

2025年两场技术革命正在发生:
比亚迪将高阶智驾功能“下放”至10万元车型,宣告“全民智驾”时代加速到来。
DeepSeek以强化学习撕开数据瓶颈,证明AI可超越人类逻辑。
商汤绝影的工程师们,悄然将这两股浪潮拧成一条全新的绳——“端到端模型+世界仿真+强化学习”的三体协同。
在商汤大模型生产力论坛上,商汤科技联合创始人、绝影智能汽车事业群总裁、首席科学家王晓刚教授,揭开了这场变革的底层逻辑。

当行业困于“有多少数据才能喂饱自动驾驶”的焦虑时,商汤给出的答案却是——“让AI学会在虚拟世界中自我进化”。
(以下内容根据王晓刚教授演讲实录整理,仅做阅读流畅性编辑)
王晓刚教授认为,端到端本质实际上模仿学习最佳的人类驾驶行为。数据输入端是各种高质量人类驾驶的数据,包括摄像头采集到的视频;输出就是人类驾驶行为的轨迹。
但是以这种模仿学习为主的方式,面临着挑战。
首先是海量数据的门槛。端到端自动驾驶要做好,需要这个千万级甚至更多的clips(视频数据片段)。
特斯拉有 700 万量产车源源不断的产生数据回流。但今天国内任何一个自动驾驶公司或者是车厂,搭载智驾系统的车辆其实是远远小于这个规模的,而且不同的车型上的传感器也不一致,各种数据标准还不一样,比较难以形成合力。

第二点,即便有了这么大规模的量产车,高质量、高难度场景的驾驶数据,占比例也是非常少的。
而且在这其中,类驾驶行为的质量也是参差不齐的,这就导致端到端发展的过程当中,遇到了数据端瓶颈。
另外,端到端始终是模仿学习,希望接近人类驾驶行为,那么人类驾驶行为最好的水平也是它的天花板,很难去突破。
OpenAI从2018年开始在大模型的算法上做了大量的探索和储备,直到 2022年底的时候ChatGPT出圈。
大家看到的是基于稳定算法条件下,依据Scaling Law不断增加网络的规模和算力的规模,持续网络的性能,去挖掘数据的红利。
但同时业内也发现,整个2204年Scaling Law逐渐遇到了瓶颈,似乎互联网上的数据价值被榨干了一样,再进一步扩大网络规模、增加算力,得到的收益却比较小。
就在时候,Deepseek横空出世,实际上是在算法层间取得了新的突破,甚至带来的新的研究的范式。
它证明了:纯强化学习产生的长思维链涌现,能够打破数据的瓶颈。
举个例子,对于给定问题,Deepseek可以通过强化学习的框架,生成多条思维链,针对每一个题有很多不同解法,突破了人类知识库的限制,从而产生了更多的数据,这就是打破了数据的瓶颈,让Scaling Law得以延续。
继续增加大模型的网络规模,还可以看到在强化学习帮助下,网络的性能还能够得到持续的提升。所以强化学习它也能够突破人类固有的极限。
自然而然给自动驾驶带来了新的启示。
有了强化学习的加持,就能够用世界模型跟端到端自动驾驶模型进行协同交互。
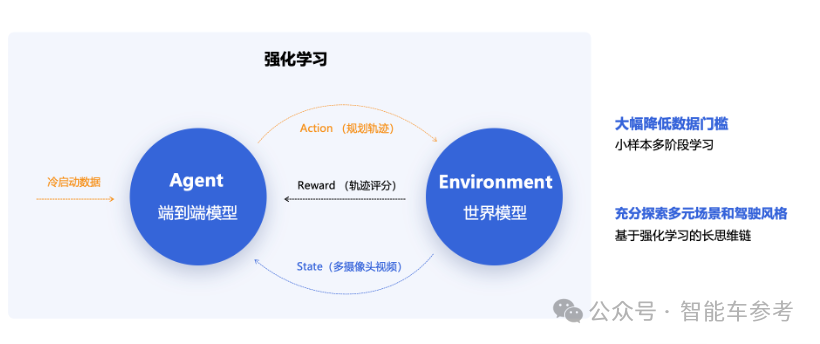
这是一种新技术路线。
如果把车辆当成一个智能体,背后是端到端模型支撑,那么在启动的时候它需要一些冷启动的数据,让模型能够达到一个基础水平,然后就进入强化学习阶段。
端到端模型输出的轨迹,又作为一个模拟仿真器的输入,这个仿真器背后是由世界模型作为支撑的,它能够去模拟仿真下一个时刻环境的变化,各种多摄像头里面观察到的视频的变化。
如此循环往复,世界模型就可以产生一个时间序列里轨迹的变化以及周围环境的变化。
端到端用来生成多种不同轨迹,世界模型去模拟各种不同轨迹影响下,周边环境的变化,同时仿真器还会通过reward方式,针对各种不同的轨迹、不同的环境的变化打分,找到一个最佳的驾驶行为。
所以在这种这个强化学习的范式下,整个自动驾驶系统就能够去通过小样本多监督、多阶段的学习,降低数据的门槛。
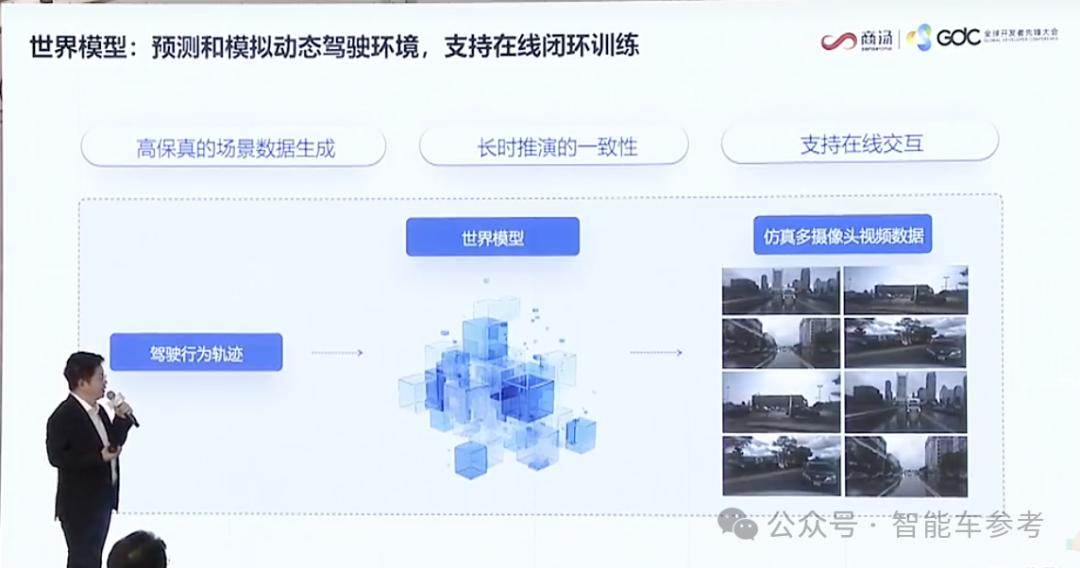
强化学习的长思维链可以充分探索多元场景里不同的驾驶风格。但是需要一个非常关键的要素——强大的世界模型。
2024年11月,商汤绝影发布了用于量产智驾的世界模型——开悟。
它有几个核心能力,第一个就是真实度高,能够理解真实的世界,生成的视频天然遵循物理法则和交通规则。
另外是准确度好,能够同时保持11个摄像头在150 秒内的时空一致性,而且是高分辨率。
第三点是可控性强,包括天气、路况,不同的轨迹, 3D目标等等都能够精细的控制、编辑,然后根据不同元素的变化生成视频。
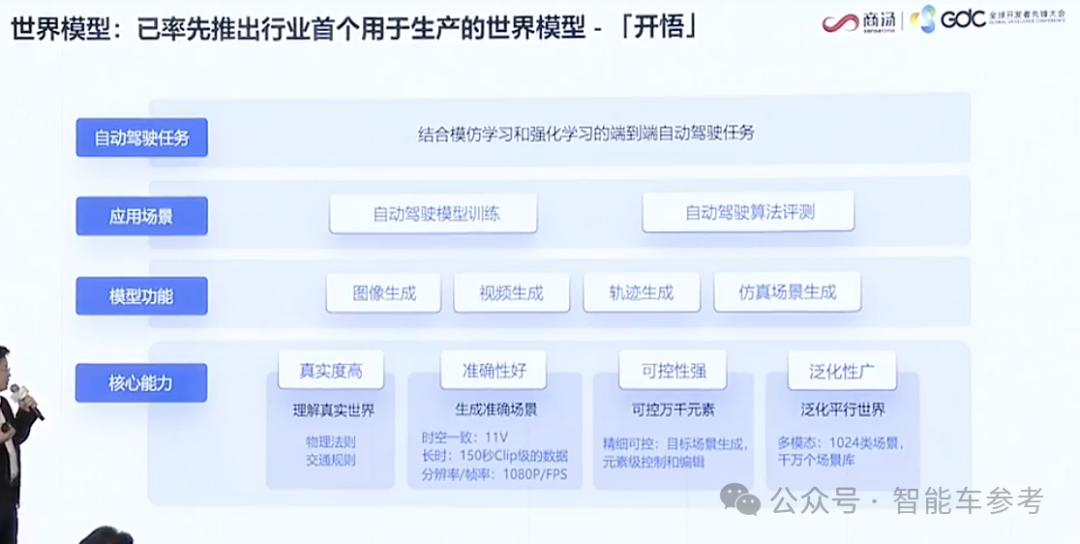
最后是泛化性广,开悟世界模型能够生成各种不同场景下的图像视频轨迹,结合强化学习,加速端到端模型的训练和演进。
目前,开悟世界模型已经有1024类的不同的场景,生成千万级别的这样的一个场景库。
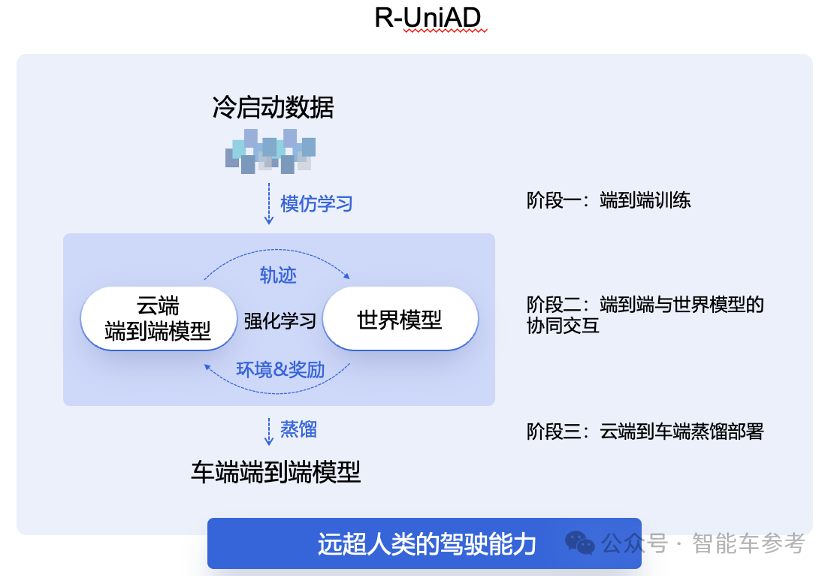
可以清楚看到单纯端到端自动驾驶,和基于强化学习、世界模型与端到端协同交互模式的不同。
一个是简单的模仿学习,另外一个是多阶段:首先通过端到端冷启动训练,达到一个比较好的基模型。

第二阶段,端到端模型和世界模型去协同交互,通过强化学习不断的更新演进。
第三个阶段从云端到车端,通过知识的蒸馏得到更灵巧的车端模型去节省算力、硬件的成本。
开悟模型可以理解为自动驾驶专用版的Sora大模型,用来解决端到端研发体系中的仿真问题。
具体来说,生成的视频基于11个摄像头, 11V保持时空一致的时间间隔,最长可以达到 150 秒,分辨率能够达到1080P。
同时开悟生成的场景也是可控的,能够细微的做到元素级别。
晴天下周边环境的投影、夜间车辆远近近光的投射,都是符合物理法则的真实呈现。
这种感觉有点像游戏工业著名的虚幻引擎,但开悟世界模型的的不同之处在于,它通过海量数据的学习物理法则,而且同时还学会了交通规则,比如车辆刹车的时候视屏中车辆会适当的保持车距并合理启停。

而与行业内其他先发的世界模型相比,开悟的优势在于多视角和清晰度。
目前业内最好的水平现在是6V视角,而开悟通过行人车辆3D框和时空轨迹作为精准的输入,控制信号来生成 11V 的视频数据,保证了11个摄像头在仿真空间中的时空一致性。
另外,开悟生成的是1080P视频会更加清晰,更加方便模型进行训练。借助商汤日日新原生多模态的基模型,开悟可以达到元素级别的精准度,可以生成不同的场景和各种的 corner case,比如同一路段雨天变晴天、增加车辆种类数目等等。

目前绝影智驾研发中20%的数据,都是由开悟世界模型生成。在一块A100 GPU上,世界模型平均每天可以生产大约2万个bundle,相当于100台路测车的数据采集能力,或500 台量产车回传有效数据的效率。
而这样的GPU,商汤一共有超过5.4万块,另外世界模型生成的训练数据,往后还会进一步占比达到80%。
这其实才是“绝影”真正一日千里的核心,也是车企和AI公司无法“独赢”的底层逻辑。
— 联系作者 —

— 完 —
智能车2024年度评选结果
在经过广泛征集、专业推荐,以及智能车参考垂直社群的万人票选后,智能车2023年度评选结果正式发布。涵盖三类奖项:
· 十大智能车年度人物
· 十大智能车车型
· 十大智能车技术方案/产品
在汽车工业迎来百年未有之大变局时,我们希望能以此提供智能维度的参考和注脚。
其中,十大智能车车型是:
<< 左右滑动查看更多车型>>
— 完 —
【智能车参考】原创内容,未经账号授权,禁止随意转载。
点这里👇关注我,记得标星,么么哒~











