



自2024年起,DeepSeek在AI领域迅速崛起并不断迭代。从年初发布初始版本,到后DeepSeek持续迭代升级时间模型名称模型类型主要特点持续迭代升级续融入数学、视觉语言技术的版本,技术实力稳步提升。2024年12月底至2025年1月底,更新尤为密集,发布了参数众多且性能提升的V3、支持思维链输出和模型训练的R1,以及深耕图像领域的视觉和多模态模型。

DeepSeek 的产品体系不断丰富,每个模型都在不同的领域和任务中展现出了独特的优势和性能特点。随着时间的推移,DeepSeek 在不断优化模型性能的同时,也在推动着人工智能技术的发展和应用。
DeepSeek 产品技术特点
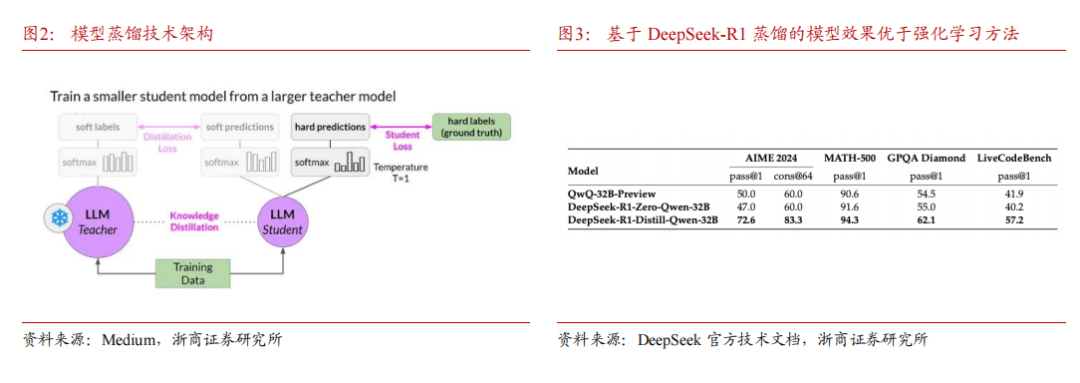
DeepSeek 采用模型蒸馏技术,极大提升模型推理能力。DeepSeek 官方技术文档显示,研究人员使用 DeepSeek 模型遴选了 80 万个样本,并且基于 DeepSeek-R1 模型的输出对阿里 Qwen 和 Meta 的 Llama 开源大模型进行微调。评测结果显示,基于 DeepSeek-R1 模型蒸馏的 32B 和 70B 模型在多项能力上可对标 OpenAI o1-mini 的效果。DeepSeek 研究结果表明,蒸馏方法可以显著增强小模型的推理能力。
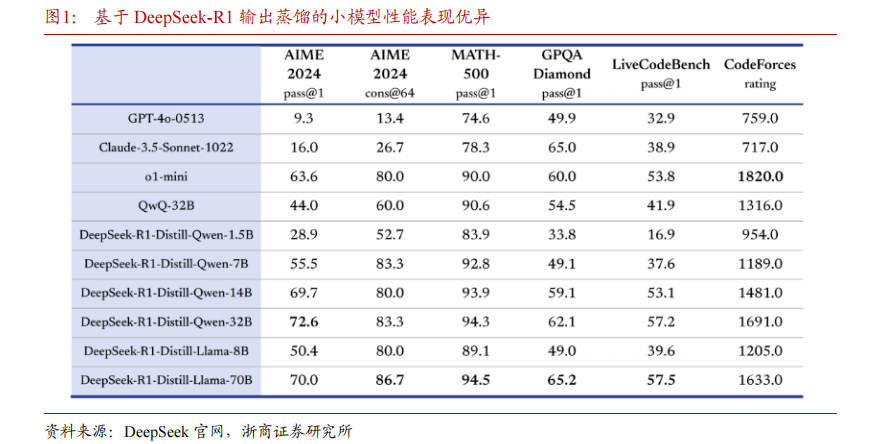
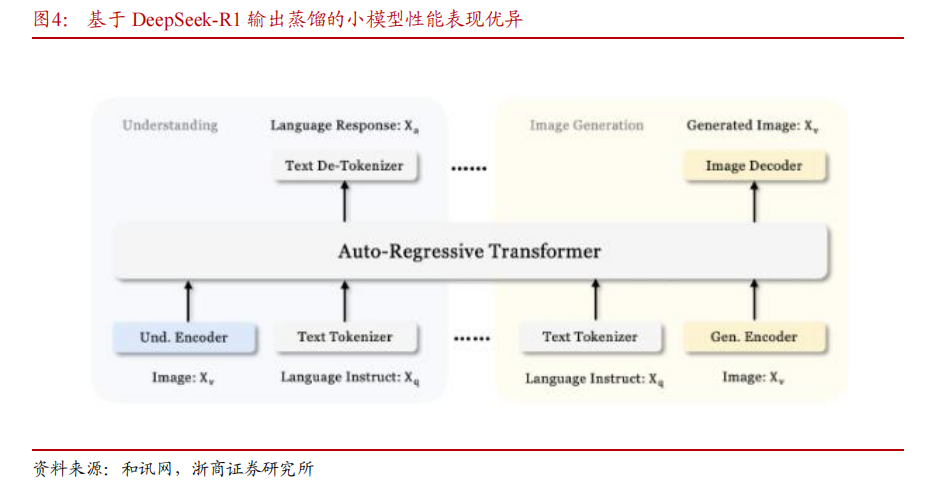
DeepSeek 采用蒸馏技术得到的模型效果优于同等条件下使用强化学习(RL)的效果。技术文档显示,DeepSeek-R1-Zero-Qwen-32B 模型是研究人员在 Qwen-32B-Base 模型基础上使用数学、代码、STEM 数据进行超过 10,000 步的 RL 训练得到,其各项测评结果均差于 DeepSeek-R1 模型通过蒸馏得到的 DeepSeek-R1-Distill-Qwen-32B 模型。考虑 RL 方法需要大量的计算资源,蒸馏方法在性能和性价比方面均呈现出显著的优势。
Janus-Pro 是 DeepSeek 发布的一款统一多模态理解与生成的创新框架,通过解耦视觉编码的方式,极大提升了模型在不同任务中的适配性与性能。其中,Janus-Pro 的 SigLIP编码器专门负责理解图像,能提取图像的高层语义特征,并关注图像的整体含义和场景关系;而 VQ tokenizer 编码器,专门用于创作,将图像转换为离散的 token 序列,这样架构创新使得 Janus-Pro 在 7B 参数规模下,仅用 32 个节点、256 张 A100 和 14 天的时间就完成训练并取得出色性能表现。
DeepSeek-V3通过算法创新和工程优化大幅提升模型效率,从而降低成本,提高性价比。
1)从算法创新层面来看,DeepSeek-V3采用了自主研发的MoE架构,总参数量达671B,每个token激活37B参数,实现多维度对标GPT-40。其稀疏专家模型MoE,拓展至256个路由专家加1个共享专家,每个token激活8个路由专家、最多被发送到4个节点,并引入冗余专家部署策略,实现推理阶段MoE不同专家间的负载均衡,还提出无辅助损失的负载均衡策略,减少性能下降。
此外,多头注意力机制MLA围绕推理阶段的显存、带宽和计算效率展开,通过创新底层软件架构,引入数学变换减少KV-cache内存占用,缓解transformer推理时的显存和带宽瓶颈,优化注意力计算方式,进一步提高效率。同时,采用创新训练目标MTP,让模型训练时一次性预测多个未来令牌,扩展预测范围,增强对上下文的理解能力,优化训练信号密度,将推理速度提升1.8倍。
2)在工程优化方面,DeepSeek-V3创新性地大范围落地FP8+混合精度策略,计算精度从主流的FP16降到FP8,保留混合精度策略,在重要算子模块保留FP16/32保证准确度和收敛性,兼顾稳定性和降低算力成本。
3)在解决通信瓶颈问题上,采用DualPipe高效流水线并行算法,实现接近于0的通信开销。
据DeepSeek-V3的技术文档,该模型使用数据蒸馏技术生成的高质量数据提升了训练效率。通过已有的高质量模型来合成少量高质量数据,作为新模型的训练数据,从而达到接近于在原始数据上训练的效果。DeepSeek发布了从15亿到700亿参数的R1蒸馏版本。这些模型基于Qwen和Llama等架构,表明复杂的推理能力可以被封装在更小、更高效的模型中。
蒸馏过程包括使用由完整DeepSeek-R1生成的合成推理数据对这些较小的模型进行微调,从而在降低计算成本的同时保持高性能。让规模更大的模型先学到高水平推理模式,再把这些成果移植给更小的模包。
英伟达、微软等巨头携手 DeepSeek,推动 AI 落地革新
国内外芯片厂商和云服务厂商迅速响应,纷纷接入 DeepSeek 模型,在海外,以英伟达、微软、亚马逊为首的科技巨头率先采用 DeepSeek,在国内,腾讯云和华为云已经上线DeepSeek 相关服务。
英伟达:2025 年 1 月 31 日,英伟达(NVIDIA)宣布,NVIDIA NIM 已支持使用 DeepSeek - R1。
微软:2025 年 1 月 30 日,微软宣布已将 DeepSeek - R1 正式纳入 Azure AIFoundry,成为该企业级 AI 服务平台的一部分。微软强调,DeepSeek - R1 模型已通过 “严格的红队测试与安全评估”,并历经 “模型行为自动化检测与广泛的安全审查” 以降低潜在风险。
亚马逊:2025 年 1 月 31 日,亚马逊表示 DeepSeek - R1 模型已可在 AmazonWeb Services 上使用,这一合作彰显了 DeepSeek 模型在云计算场景中的价值,有助于亚马逊为用户提供更具创新性和高效性的 AI 技术,提升用户在电商、数据分析等领域的体验,推动业务发展。
腾讯云:2025 年 2 月 2 日,腾讯云宣布将 DeepSeek-R1 大模型一键部署至其HAI 平台,开发者仅需 3 分钟即可完成接入。这一举措降低了开发者使用DeepSeek-R1 模型的门槛,使得更多基于该模型的创新应用能够快速开发和部署。借助腾讯云 HAI 平台的强大算力和丰富的生态资源,DeepSeek-R1 模型有望在内容创作、智能客服、数据分析等多个领域发挥更大的作用,为腾讯云的用户提供更加智能化的服务。
华为云:2025 年 2 月 1 日,硅基流动和华为云团队联合首发并上线基于华为云昇腾云服务的 DeepSeekR1/V3 推理服务。
国产大模型推理能力提升,加速在应用端落地
DeepSeek 最新版模型展现出来的优异能力,表明国内大模型推理能力提升到一个新的阶段,大模型在各领域的应用有望加速加速落地。我们认为,DeepSeek 给 AI 研究和企业端应用都将带来革新。
以秘塔 AI 搜索为例,在融合 DeepSeek-R1 后,实现了 “国产最强推理 + 全网实时搜索 + 高质量知识库” 的结合,在多个方面利用 DeepSeek 技术提升用户体验:
处理复杂问题:借助 DeepSeek-R1 强大的复杂推理能力,结合自身的联网检索和海量知识库 / 论文数据,处理复杂查询。
提升专业知识查询能力:在查询专业知识时,如 OpenAI 模型进展相关问题,秘塔 AI 搜索可利用 DeepSeek 的推理能力深入分析资料。
优化搜索结果质量:对接 DeepSeek-R1 的推理能力后,秘塔 AI 搜索可以更准确地理解用户查询意图,处理多条件筛选、语义模糊等复杂查询,返回更快速、相关、精准的信息结果。同时,通过分析信息来源和内容逻辑性,过滤谣言等虚假信息,增强搜索结果的真实性和可靠性。
助力深度知识挖掘:让 DeepSeek-R1 拥有 AI 联网搜索及背后的高质量索引库,能够实时查询最新资料,全网搜罗、分析各种论文并形成思维导图汇总,满足用户从查询一项研究 / 技术的最新进展到纵观一个学科技术发展历程等多样需求。
下载链接:
8、《3+份技术系列基础知识详解(星球版)》
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
【华为】AI Ready的数据基础设施参考架构白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


