

DeepSeek在研发大模型时绕过了英伟达的护城河CUDA,这让美国不少巨头们感到了很大的威胁,而现在这件事才刚刚开始。
DeepSeek真的绕过了CUDA,那这件事意味着什么?对此,北京航空航天大学黄雷副教授接受采访时表示,绕过CUDA,可以直接根据GPU的驱动函数做一些新的开发,从而实现更加细粒度的操作。
譬如DeepSeek在多节点通信时绕过了 CUDA 直接使用 PTX(Parallel Thread Execution),其最多只能实现以算法的方式来高效利用硬件层面的加速。
一旦速度变得更快,打个比方这就意味着别人家的模型要训练十天,而DeepSeek只需要训练五天,那么就能给模型喂更多的数据,即能让模型在同等时间内看到更多的数据,间接提高模型的效果。
按照消息人士的说法,DeepSeek拥有一些擅长写PTX语言的内部开发者。
那么,假如它之后使用国产GPU,其在硬件适配方面将会更得心应手,其只要了解这些硬件驱动提供的一些基本函数接口,就可以仿照英伟达GPU硬件的编程接口去写相关的代码,从而让自家大模型更加容易适配国产硬件。

另外,特朗普与英伟达首席执行官黄仁勋本周五在白宫会面,讨论了中国公司深度求索(DeepSeek)以及收紧人工智能芯片出口等问题。
次会议召开之际,美国政府计划今年春天进一步限制人工智能芯片出口,以确保先进的计算能力留在美国及其盟友手中,同时寻求更多途径阻止中国获取相关技术。
英伟达发言人在一份声明中表示:“我们感谢有机会与特朗普总统会面,讨论半导体和人工智能政策。黄仁勋与总统讨论了加强美国技术和人工智能领导力的重要性。”
了解此次会面情况的消息人士称,此次会面是在DeepSeek震撼科技界之前安排的。
该消息人士还称,总统认为这家中国公司的出现意味着“美国公司不必花费大量资金来打造低成本(人工智能)替代品”。
此次会议召开之时,人们越来越担心中国在人工智能发展方面正在追赶美国。

很有意思的是,最快的N卡和最快的A卡跑DeepSeek谁更快?
最新消息显示,RTX 5090在DeepSeek R上的推理性能比AMD的 RX 7900 XTX快得多,性能至少翻了一倍。
测试显示,在多个DeepSeek R1型号中,RTX 5090明显领先于RX 7900 XTX,也比RTX 4090快了不少。
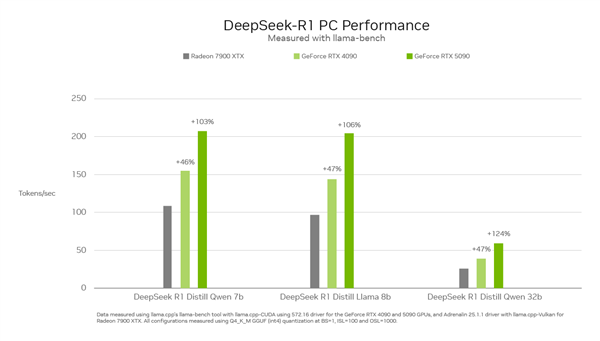
在Distill Qwen 7b和Distill Llama 8b模型中,该RTX 5090每秒可运行200个Tokens,几乎是RX 7900 XTX 的两倍。
1月31日,NVIDIA宣布,NIM已经可以使用DeepSeek-R1。
NIM,即NVIDIA Inference Microservices,是一种云原生微服务技术,可简化生成式AI模型在云端、数据中心及GPU加速工作站上的部署流程
NVIDIA官网发布文章指出,DeepSeek-R1是最先进的推理开放模型,会对查询进行多次推理处理,使用连锁思维、共识和搜寻方法来生成最佳答案。
文章写道,为了帮助开发者安全地试验这些功能,并构建自己的专门代理,DeepSeek-R1模型现已作为NVIDIA NIM微服务预览版上线使用。
