·聚焦:人工智能、芯片等行业
欢迎各位客官关注、转发


近日,UALink联盟发布官方公告,宣布阿里云、苹果公司以及新思科技已正式加入董事会,共同致力于推动下一代人工智能集群互连技术的发展。
据先前报道,UALink 联盟成立于2024年10月,由AMD、亚马逊AWS、Astera Labs、思科、谷歌、慧与、英特尔、Meta和微软九家知名企业共同发起,旨在联合挑战英伟达在人工智能数据中心互联领域的领先地位。
苹果公司在董事会中的影响力可能会激发公众对于其开发数据中心专用芯片的种种猜想,该芯片预期将利用UALink互连技术为iPhone提供人工智能服务。
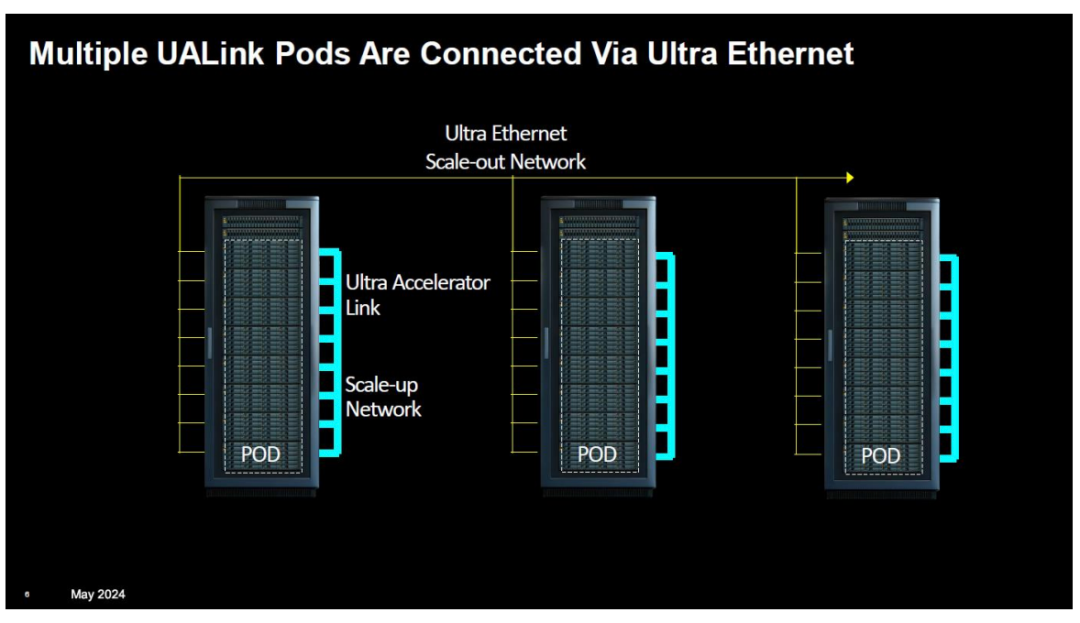
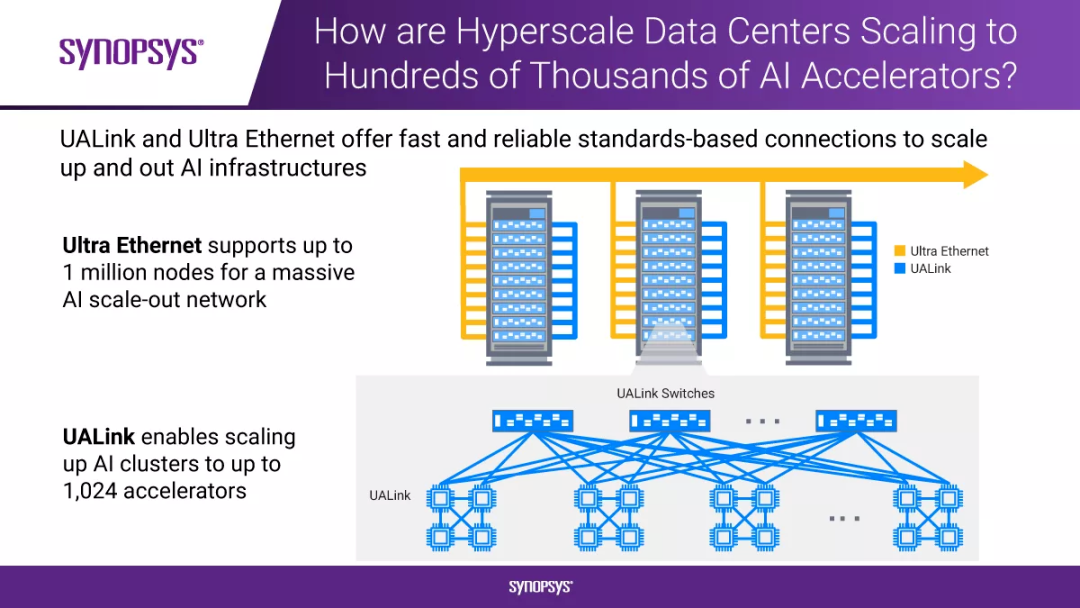
UALink 联盟致力于为AI Pod和集群中加速器与交换机之间的纵向扩展通信制定一套高速、低延迟的互联规范,以期在该领域挑战英伟达NVLink等互联技术的主导地位。
该联盟的首个正式版规范UALink 1.0计划于今年向贡献者成员发布,并将于明年第一季度向公众开放审查。
该规范预计将实现AI Pod中最多1024个加速器的每通道扩展连接,达到高达200Gbps的扩展连接速度。
UALink 联盟此次迎来三大行业巨头的加入,标志着UALink技术获得了更广泛的业界支持,有望推动其在人工智能领域的广泛应用。
UALink 联盟主席Kurtis Bowman对新成员的加入表示热烈欢迎,并指出,联盟成员已超过65家,成员类型包括云服务提供商、芯片与IP技术供应商、软件公司以及系统OEM厂商等。
UALink 1.0规范预计将于2025年第一季度正式发布,届时将支持每通道高达200Gbps的扩展连接,最多可在AI Pod内连接1024个加速器。

UALink与英伟达的实力较量
①性能对决:在数据传输速率方面,英伟达的 NVLink 技术始终占据行业领先地位。
以第五代 NVLink 为例,单个NVIDIA Blackwell Tensor Core GPU支持高达18 个NVLink 100GB/s 连接,总带宽达到 1.8TB/s,这一成就在相当长的一段时间内是业界难以超越的。
然而,UALink 1.0 的问世打破了这一局面。
据 TechCrunch 报道,UALink 1.0 计划通过单个计算 Pod 连接多达1024个AI芯片,并且单个通道速率可达 200Gbps,在大规模芯片互联的场景下,其总带宽能力令人瞩目。
在处理大规模深度学习模型训练时,大量模型参数需要在芯片间迅速传输,UALink 1.0 的UALink作为新一代AI/ML集群性能的高速加速器互连技术,以其低延迟和高带宽特性著称。
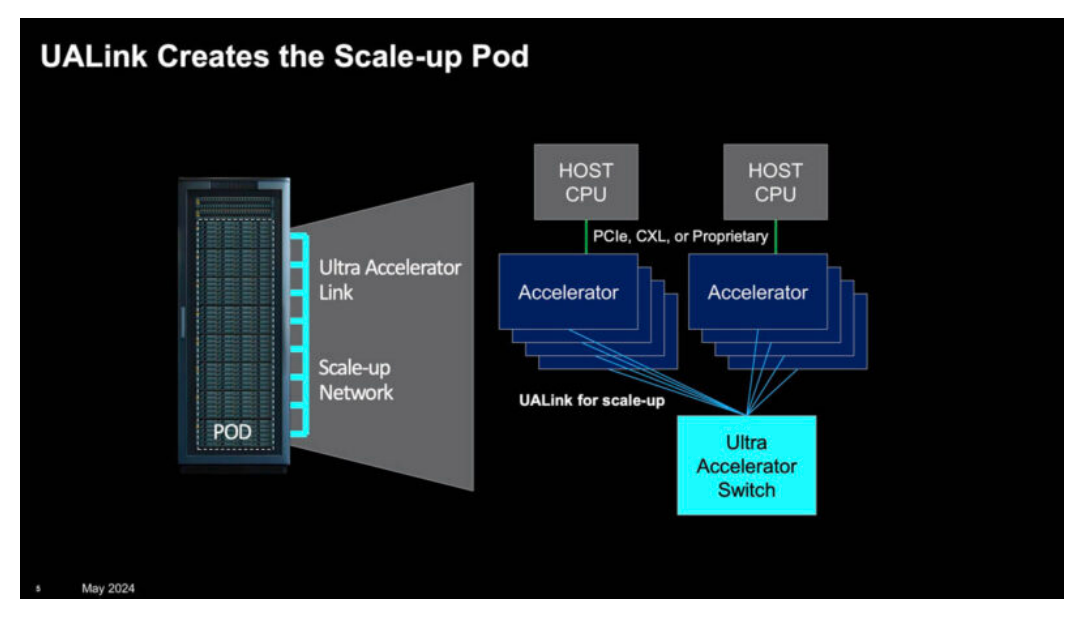
原生支持高性能内存语义访问,与GPU等AI加速器的编程模型高度兼容,能在单一超节点内实现大规模AI计算节点的互连。
UALink的优势还体现在显存共享、支持Switch组网模式以及其超高的带宽和极低的时延性能上。
该技术规范定义了一种创新的I/O架构,单通道传输速率可达200 Gbps,支持多达1024个AI加速器的互连。
相较于传统以太网(Ethernet)架构,UALink在性能和GPU互连规模方面均展现出显著优势,其互连规模远超Nvidia NVLink技术。
以Dell PowerEdge XE9680服务器为例,单台服务器最多可支持8块AMD Instinct或Nvidia HGX GPU。
采用UALink技术后,可实现百台级服务器集群内GPU的直接低延迟访问。
更为重要的是,UALink在加速器、交换芯片、Retimer等互连技术上保持中立,不偏袒任何特定厂商,致力于构建一个开放创新的技术生态系统。
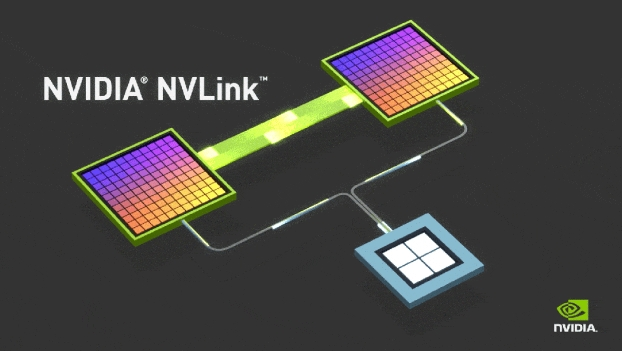
②生态系统之争:凭借在GPU领域的深厚积累及市场领导地位,英伟达构建了一个庞大且成熟的生态系统。
其CUDA平台作为该生态系统的基石,向开发者提供了广泛的开发工具和库,使得他们能够利用英伟达的GPU和NVLink技术进行高效的应用开发。
在COMPUTEX 2023大会上,英伟达透露,CUDA平台已拥有超过四百万的开发者,三千多个应用程序,以及高达四千万次的历史下载量。
众多企业和开发者基于英伟达的生态系统,进行深度学习、数据分析等应用的开发,形成了显著的用户粘性。
相对而言,UALink的生态系统尚处于成长阶段,但其开放标准的策略已吸引了众多企业的参与。
对于数据中心运营商而言,他们将拥有更多元化的选择,不再受限于英伟达的技术和产品,从而能够根据自身需求和预算,灵活选择最适宜的互联技术和硬件设备。
这将有助于降低数据中心的建设成本,提升服务质量和效率,推动整个数据中心行业的健康发展。
UALink提供了追赶英伟达的机会
尽管英伟达已将NVSwitch应用于NVIDIA DGX GB200 NVL72等产品,但AI加速器市场并非仅由英伟达一家独占。
例如,英特尔今年已销售数亿美元、数万个AI加速器,而AMD今年也将销售数十亿美元的MI300X。
拥有UALink技术后,Broadcom等公司能够生产UALink交换机,以协助其他公司扩展规模,并在多家公司的加速器中使用这些交换机。
目前,UALink已成为最具潜力的AI服务器Scale UP(纵向/垂直扩展)互连开放标准,并正在迅速构建起一个AI服务器Scale Up互连技术的超级开放生态。
截至11月,UALink联盟已有三十余家厂商加入,并持续扩展;其成员涵盖了云计算和应用、硬件、芯片、IP等产业全生态。
这一变革主要源于超大规模人工智能集群对网络带宽和低延迟需求的增加,导致行业集群规模不断扩大。
网络连接成为释放AI集群性能潜力的关键因素
在规模较小的人工智能集群中,例如包含10万个XPU的集群,网络连接的价值量占比大约为XPU总价值的5%至10%。
然而,当人工智能集群规模增长至50万至100万个XPU时,该比例显著上升至15%至20%的价值占比。
预计到2025年,北美四大超级云服务提供商的资本开支将增至3150亿美元,较前一年增长46%,资本开支的同比增速保持在高位,显示出对算力需求市场的乐观态度。
因此,建立更大规模的人工智能集群已成为海外超级云服务提供商的共同战略。
目前,英伟达的专有网络连接技术NVLink+InfiniBand,已成为其软件生态CUDA之外的硬件护城河。
面对英伟达芯片算力的垄断,行业正寻求突破,特别是随着全球推理业务需求的首次增长以及定制芯片ASIC市场份额的持续扩大,为行业打破英伟达垄断提供了极佳的时机。
结尾:
芯片领域的竞争实质上是软件生态系统之间的较量,这也是业界试图通过网络硬件技术如NVLink打破英伟达市场主导地位的关键所在。
显而易见,当前业界两大阵营,即UALink和超以太网联盟UEC,正分别针对NVLink和InfiniBand进行技术突破。
回顾历史,从挖矿时代专用集成电路ASIC的崛起,逐渐取代了通用图形处理单元GPU成为挖矿的主要力量,到如今人工智能计算芯片ASIC的再次兴起;
业界联盟正率先通过网络硬件技术如NVLink来突破英伟达的市场垄断,历史似乎正准备再次重演。
部分资料参考:半导体行业观察:《NVLink迎来劲敌:九大巨头,正式成立UALink联盟》,阿里云:《阿里云当选UALink联盟董事会成员,推进新一代GPU互连技术》,Synopsys:《如何利用业界首发的超以太网和UALink IP,高效互连技术扩展HPC和AI加速器生态系统》,电子工程世界:《英伟达的筹码,又少了一枚》,新财富:《英伟达还能走多远》
本公众号所刊发稿件及图片来源于网络,仅用于交流使用,如有侵权请联系回复,我们收到信息后会在24小时内处理。
推荐阅读:



商务合作请加微信勾搭:
18948782064
请务必注明:
「姓名 + 公司 + 合作需求」