

之前在某宝上买了两个拆机硬盘,这个文章(《我在二手硬盘里发现了一堆不可描述的内容》)有描述其中的内,后来觉得很鸡肋,然后送我朋友了。
没多久,那家伙吞吞吐吐问我那个硬盘坏了能不能修复,我搞不明白他对硬盘塞了什么不可描述的内容,导致其承受不了崩了,我在这个文章(《一块不可描述的硬盘坏了,又不好意思去修……》)讲了这个事情的经过。
最后,反正我没修好,也不知道他对硬盘干了啥。他知道我没帮他修好硬盘,将大腿都拍烂了。
又过了段时间,他找我唠叨,说看片没字幕,很好奇里面是啥剧情。我跟他说网上一大堆字幕网站,很容易找到影片对应的字幕文件的。
他说找不到的,真的找不到,然后又在叹气,说好不容易下了几个4K HDR的片子,画面贼溜,就是缺了字幕,很是遗憾。
我还在纳闷啥玩意呢,听他这么说似乎瞬间又明白他看得是啥片子了。
我一下子也不知道怎么搞,直接跟他说:要不你学学这门外语?你之前为了批量爬取这些信息把Python都啃下了,这对你来说还不是“湿湿碎”?!
他没理我,过一会他突发奇想,说最近Deepseek很火,能不能用AI帮忙搞搞?辅助看片 or 提取字幕?
咦?对于身为程序员且颇有好奇心的我,为啥不试试呢?我对不可描述技术研究可是很感兴趣的。
用AI辅助看片?我以前真没想过这种操作!
AI同声传译
于是我发挥我的想象力,把手机摆在电脑旁边,开着AI实时语音翻译或同声传译功能?

但是,这样也能解决问题,但总觉得怪怪的。
在线音频提取文字
于是乎,从网上搜提取字幕的工具或方法,但是经验告诉我:别用度娘,浪费时间浪费精力!
呵呵,广告!在线提取……
这里提个醒,不要将不可描述的内容上传到网上哈,不然分分钟被警察叔叔找你喝茶都不知道怎么回事。
然后呢,好像都不尽如意!
Whisper
不是说用AI辅助看片吗,这事肯定问AI啊。
于是我问好几个AI(中间结果我就不展示了),最终发现还是鼎鼎大名的Deepseek给我的答案靠谱点。
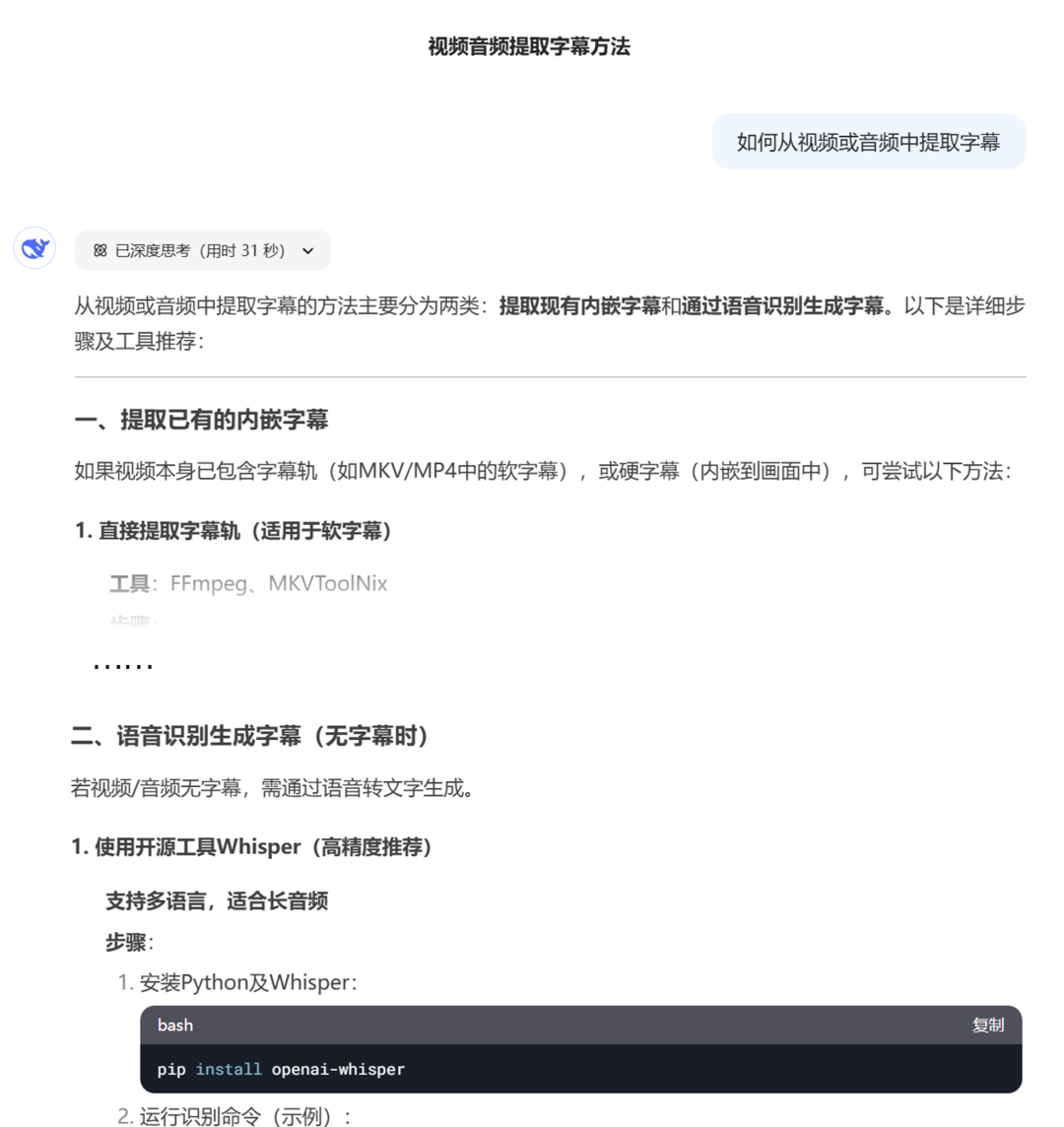
他贴心地告诉我,提取字幕的方法分两类:提取内嵌字幕和通过语言识别生成字幕。而且,还给我做了个总结。

他不知道我问这个问题是想用AI帮忙看片哈,第一种方法是不适用的,我想要的是第二种。
看名字,好像Whisper很厉害的样子,窃窃私语都能懂。
接着,我从OpenAI的官网找到这个Whisper。
Whisper是一个自动语音识别系统,它是在从网络上收集的 68 万小时的多语言、多任务监督数据上进行训练的。
然后,看这配图,不觉明历!

表面上的原理很简单,它是一个end-to-end模型,实现一个encoder-decoder的转换,输入的音频会被切片成30秒的小块,然后就巴拉巴拉……

好吧,这原理我看不懂,反正觉得它应该搞得定。
怎么玩呢?
首先要安装whisper,如果用Python的话,还要安装PyTorch
pip install -U openai-whisper或者
pip install git+https://github.com/openai/whisper.git 然后下载模型包。注意,这是AI模型来的,所以要下载人家训练好的模型来使用。这里有6种模型,存在性能和准确度的差异,以下官方提供了个表做对比:
tiny.en | tiny | ||||
base.en | base | ||||
small.en | small | ||||
medium.en | medium | ||||
large | |||||
turbo |
你不知道用哪个,都下几个来试试。
这不用说,肯定是越大就越精确,但是就运行效率越低,那你就根据你的电脑性能来选咯。
在哪下载模型呢?
在huggingface.co上可以下载,但是要技术上网,你懂的。如果你不懂,继续往下看,还有方法解决。
还有另一种,就是找国内的镜像了,例如gitee上面就能找到(https://gitee.com/organizations/hf-models/projects)。
好了,那怎么用呢?
import whisper# 加载模型model = whisper.load_model("large - v2")# 转录音频文件result = model.transcribe("path_to_your_audio_file.wav")# 打印识别结果print(result["text"])
就这样,简单吧。
还有命令行方式的
whisper audio.flac audio.mp3 audio.wav --model turbo当然也可以指定语言的,例如Japanese
whisper japanese.wav --language Japanese此时,你提取的文字是日文的哦,看得懂当我没说,不行的话就去翻译吧(这一步简单,我就不啰嗦了)。
然后把字幕扔到播放器就可以愉快地看片了

你还可以通过--help查看相关参数使用。
whisper --help但是,还是有点麻烦啊。
PotPlayer+Whisper
PotPlayer 241212 版本新增了使用 Whisper 从语音生成字幕的功能,用PotPlayer播放视频可实现识别音频为字幕的功能。
步骤:
右键打开菜单
点击“字幕”
点击“创建有声字幕”
点击“创建有声字幕……”
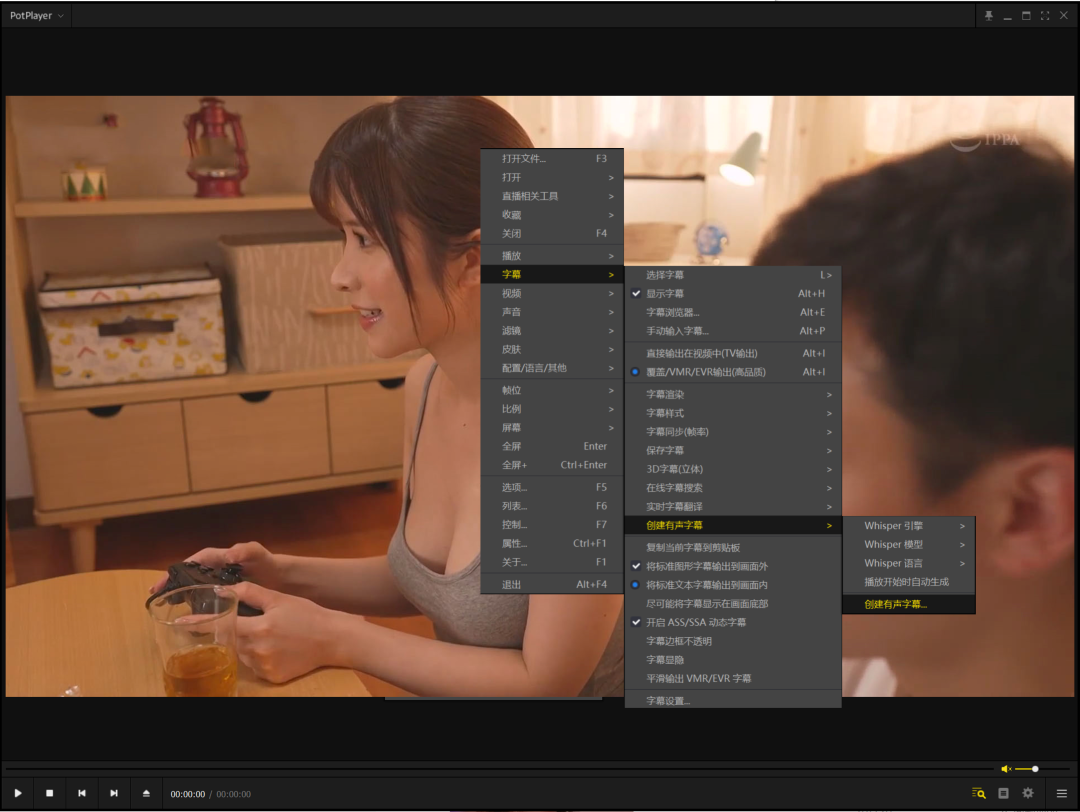
然后再打开的对话框里选择参数
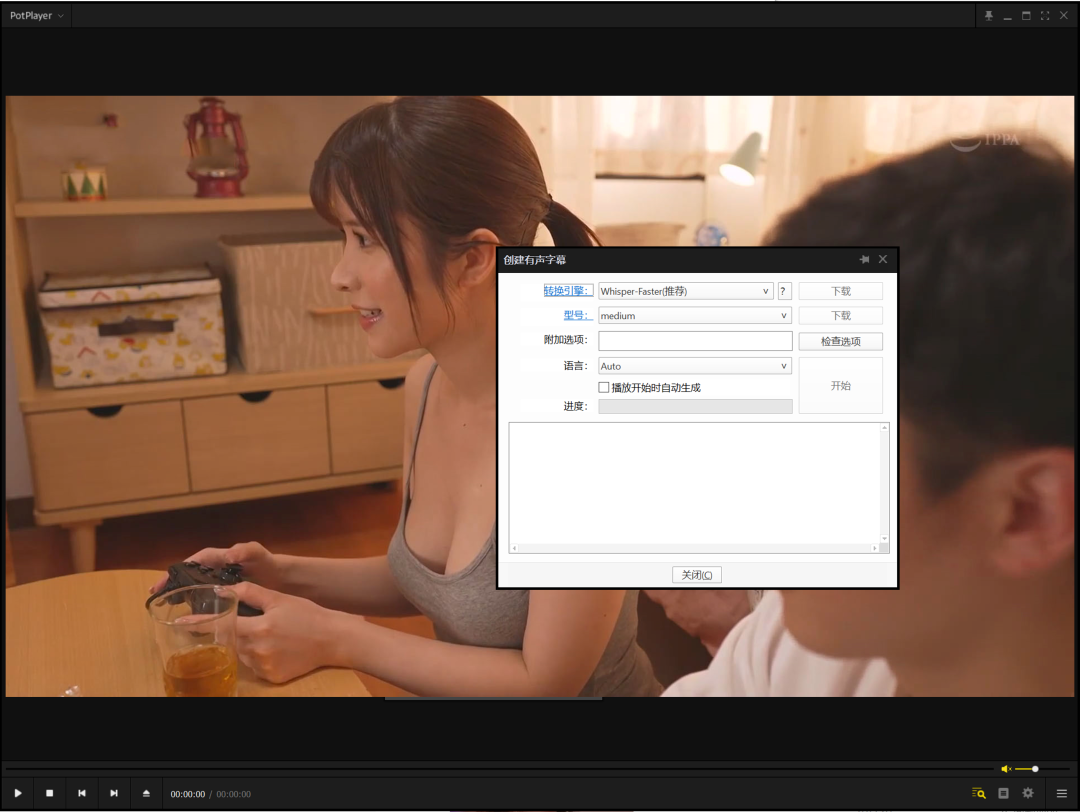
这里看一眼就懂了,注意这里这个“型号”就是大模型的名称,例如图中的medium表示faster-whisper-medium模型。
如果你的电脑配置牛逼,你可以选large-v3,这个模型的精确度高很多,当然你要提前下载好这些模型。
完了吗?
Potplayer还给你提供自动翻译的途径。就是这里哈
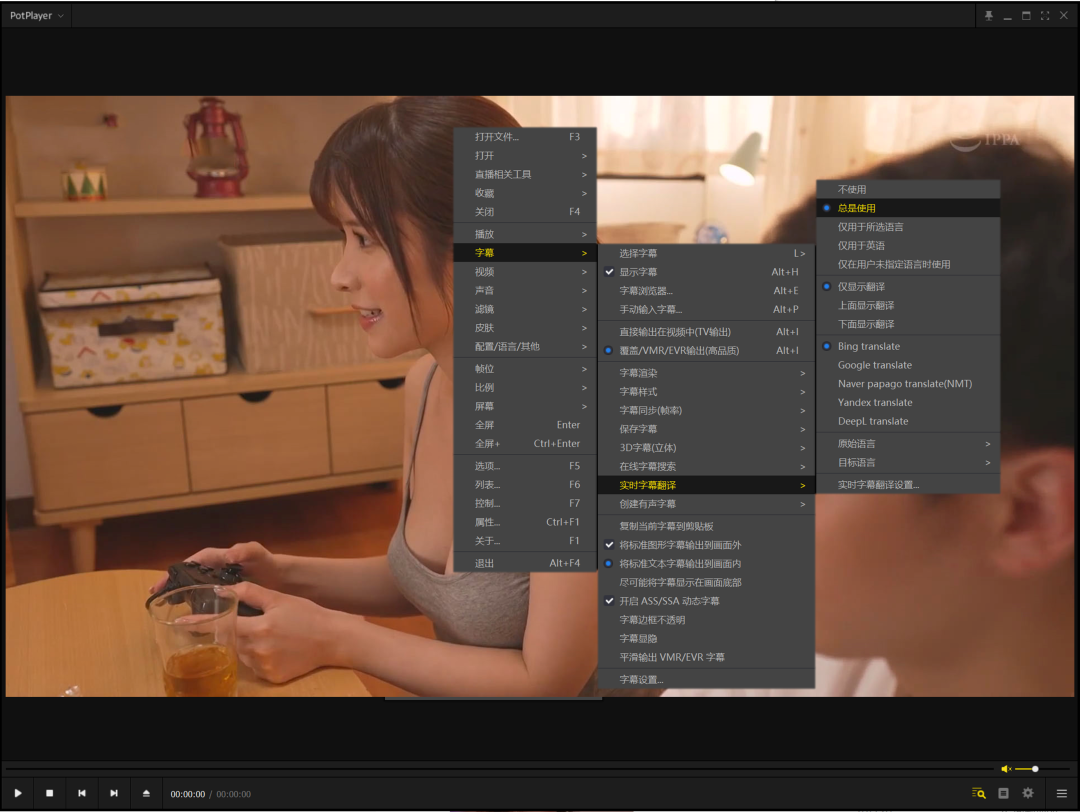
你可以点击上面的“实时字幕翻译设置……”
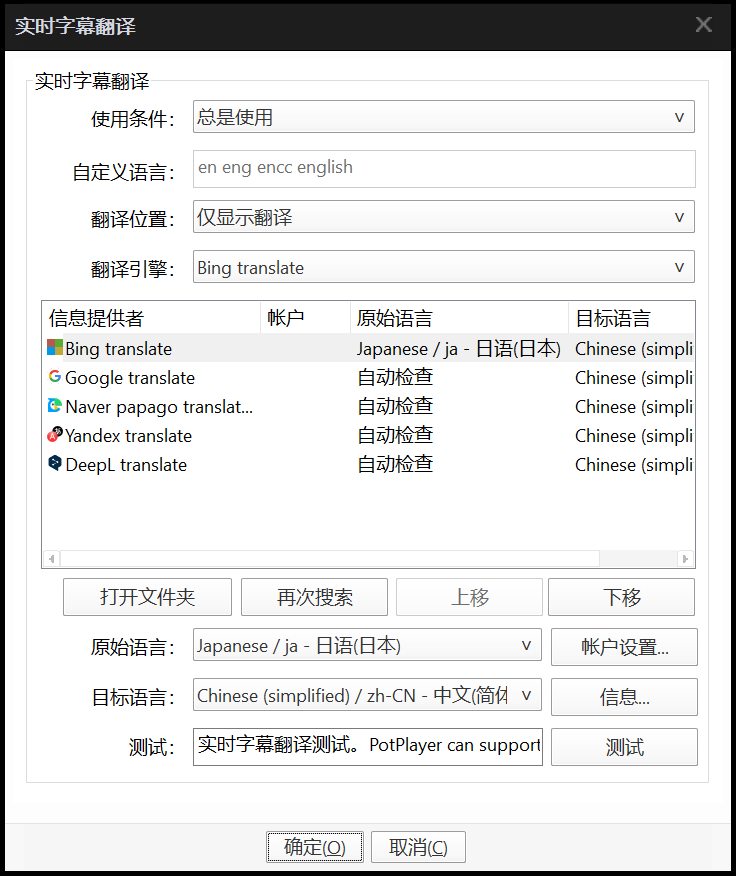
这个不难,有兴趣的同学你自己研究吧。
好了,好了。方法有了,软件也装好了,片呢?
我朋友不肯给我片子啊!
回头翻了下前面几个文章,我也不知道,为什么这几篇文章的阅读量那么高,而且比其他的高得离谱。是不是很多人对这个“不可描述”感兴趣,还是平台热度问题。
要是我这个文章超过100个赞,老子豁出去了,将我朋友摁在地上,开个专栏,让他写那个“学Python”的经过,你懂的!
更多内容,请关注“嵌入式软件实战派”!
看完别走,记得点赞、点关注啊!
相关文章>>>
一块不可描述的硬盘坏了,又不好意思去修……
我在二手硬盘里发现了一堆不可描述的内容
