



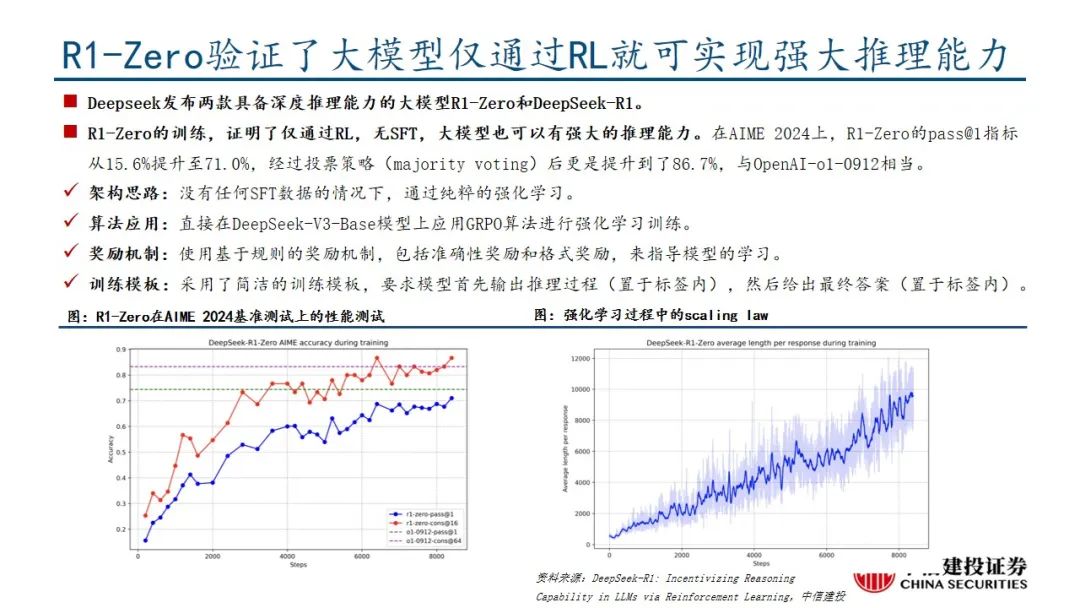
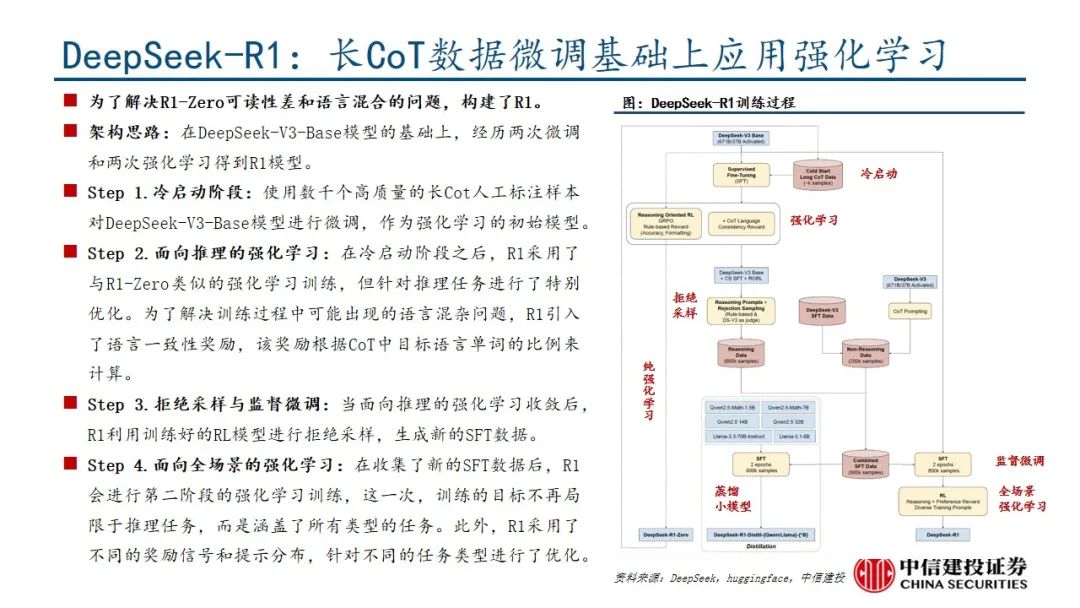
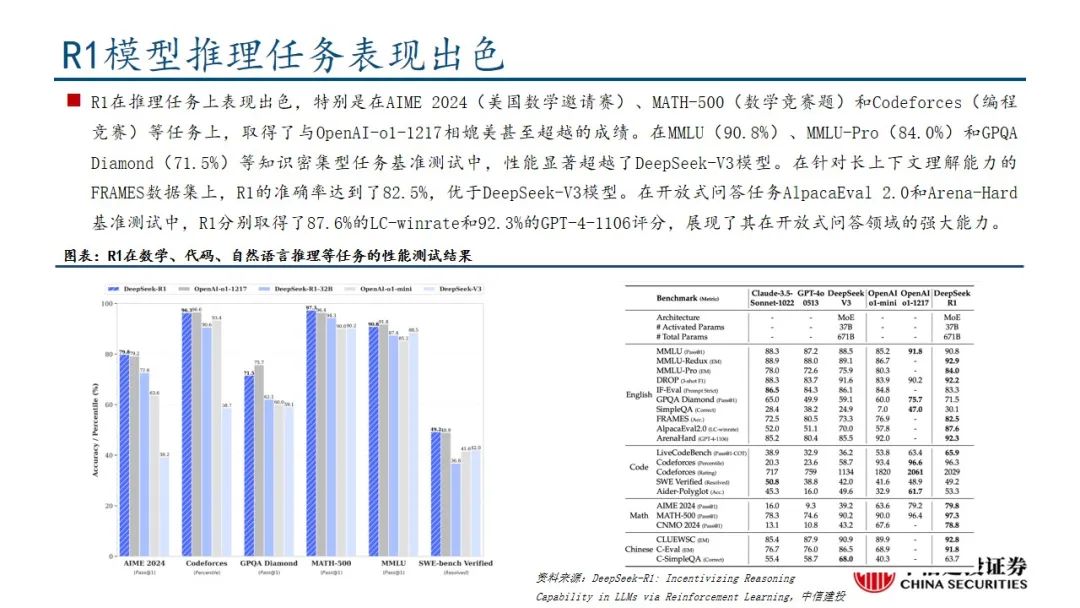
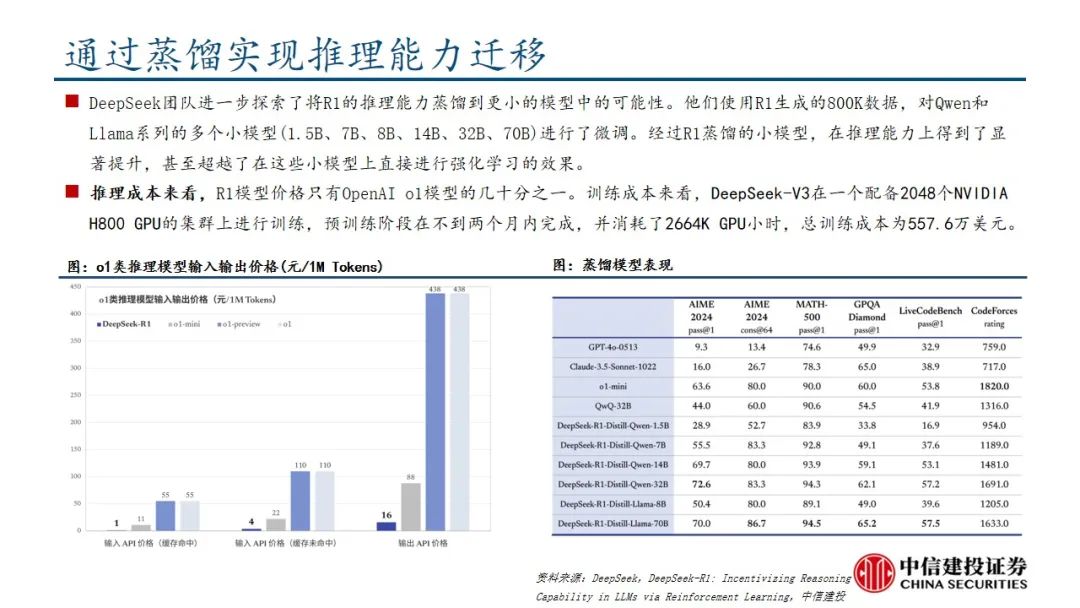
本文来自“DeepSeek R1深度解析及算力影响几何”,Deepseek发布深度推理能力模型。R1-Zero采用纯粹的强化学习训练,证明了大语言模型仅通过强化学习也可以有强大的推理能力,DeepSeek-R1经历微调和强化学习取得了与OpenAI-o1-1217相媲美甚至超越的成绩。
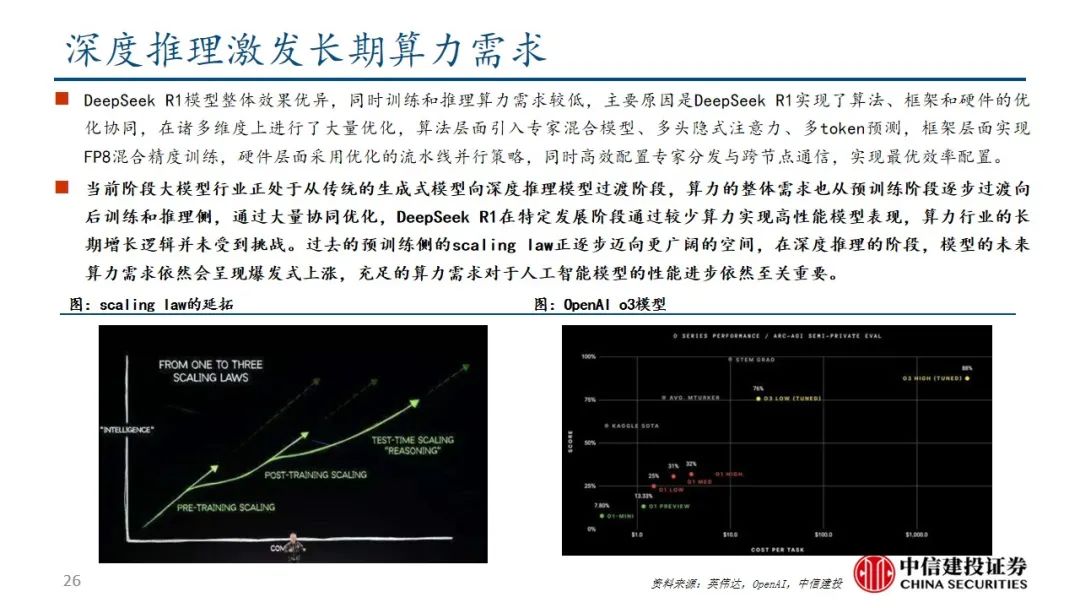
DeepSeek R1训练和推理算力需求较低,主要原因是DeepSeek R1实现算法、框架和硬件的优化协同。过去的预训练侧的scaling law正逐步迈向更广阔的空间,在深度推理的阶段,模型的未来算力需求依然会呈现爆发式上涨,充足的算力需求对于人工智能模型的性能进步依然至关重要。
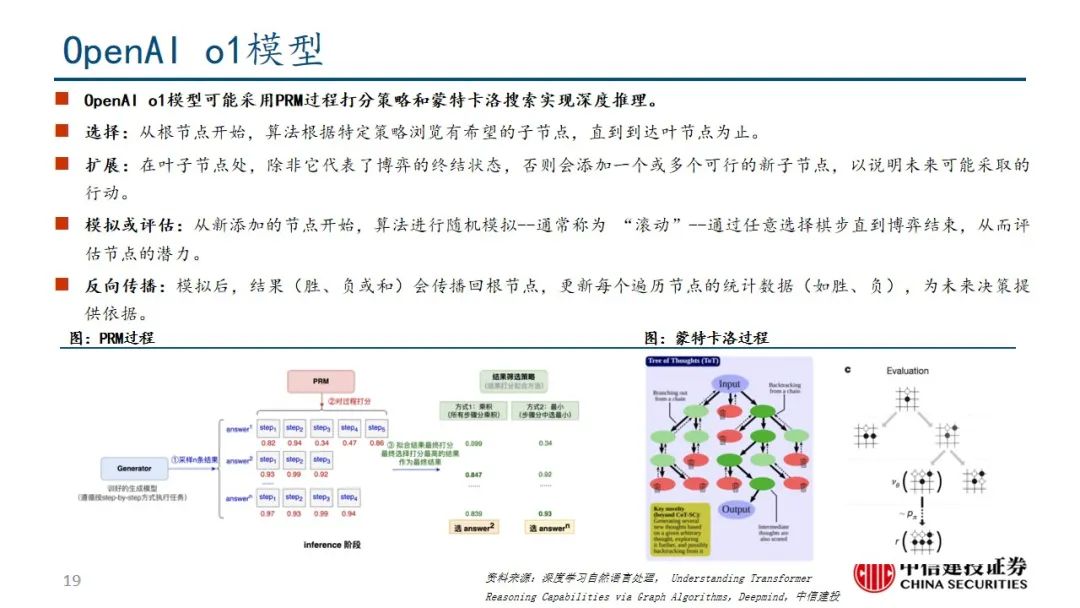
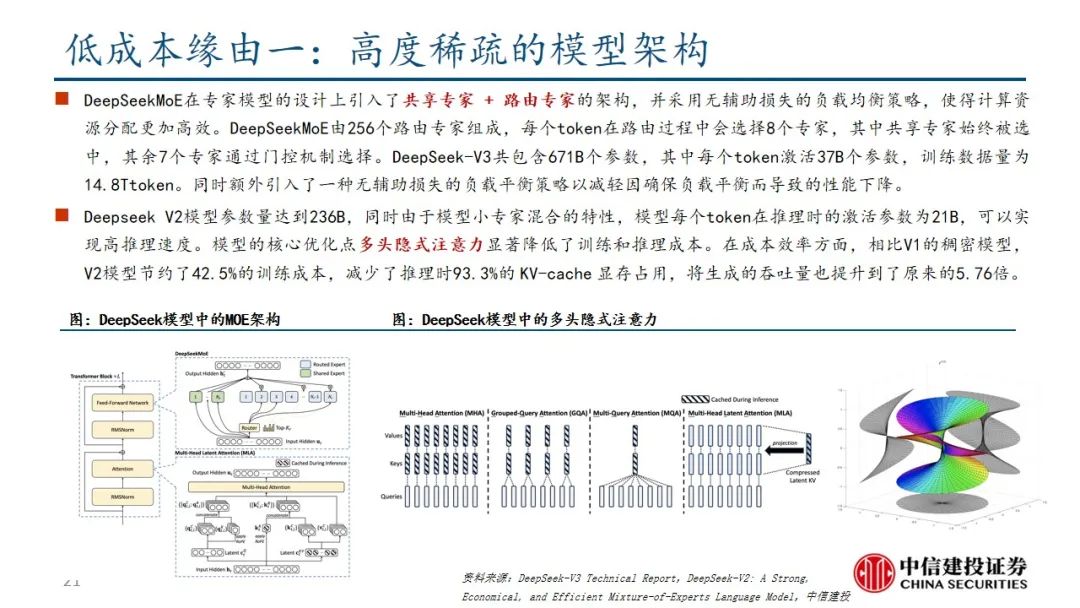
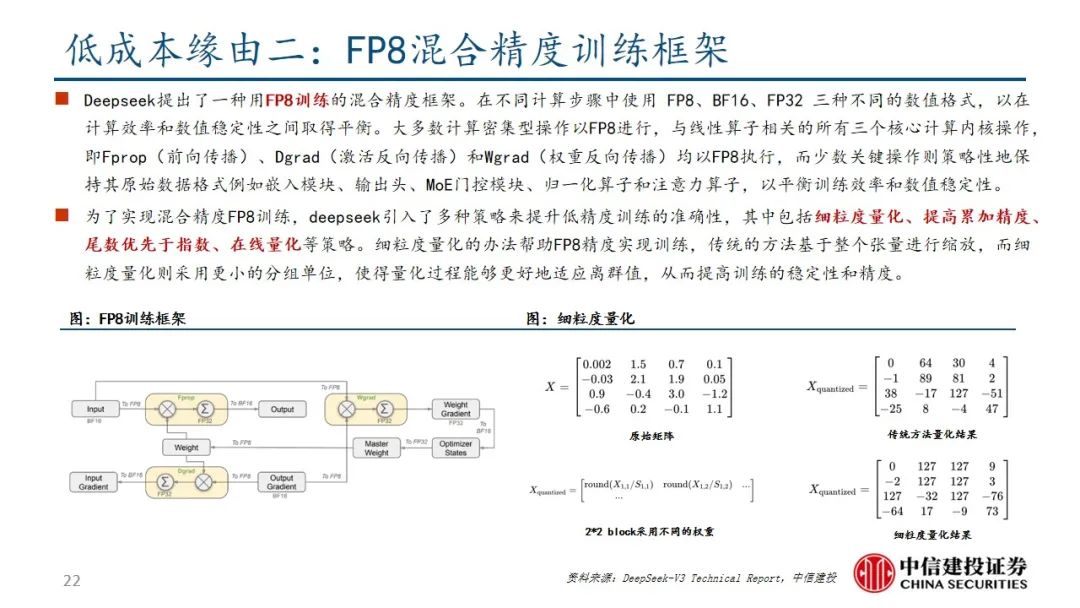
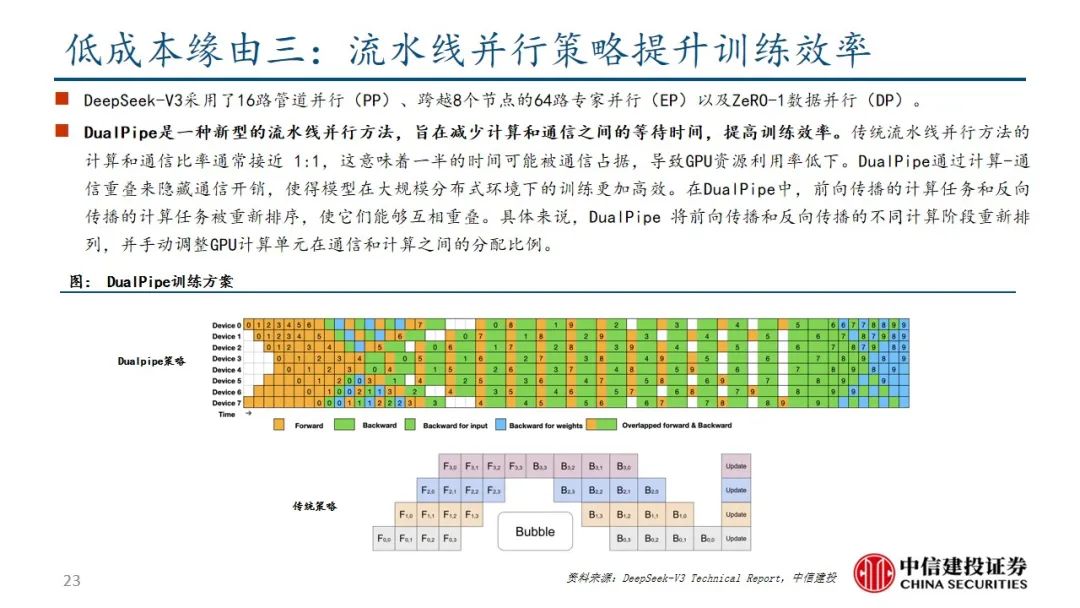
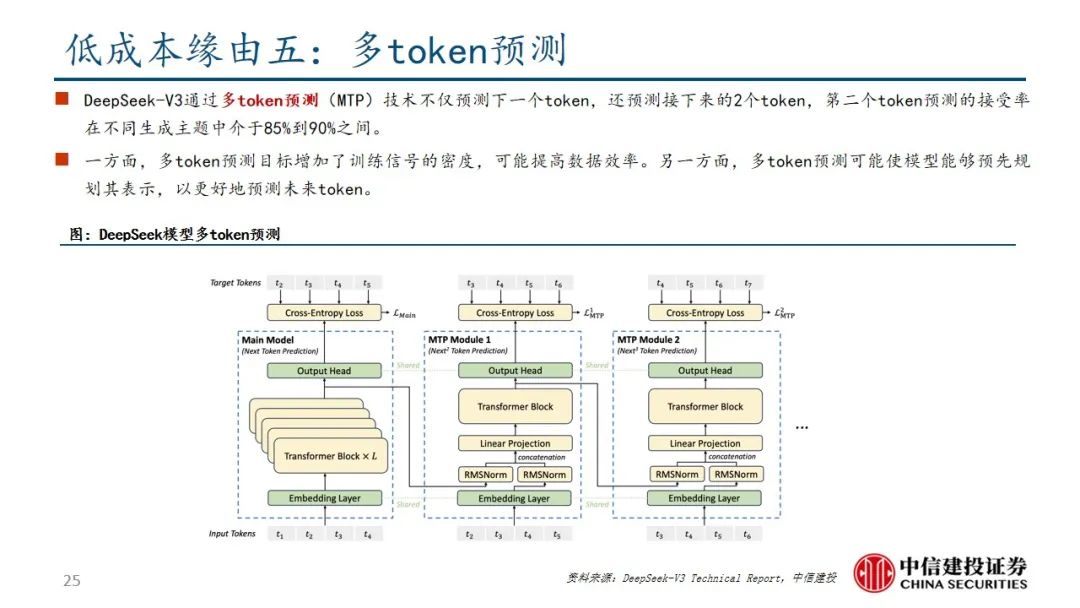
DeepSeek R1在诸多维度上进行了大量优化,算法层面引入专家混合模型、多头隐式注意力、多token预测,框架层面实现FP8混合精度训练,硬件层面采用优化的流水线并行策略,同时高效配置专家分发与跨节点通信,实现最优效率配置。当前阶段大模型行业正处于从传统的生成式模型向深度推理模型过渡阶段,算力的整体需求也从预训练阶段逐步过渡向后训练和推理侧,通过大量协同优化,DeepSeek R1在特定发展阶段通过较少算力实现高性能模型表现,算力行业的长期增长逻辑并未受到挑战。












下载链接:
8、《3+份技术系列基础知识详解(星球版)》
9、《60+份DeepSeek技术报告合集》
亚太芯谷科技研究院:2024年AI大算力芯片技术发展与产业趋势
【华为】AI Ready的数据基础设施参考架构白皮书
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


