


----追光逐电 光引未来----
·K近邻(KNN)算法
·朴素贝叶斯算法
·决策树算法
·SVM算法
·adaboost算法
·EM算法(期望最大化算法)

NO.1
KNN算法

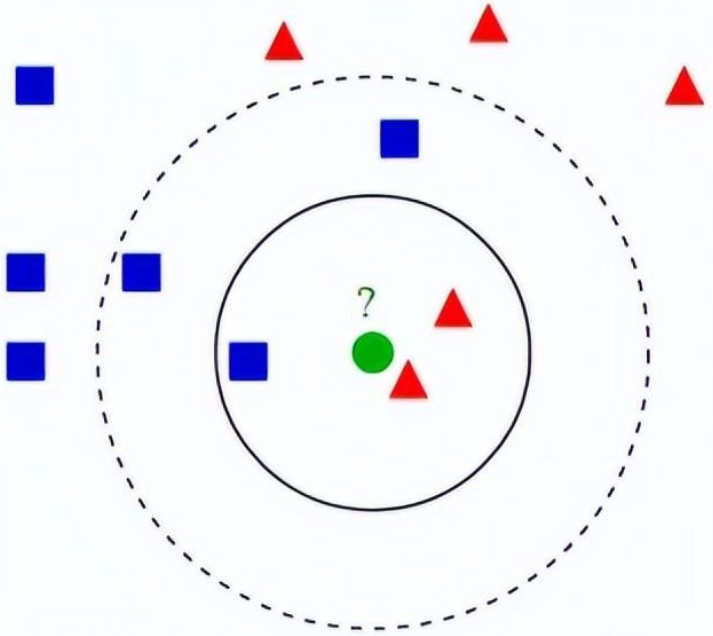
适用场景及主要应用领域:
K近邻(KNN)算法需要注意的问题:
NO.2
朴素贝叶斯算法
朴素贝叶斯算法注意点:
·当特征属性值的值类型不是离散值而是连续值的时候,需要通过高斯分布做概率的计算;
·为了避免统计概率中出现概率为0的情况,可以引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1。
适用场景及主要应用领域:
主要应用领域
NO.3
决策树算法
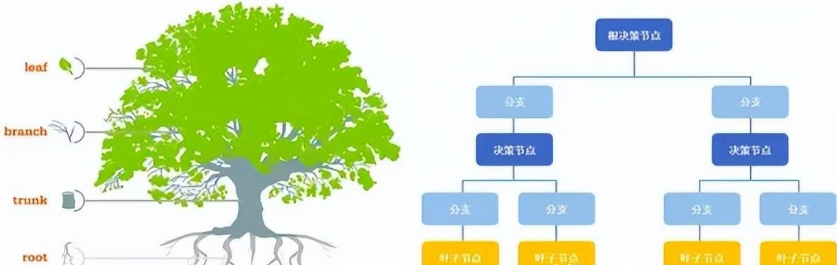
决策树算法注意点:
适用场景及主要应用领域:
NO.4
SVM算法
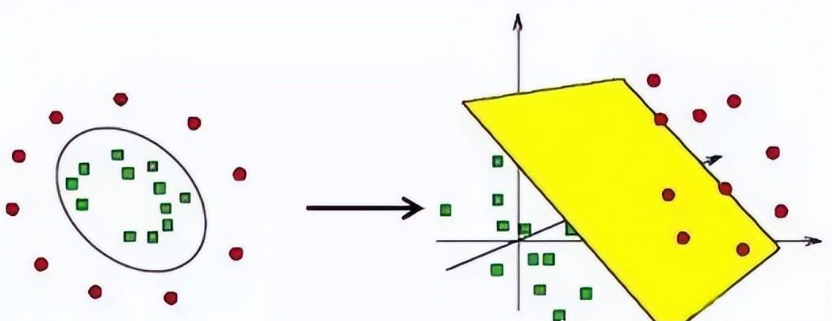
SVM算法注意点:
·处理非线性数据集的方法之一是添加更多的特征,比如多项式特征。
适用场景及主要应用领域:
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,但它具有以下缺点:
·无法应对大规模训练样本;
·难以解决多分类问题;
·对参数及核函数选择非常敏感。
支持向量机的常见适用范围如下:
·网络完全
传统的网络入侵检测方法大多采用密码签名的方法。在进行入侵检测方面,机器学习技术可以帮助我们进行网络流量的分析,在这里支持向量机具有检测速度快,分类精度高等特点,可以帮助安全人员识别不同类别的网络攻击,例如扫描和欺诈网络。
·人脸识别
SVM可以将图像部分分为人脸和非人脸。它包含nxn像素的训练数据,具有两类人脸(+1)和非人脸(-1),然后从每个像素中提取特征作为人脸和非人脸。根据像素亮度在人脸周围创建边界,并使用相同的过程对每个图像进行分类。
·文本和超文本分类
SVM可以实现对两种类型的模型进行文本和超文本分类,它主要通过使用训练数据将文档分类为不同的类别,如新闻文章、电子邮件和网页。
对于每个文档,计算一个分数并将其与预定义的阈值进行比较。当文档的分数超过阈值时,则将文档分类为确定的类别。如果它不超过阈值,则将其视为一般文档。
通过计算每个文档的分数并将其与学习的阈值进行比较来对新实例进行分类。
·蛋白质折叠和远程同源检测
蛋白质远程同源性检测是计算生物学中的一个关键问题。SVM算法是远程同源检测最有效的方法之一。这些方法的性能取决于蛋白质序列的建模方式。
NO.5
adaboost算法
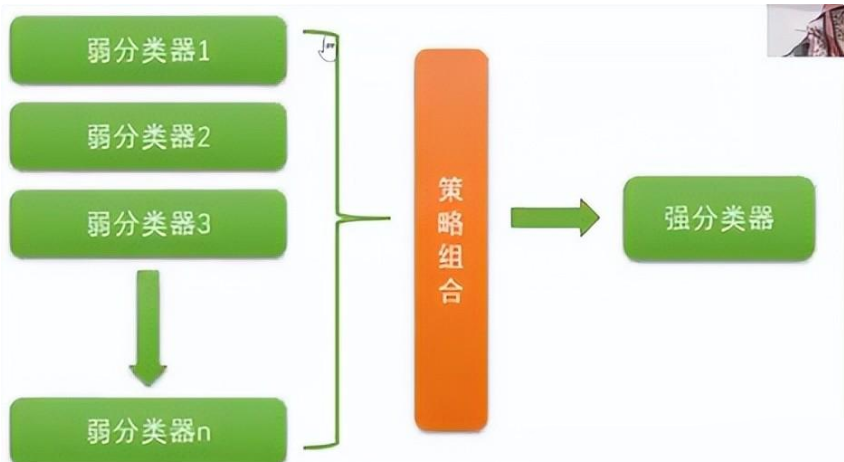
adaboost算法注意点:
适用场景及主要应用领域:
NO.6
EM算法
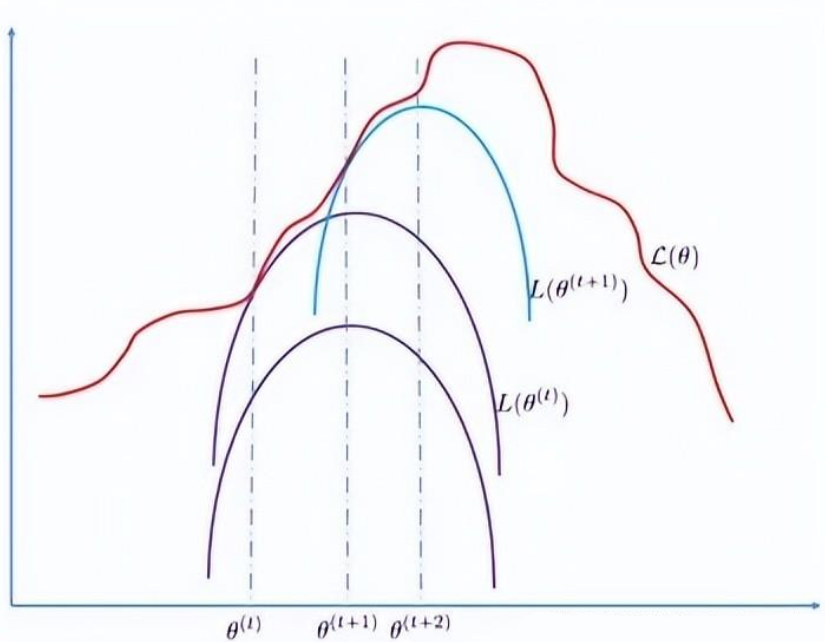
EM算法注意点:
适用场景及主要应用领域:
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


