

 数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别,大大缩短了业务处理时间,提升了工作效率和质量。另一个重要的原因是,对于编程来说入门是打印一个HelloWorld,但是深度学习入门就是实现一个手写数字的识别~
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别,大大缩短了业务处理时间,提升了工作效率和质量。另一个重要的原因是,对于编程来说入门是打印一个HelloWorld,但是深度学习入门就是实现一个手写数字的识别~

任务输入:一系列手写数字图片,其中每张图片都是28x28的像素矩阵。
任务输出:经过了大小归一化和居中处理,输出对应的0~9数字标签。
在处理如 图1 所示的手写邮政编码的简单图像分类任务时,可以使用基于MNIST数据集的手写数字识别模型。MNIST是深度学习领域标准、易用的成熟数据集,包含60000条训练样本和10000条测试样本。
MNIST数据集是从NIST的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST训练集和测试集,其中训练集来自250位不同的标注员,且训练集和测试集的标注员完全不同。
MNIST数据集的发布,吸引了大量科学家训练模型。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验使得测试集的误差不断下降(从12%下降到0.7%)。在研究过程中,LeCun提出了卷积神经网络(Convolutional Neural Network,CNN),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。
如今在深度学习领域,卷积神经网络占据了至关重要的地位,从最早LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等,人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。
手写数字识别的模型是深度学习中相对简单的模型,非常适用初学者。
使用飞桨完成手写数字识别模型构建的代码结构如 图2 所示
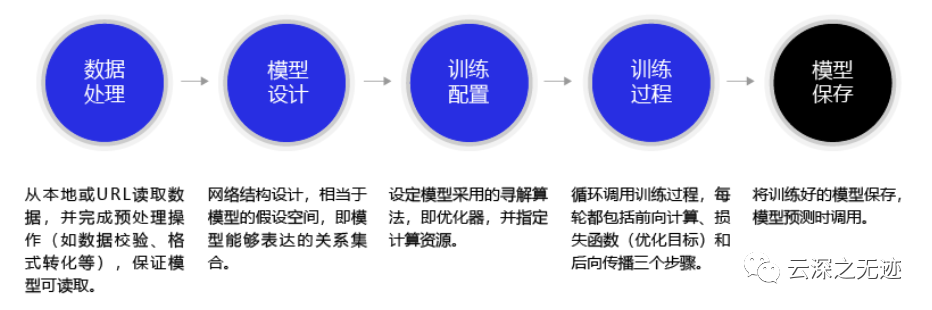 训练的流程
训练的流程

我们这次训练,用GPU,嘤嘤嘤

看看我的GPU还好吗~

这个是我们今后做实验的流程图
import paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Linearimport numpy as npimport osfrom PIL import Image
在进入训练环境之后,需要导入的Python库有这些
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/data_cn/dataset_cn.html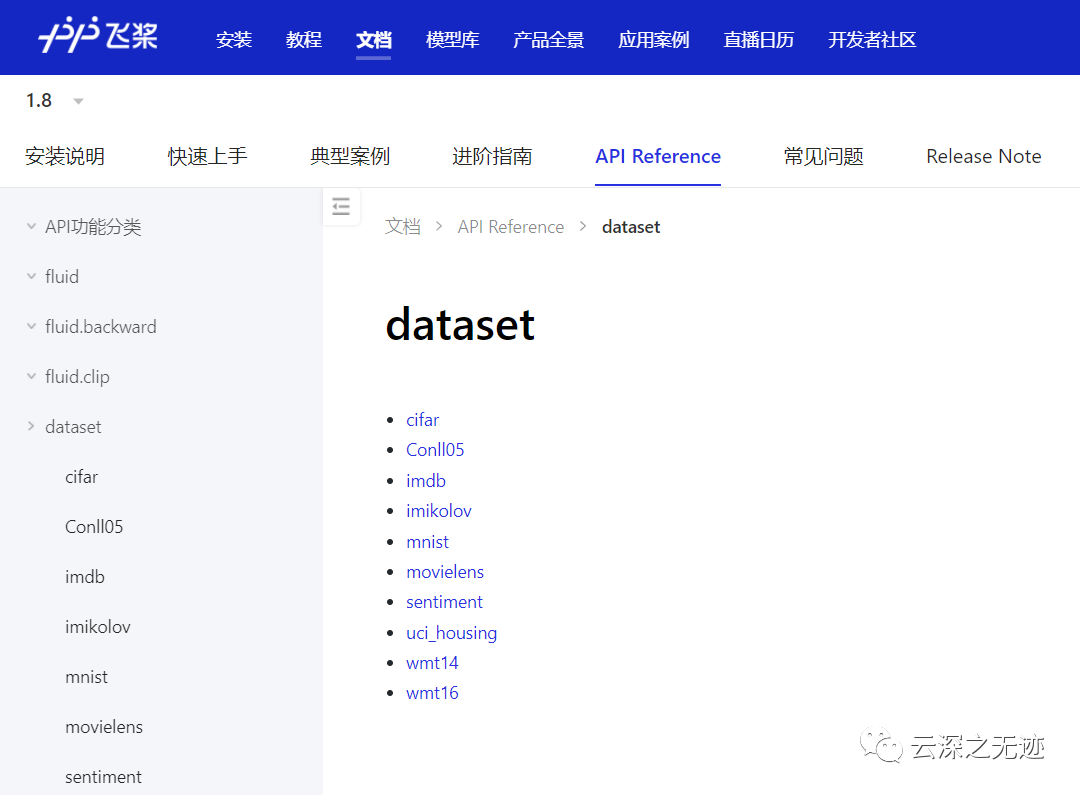
相关要处理的数据在这个网址里有,相关的API也封装好了
# 如果~/.cache/paddle/dataset/mnist/目录下没有MNIST数据,API会自动将MINST数据下载到该文件夹下# 设置数据读取器,读取MNIST数据训练集trainset = paddle.dataset.mnist.train()# 包装数据读取器,每次读取的数据数量设置为batch_size=8train_reader = paddle.batch(trainset, batch_size=8)
通过paddle.dataset.mnist.train()函数设置数据读取器,
batch_size设置为8,即一个批次有8张图片和8个标签.
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-images-idx3-ubyte.gzBegin to downloadDownload finishedCache file /home/aistudio/.cache/paddle/dataset/mnist/train-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-labels-idx1-ubyte.gzBegin to download........Download finished
这个是下载好的输出结果
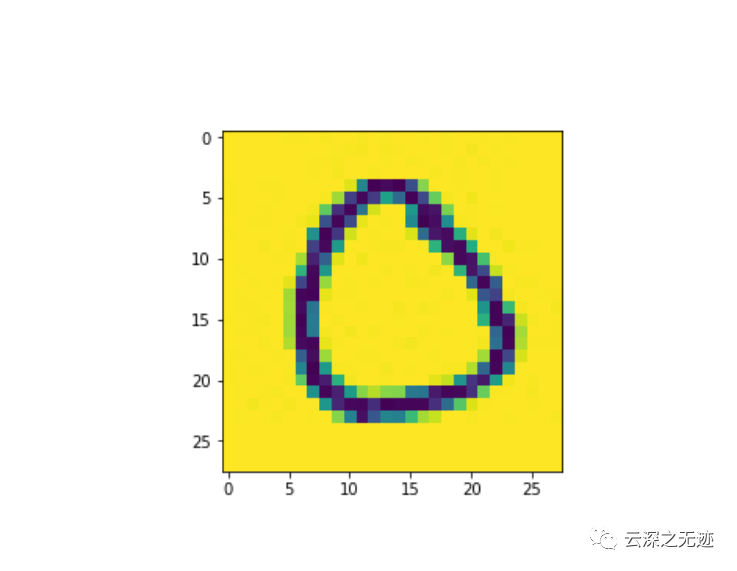
长这个样的
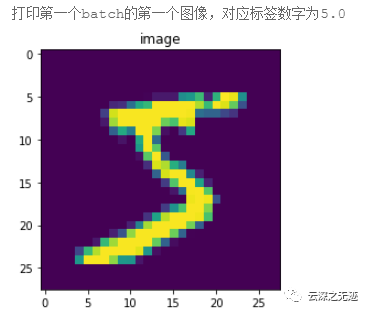
# 以迭代的形式读取数据for batch_id, data in enumerate(train_reader()):# 获得图像数据,并转为float32类型的数组img_data = np.array([x[0] for x in data]).astype('float32')# 获得图像标签数据,并转为float32类型的数组label_data = np.array([x[1] for x in data]).astype('float32')# 打印数据形状print("图像数据形状和对应数据为:", img_data.shape, img_data[0])print("图像标签形状和对应数据为:", label_data.shape, label_data[0])breakprint("\n打印第一个batch的第一个图像,对应标签数字为{}".format(label_data[0]))# 显示第一batch的第一个图像import matplotlib.pyplot as pltimg = np.array(img_data[0]+1)*127.5img = np.reshape(img, [28, 28]).astype(np.uint8)plt.figure("Image") # 图像窗口名称plt.imshow(img)plt.axis('on') # 关掉坐标轴为 offplt.title('image') # 图像题目plt.show()
paddle.batch函数将MNIST数据集拆分成多个批次,
通过如下代码读取第一个批次的数据内容,观察数据打印结果。
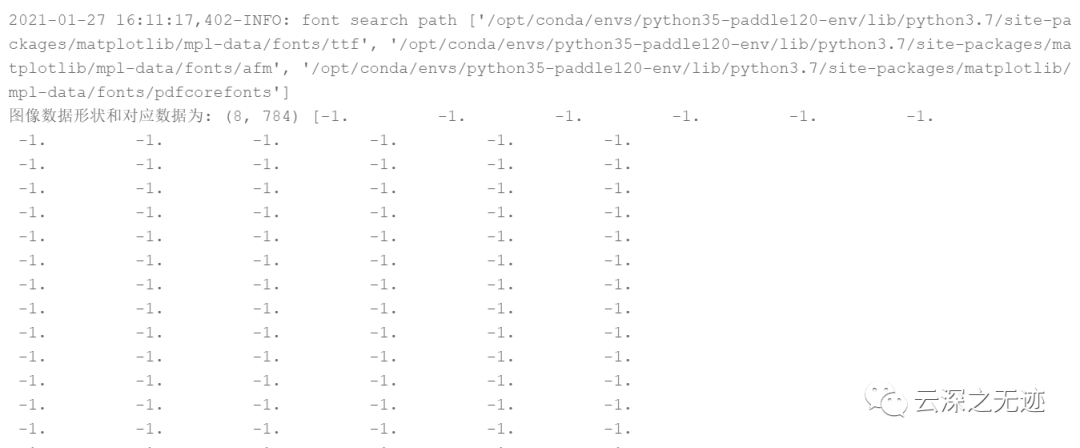
执行的结果很多,我就截图一些
从打印结果看,从数据加载器train_reader()中读取一次数据,可以得到形状为(8, 784)的图像数据和形状为(8,)的标签数据。其中,形状中的数字8与设置的batch_size大小对应,784为MINIST数据集中每个图像的像素大小(28*28)。
此外,从打印的图像数据来看,图像数据的范围是[-1, 1],表明这是已经完成图像归一化后的图像数据,并且空白背景部分的值是-1。将图像数据反归一化,并使用matplotlib工具包将其显示出来,如图2 所示。可以看到图片显示的数字是5,和对应标签数字一致。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_guides/index_cn.html
一开始的API中讲了一些训练的基本概念
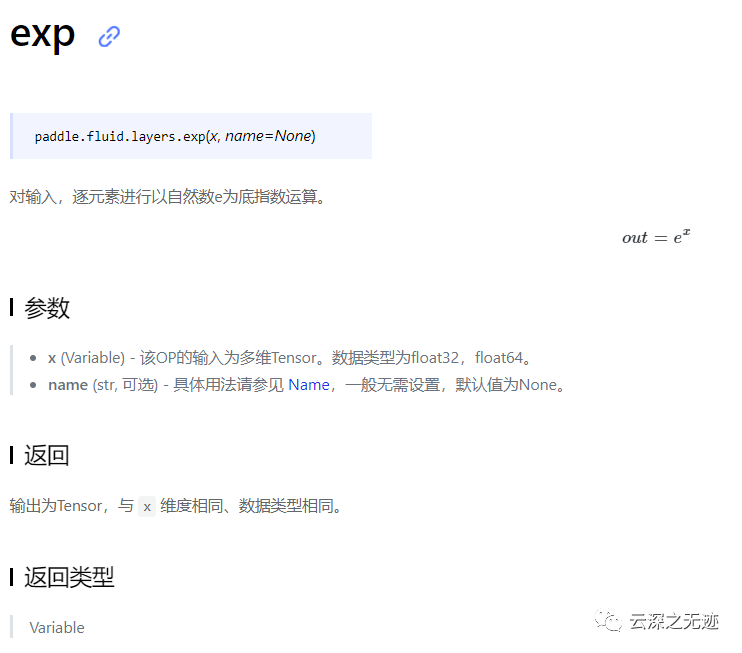
还有基本的数学概念
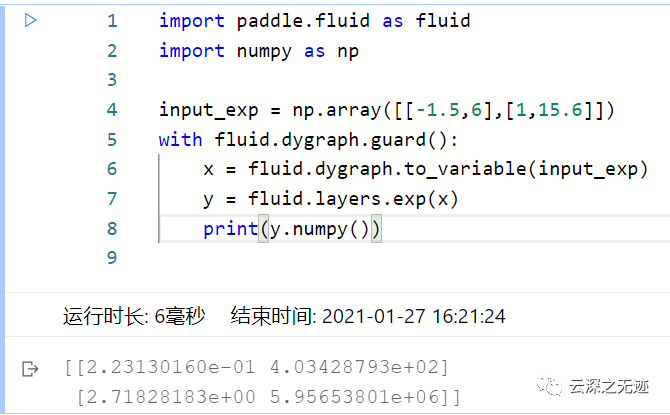
我们可以写一个代码验证
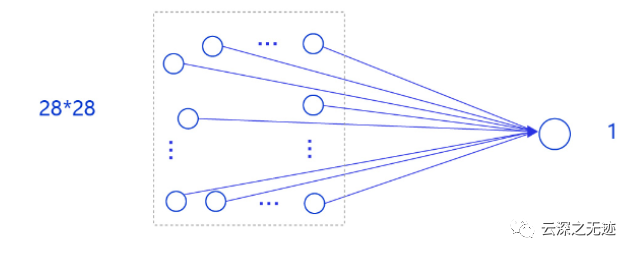
要用到的网络模型的样子
模型的输入为784维(28*28)数据,输出为1维数据
输入像素的位置排布信息对理解图像内容非常重要(如将原始尺寸为28*28图像的像素按照7*112的尺寸排布,那么其中的数字将不可识别),因此网络的输入设计为28*28的尺寸,而不是1*784,以便于模型能够正确处理像素之间的空间信息。
事实上,采用只有一层的简单网络(对输入求加权和)时并没有处理位置关系信息,因此可以猜测出此模型的预测效果可能有限。在后续优化环节介绍的卷积神经网络则更好的考虑了这种位置关系信息,模型的预测效果也会有显著提升。
# 定义mnist数据识别网络结构class MNIST(fluid.dygraph.Layer):def __init__(self):super(MNIST, self).__init__()# 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数self.fc = Linear(input_dim=784, output_dim=1, act=None)# 定义网络结构的前向计算过程def forward(self, inputs):outputs = self.fc(inputs)return outputs
定义一个神经网络层
# 定义飞桨动态图工作环境with fluid.dygraph.guard():# 声明网络结构model = MNIST()# 启动训练模式model.train()# 定义数据读取函数,数据读取batch_size设置为16train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=16)# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001)
# 通过with语句创建一个dygraph运行的context# 动态图下的一些操作需要在guard下进行with fluid.dygraph.guard():model = MNIST()model.train()train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=16)optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())EPOCH_NUM = 10for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,格式需要转换成符合框架要求的image_data = np.array([x[0] for x in data]).astype('float32')label_data = np.array([x[1] for x in data]).astype('float32').reshape(-1, 1)# 将数据转为飞桨动态图格式image = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程predict = model(image)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.square_error_cost(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了1000批次的数据,打印下当前Loss的情况if batch_id !=0 and batch_id % 1000 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()# 保存模型fluid.save_dygraph(model.state_dict(), 'mnist')
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置

开始训练
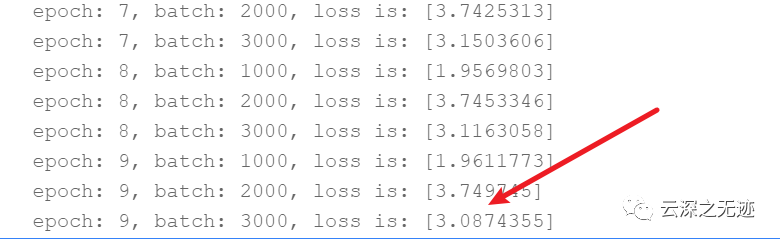
训练到最后一轮的时候,发现损失函数还是这么高
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
声明实例
加载模型:加载训练过程中保存的模型参数,
灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从'./work/example_0.jpg'文件中读取样例图片,并进行归一化处理。
# 导入图像读取第三方库import matplotlib.image as mpimgimport matplotlib.pyplot as pltimport cv2import numpy as np# 读取图像img1 = cv2.imread('./work/example_0.png')example = mpimg.imread('./work/example_0.png')# 显示图像plt.imshow(example)plt.show()im = Image.open('./work/example_0.png').convert('L')print(np.array(im).shape)im = im.resize((28, 28), Image.ANTIALIAS)plt.imshow(im)plt.show()print(np.array(im).shape)
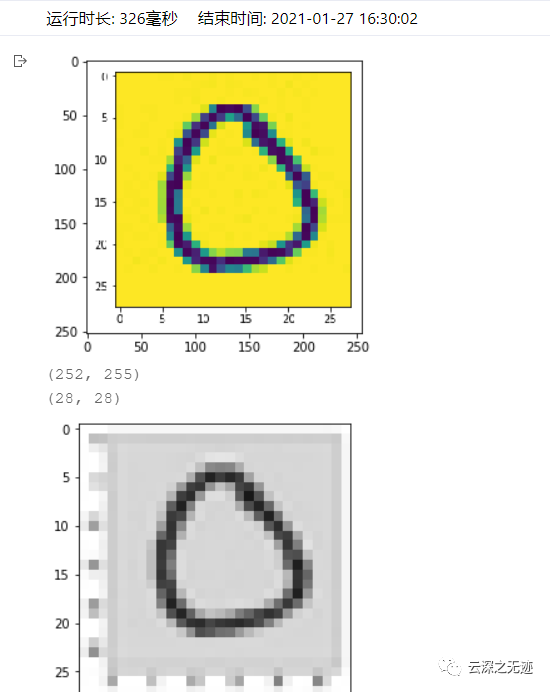
加载并处理,很显然
这个是0
# 读取一张本地的样例图片,转变成模型输入的格式def load_image(img_path):# 从img_path中读取图像,并转为灰度图im = Image.open(img_path).convert('L')print(np.array(im))im = im.resize((28, 28), Image.ANTIALIAS)im = np.array(im).reshape(1, -1).astype(np.float32)# 图像归一化,保持和数据集的数据范围一致im = 1 - im / 127.5return im# 定义预测过程with fluid.dygraph.guard():model = MNIST()params_file_path = 'mnist'img_path = './work/example_0.png'# 加载模型参数model_dict, _ = fluid.load_dygraph("mnist")model.load_dict(model_dict)# 灌入数据model.eval()tensor_img = load_image(img_path)result = model(fluid.dygraph.to_variable(tensor_img))# 预测输出取整,即为预测的数字,打印结果print("本次预测的数字是", result.numpy().astype('int32'))
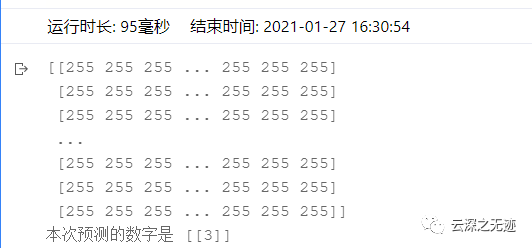
执行结果,出个3
那这个结果肯定是骗不了我的,那证明我姿势不太对,我继续捣鼓~

我的半个小时GPU时间啊,训练个什么东西出来

