2025年伊始,DeepSeek的惊艳登场再次刷新了大众对AI技术的认知边界。随着其迅速走红,越来越多的AI芯片厂商纷纷宣布适配DeepSeek,展现出这一新兴技术的强大潜力和吸引力。作为一名电子工程师,您是否已经抢先完成了DeepSeek的本地部署?如果您还在摸索阶段,不妨参考一下EEWorld论坛上众多网友分享的宝贵经验。 Raspberry Pi 5 ——本地部署DeepSeek-R1大模型 原文链接:https://www.eeworld.com.cn/aTmbD4S 一、DeepSeek简介 1.1 发展历程 DeepSeek是由中国深度求索公司开发的开源大语言模型系列,其研发始于2023年,目标是为学术界和产业界提供高效可控的AI基础设施。R1系列作为其里程碑版本,通过稀疏化架构和动态计算分配技术,在保持模型性能的同时显著降低了计算资源需求。 1.2 模型特点 参数规模灵活:提供1.5B/7B/33B等多种规格
混合精度训练:支持FP16/INT8/INT4量化部署
上下文感知优化:动态分配计算资源至关键token
中文优化:在Wudao Corpus等中文数据集上强化训练
1.3 技术突破 相比传统LLM,DeepSeek-R1通过以下创新实现低资源部署: MoE架构:专家混合层动态路由计算路径
梯度稀疏化:反向传播时仅更新关键参数
自适应量化:运行时根据硬件自动选择最优精度
二、ollama简介 2.1 软件简介 Ollama是一个获取和运行大语言模型的工具,官网的简介是: Get up and running with large language models. 2.2 主要功能 下载大语言模型;
运行大语言模型;
基本上可以归纳为两类功能:
模型文件管理:下载(pull)、创建(create)、删除(rm)、拷贝(cp)、查看(list)、上传(push)、查看模型信息(show)
模型运行管理:运行(run)、启动(serve)、停止(stop)、查看正在运行的模型(ps)
跨平台支持(Linux/Windows/macOS);
支持NIVIDA/AMD GPU加速,如有相应GPU推理速度快;
使用简单,安装软件、下载模型、运行模型均只需要一条命令
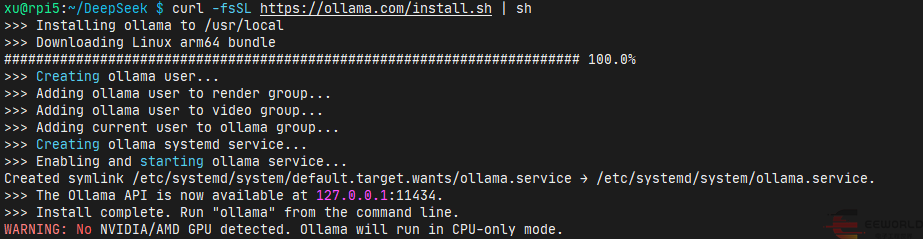
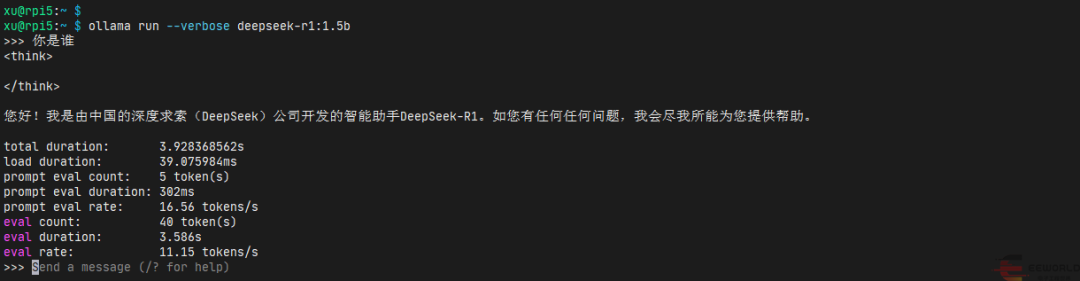
三、安装ollama 安装ollama非常简单,官网提供了在线安装脚本(install.sh)。 在树莓派5上,使用如下命令即可下载在线安装脚本并运行: curl -fsSL https://ollama.com/install.sh | sh 四、下载deepseek-r1:1.5b模型 安装好了ollama之后,我们就可以使用ollama下载deepseek-r1:1.5b模型了,使用如下命令: ollama pull deepseek-r1:1.5b 五、运行deepseek-r1:1.5b模型 下载好了deepseek-r1:1.5b模型之后,我们就可以使用ollama运行deepseek-r1:1.5b模型了,使用如下命令: ollama run deepseek-r1:1.5b 直接运行也可以,该命令会下载模型,再运行,非常方便! >>> 用Python写一个快速排序的函数,实现对包含整数的列表进行排序 ```python total duration: 1m16.264529746s 看起来好像没啥问题,速度还行,达到了10 token/s。 但是,更复杂一点的问题,deepseek-r1:1.5b模型就回答不了了,比如: >>> 水浒传中有多少个梁山好汉? 这次的输出就是在胡说了,模型太小了,考虑里面没有相关的信息。PS:而且每次同样这个问题,提问之后回答的还不一样。 原文链接:https://www.eeworld.com.cn/aePmPm1 在RDK X3上利用ollama部署deepseek 看似本地部署deepseek很简单,实际因为网络问题,部署起来还是非常麻烦的。在这里给出我摸索出来的方法,在RDK X3上利用ollama部署deepseek,分发ip,使用chatbox同一局域网即可使用deepseek,获得更好的体验 确认系统信息
查找输出中的“Architecture”字段来确定是x86_64(适用于AMD/Intel 64位处理器)还是aarch64/arm64(适用于ARM架构64位处理器)。 根据你的CPU架构从GitHub的release下载对应的.tgz安装包。 对于aarch64/arm64架构,则下载ollama-linux-arm64.tgz。 确保你已经将下载好的.tgz文件传输到了目标Linux服务器上。在vscode上直接拖动即可 sudo tar -C /usr -xzf ollama - linux - amd64.tgz -C /usr指定了解压的目标目录,可根据实际情况调整路径。 这会在后台启动Ollama服务,准备好接收请求并管理模型。 为了确保Ollama已成功安装并正在运行,执行以下命令来列出所有可用的模型: 如果一切正常,你应该能看到已下载模型的列表。如果没有下载任何模型,该命令不会返回错误,只会显示一个空列表。 有时需要根据实际需求更改模型文件的存储路径。以下是详细步骤。 关闭Ollama服务
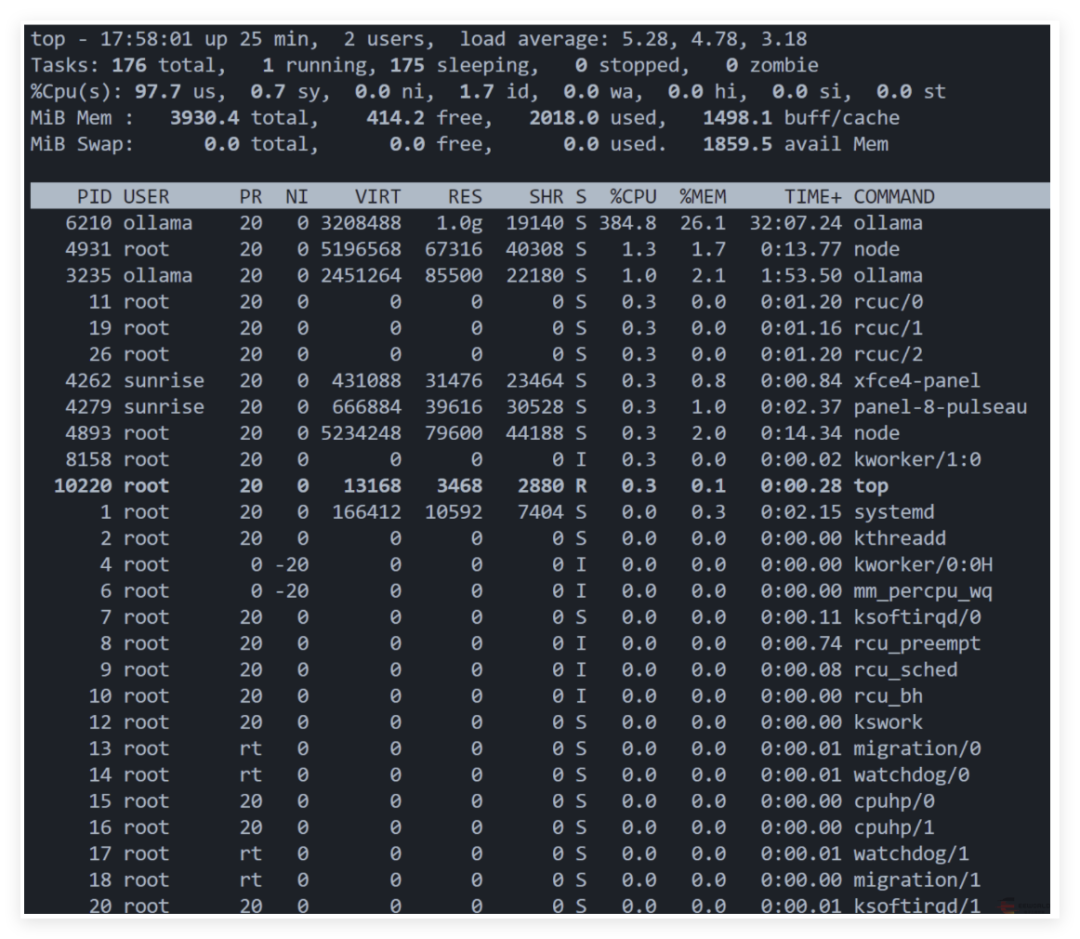
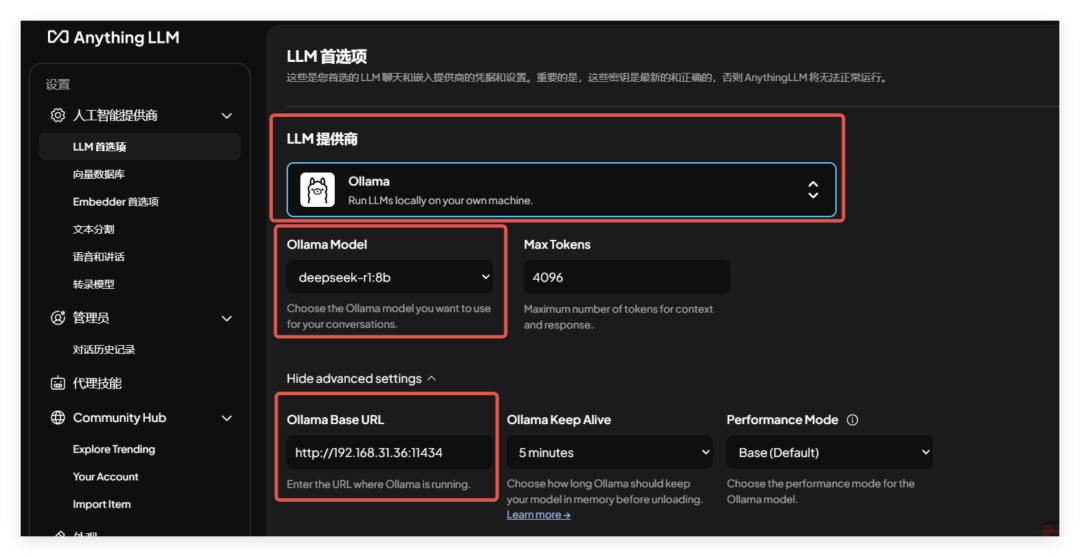
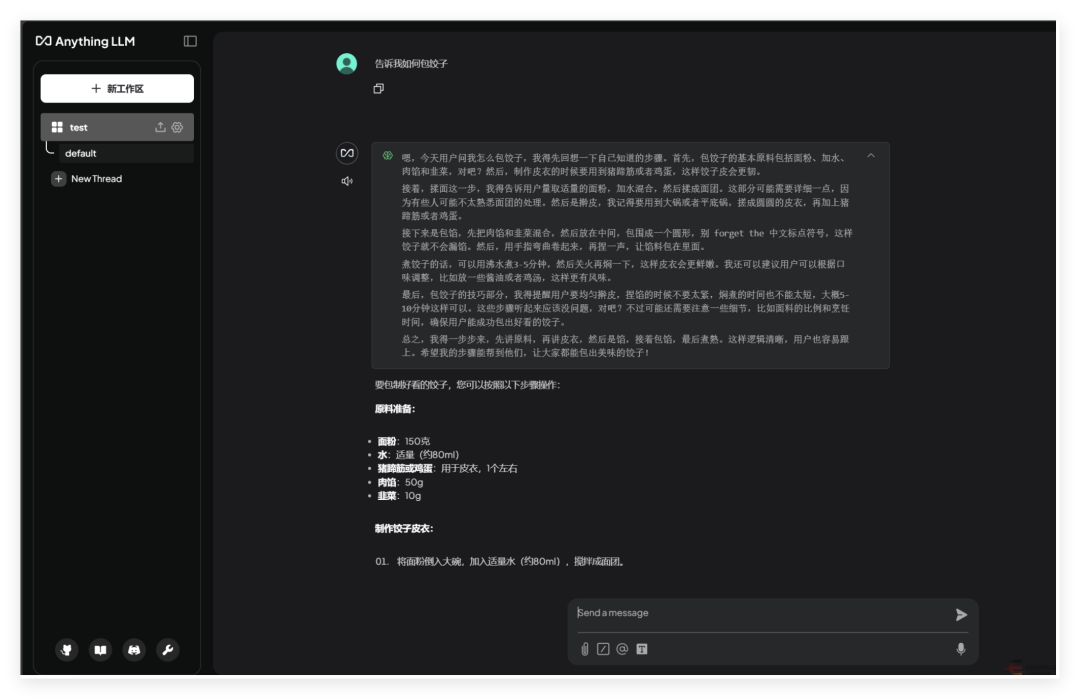
在更改模型路径之前,需先停止当前运行的Ollama服务。 sudo systemctl stop ollama sudo systemctl disable ollama.service 默认情况下,Ollama会在 /usr/share/ollama/.ollama/models 存储模型文件。 首先,创建一个新的目录作为模型存储路径。例如,创建 /data/ollama/models 目录: sudo mkdir -p /data/ollama/models 确保新目录的权限设置正确,允许Ollama访问和写入: sudo chown -R root:root /data/ollama/models sudo chmod -R 777 /data/ollama/models 注意:这里的用户和组 (root:root) 应根据实际情况调整为运行Ollama服务的实际用户和组。 假设Ollama是通过systemd管理的服务,你需要编辑相应的服务配置文件来指定新的模型路径。 sudo gedit /etc/systemd/system/ollama.service sudo vim /etc/systemd/system/ollama.service Description = Ollama Service After = network - online.target ExecStart = /usr/local/bin/ollama serve Environment = "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" Environment = "OLLAMA_MODELS=/data/ollama/models" WantedBy = default.target sudo systemctl daemon - reload sudo systemctl restart ollama.service sudo systemctl status ollama 三、使用Ollama加载ModelScope上的GGUF模型 Ollama支持加载托管在ModelScope社区上的模型,魔搭社区是国内的,所以拉取模型速度快更快。ollama默认是拉取huggingface上的,速度比较慢。 GGUF代表量化后的模型,根据RDK X3的性能选择,选择合适的量化模型,这里我使用Q2_K的,测试能做到一秒两三个字。 https://www.modelscope.cn/docs/models/advanced-usage/ollama-integration ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf 出现以上样式,说明模型在运行,通过top可以观察CPU使用率 Jetson 利用 Ollama + Anything LLM 部署 Deepseek、LLama3 原文链接:https://www.eeworld.com.cn/a0if5m1 git clone https://github.com/dusty-nv/jetson-containersbash jetson-containers/install.sh jetson-containers run --name ollama $(autotag ollama) ollama run deepseek-r1:1.5b ollama run deepseek-r1:8b ollama run deepseek-r1:8b -verbose ollama list 输出解释 total duration: 3m31.258084877s load duration : 29.482802 msprompt eval count : 34 token(s)prompt eval duration : 622 msprompt eval rate: 54.66 tokens/seval count : 1417 token(s) eval duration : 3 m30.603 s eval rate: 6.73 tokens/s “prompt eval rate(提示评估速率)” 指的是在对输入的提示(prompt)进行评估处理时,模型每秒能够处理的tokens数量。提示通常是用户输入给模型的文本内容,用于引导模型生成特定的输出,prompt eval rate主要衡量的是模型处理初始输入提示部分的速度和效率。 是模型在整体评估过程中,每秒处理tokens的数量。这里的评估过程不仅仅包括对输入提示的处理,还涵盖了模型根据提示进行推理、计算、生成等一系列操作的整个过程,它反映的是模型在完整的任务执行过程中的综合处理速度。 部署Anything LLM容器 export STORAGE_LOCATION=/opt/anythingllm sudo mkdir -p $STORAGE_LOCATION sudo chmod 777 -R $STORAGE_LOCATION touch "$STORAGE_LOCATION/.env" sudo docker run -it --rm -p 3001 : 3001 --cap-add SYS_ADMIN -v ${STORAGE_LOCATION}:/app/server/storage -v ${STORAGE_LOCATION}/.env: /app/server/.env -e STORAGE_DIR="/app/server/storage" ghcr.io/mintplex-labs/anything-llm
欢迎将我们设为“ 星标 ”,这样才能第一时间收到推送消息。 关注EEWorld 旗下订阅号:“机器人开发圈”
回复“ DS ”领取《DeepSeek:从入门到精通》完整版