



英特尔新上任的代工技术开发高级副总裁Navid Shahriari日前出席ISSCC2025并发表主题为“AI时代创新矩阵”全体会议演讲。
Navid Shahriari在演讲中描述了一系列技术,这些技术使该行业能够在从芯片到系统的各个层面取得显著进步。
人工智能浪潮袭来
人工智能为人类带来了变革潜力,增强了人类解决复杂问题的能力、速度和准确性的问题,以及解锁创新和理解。人工智能的闪电般快速发展是历史上前所未有的,这需要从低功耗和边缘AI设备到基于云的系统级快速发展并且在连接它们的通信网络中。对快速AI的需求系统扩展正在推动硅、封装、架构和软件。本演示文稿描述了赋予行业权力的技术矩阵从芯片到系统,在各个层面都取得了显著进展。
人工智能为人类带来了变革潜力,增强了我们快速准确地解决复杂问题的能力,并开启了创新和理解的新领域。人工智能的闪电般快速发展是历史上前所未有的,需要在系统层面迅速发展,从低功耗和边缘人工智能设备到基于云的计算,以及连接它们的通信网络。这种对快速AI系统扩展的需求正在推动硅、封装、架构和软件的创新前沿。
人工智能(AI)的快速发展正在推动传统计算技术的发展到其极限,需要可持续和节能的解决方案,以指数级扩展并行计算系统。计算行业必须满足日益增长的需求计算能力、内存带宽、连接性、高性能基础设施,以及所有领域的人工智能。

如上图所示的技术矩阵,从软件和系统架构到硅和封装,每个领域的进展都是必要的,但整个系统必须共同优化,以最大限度地提高性能、功率和成本。强大的生态系统合作伙伴关系和新颖的设计方法论对于有效的协同优化和更快的上市时间至关重要人工智能变革潜力的舞台。
硅的发展
硅缩放(Silicon scaling)一直是半导体产业进步的根本驱动力,也是创新矩阵的基石。硅路线图得益于非增量晶体管和互连架构的进步、高NA EUV光刻机以及相关的掩模和建模解决方案。每一代技术的功能扩展和改进都以设计技术协同优化(DTCO)过程为指导,该过程设定并推动逻辑、存储器和模拟/混合信号功率、性能、面积(PPA)和成本扩展的整体目标。设计和工艺技术之间的这种迭代循环对于实现持续的硅缩放效益至关重要。
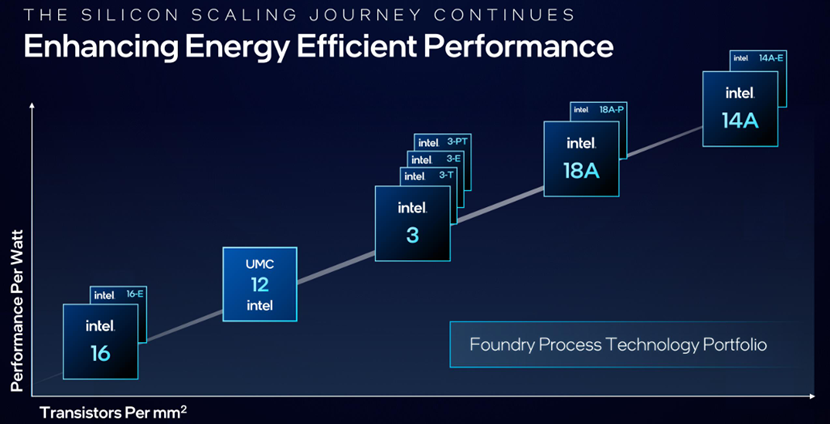
Ribbon-FET是一种全栅极晶体管,超越了FinFET架构,提供了性能扩展和工作负载灵活性。变化的Ribbon宽度在同一技术基础上为不同性能和效率需求提供了定制解决方案。

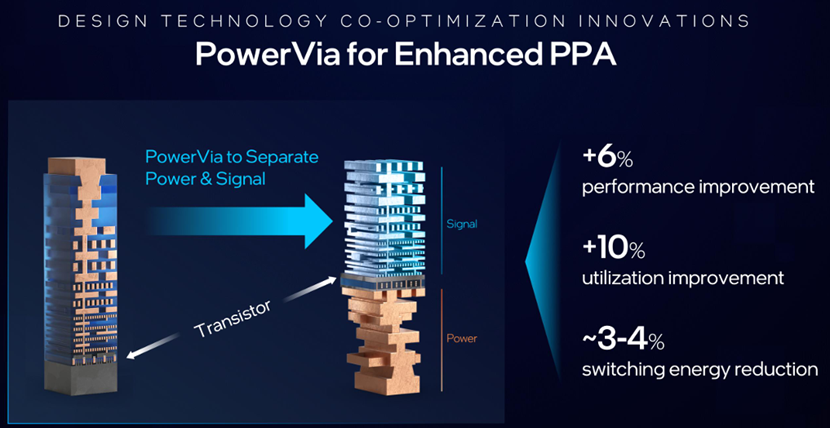
Power Via是一种高产量的背面电源传输技术,将电源传输集成到晶体管中,将IR压降减少5倍,并为信号路由提供额外的正面布线。它满足所有JEDEC热机械应力要求,零故障,在硅中显示出超过5%的频率效益。英特尔18A是英特尔领先的工艺节点,将提供业界首个RibbonFET和PowerVia技术的组合。
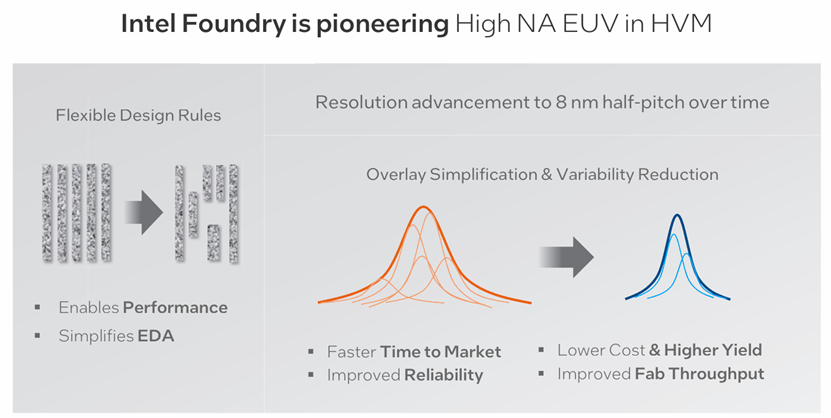
High NA EUV实现了灵活的设计规则,减少了寄生电容并提高了性能。它通过降低设计规则的复杂性和对多模式的需求,简化了电子设计自动化(EDA)的各个方面。Intel 14A正面互连针对高NA单次曝光图案化进行了优化,提高了产量和可靠性。
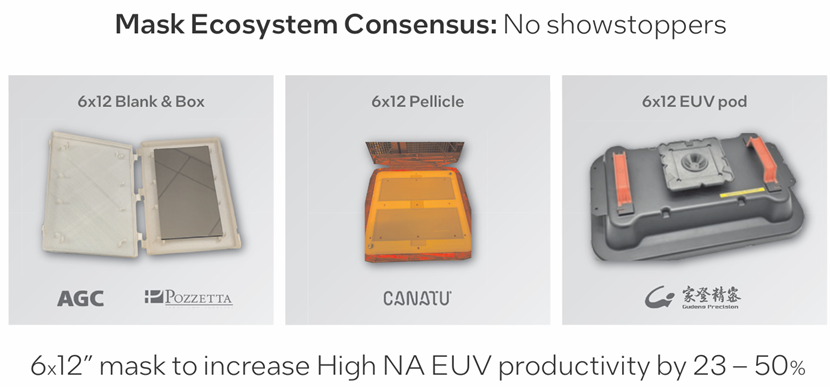
赋能AI构建全场大型应用高NA EUV工具的成像场尺寸较小,但英特尔已经开发出跨边界电缝合芯片的解决方案。EDA生态系统正在创建支持这一点的工具,掩模生态系统正在努力实现无需十字线拼接的全场尺寸能力,将生产率提高23-50%。
高NA EUV光刻需要先进的建模和掩模解决方法。英特尔使用人工智能和机器学习来实现准确性,同时管理计算成本。曲线掩模提高了图案空间利用率、工艺窗口,并显著降低了可变性。
封装
随着数据处理需求的增长,在更小的区域内以更低的能耗实现更高的计算能力至关重要。3DIC技术通过异构集成降低了成本和占地面积,通过更高的带宽提高了性能,并通过垂直堆叠降低了功耗。高级节点上的基片对于实现硅通孔(TSV)和高级接口、无缝集成3D元件至关重要。

封装上的垂直和横向互连必须继续扩展,为带宽增长和提高能效提供更高的互连密度。具有成本效益的互连扩展,结合使用基于标准化的链接,如UCIe,对于创建一个即插即用的小芯片生态系统至关重要,该生态系统将实现产品多样性和定制。成熟使用玻璃来缩放封装基板互连几何形状、尺寸和信号特征是一个重要的技术载体。
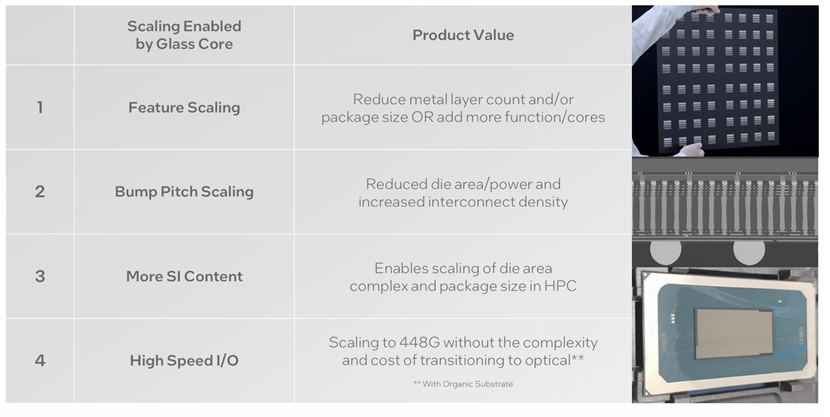
必须通过提高系统级功率传输效率和通过组件和系统级创新扩大热包络来解决人工智能应用对不断增长的功率需求。

随着特征尺寸和制造工艺的重叠,先进的封装技术正在以一种封装和硅后端互连之间的边界越来越模糊的方式发展。此外,该包变成了一个复杂的异构结构。制造和测试过程必须不断发展,以确保产量保持较高水平。
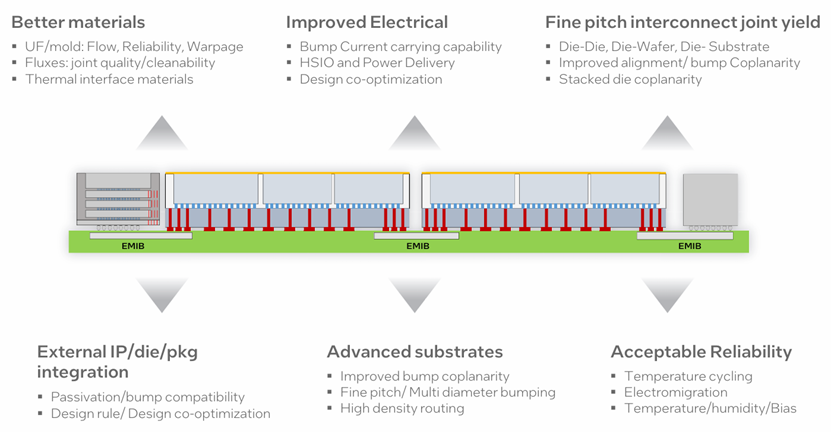
一个模块化设计环境,允许直接组装多硅共封装系统,优化成本、性能和带宽,这一点至关重要。需要全面的EDA工具和流程功能来跨管芯进行设计划分,实现成功的协同设计以及管芯和封装的优化。目前的3DIC设计流程缺乏热应力和机械应力建模,导致潜在的故障和影响上市时间的重新设计工作。3DIC设计工具必须涵盖实施、提取、可靠性和验证,以确保无缝集成。

互连
并行AI工作负载的指数级扩展给互连带宽密度、延迟和功耗带来了压力。通过将组件与密集的2.5D和3D装配技术更紧密地集成,所有这三个指标都得到了改善。新的封装技术通过最大限度地减少GPU之间非常昂贵的(在成本和功耗方面)互连,提供了更好的总体拥有成本(TCO)。传输每个数据比特的能量随信道损耗而变化。这种权衡推动了低功耗、高密度封装内通信的UCIe等行业规范的定义。UCIe在<1pJ/bit的情况下,每毫米管芯周长可达1.35TB/s。
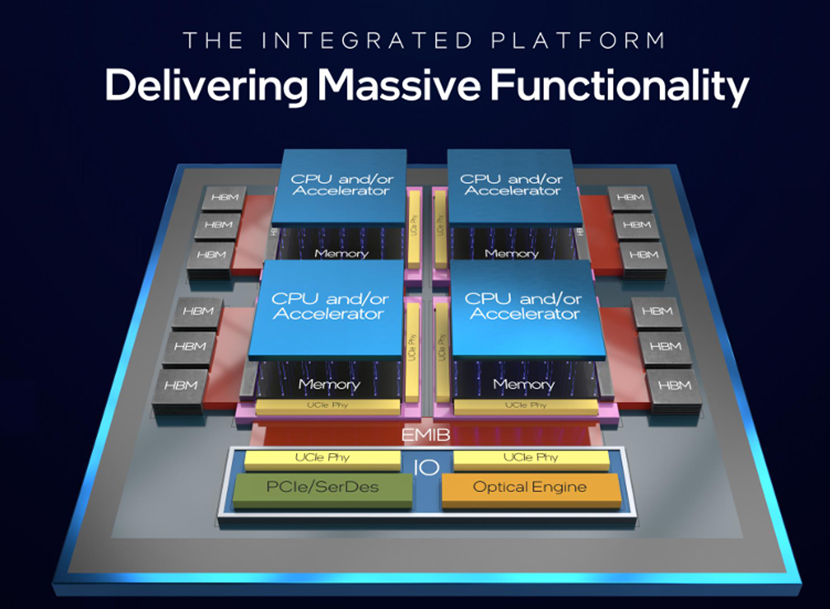
主板和机架内的较长互连构成了扩展网络拓扑中的高带宽域,需要增加数据序列化以考虑实际的连接器信号密度,从而扩展聚合带宽。串行全通道数据速率每3-4年扩展2倍,包括以太网、PCIe和OIF-CEI等行业规范。最新生产的有线SerDes已达到212Gb/s PAM4,支持4-6pJ/bit的机架内(约1米范围)通信。模拟电路和数字均衡的每比特能量都继续受益于工艺技术的扩展。
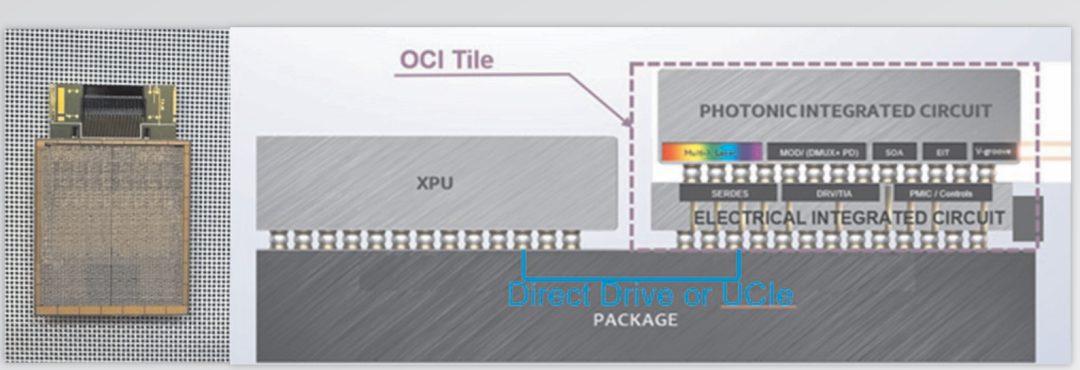
随着有线互连数据速率的不断扩大,由于更高符号率下的信道损耗更高,SerDes重定时器之间可以桥接的距离减小。添加更多的重定时器可以扩展覆盖范围,但会增加功耗、延迟和成本。这种经验权衡导致了从海底电缆到机架到机架网络的一系列应用中采用了光互连。此外,使用光学器件将高带宽域的范围扩展到机架之外与人工智能的扩展网络战略相一致。因此,光学互连需要移动到机架中以扩展带宽,并达到可接受的功率包络。
正在开发诸如共封装光学器件(CPO)和直接驱动线性光学器件等技术来实现这一转变。英特尔最近展示了一个基于英特尔内部硅光子学技术和224Gb/s PAM4的4Tb/s(每个方向8根光纤×8个波长/光纤×2Gbps/波长)双向全集成光计算互连(OCI)小芯片,该芯片在23km光纤上具有直接驱动线性光学元件。全行业正在努力加快这一机架内光互连生态系统的发展,开发高产量的制造工艺、材料和设备,同时提高带宽密度、总功率、可靠性和成本。
电力输送
像AI这样的并行工作负载的每包功耗正在迅速扩大。为封装供电的一种常见方法是主板电压调节器(MBVR)。这些调节器将板级电源(例如12V)降压至封装上的管芯所使用的电压(VOUT)。无论是位于封装旁边(横向MBVR)还是封装下方(垂直MBVR),MBVR提供的电流密度都无法跟上未来高性能芯片的步伐。此外,调节器效率随着功率和电流的增加而降低(I2R损耗),从而降低了系统性能。需要解决方案,使电压转换更接近具有高电流密度、转换效率和调节带宽的管芯。
一种解决方案是使用完全集成的电压调节器(FIVR),将功率转换的最后一步带到封装上。在封装上进行最终电压降压可以通过降低给定功率的电流来减少将电源轨布线到封装上时的能量损失。十多年前,英特尔首次在Haswell产品中引入FIVR,使用密集的片上电容器和空心封装电感器。
第一代FIVR将1.8V输入电源轨转换为多个管芯上电压域。在过去的十年中,这种架构已被用于许多产品中,并不断改进,如更密集的封装内磁电感器和片上电容器。除了集成到SoC中的FIVR外,英特尔还开发了一种基于CMOS的独立2.4V IVR小芯片,该芯片使用英特尔的高密度电容器(HDMIM)技术开发了一个具有连续可扩展电压转换比的开关电容电压调节器(SCVR)。
使用现有的MBVR架构,封装功率容量进一步扩大到1-2kW以上,将导致稳压器效率出现不可接受的下降。通过将高压(12V)电源转换集成到封装上,可以缓解这个问题。12V稳压器集成将减少输送到封装中的电流,从而降低I2R损耗。一种有前景的方法是将封装上的高压(12V)开关电容电压调节器(SCVR)与较低电压(1.8-2.4V)IVR配对,进行两步转换。这种两步架构的功率密度和效率依赖于密集的封装无源器件,如嵌入式深沟槽电容器(eDTC)和磁电感器,以及密集的管芯上电容器。
使用氮化镓(GaN)等宽带隙工艺技术可以使高压转换器比硅基解决方案具有更高的效率和密度。然而,功率转换器的封装实现需要更高的开关频率和集成驱动器,这在纯GaN工艺上是不支持的。用硅CMOS制造GaN器件可以为高压功率转换器的封装集成开辟更多机会,因为它可以在同一芯片上设计CMOS驱动器和GaN功率FET。为此,英特尔最近展示了一种将硅基氮化镓技术结合在同一个300mm晶片上的技术。该技术可以支持输入电压高达12V的高压IVR选项,使功率扩展超过1-2kW。
架构和软件
下一代计算架构必须推动系统性能指标(如每瓦性能)的指数级改进,同时解决热和电源完整性挑战。创新应通过先进的封装和硅工艺堆叠和互连晶圆和小芯片,实现有凝聚力的系统。此外,它们必须支持各种工作负载的自定义加速器的无缝集成。
软件是创新矩阵的重要组成部分,必须通过开源生态系统中的协作、标准化和互操作性来推进。自动化应增强安全性并简化流程,而高度优化的软件对于高效利用硅资源至关重要。在数千个GPU上分发软件会带来巨大的带宽和延迟挑战,比如高性能计算。人工智能软件将是微调系统元素、确保无缝集成和实现显著进步的关键。
超越传统计算
神经形态和量子计算等技术对于扩大人工智能所需的效率和速度的突破至关重要。自2018年以来,全球250多个实验室使用的英特尔Loihi研究芯片表明,采用CMOS工艺技术制造的神经形态芯片可以为广泛的示例算法和应用带来数量级的收益。虽然其中许多例子涉及目前与当今软件和人工智能方法不兼容的新型大脑启发算法,但一类新兴技术表明,在不久的将来,目前广泛使用的深度学习和变换器方法将实现1000倍的增益。这些神经形态创新对于将先进的人工智能功能扩展到实时环境中运行的功率、延迟和数据受限的智能设备至关重要。
量子计算代表了一种新的范式,它利用量子物理学的力量以比传统计算快得多的速度解决复杂问题。它有望彻底改变行业,解决包括气候变化在内的关键问题;化学工程;药物设计和发现;金融;以及航空航天设计。在将这项变革性技术从实验室过渡到工程领域方面取得稳步进展,为有用的、短期的应用提供客户解决方案,这一点至关重要。英特尔独特的量子研究方法涵盖了整个计算栈,包括量子比特制造、用于量子比特控制的低温CMOS技术、软件、编译器、算法和应用程序。凭借50多年的大规模晶体管制造经验,英特尔正在利用其成熟的技术开发硅自旋量子比特,作为量子计算可扩展性的最佳途径。英特尔还投资于定制设计的低温探测器等功能,这些功能大大加快了英特尔的量子测试和验证工作流程。
量子计算硬件的当前状态还不具备对当今人工智能产生直接影响的鲁棒性和规模。人工智能与量子计算机的另一个挑战是如何将大量数据输入这些复杂的机器。然而,一旦我们有了可扩展的容错量子计算机,就会有明显的好处。量子计算机可以比经典计算机更快地执行复杂的计算,这可以更快地训练和分析人工智能模型。量子计算的两个关键原理是叠加和纠缠,这使得可以同时探索多个解决方案,这可以直接有利于人工智能模型的训练和优化。并行分析大量数据的可能性也可以提高人工智能识别模式的能力,例如在图像或语音中。可以开发直接优化以利用量子特性的新AI算法,而不是使用经典的AI算法。最后,量子计算机不应被视为经典计算机的替代品,而应被视作为特殊应用的计算加速器。因此,未来人工智能的系统解决方案可能会利用经典计算和量子计算的混合实现。
生态系统协作
快速开发下一代高级计算系统将需要整个行业生态系统在这一创新矩阵上进行协作。从制造到设计工具,从知识产权到系统设计再到软件,与整个技术栈的最终用户和合作伙伴互动,确保开发过程符合市场需求和时间表,环境可持续,并利用整个生态系统的关键学习和发展。系统级协同优化需要密切协作才能实现快速进展。跨学科的专业知识和跨战略伙伴关系的知识共享对于有效解决问题和加快发展周期至关重要。利用跨行业优势并避免重复工作将使团队能够更有效地工作。

行业挑战与机遇
近二十年前,CPU时钟频率缩放面临着一个困境——对指数级性能改进的持续追求在功率密度方面遇到了障碍。其结果是一套新的并行处理器架构,以及一系列支持硅、封装和散热、互连、电源传输和核心架构的技术。今天,我们处于类似的情况,指数级性能扩展(这次是为了支持人工智能)在功率、连接性和成本方面遇到了根本性的挑战。再一次,我们系统的增量扩展是不够的,我们将需要新的方法来解决这个问题——人工智能创新矩阵。从工艺技术扩展到3DIC系统设计,再到电源传输、互连和核心架构,都不乏工程挑战。我们需要这些领域创新的综合效益,以可制造、可持续和经济高效的方式满足行业对计算能力的需求。

