

关注 ▲射频美学 ▲ ,一起学习成长
这是射频美学的第 1810 期分享。
来源 | 原创;
微圈 | 进微信群,加微信: RFtogether521 ;
备注 | 昵称+地域+产品及岗位方向 (如大魔王+上海+芯片射频工程师);
宗旨 | 看见即自由。

最近DeepSeek公司比较火,美国的一把山林大火,几个星期烧掉了加州2500亿美元。而DeepSeek横空出世,纳斯达克大跌3%,瞬间烧掉了5000多亿。什么概念?如果把这5000多亿换成百元美刀,用飞机来运到焚烧厂去烧,需要87架满载的空客380。
1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。
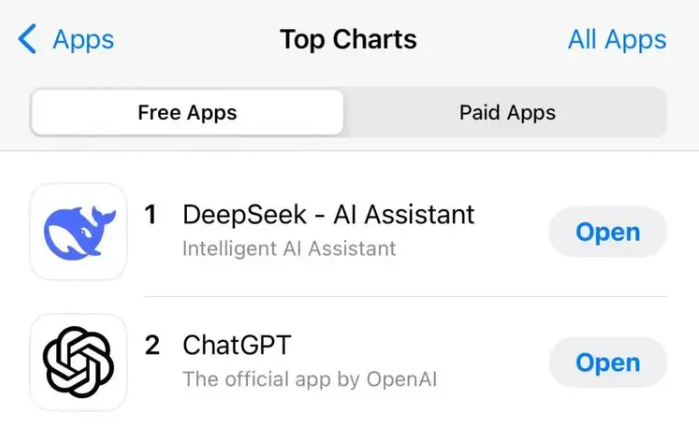
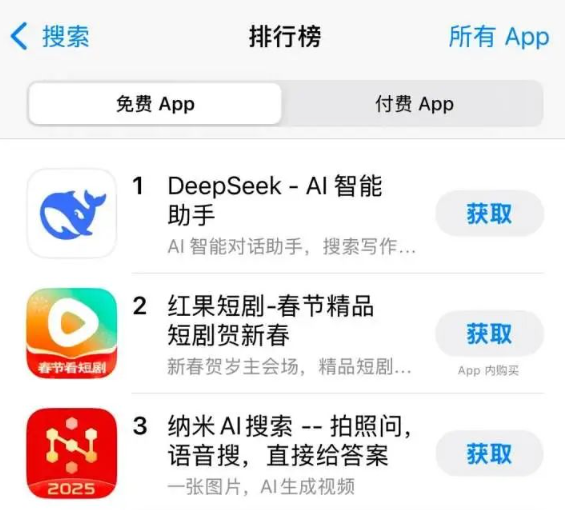
同日,苹果中国区应用商店免费榜显示,DeepSeek成为中国区第一。
01-DeepSeek公司简介
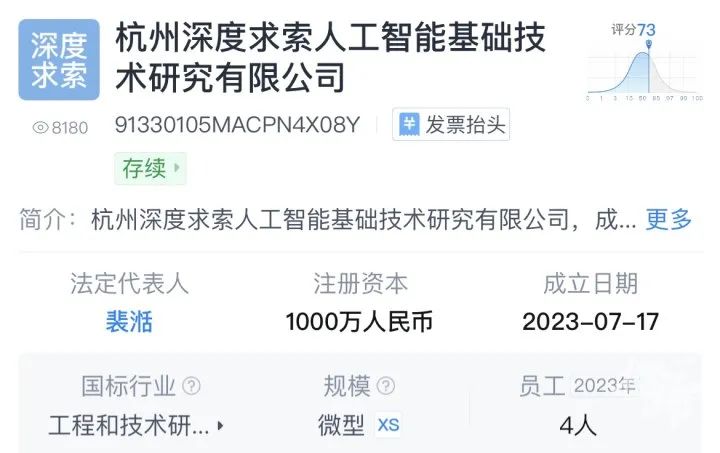
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年7月17日,是一家创新型科技公司,专注于开发先进的大语言模型(LLM)和相关技术。
在团队配置上, DeepSeek团队只有139名研发人员,相比OpenAI拥有1200名研究人员,团队规模是DeepSeek的近乎9倍之多。
算子、推理框架、多模态等研发工程师以及深度学习方面的研究人员共有约70人。比如前段时间的热门话题“雷军千万年薪挖95后天才AI少女”,这位“95后AI天才少女”罗福莉,就是DeepSeek开源大模型DeepSeek-V2的关键开发者之一。
其核心人员有以下几位。
•梁文锋:DeepSeek的创始人,浙江大学信息与通信工程专业的硕士。
• 高华佐:MLA架构的关键贡献者,毕业于北大物理系。
• 曾旺丁:MLA架构的关键贡献者,来自北邮,其研究生导师是北邮人工智能与网络搜索教研中心主任张洪刚。
• 邵智宏:清华大学交互式人工智能(CoAI)课题组博士生,主要研究自然语言处理、深度学习,对构建稳健且可扩展的AI系统有着独特见解。
• 朱琪豪:北京大学计算机学院2024届的博士毕业生,专注于深度代码学习研究,是GRPO算法创新的另一重要贡献者。
• 代达劢:北京大学计算机学院2024年博士毕业生,师从穗志方教授。
• 赵成钢:负责DeepSeek大模型训练及推理基础架构的工程师,加入DeepSeek之前,曾在英伟达公司实习。
• Peiyi Wang:北大博士生,参与了DeepSeek-Math项目。
• 王炳宣:清华博士生。
• 吴作凡:中山大学博士生。
• 任之洲:中山大学博士生。
• 周雨杨:中山大学博士生。
• 罗翔煜:中山大学博士生。
02-梁文锋何许人也?
低调的梁文锋是个80后,出生在广东的一个五线城市,父亲是一名小学老师。他毕业于浙江大学,主修软件工程,人工智能方向。
17岁时,梁文锋考入浙大,读的是电子工程系人工智能方向,毕业后在浙大攻读硕士研究生,论文题目是《基于低成本PTZ摄像机的目标跟踪算法研究》。
2015年,30岁的梁文锋和朋友一起创办了杭州幻方科技有限公司,立志成为世界顶级的量化对冲基金。2016年10月,幻方量化推出第一个AI模型,第一份由深度学习生成的交易仓位上线执行。到2017年底,几乎所有的量化策略都采用AI模型计算。
2023年5月,38岁的梁文锋宣布做通用人工智能(AGI)。7月,他正式创办杭州深度求索人工智能基础技术研究有限公司,就是DeepSeek公司,专注于AI大模型的研究和开发,公司设在杭州。
从公开的工作经历和职业生涯来看,梁文锋在量化投资和高性能计算领域具有深厚的背景和丰富的经验,创业范畴横跨金融和人工智能领域。
03-DeepSeek发展进程
2023年7月:DeepSeek成立,总部位于杭州。
2023年11月2日:发布首个开源代码大模型DeepSeek Coder,支持多种编程语言的代码生成、调试和数据分析任务。
2023年11月29日:推出参数规模达670亿的通用大模型DeepSeek LLM,包括7B和67B的base及chat版本。
2024年5月7日:发布第二代开源混合专家(MoE)模型DeepSeek-V2,总参数达2360亿,推理成本降至每百万token仅1元人民币。
2024年12月26日:发布DeepSeek-V3,总参数达6710亿,采用创新的MoE架构和FP8混合精度训练,训练成本仅为557.6万美元。
2025年1月20日:发布新一代推理模型DeepSeek-R1,性能与OpenAI的GPT-4o持平,并开源。
2025年1月26日:DeepSeek登顶美区App Store免费榜第六,超越Google Gemini和Microsoft Copilot等产品。
1月27日,DeepSeek应用登顶苹果美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。
04-DeepSeek为啥能火?
在硅谷,DeepSeek很早就被称作“来自东方的神秘力量”,也是网上热议的“杭州六小龙”之一。
真正让DeepSeek火出圈的是2024年12月26日,这家公司宣布上线并同步开源的 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。
它以1/11的算力、仅2000个GPU芯片训练出性能超越GPT-4o的大模型。其总训练成本只有557.6万美元,而GPT-4o的约为1亿美元,使用25000个GPU芯片。双方的成本至少是10倍的差距。
在性能上,DeepSeek-V3在数学、代码能力和中文知识问答方面还超过了ChatGPT-4o。
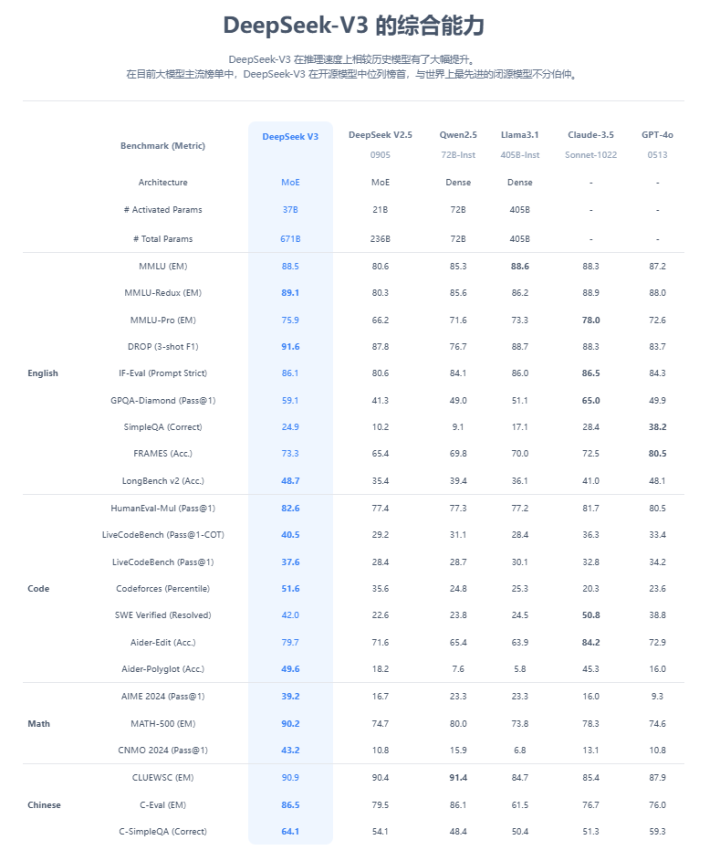
国外独立测评机构Artificial Analysis测试后,发出了“超越了迄今为止所有开源模型”的惊叹;Meta科学家田渊栋感慨:“这是非常伟大的工作。”
“性价比”是商业社会中的制胜法宝之一,DeepSeek也因创新的模型架构和史无前例的性价比被称为“大模型界的拼多多”,引发字节、阿里、百度等大厂的大模型价格大战。

声明: 欢迎转发本号原创内容,转载和摘编需经本号授权并标注原作者和信息来源为射频美学。 本公众号目前传播内容为本公众号原创、网络转载、其他公众号转载、累积文章等,相关内容仅供参考及学习交流使用。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请跟我们联系,我们致力于保护作者知识产权或作品版权,本公众号所载内容的知识产权或作品版权归原作者所
