


导读
01
02
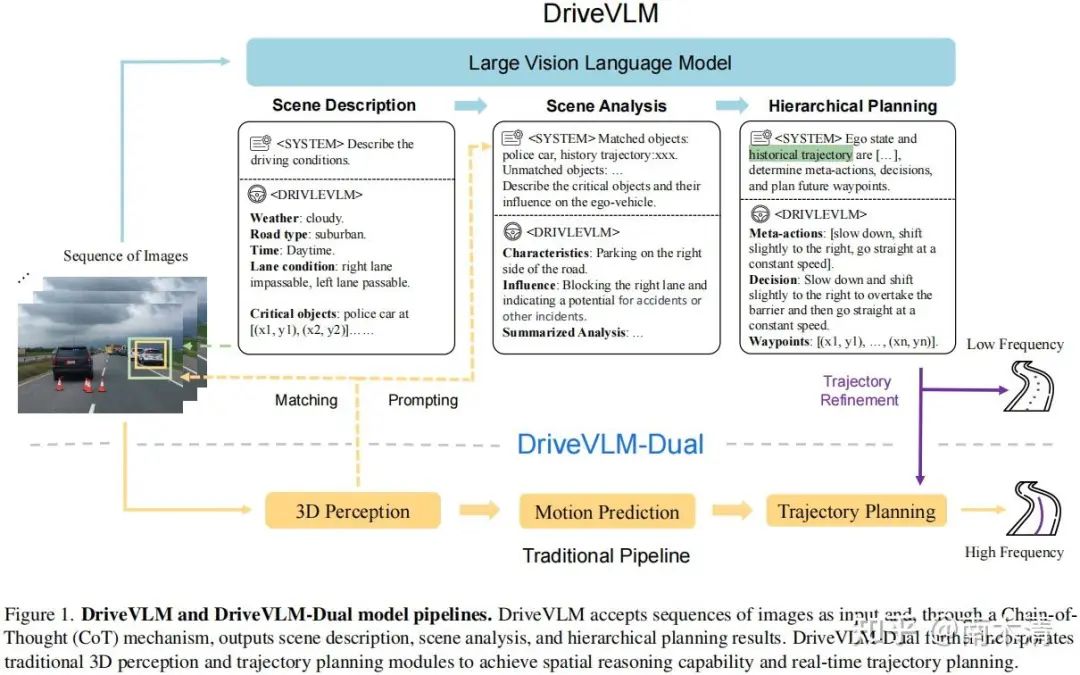
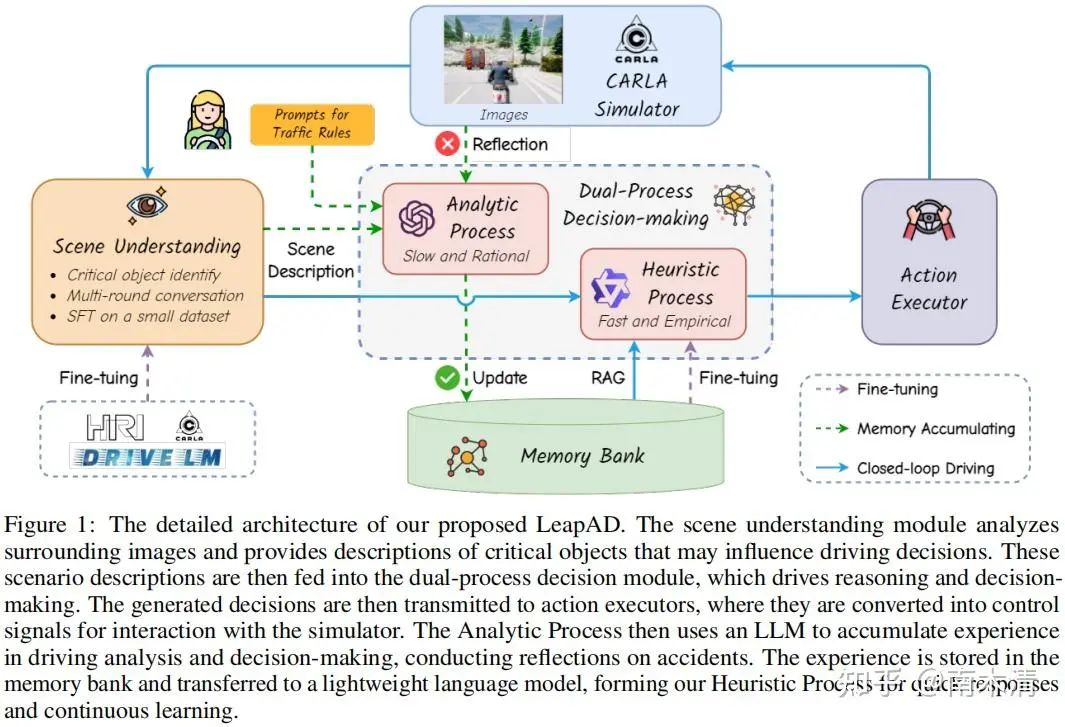
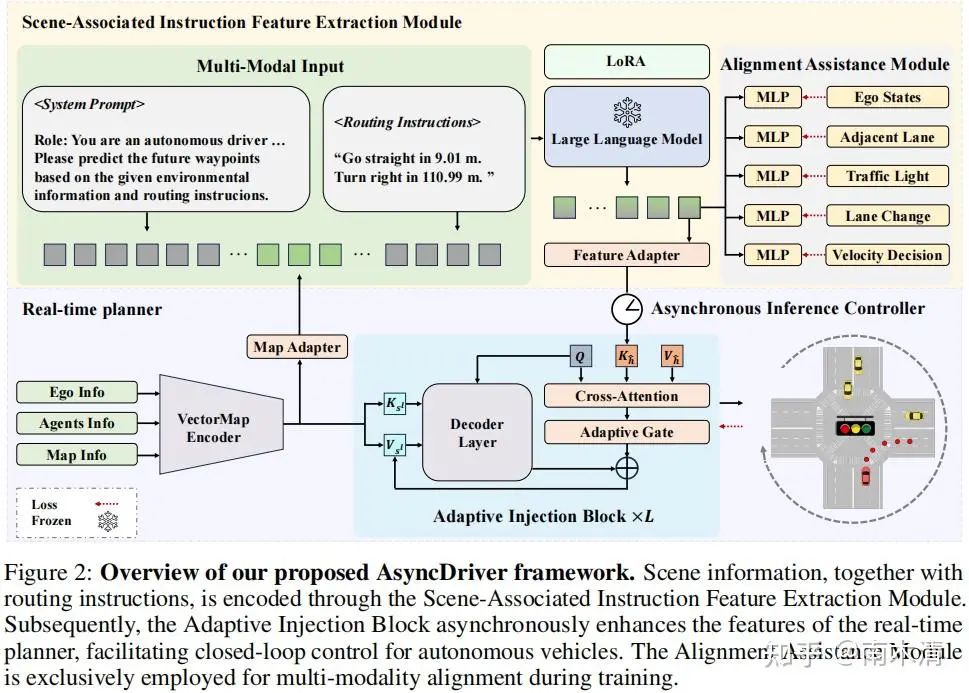

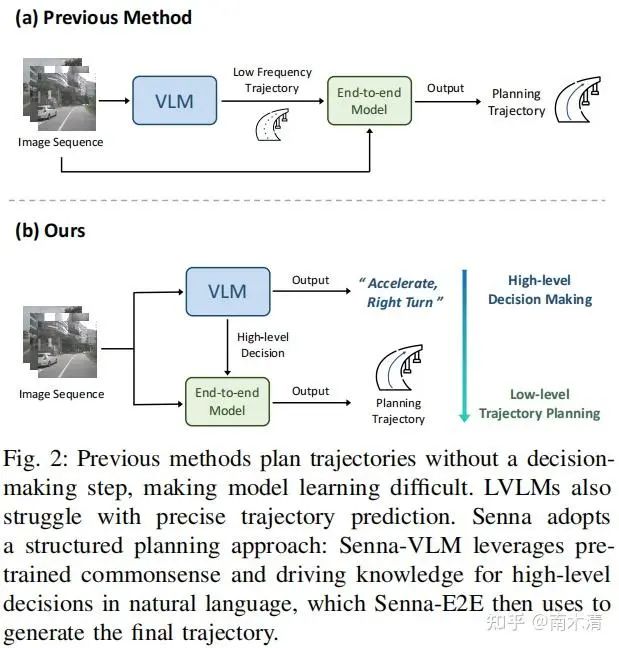
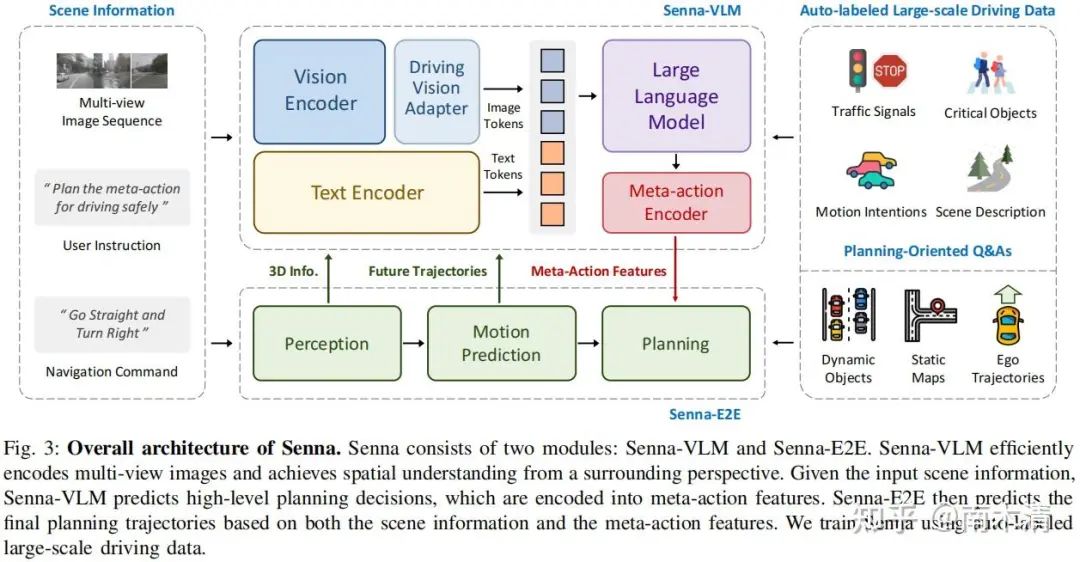
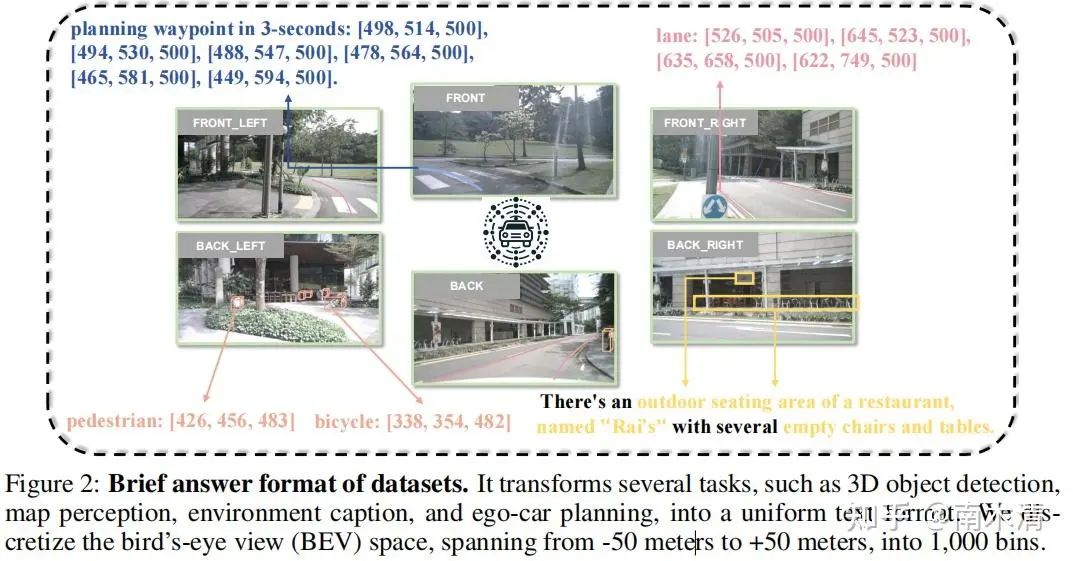
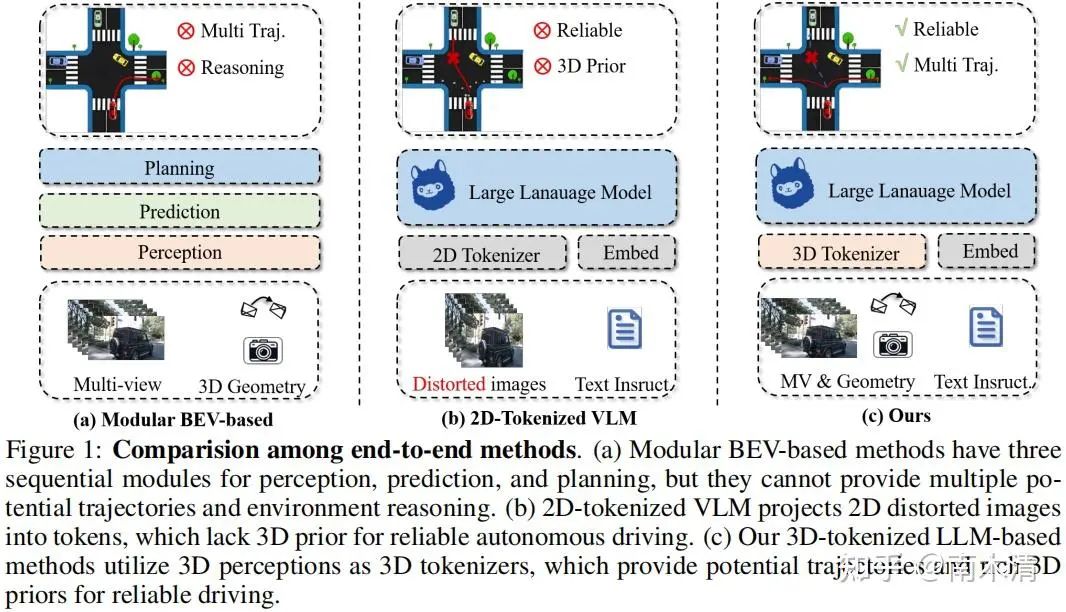

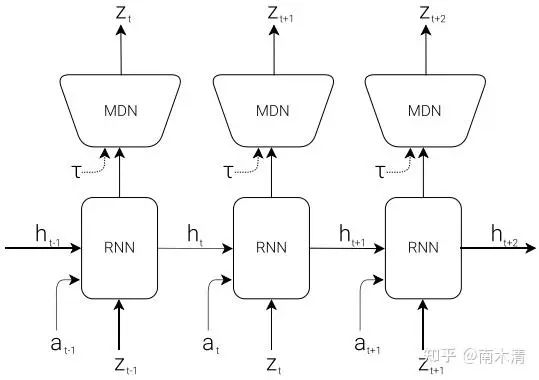

03

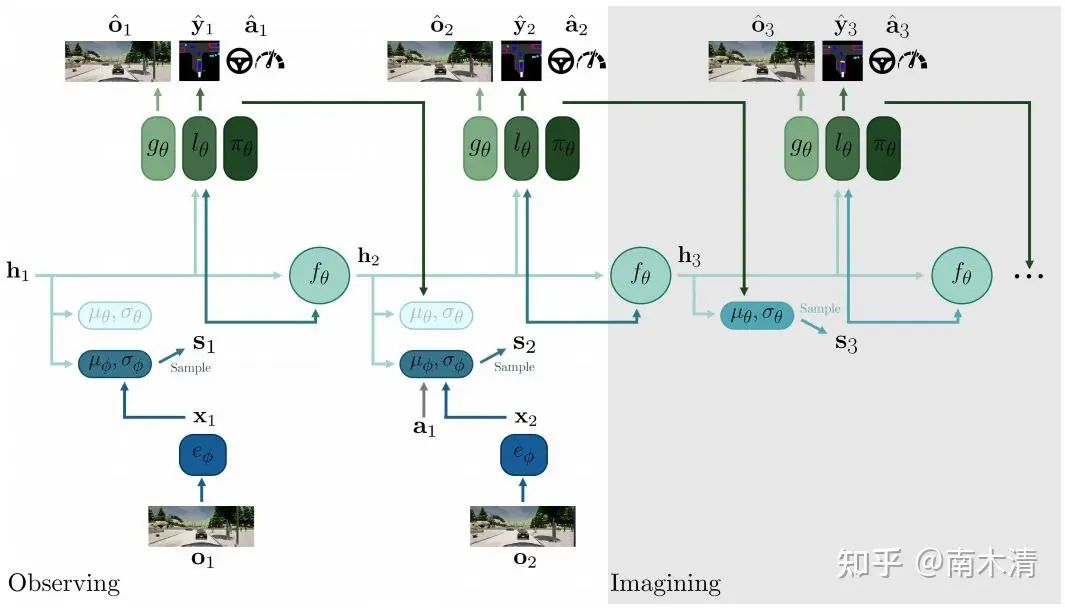
(mile) Hu A, Corrado G, Griffiths N, et al. Model-based imitation learning for urban driving[J]. Advances in Neural Information Processing Systems, 2022, 35: 20703-20716.
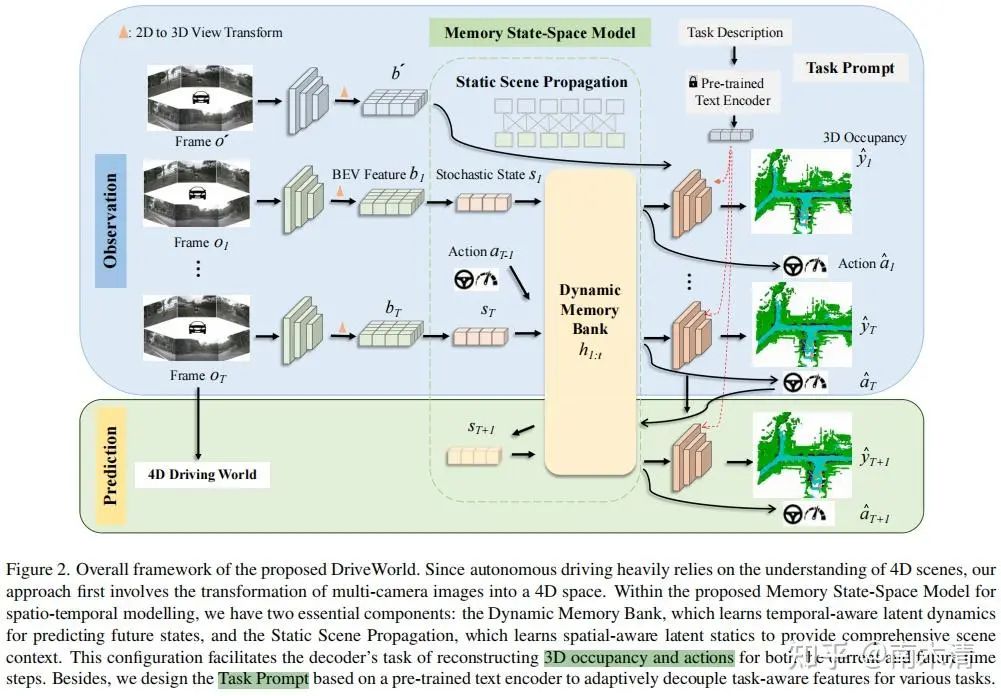
(Driveworld) Min C, Zhao D, Xiao L, et al. Driveworld: 4d pre-trained scene understanding via world models for autonomous driving[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 15522-15533.
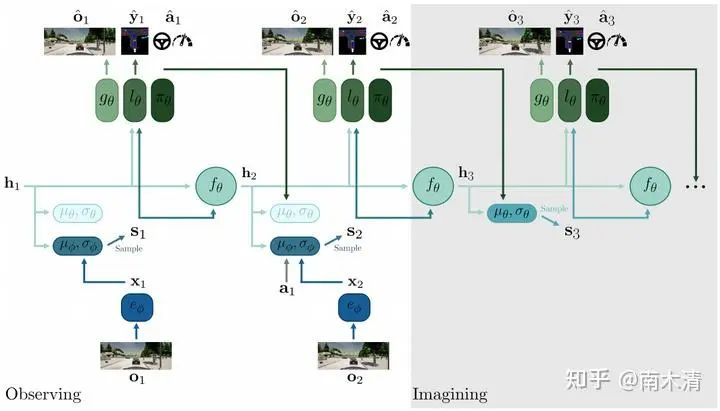
(Dreamer-v1) Hafner D, Lillicrap T, Ba J, et al. Dream to control: Learning behaviors by latent imagination[J]. arXiv preprint arXiv:1912.01603, 2019.
(Dreamer-v2) Hafner D, Lillicrap T, Norouzi M, et al. Mastering atari with discrete world models[J]. arXiv preprint arXiv:2010.02193, 2020.
(SEM2) Gao Z, Mu Y, Chen C, et al. Enhance sample efficiency and robustness of end-to-end urban autonomous driving via semantic masked world model[J]. IEEE Transactions on Intelligent Transportation Systems, 2024.
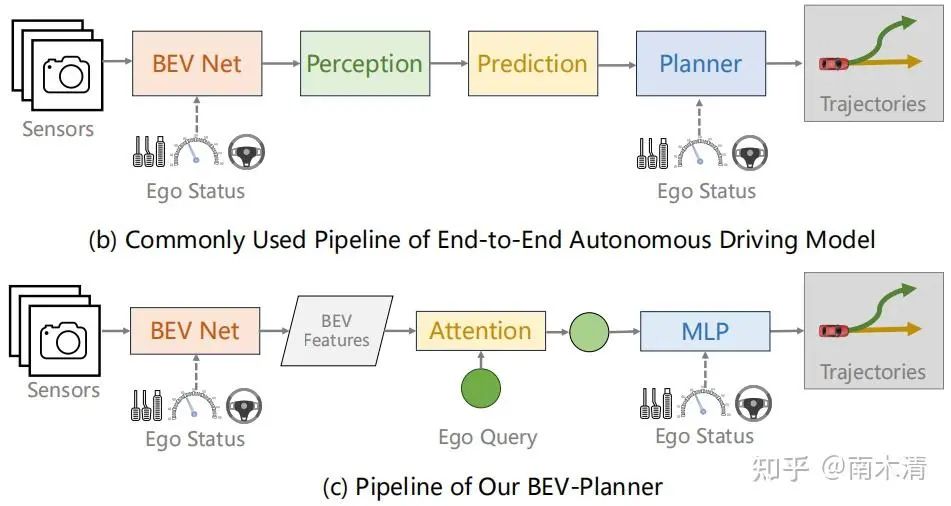
(BevPlanner) Li Z, Yu Z, Lan S, et al. Is ego status all you need for open-loop end-to-end autonomous driving?[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 14864-14873.
(TransFuser) Chitta K, Prakash A, Jaeger B, et al. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(11): 12878-12895.
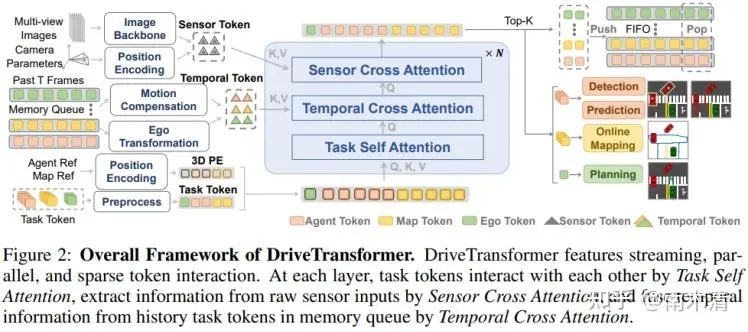
(DriveTransformer) https://openreview.net/pdf?id=M42KR4W9P5
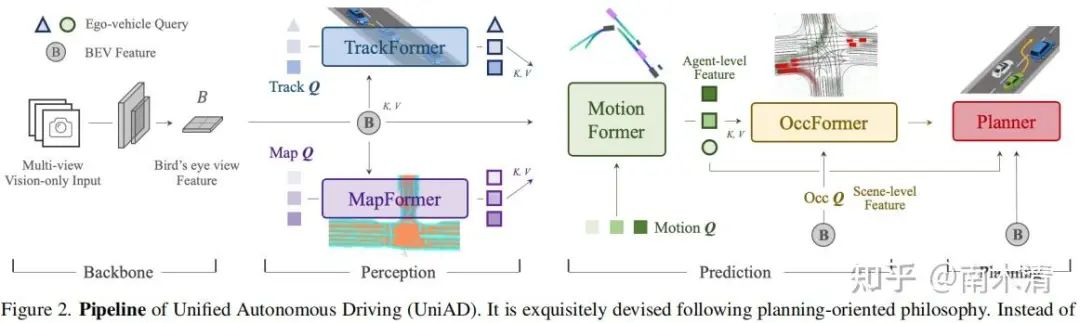
(UniAD) Hu Y, Yang J, Chen L, et al. Planning-oriented autonomous driving[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 17853-17862.
(FusionAD) Ye T, Jing W, Hu C, et al. Fusionad: Multi-modality fusion for prediction and planning tasks of autonomous driving[J]. arXiv preprint arXiv:2308.01006, 2023.
(VAD) Jiang B, Chen S, Xu Q, et al. Vad: Vectorized scene representation for efficient autonomous driving[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 8340-8350.
(GenAD) Zheng W, Song R, Guo X, et al. Genad: Generative end-to-end autonomous driving[C]//European Conference on Computer Vision. Springer, Cham, 2025: 87-104.
(Drive like a human) Fu D, Li X, Wen L, et al. Drive like a human: Rethinking autonomous driving with large language models[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024: 910-919.
(DriveGPT4) Xu Z, Zhang Y, Xie E, et al. Drivegpt4: Interpretable end-to-end autonomous driving via large language model[J]. IEEE Robotics and Automation Letters, 2024.
(LMDrive) Shao H, Hu Y, Wang L, et al. Lmdrive: Closed-loop end-to-end driving with large language models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 15120-15130.
(EMMA) Hwang J J, Xu R, Lin H, et al. Emma: End-to-end multimodal model for autonomous driving[J]. arXiv preprint arXiv:2410.23262, 2024.
(Senna) Jiang B, Chen S, Liao B, et al. Senna: Bridging large vision-language models and end-to-end autonomous driving[J]. arXiv preprint arXiv:2410.22313, 2024.
(World Models) Ha D, Schmidhuber J. World models[J]. arXiv preprint arXiv:1803.10122, 2018.
(Gaia-1) Hu A, Russell L, Yeo H, et al. Gaia-1: A generative world model for autonomous driving[J]. arXiv preprint arXiv:2309.17080, 2023.
(DriveWM) Wang Y, He J, Fan L, et al. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 14749-14759.
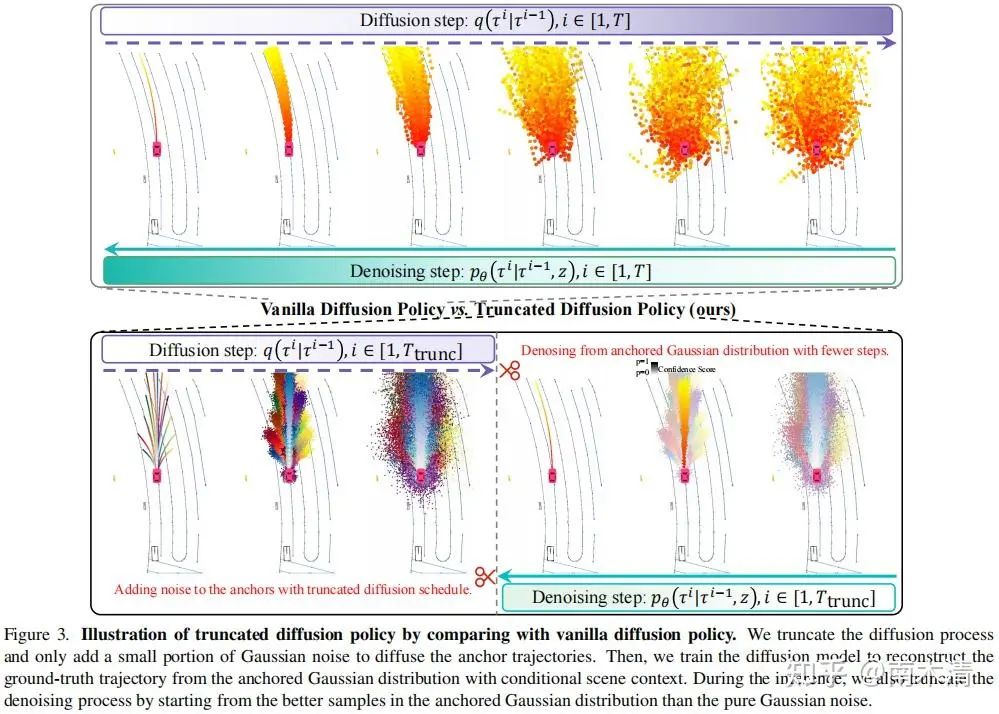
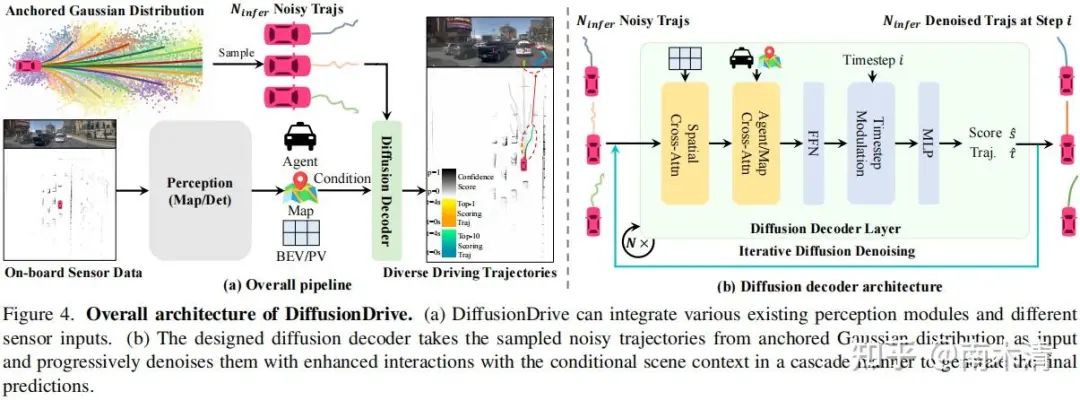
(DiffusionDrive) Liao B, Chen S, Yin H, et al. DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving[J]. arXiv preprint arXiv:2411.15139, 2024.
(DriveVLM) Tian X, Gu J, Li B, et al. Drivevlm: The convergence of autonomous driving and large vision-language models[J]. arXiv preprint arXiv:2402.12289, 2024.
(LeapAD) Mei J, Ma Y, Yang X, et al. Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving[J]. arXiv preprint arXiv:2405.15324, 2024.
(AsyncDriver) Chen Y, Ding Z, Wang Z, et al. Asynchronous large language model enhanced planner for autonomous driving[C]//European Conference on Computer Vision. Springer, Cham, 2025: 22-38.
(On the road) Wen L, Yang X, Fu D, et al. On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving[J]. arXiv preprint arXiv:2311.05332, 2023.
(3D-Tokenized LLM) Bai Y, Wu D, Liu Y, et al. Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?[J]. arXiv preprint arXiv:2405.18361, 2024.
(Cube-LLM) Cho J H, Ivanovic B, Cao Y, et al. Language-Image Models with 3D Understanding[J]. arXiv preprint arXiv:2405.03685, 2024.
(Image Textualization) Pi R, Zhang J, Zhang J, et al. Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions[J]. arXiv preprint arXiv:2406.07502, 2024.
(Fiery) Hu A, Murez Z, Mohan N, et al. Fiery: Future instance prediction in bird's-eye view from surround monocular cameras[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15273-15282.

