

近日,AMD新款中国特供版显卡RX 7650 GRE在京东商城开启预售,价格2049元起,叠加返京东E卡活动,到手价1999元。
作为一款专供中国内地市场的显卡,在新一代Radeon RX 9000系列还要稍等一些时日的情况下,RX 7650 GRE自然是备受中国玩家关注。

首先,GRE这个后缀最早用于RX 7900 GRE,代表着“Gold Rabbit Edition”(金兔版),因为当年是中国农历兔年,以此作为送给中国玩家的特殊大礼。
之后,它又用于RX 6750 GRE,定位主流市场。
不过,今年已经是蛇年,再叫金兔版显然不太合适,GRE也有了新的含义,那就是“Great Radeon Edition”。
相信在未来,我们应该会看到更多AMD GRE显卡,成为一种针对中国市场的特殊传统。

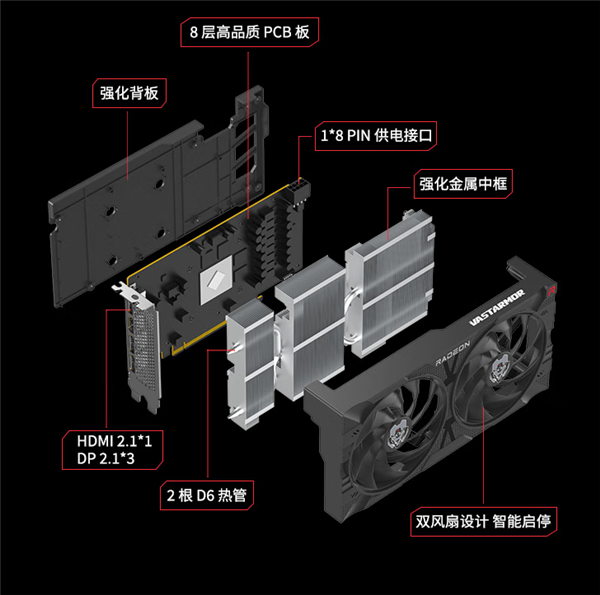
其次,RX 7650 GRE从规格参数看,显然是RX 7600系列的同门,更确切地说和RX 7600 XT一样,都使用了更高级的Navi 33 XT GPU芯片,只是频率稍有降低,显存也减了一半,不过AIB非公版大部分都会预超频。
功耗也从190W显著降至170W,因此不再需要两个8针供电接口,一个就够了,自然更加友好。
由于中国市场存在RX 6750 GRE,因此RX 7600 XT发布后并未在中国市场销售,而此番RX 7650 GRE的诞生,算是弥补了这一遗憾。

最后在价格方面,RX 7650 GRE叠加京东E卡活动,最终到手价其实只要1999元起。
这还是比较有诚意的,特别是考虑到它的性能明显超过对标的RTX 4060,而且后者近来供货日趋紧张,价格也全面上涨,目前最低也要2249元。
再考虑到RTX 5060系列还得等待大概两个月,因此RX 7650 GRE选择这个时候登场,还是很会打时间差的,值得考虑。

DeepSeek火得一塌糊涂,国内外的相关企业都在积极适配支持,而对于AI大模型来说,使用GPU运行无疑是最高效的,比如AMD,无论是Instinct加速卡还是Radeon游戏卡,都已经适配到位。
你只需要任意一块AMD RX 7000系列显卡,就可以在本地体验DeepSeek。

RX 7650 GRE首批上架产品一览:
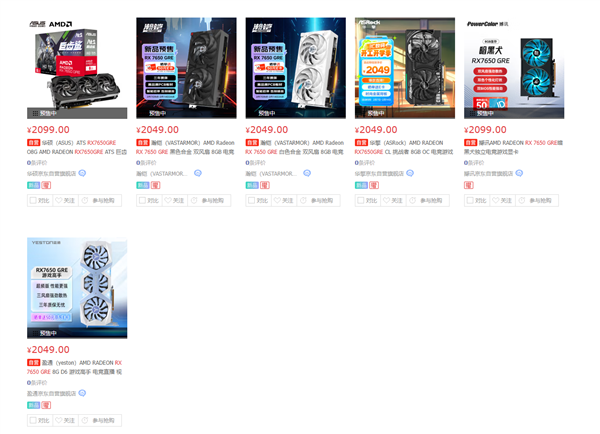
华擎RX 7650 GRE挑战者OC:2049元


华硕RX 7650 GRE巨齿鲨OC:2099元



撼迅RX 7650 GRE暗黑犬:2099元



蓝宝石RX 7650 GRE Black Diamond黑钻:



蓝宝石RX 7650 GRE Pulse:



瀚铠RX 7650 GRE合金(黑白双色):2049元




盈通RX 7650 GRE游戏高手:2049元


盈通RX 7650 GRE大地之神:

AMD Radeon游戏卡本地部署DeepSeek非常简单,只需打开AMD官网(中英文均可),搜索“15.1.1”,进入第一个结果,下载AMD Adrenalin 25.1.1测试版驱动,安装并重启。
直接下载地址:
https://www.amd.com/zh-cn/resources/support-articles/release-notes/RN-RAD-WIN-25-1-1.html

然后打开LM Studio官网网站的锐龙专栏(https://lmstudio.ai/ryzenai),并下载LM Studio for Ryzen AI安装包,安装并运行。
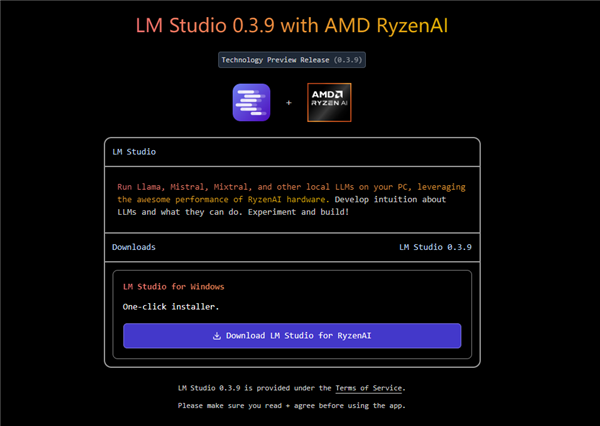
启动之后,点击右下角设置(可选中文语言),找到并开启“Use LM Studio's Hugging Face”这个选项。
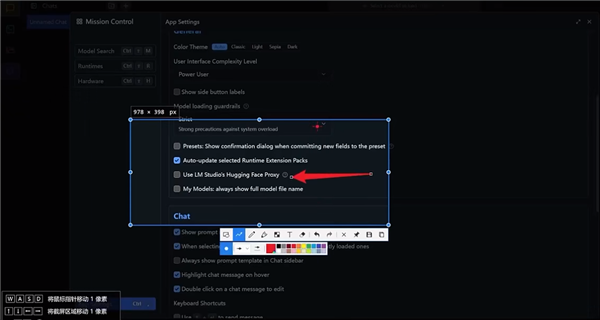
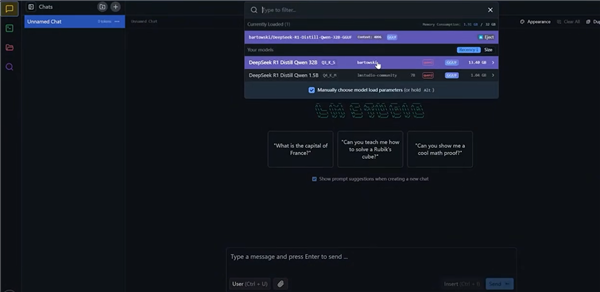
回到主界面,在左侧菜单栏点击搜索图标,输入“DeepSeek R1”,就可以看到已经训练好的各种DeepSeek模型。
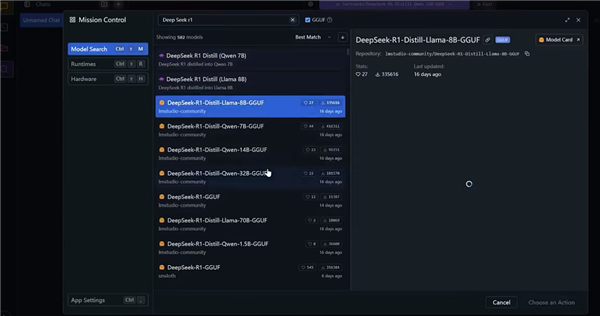
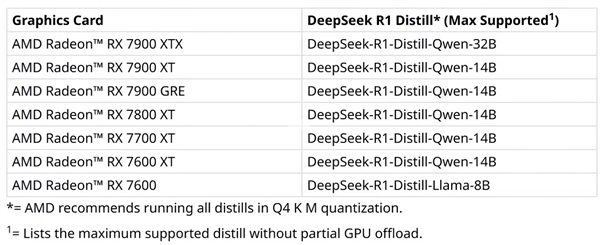
至于如何选择,可以参考如下的AMD官方推荐列表,比如旗舰级的RX 7900 XTX可以支持到32B参数,主流的RX 7600则仅支持8B模型。
顺带一提,最新的中国特供版显卡RX 7650 GRE也同样支持本地部署DeepSeek,只待正式发布。
然后下载合适的模型,在主界面上方选择已下载的模型,然后调高“GPU Offload”的数值,不同选项的具体含义可自行搜索或者直接询问DeepSeek。
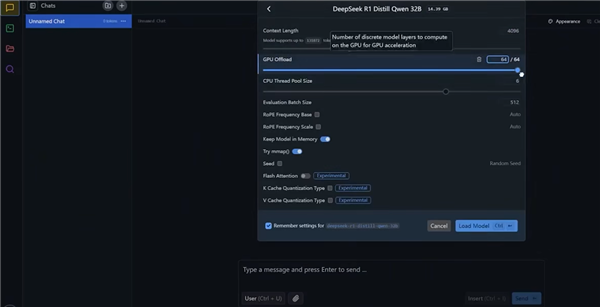
模型加载完毕后,就可以尽情地在本地体验DeepSeek了。
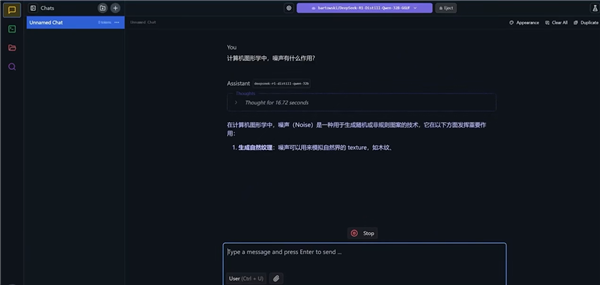
与此同时,AMD Instinct GPU加速卡也已经部署集成DeepSeek V3模型,并优化了SGLang性能,支持完整的671B参数,开发者可以借助AMD ROCm平台快速、高效地开发AI应用。
1、启动Docker容器
docker run -it --ipc=host --cap-add=SYS_PTRACE --network=host \
--device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined \
--group-add video --privileged -w /workspace lmsysorg/sglang:v0.4.2.post3-rocm630
2、开始使用
(1)、使用CLI登陆进入Hugging Face。
huggingface-cli login
(2)、启动SGLang Server,在本地部署DeepSeekV3 FP8模型。
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3 --port 30000 --tp 8 --trust-remote-code
(3)、服务器启动后,打开新的终端,发送请求。
curl http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "Once upon a time,",
"sampling_params": {
"max_new_tokens": 16,
"temperature": 0
}
}'
3、基准测试
export HSA_NO_SCRATCH_RECLAIM=1
python3 -m sglang.bench_one_batch --batch-size 32 --input 128 --output 32 --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 benchmark/gsm8k/bench_sglang.py --num-questions 2000 --parallel 2000 --num-shots 8
Accuracy: 0.952
Invalid: 0.000
另外,如果需要BF16精度,可以自行转换:
cd inference
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights

