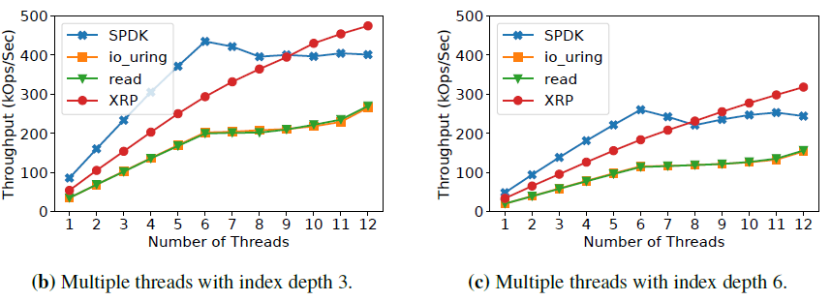
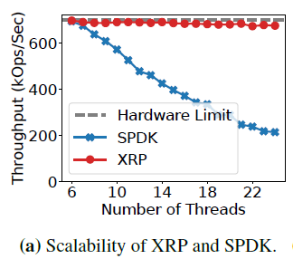
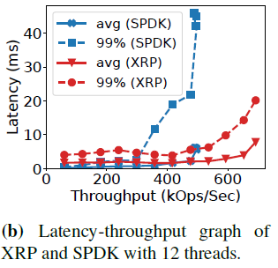
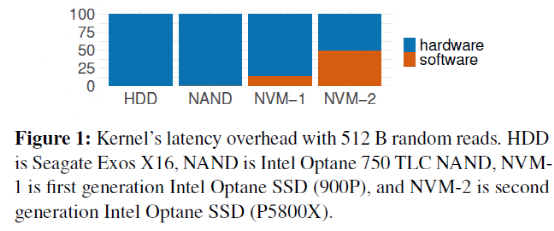
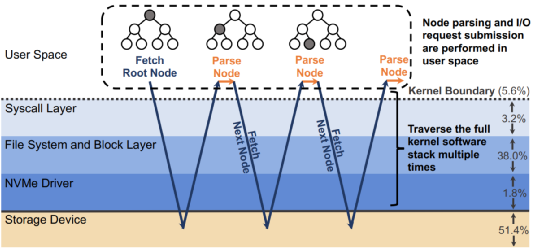
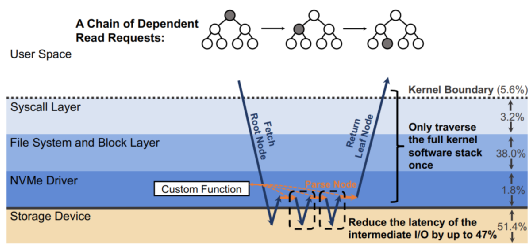
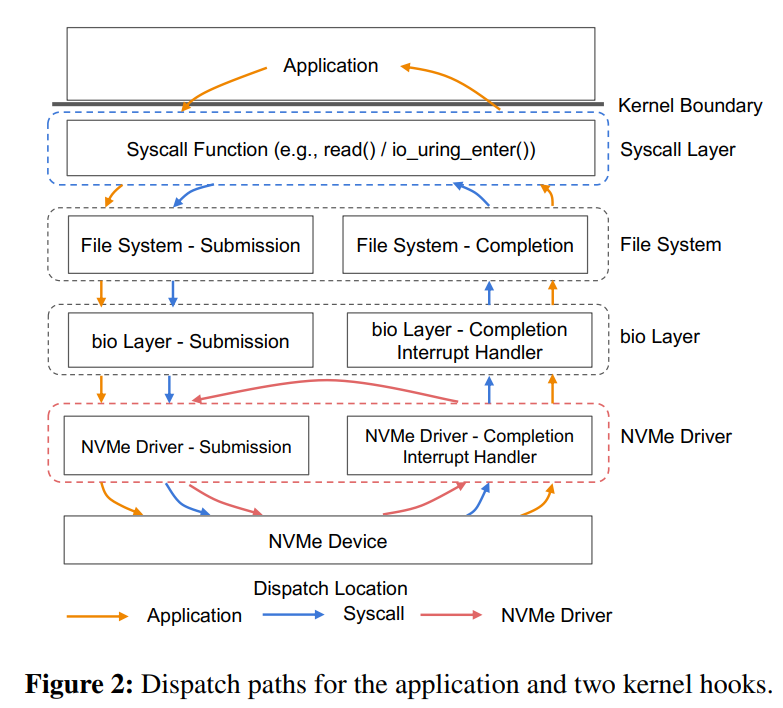
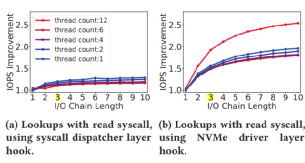
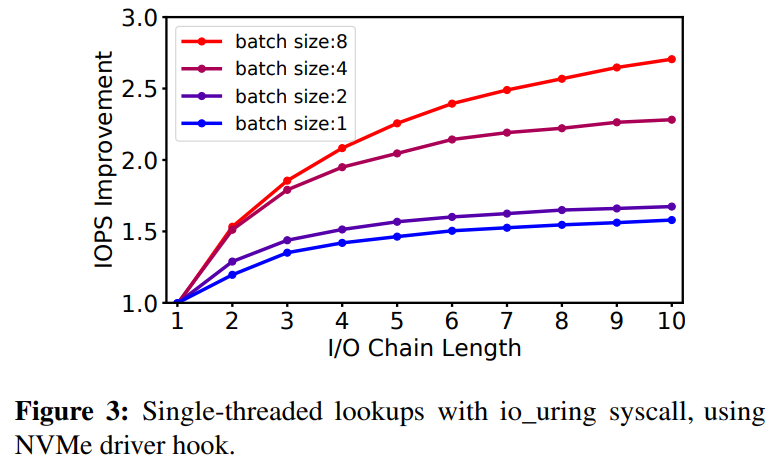
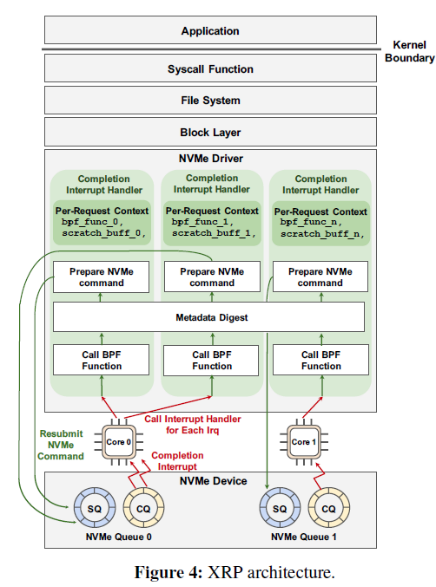
那么,为什么不直接绕过内核呢?这种办法并非灵丹妙药:这意味着把存储设备的访问完全暴露给应用,同时应用必须实现自己的文件系统——这意味着没有保证数据孤立的机制,不同应用无法共享同一个设备的空间。此外,用户态应用也无法接受中断——这意味着当I/O并非性能瓶颈时,CPU资源会被浪费,利用率低下。而且当多个polling的线程共享一个CPU时,CPU竞争+缺乏同步机制会导致所有polling的线程的尾端延迟巨大,带宽巨低。3、BPF简介BPF(Berkeley Packet Filter)是一个允许用户把一个简单的函数注入内核执行的接口。Linux中实现的BPF框架叫eBPF。函数在注入前,需要经过几秒钟的检验(verification),随后这个eBPF函数就可以被正常调用了。BPF的潜在优势当一个请求需要进行多次I/O查找(resubmission)时,BPF可以避免内核态和用户态之间的数据迁移。例如,查找B树的索引时,需要先从根节点查起,直到找到叶子节点。而这一过程若使用多个系统调用,则每一次系统调用都要遍历整个内核存储栈。而若使用BPF函数,可以把刚刚的查找函数注入NVMe驱动层,这样只有第一次查找需要遍历整个内核存储栈,之后的查询结果只需要返回驱动层即可。二者的对比如下图:B-Tree Lookup from User SpaceB-Tree Lookup With an In-Kernel Function其他数据结构(LSM树)、其他操作(范围查询、迭代、计算统计数据)也可以从这种机制中获益。这些操作的特点是有大量“中间“(或者说”备用“)的I/O操作,而对用户而言只需要最后的单个结果或者I/O返回的一小部分对象。除了在NVMe驱动层,BPF函数也可以放在其他层,如系统调用。下图是普通的系统调用和两个使用BPF函数分发(或者重发)I/O操作时的不同路径。







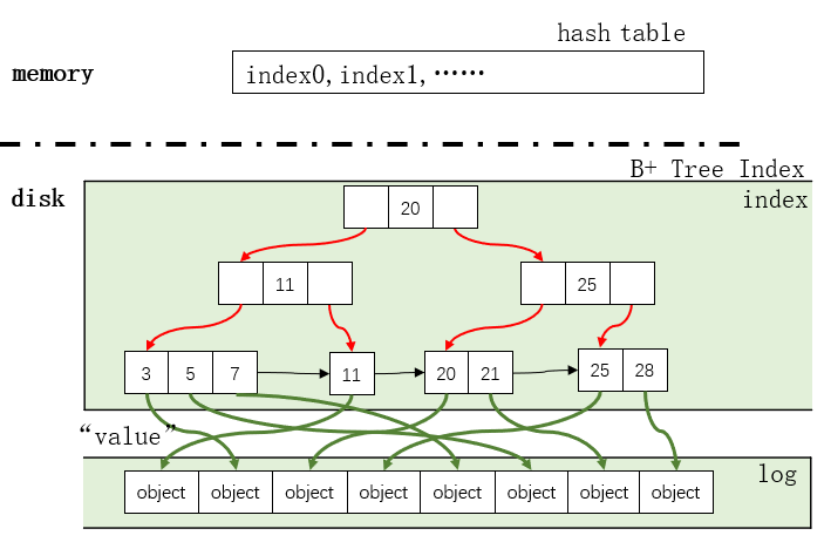
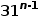 个指向object的指针,而object有
个指向object的指针,而object有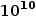 个,解得n=8.
个,解得n=8.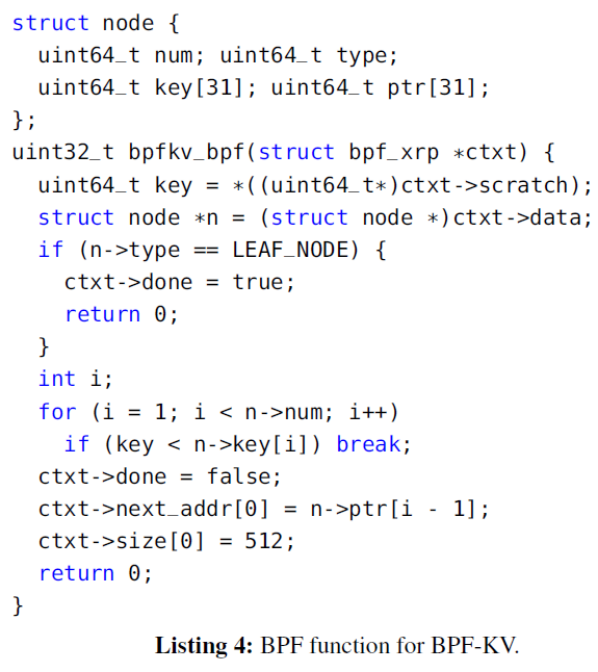
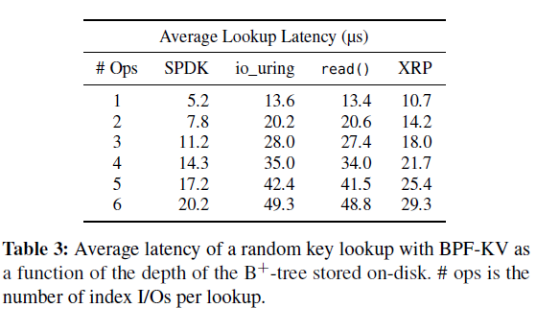
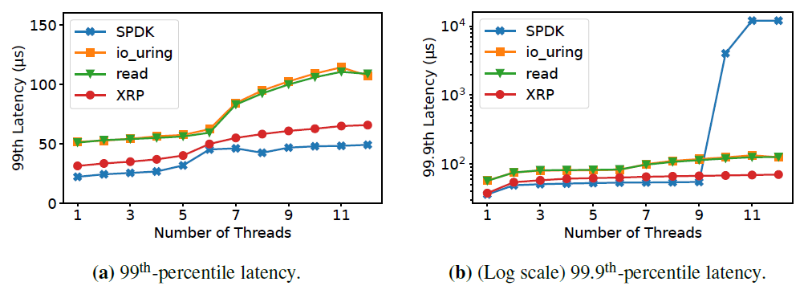
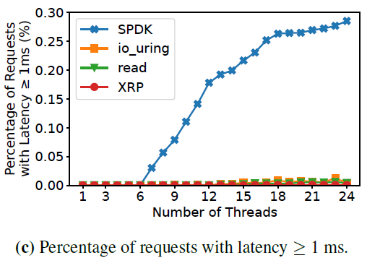
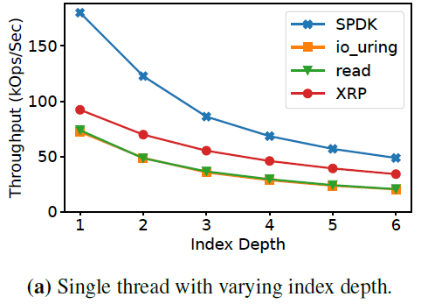
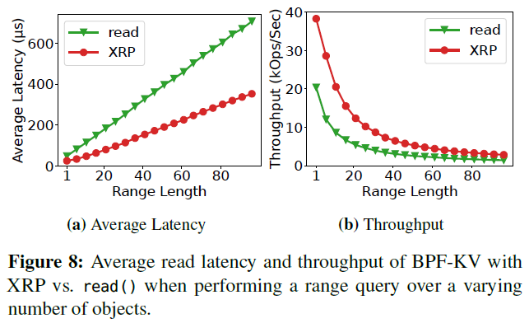
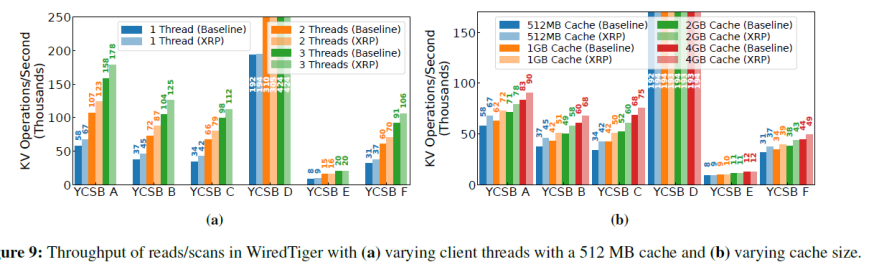
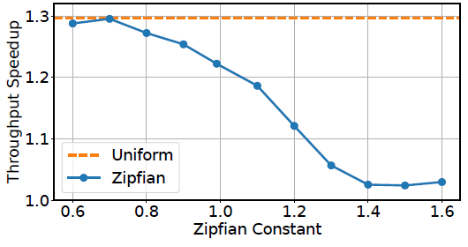
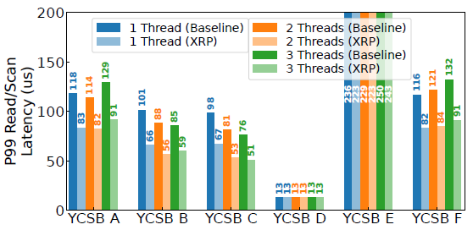
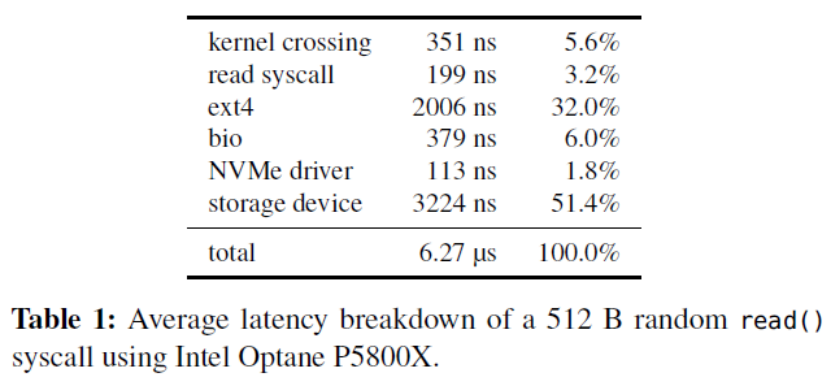
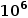 次随机读操作。为了关注查询盘上数据的开销,作者关闭了内存的缓存(缓存对象和缓存index)。平均延迟的对比如下表,最左一列的I/O数不包括获得最终要的数据的最后一次I/O。
次随机读操作。为了关注查询盘上数据的开销,作者关闭了内存的缓存(缓存对象和缓存index)。平均延迟的对比如下表,最左一列的I/O数不包括获得最终要的数据的最后一次I/O。