


关于TPU 的工作原理、它们如何联网以实现多芯片训练和推理,以及它们如何限制我们最喜欢的算法的性能。虽然这看起来有点枯燥,但对于真正提高模型效率来说,它非常重要。
DeepSeek核心技术:模型训练、优化及数据处理的技术精髓(合集)
《42篇半导体行业深度报告&图谱(合集)
什么是TPU?
TPU 基本上是一个专门用于矩阵乘法的计算核心(称为 TensorCore),连接到一堆快速内存(称为高带宽内存或 HBM),以下是图表:
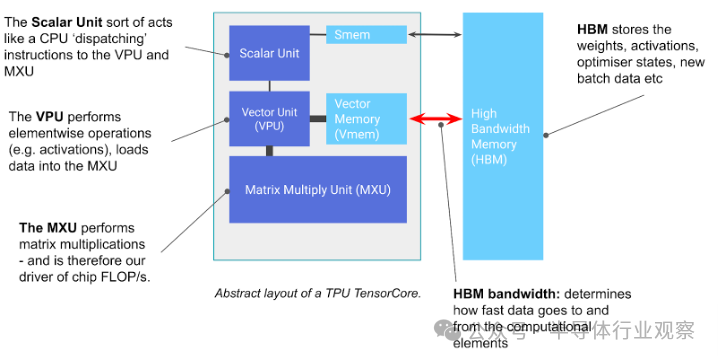
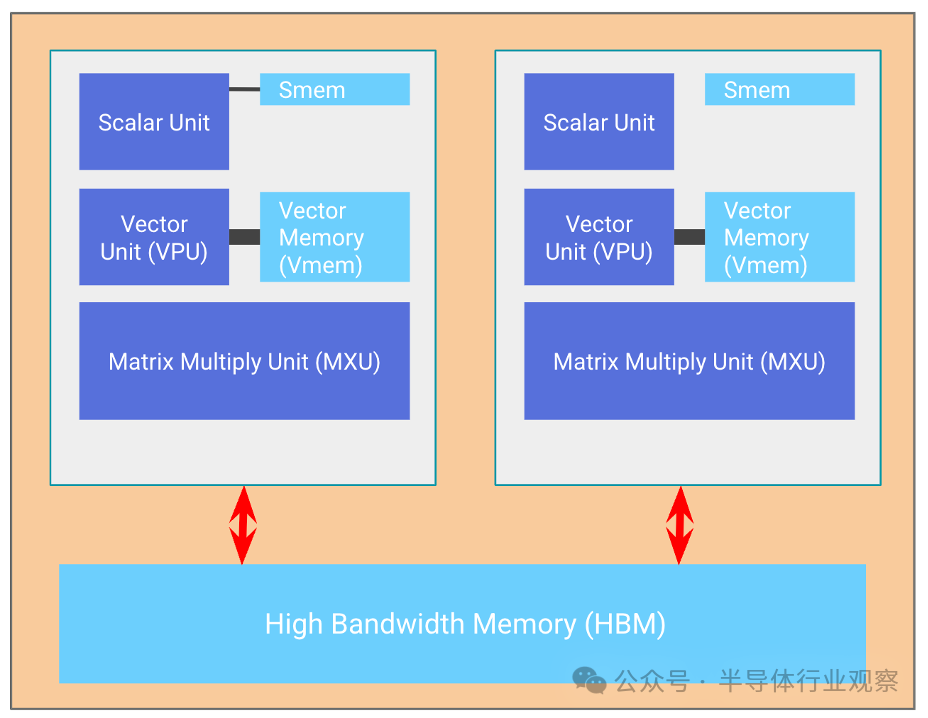
图: TPU 芯片的基本组件。TensorCore 是左侧灰色框,包含矩阵乘法单元 (MXU)、矢量单元 (VPU) 和矢量内存 (VMEM)。
您可以将 TensorCore 视为一款出色的矩阵乘法机,但它还有一些其他值得注意的功能。TensorCore 有三个关键单元:
MXU (矩阵乘法单元)是 TensorCore 的核心。对于大多数 TPU 代,它执行一次矩阵bfloat16[8,128] @ bf16[128,128] -> f32[8,128]乘法1每 8 个周期使用一个脉动阵列。
在 TPU v5e 上,1.5GHz 时每个 MXU大约为5e13bf16 FLOPs/s。大多数 TensorCores 有 2 个或 4 个 MXU,因此例如 TPU v5e 的总 bf16 FLOPs/s 为2e14。
TPU 还支持具有更高吞吐量的较低精度矩阵乘法(例如,每个 TPU v5e MXU 可以执行4e14int8 OPs/s)。
VPU (矢量处理单元)执行一般数学运算,如 ReLU 激活或矢量之间的逐点加法或乘法。这里还执行缩减(求和)。
VMEM(矢量内存)是位于 TensorCore 中靠近计算单元的片上暂存器。它比 HBM 小得多(例如,TPU v5e 上为 128 MiB),但到 MXU 的带宽要高得多。VMEM 的运行方式有点像 CPU 上的 L1/L2 缓存,但要大得多,而且由程序员控制。HBM 中的数据需要复制到 VMEM 中,然后 TensorCore 才能使用它进行任何计算。
TPU 在矩阵乘法方面非常非常快。这主要是它们所做的事情,而且它们做得很好。TPU v5p是迄今为止最强大的 TPU 之一,可以达到2.5e14bf16 FLOPs/秒/核心或5e14bf16 FLOPs/秒/芯片。一个由 8960 个芯片组成的 pod 可以达到 4 exaflops/秒。这可真不少。这是世界上最强大的超级计算机之一。而且谷歌有很多这样的超级计算机。
上图还包括一些其他组件,如 SMEM 和标量单元,它们用于控制流处理,并在附录 C中进行了简要讨论,但理解起来并不重要。另一方面,HBM 很重要,而且相当简单:
HBM(高带宽内存)是一大块快速内存,用于存储供 TensorCore 使用的张量。HBM 的容量通常为数十 GB 的数量级(例如,TPU v5e 有 16GiB 的 HBM)。
当需要计算时,张量会通过 VMEM(见下文)从 HBM 流出到 MXU,然后将结果从 VMEM 写回 HBM。
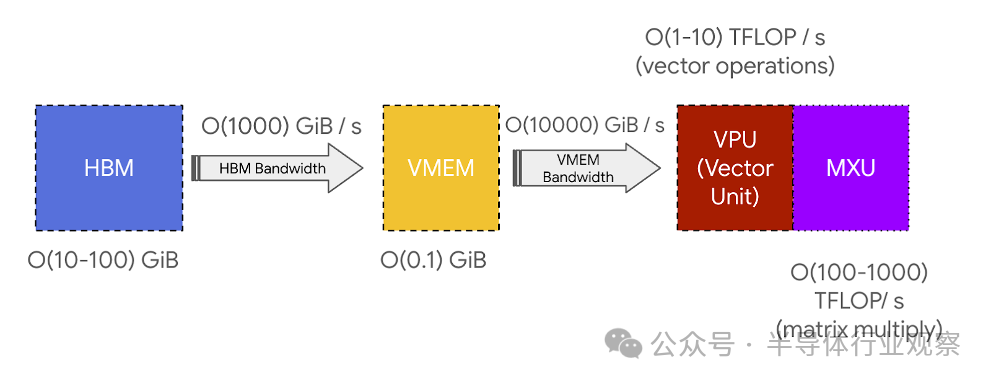
HBM 和 TensorCore(通过 VMEM)之间的带宽称为“HBM 带宽”(通常约为 1-2TB/秒),限制了在内存受限工作负载中计算的速度。
通常,所有 TPU 操作都是流水线式和重叠式的。要执行 matmul X⋅A → Y,TPU 首先需要复制矩阵块和从 HBM 传输到 VMEM,然后将它们加载到 MXU 中,MXU 将 8x128 的块相乘(例如)和 128x128(用于),然后将结果逐块复制回 HBM。为了高效地完成此操作,matmul 是流水线式的,因此往返于 VMEM 的复制与 MXU 工作重叠。这允许 MXU 继续工作,而不必等待内存传输,从而使 matmul 受计算限制,而不是受内存限制。
以下是如何从 HBM 执行元素积的示例:
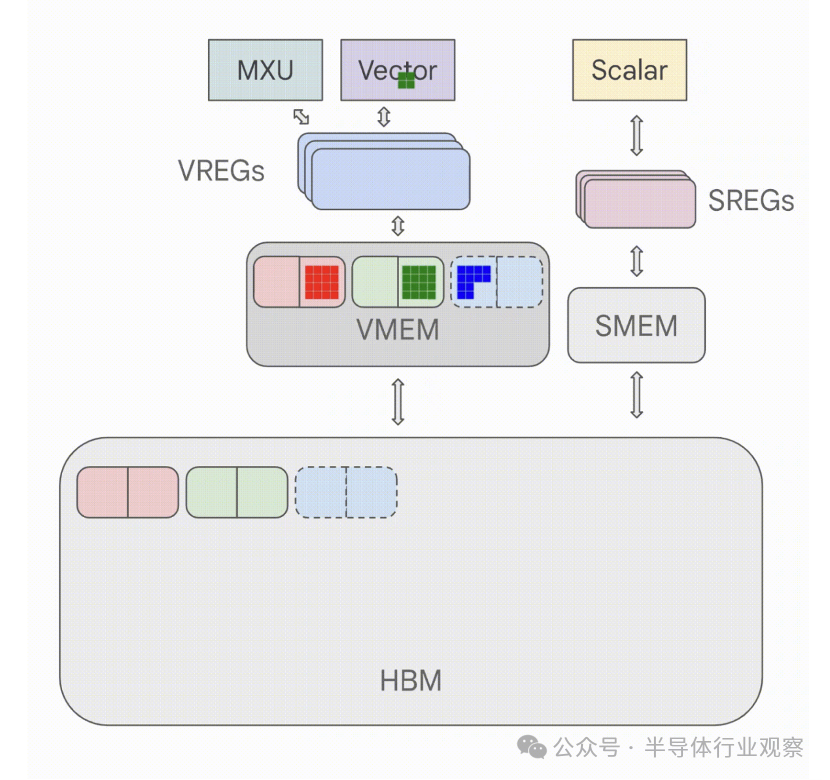
图:上图展示了在 TPU 上执行的逐点乘积,其中字节从 HBM 加载。请注意字节如何以块的形式从内存中流出,并且部分结果如何通过管道传输回来,而无需等待整个数组实现。
matmul 看起来几乎完全相同,只是它会加载到 MXU 而不是 VPU/矢量单元,并且加载和存储会以不同的顺序发生,因为相同的权重块用于多个激活块。您可以看到数据块流入 VMEM,然后流入 VREG(矢量寄存器),然后流入矢量单元,然后返回 VMEM 和 HBM。正如我们将要看到的,如果从 HBM 到 VMEM 的加载速度比矢量单元(或 MXU)中的 FLOP 慢,我们就会变得“带宽受限”,因为我们正在耗尽 VPU 或 MXU 的工作量。
关键要点: TPU 非常简单。它们将权重从 HBM 加载到 VMEM,然后从 VMEM 加载到脉动阵列中,该阵列每秒可执行约 200 万亿次乘加运算。HBMVMEM 和 VMEM脉动阵列带宽对 TPU 能够有效执行的计算设定了基本限制。
VMEM 和算术强度: VMEM 比 HBM 小得多,但其到 MXU 的带宽高得多。正如我们在第 1 节中看到的,这意味着如果算法可以将其所有输入/输出放入 VMEM 中,则不太可能遇到通信瓶颈。当计算的算术强度较差时,这尤其有用:VMEM 带宽大约比 HBM 带宽高 22 倍,这意味着从 VMEM 读取/写入 MXU 操作只需要 10-20 的算术强度即可实现峰值 FLOPs 利用率。这意味着如果我们可以将权重放入 VMEM 而不是 HBM,我们的矩阵乘法可以在更小的批量大小下受 FLOPs 约束。这意味着从根本上具有较低算术强度的算法仍然可以高效。VMEM 太小了,这通常是一个挑战。
TPU 芯片通常(但并非总是)由两个共享内存的 TPU 核心组成,可以视为一个具有两倍 FLOP 的大型加速器。自 TPU v4(称为“兆核”)以来一直如此。在较旧的 TPU 芯片上,它们具有单独的内存,被视为两个单独的加速器(TPU v3 及更早版本)。像 TPU v5e 这样的推理优化芯片每个芯片只有一个 TPU 核心。
芯片以 4 个为一组排列在通过 PCIe 网络连接到CPU 主机的“托盘”(tray)上。这是大多数读者熟悉的格式,即通过 Colab 或单个 TPU-VM 公开的 4 个芯片(8 个核心,但通常被视为 4 个逻辑兆核)。对于像 TPU v5e 这样的推理芯片,我们每个主机有 2 个托盘,而不是 1 个,但每个芯片只有 1 个核心,这样我们就有 8 个芯片 = 8 个核心。
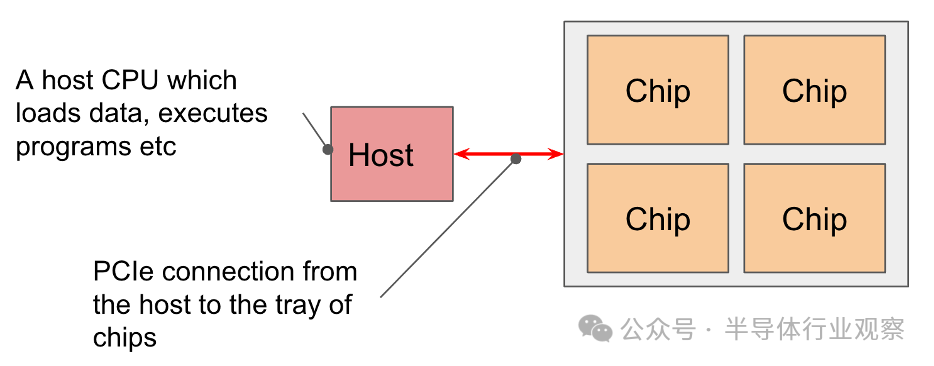
PCIe 带宽有限:与 HBM 一样VMEM 链接,CPUHBM PCIe 连接具有特定带宽,限制了从主机内存加载到 HBM 或反之亦然的速度。例如,TPU v4 的 PCIe 带宽为单向 16GB/秒,因此比 HBM 慢近 100 倍。我们可以将数据加载/卸载到主机 (CPU) RAM 中,但速度不是很快。
TPU 网络
芯片通过 Pod 中的 ICI 网络相互连接。在老一代(TPU v2 和 TPU v3)、推理芯片(例如 TPU v5e)和 Trilium(TPU v6e)中,ICI(“芯片间互连”)连接 4 个最近的邻居(通过边缘链接形成 2D 环面)。TPU v4 和 TPU v5p 连接到最近的 6 个邻居(形成 3D 环面)。请注意,这些连接不通过其主机,它们是芯片之间的直接链接。
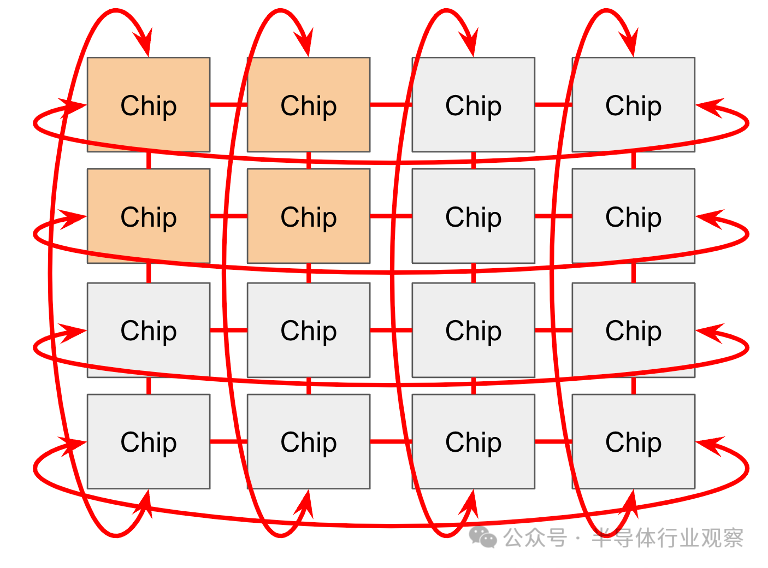
环形结构减少了任意两个节点之间的最大距离到,使通信速度更快。TPU 还具有“扭曲圆环”配置,该配置将圆环包裹在类似莫比乌斯带的拓扑中,以进一步缩短节点之间的平均距离。
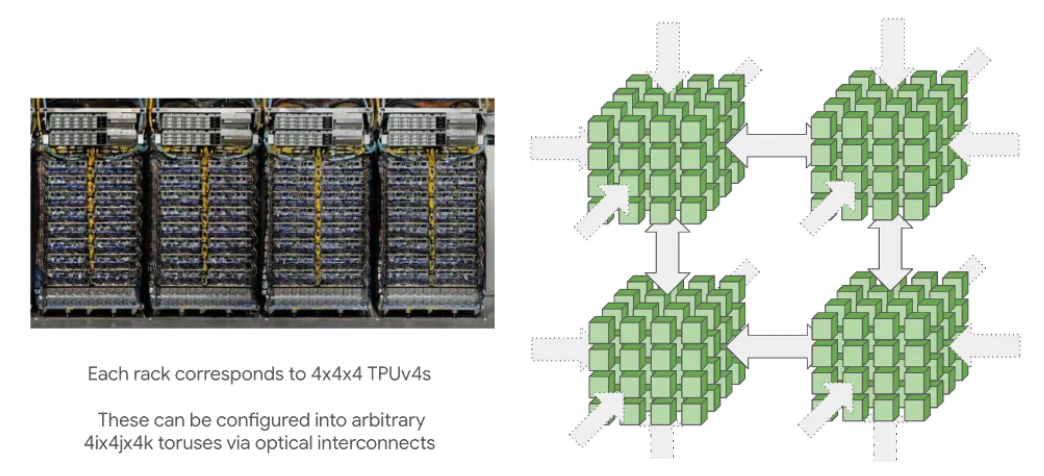
TPU pod(由 ICI 连接)可以变得非常大:最大 pod 尺寸(称为超级 pod)适用16x16x16于 TPU v4 和16x20x28TPU v5p。这些大型 pod 由可重构的芯片立方体组成,4x4x4通过光学环绕链路连接5我们可以重新配置它来连接非常大的拓扑。
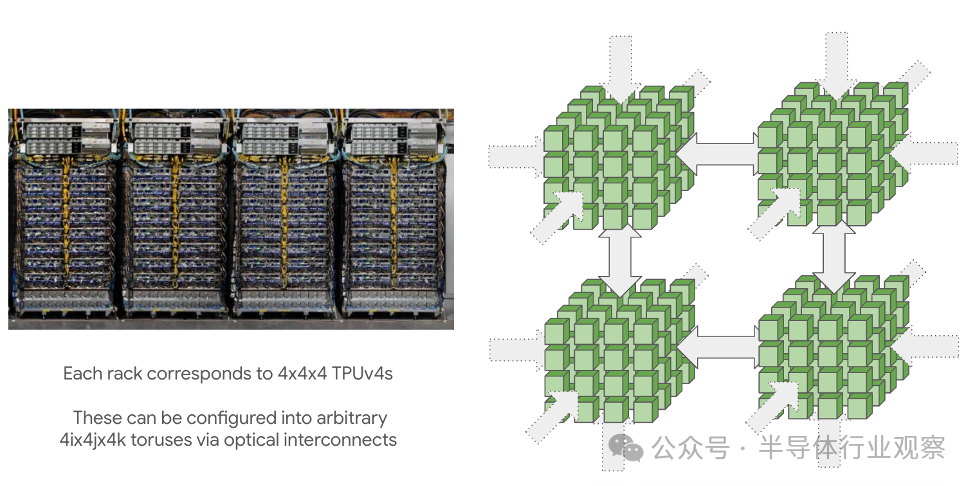
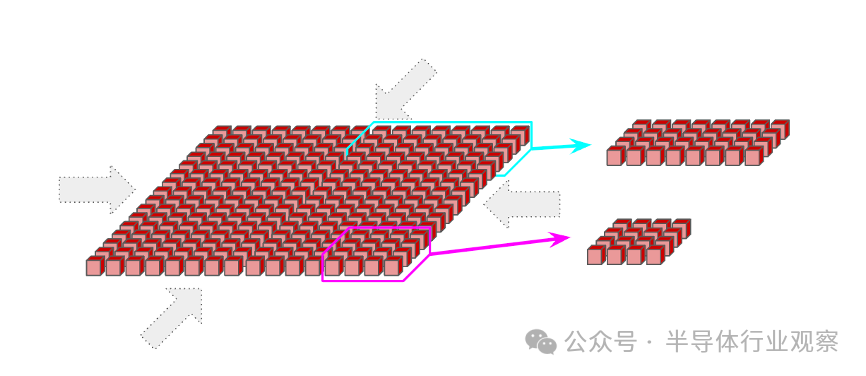
也可以请求较小的拓扑(例如2x2x1,2x2x2),尽管没有回绕。这是一个重要的警告,因为它通常会使大多数通信的时间加倍。任何完整立方体的倍数(例如4x4x4或4x4x8)都将具有由光开关提供的回绕。
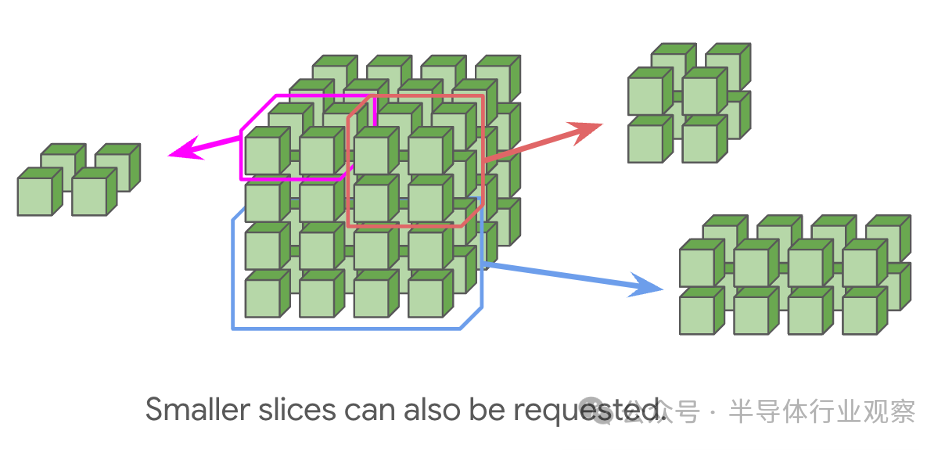
对于 TPU v5e 和 Trillium,我们有由 2D 圆环组成的 pod。TPU 16x16v5e 和 v6e (Trillium) 无法扩展到 16x16 圆环之外,但 pod 仍可通过标准数据中心网络 (DCN) 相互通信。同样,可以请求较小的拓扑,而无需绕回 dims< 16。
这种最近邻连接是 TPU 和 GPU 之间的一个关键区别。GPU 以全对全配置(称为节点)连接多达 256 个 H100,而不是使用本地连接。一方面,这意味着 GPU 可以在单个低延迟跳跃中在节点内发送任意数据。另一方面,TPU 连接起来的成本要低得多,也更简单,并且可以扩展到更大的拓扑,因为每个设备的链接数量是恒定的。
ICI相对于 DCN 非常快,但仍比 HBM 带宽慢。例如,TPU v5p2.5e12每轴的HBM 带宽为字节/秒(2.5 TB/秒),1e11ICI 带宽为字节/秒(100 GB/秒),大约低 25 倍。这意味着当我们将模型拆分到多个芯片上时,我们需要小心,避免因跨设备通信速度较慢而导致 MXU 出现瓶颈。
多切片训练:一组 ICI 连接的 TPU 称为一个切片。不同的切片可以使用 DCN 相互连接,例如链接不同 pod 上的切片。由于 DCN 的连接速度比 ICI 慢得多,因此应该尝试限制我们的计算需要等待 DCN 数据的时间。
关键要点
TPU 很简单,在大多数情况下可以被认为是连接到内存(超快)、通过 ICI 连接到其他芯片(相当快)以及通过 DCN 连接到数据中心其余部分的矩阵乘法单元(有点快)。
通信受到我们各种网络带宽的限制,速度依次为:
HBM 带宽:TensorCore 与其相关的 HBM 之间。
ICI 带宽:TPU 芯片与其最近的 4 个或 6 个邻居之间。
PCIe 带宽:CPU 主机与其关联的芯片托盘之间。
DCN 带宽:多个 CPU 主机之间,通常是未通过 ICI 连接的主机。
在一个切片内,TPU 仅通过 ICI 与其最近的邻居相连。这意味着切片内远距离芯片之间的 ICI 通信需要先跳过中间芯片。
权重矩阵需要在两个维度上至少填充到 128 大小(TPU v6 上为 256)才能填满 MXU(事实上,较小的轴会填充到 128)。
精度较低的矩阵乘法往往更快。对于支持此功能的几代产品,TPU 执行 int8 或 int4 FLOP 的速度大约比执行 bfloat16 FLOP 快 2 倍/4 倍。VPU 操作仍在 fp32 中执行。
为了避免 TPU 计算单元出现瓶颈,我们需要确保每个通道上的通信量与其速度成正比。以下是TPU的一些具体数字:
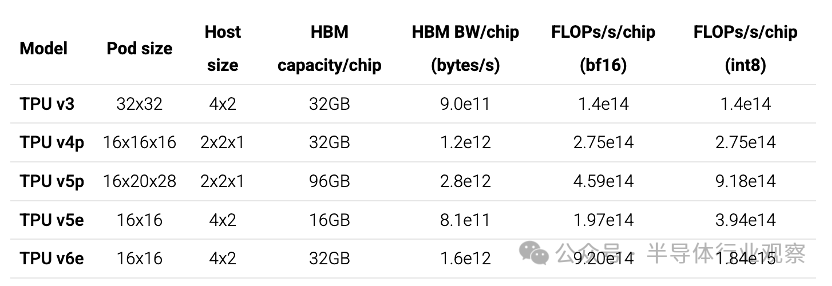
主机大小是指连接到单个主机的 TPU 的拓扑结构(例如,TPU v5e 有一个 CPU 主机,以 4x2 拓扑结构连接到 8 个 TPU)。以下是互连图:

我们同时包括单向(单向)带宽和双向(双向)带宽,因为单向带宽更符合硬件,但双向带宽在涉及全环的方程中更常出现。
PCIe 带宽通常约为1.5e10每芯片每秒字节数,而 DCN 带宽通常约为2.5e10每主机每秒字节数。为了完整起见,我们同时包括单向和双向带宽。通常,当我们能够访问完整的环绕环时,双向带宽是更有用的数字,而单向带宽更符合硬件。
内容转载:半导体行业观察
参考链接:https://jax-ml.github.io/scaling-book/tpus/
8、《3+份技术系列基础知识详解(星球版)》
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


