“ 这两家公司远远领先于其他公司。 ”


作者 | Eric Sprague
编译 | 华尔街大事件
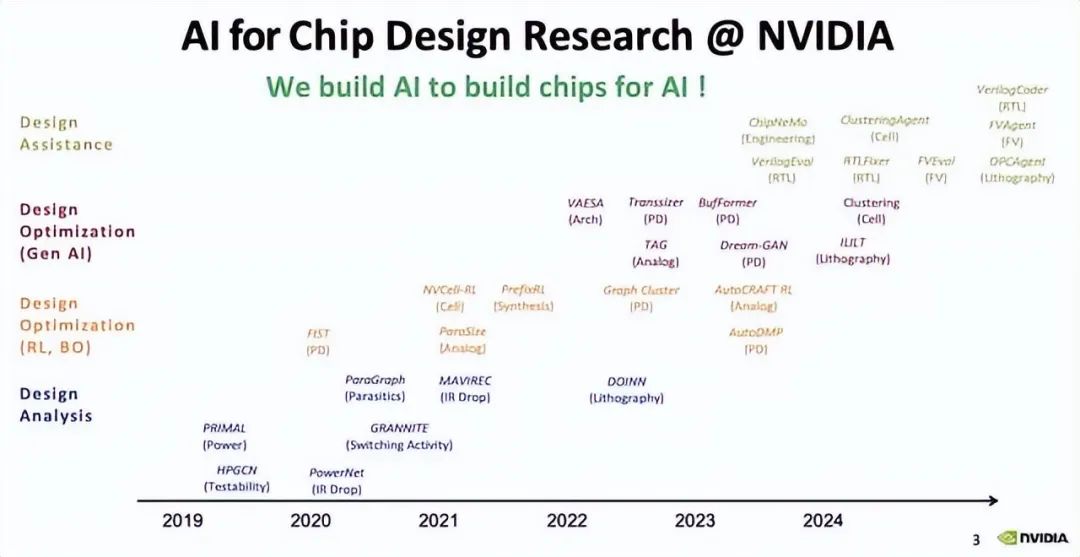
谷歌在 2018 年也做了类似的事情,就是 TPU。现在他们无法独自完成这件事,他们了解软件。他们知道计算元素需要什么,但他们什么都不知道。他们无法完成很多其他困难的事情,比如封装设计、网络,所以他们不得不与 Broadcom 等其他供应商合作来完成这件事。由于谷歌对 AI 模型的发展方向有着统一的愿景,他们实际上能够构建这个系统——针对 AI 优化的系统架构。而当时,英伟达却在想,我们要走多远?
因此,谷歌设计它是为了 英伟达可能没有那么关注的事情,对吧。所以实际上,他们的芯片之间的互连可以说是具有竞争力的,即使在某些方面比 英伟达更好,在其他方面也比 英伟达差。因为他们一直在与 Broadcom 合作,你知道,Broadcom 是世界领先的网络公司,你知道,我们与他们一起制造芯片,自 2018 年以来,他们已经扩大了规模,对吧。
谷歌引入水冷技术已经很多年了,对吧?英伟达刚刚意识到他们需要这一代水冷技术,而谷歌带来了英伟达 GPU 所不具备的可靠性。你知道,一个肮脏的秘密就是去问人们 GPU 在云端或部署中的可靠性率是多少。天哪,它们不是可靠的,但特别是在最初,你必须拿出 5% 左右。
在所有致力于定制 AI 加速器的超大规模企业中,微软排名垫底。
苹果公司并没有与博通公司合作生产整个芯片,但其中一小部分将由博通公司生产,对吧?你知道他们已经取得了很多胜利,对吧?现在这些都不会在 25 年上市,其中一些将在 26 年上市。嗯,你知道,这是一个定制的 ASIC,所以它可能会失败,不像微软那样好,因此永远不会有产量提升。或者它可能真的很好,或者至少你知道像亚马逊那样具有良好的性价比,它可以大幅提升,对吧?
到目前为止,由于硬件规格薄弱和软件集成不佳,亚马逊基于 Trainium1 和 Inferentia2 的实例在 GenAI 前沿模型训练或推理方面没有竞争力。随着 Trainium2 的发布,亚马逊进行了重大的方向调整,并最终在芯片、系统和软件编译器/框架级别提供具有竞争力的定制训练和推理芯片。需要明确的是,由于 Titan 和 Olympus 等内部模型失败,亚马逊仍处于危机模式。此外,虽然他们已经在定制AI 芯片的竞赛中稳居第二,仅次于谷歌,但他们仍然严重依赖 英伟达的产能。亚马逊的 Trainium2 并不是经过验证的“训练”芯片,大部分数据将用于 LLM 推理。
是的,它使用了更多的硅,是的,它使用了更多的内存,是的,网络在某种程度上与 TPU 相当,对吧?它是 6,是 4x4x4 Taurus,只是他们以较低效率的方式进行,你知道他们在有源电缆上花费了更多,对吧?因为他们在自己的芯片上与 Marvell 和 Al 芯片合作,而不是与网络领域的领导者 Broadcom 合作,然后他们可以使用无源电缆,对吧?
它为您提供市场上所有芯片中每美元最大的 HBM 容量和每美元最大的 HBM 内存带宽,因此,对于某些应用程序来说,使用它确实是合理的。所以这是一个真正的转变,就像,嘿,我们可能不能像 英伟达那样设计得好,但我们可以在封装上放更多的内存,对吧?现在,这只是一个向量,就像您知道这里有一个多向量问题一样。他们的网络远不如英伟达。他们的软件远不如英伟达。他们的计算元素远不如英伟达,但他们的每美元内存带宽更高。
某些成本未分配给我们的部门,因为它们代表谷歌层面的活动。这些成本主要包括以人工智能为重点的共享研发活动,包括我们通用人工智能模型的开发成本;企业计划,例如我们的慈善活动;企业共享成本,例如某些财务、人力资源和法律成本,包括某些罚款和和解。
【如需和我们交流可后台回复“进群”加社群】



