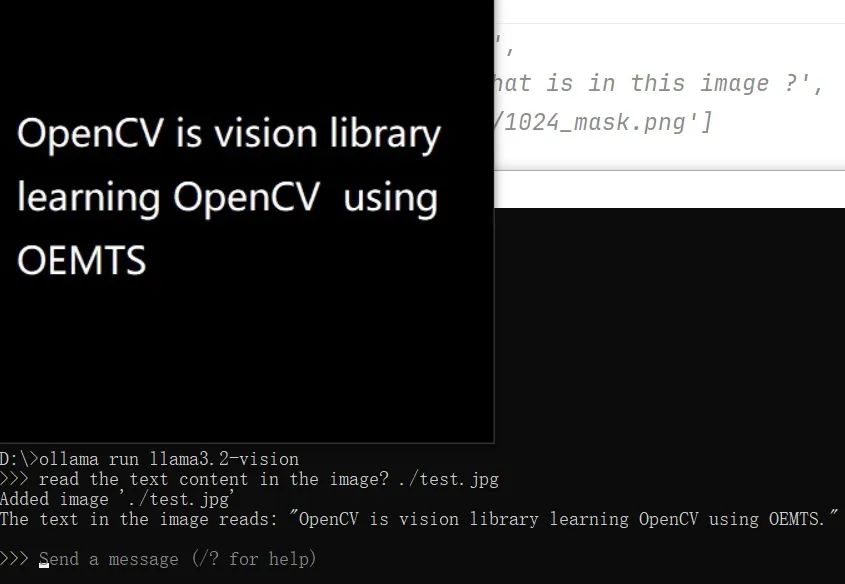
亲测证实对英文跟日期数字等信息识别准确率都非常好,就是识别中文容易翻车,各种错误,也许是因为我用的这个模型只有7B的原因。
使用llama3.2-vision多模态实现图像分类与描述
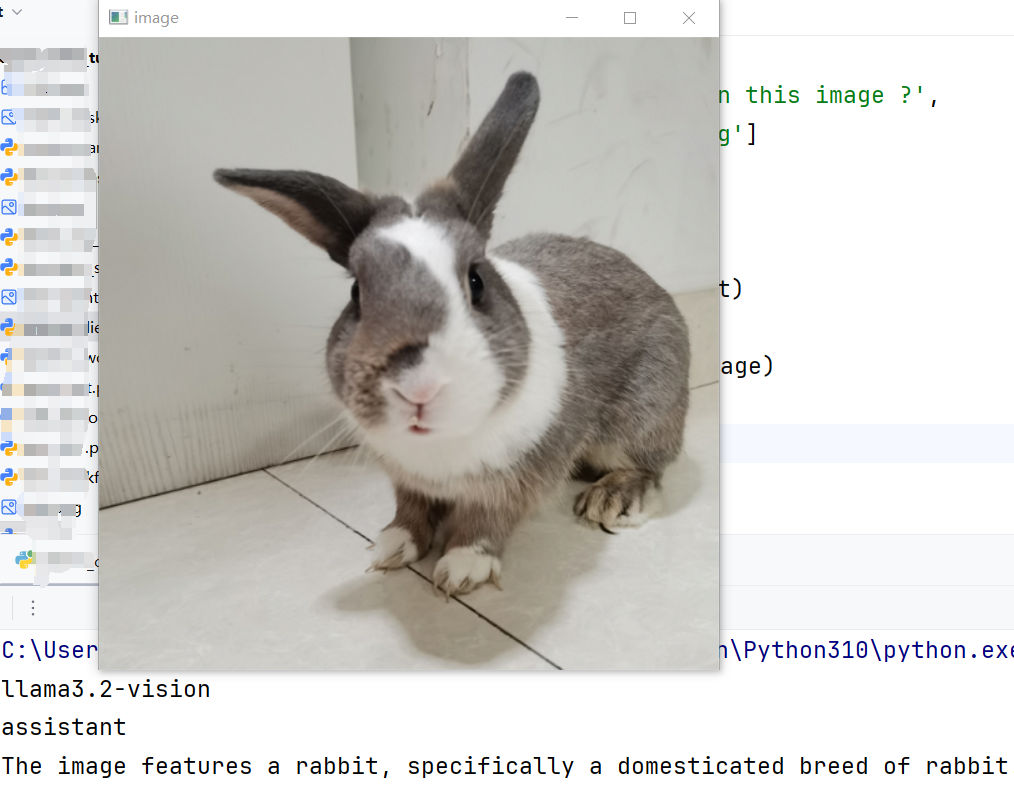
非常准确的给出了图像分类是兔子,而且还给出来一段非常详细的描述英文:
The rabbit has a distinctive grey and white coat pattern, with large ears that are perked up as if listening to something. Its eyes are dark brown, and its nose is pink. The rabbit appears to be sitting on a tiled floor, possibly in a home or pet store setting.
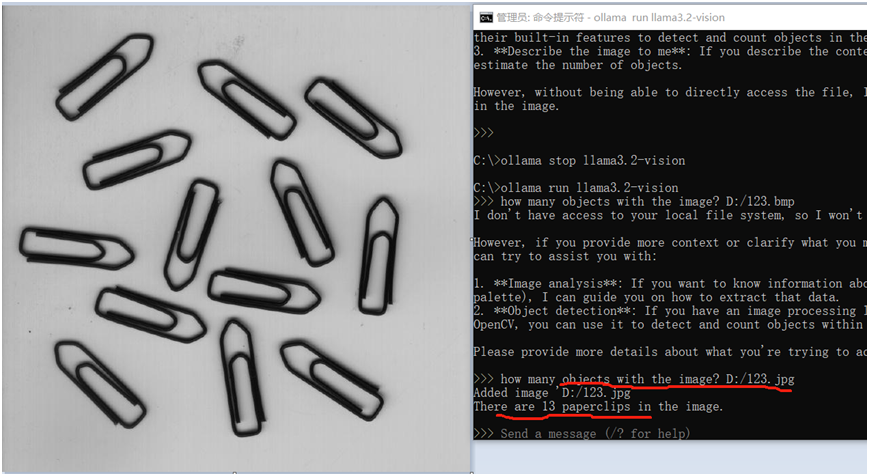
使用llama3.2-vision多模态实现对象计数
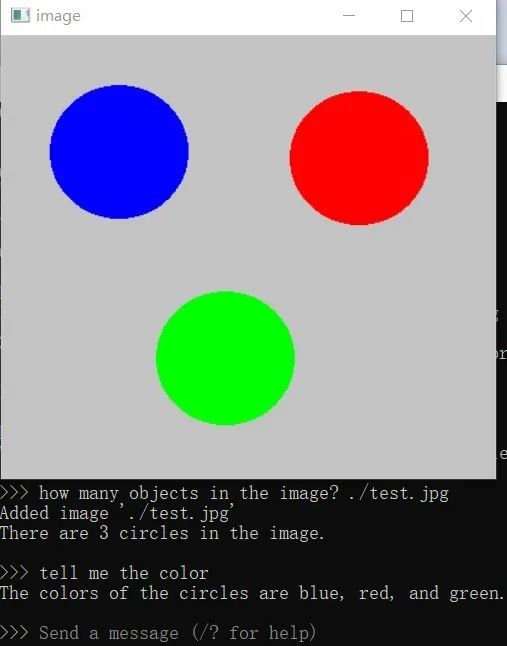
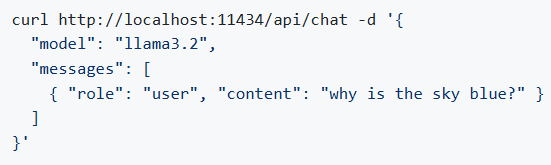
SDK API调用
启动Ollama Server以后,运行客户端API SDK 说明如下:
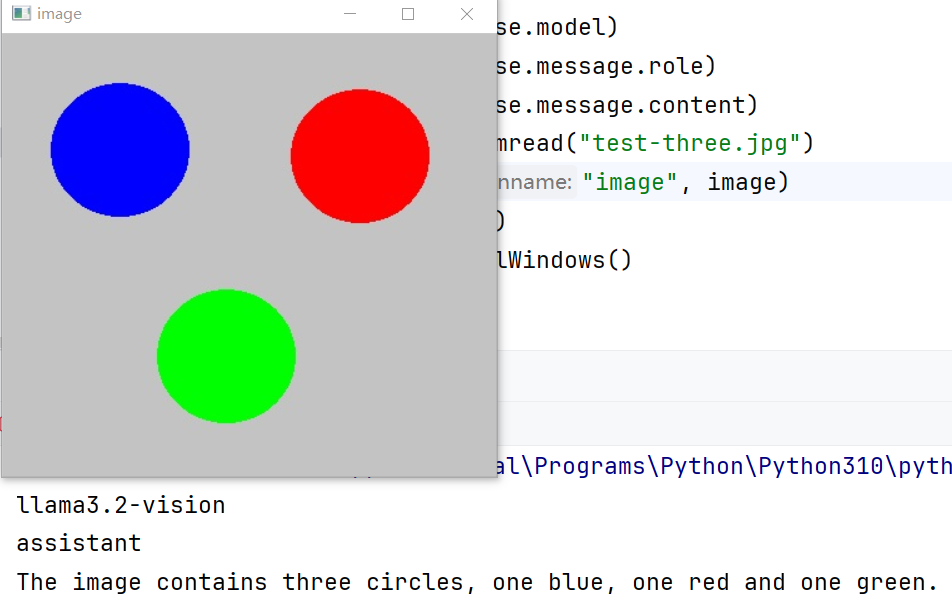
Python代码实现调用以后输出

原价:398
折扣:299
推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
总结 | OpenCV4 Mat操作全接触
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
YOLOv8 OBB实现自定义旋转对象检测
初学者必看 | 学习深度学习的五个误区
YOLOv8自定义数据集训练实现安全帽检测

