

NVIDIA GPU在图形渲染、高性能计算两条路上都是一骑绝尘,让对手看不到尾灯,但是依然没有停下甚至放缓的节奏,如今又带来了重新设计的Blackwell GPU架构,而且通吃图形、计算两大领域。
随着RTX 50系列的正式发布,NVIDIA也公开了Blackwell的诸多细节,尤其是架构设计、AI神经网络渲染、DLSS 4技术,等等。
CES 2025大展期间,文Q受NVIDIA官方邀请参加了Editor's Day活动,提前了解了Blackwell的相关设计,并参观了多项现场技术演示。
下边,我们逐一来看。

【Blackwell GPU架构设计:四大目标】
相信这部分是大家最为感兴趣的,推荐各位首先回顾一下我们快科技在2022年10月份介绍的Ada Lovelace架构设计,对比来看Blackwell架构的变化会更有针对性。
NVIDIA首先承认,当前的GPU行业内,一方面是用户对画质、帧率的要求越来越高,还得兼顾,但另一方面摩尔定律逐渐放缓。
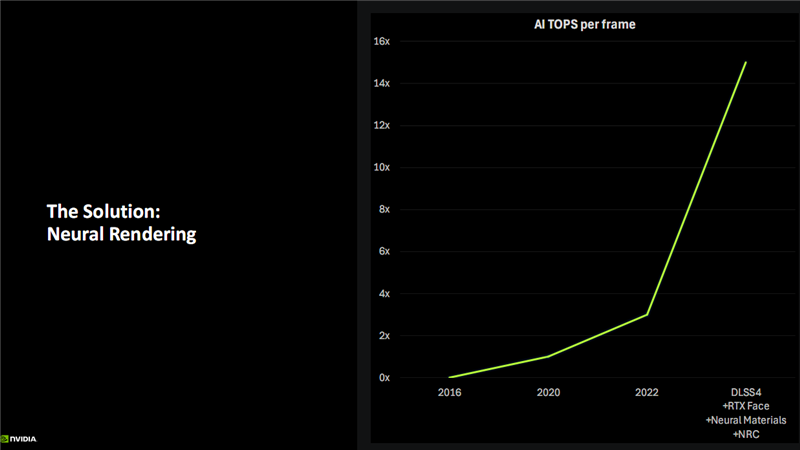
这一尖锐的矛盾如何解决,NVIDIA给出的答案就是——支持神经网络渲染、AI算力飙升的Blackwell架构。
虽然AI渲染已经诞生很多年,日渐普及,但是很多玩家依然特别在意所谓的原生渲染性能,特别是光栅化游戏的性能,而对DLSS这样基于AI算法的技术嗤之以鼻,认为算出来的画面都是作弊。
这种看法显然有失偏颇。坦白地说,至少在现有技术条件下,AI计算出来的画面肯定和原生渲染画面有一定区别,但第一,我们最终需要的是更好画质、更高帧率这一结果,只要能达成目的,方法和手段是次要的;毕竟原生渲染出的画面其实也不是真的画面,只是实现的渲染方式的差别罢了。
第二,AI技术和算法也在不断快速进步,越来越逼近甚至超过原生渲染的画质,迟早会让人无法轻易分辨或反而带来画质的提升;
第三,传统渲染技术进步越来越难,不可能一直抱残守缺,需要不断革新。

为此,NVIDIA提出了Blackwell架构设计的四大主要目标:优化新的神经网络负载、降低显存占用、优化AI精度与大模型、更高能效。
最终,Blackwell架构通过第五代Tensor Core,在新的FP4数据精度下,最高可达4000 AI TOPS(每秒4千万亿次计算)的超高算力;
通过第四代RT Core,达成了360 RT TFLOPS(每秒360万亿次计算)的性能;加入了全新的AI管理处理器(AM P),可以同步管理AI模型与图形,自动拆分不同的变成类型,调度分配给不同的硬件执行,尤其是AI相关的。
重组了SM单元,专为神经网络着色器(Neural Shaders)而组建,性能高达125 TFLOPS;
针对移动端升级了Max-Q,能效提升2倍;
还首发了新一代GDDR7显存,最高速率达30Gbps。
1、优化新的神经网络负载
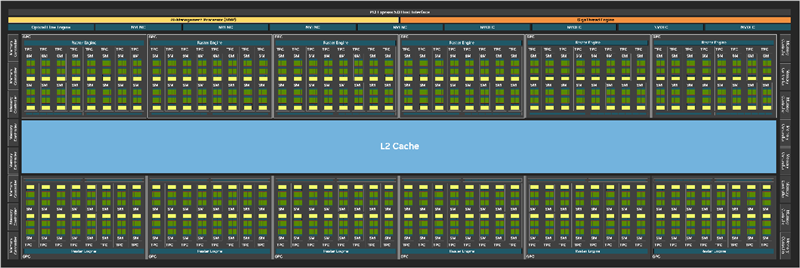
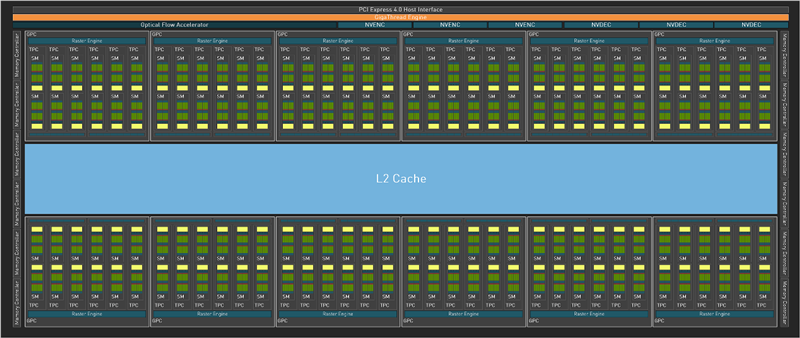
上下图分别为Blackwell(GB202)、Ada Lovelace(AD102)的架构布局总图,大体上没什么变化(当然规模更大了),属于又一次升级版。
最直接的变化,就是增加了一组AI管理处理器,和原有的线程引擎并列负责负载分配,同时PCIe 4.0升级来到了PCIe 5.0。

SM(流式多处理器单元)一直是NVIDIA GPU的基础模块,Blackwell做了大幅度的变革。
一是将传统的着色器改造为神经网络着色器,加入多个神经网络处理单元。
二是将FP32/INT32、FP32两种不同的着色器核心,统一为FP32/INT32(总数不变),也就是之前有一半着色器核心只能处理单精度浮点数据,而现在所有的都可以同时处理整数、浮点运算,效率更高,调度也更灵活,当然对负载分派的准确性、效率也有更苛刻的要求。
三是将第三代Tensor Core 升级为第四代。
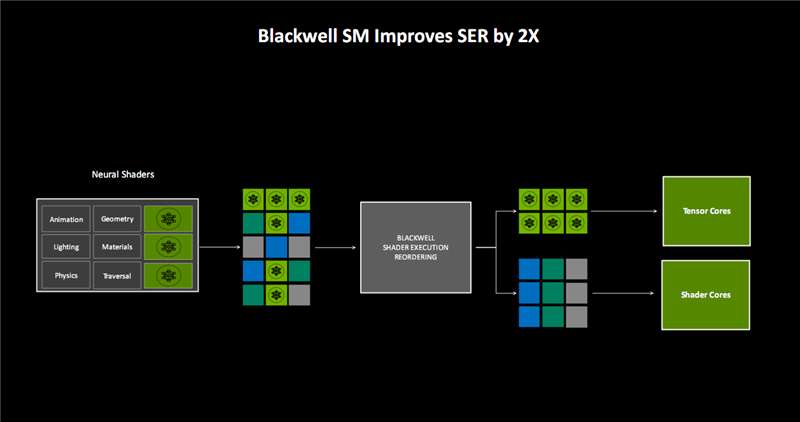
随着专用神经网络处理单元的加入,结合原本的光照、几何、物理、材料、光线遍历等单元,可以将输入的不同工作负载,更高效地进行能够重排序。
其中,神经网络类负载会专门交给Tensor Core,其他则交给着色器核心,SER(着色器执行重排序)性能提升了2倍。
2、降低显存占用
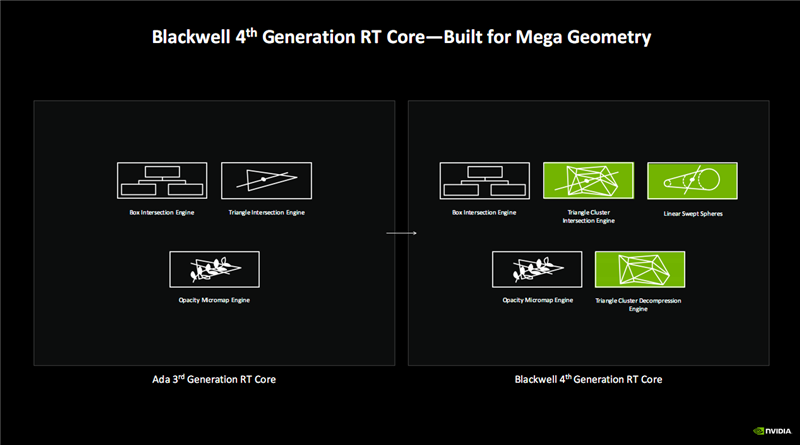
RT Core升级为第四代,重点提升了检测光线、路径与三角形相交的性能与效率,能够以大规模的集群方式进行,效率提升数十上百倍。
其中,原有的三角形碰撞引擎,升级为三角形集群碰撞引擎(Triangle Cluster Intersection Engine),新增三角形集群解压缩引擎(Triangle Cluster Decompression Engine),二者联合可处理百万级别的超大规模三角形。
还新增了线性扫描球体(Linear Swept Spheres),主要用于毛发的渲染,使用球体代替三角形来获得更准确的毛发形状拟合,从而大大减少所需的几何图形数量,性能更好,显存占用更少。
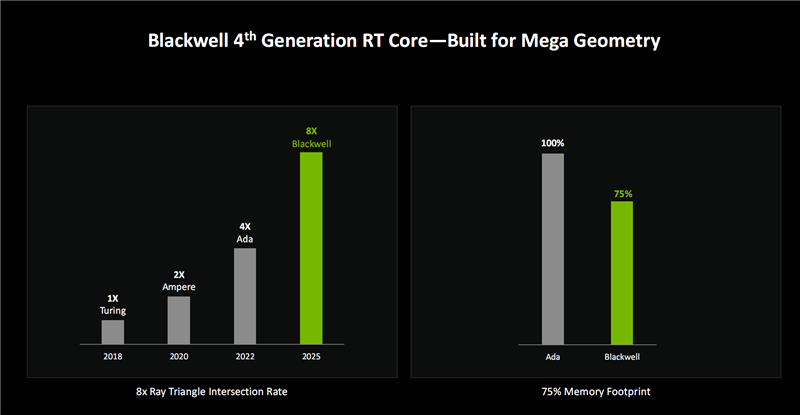
NVIDIA将这种高效的三角形处理方法称为RTX “Mega Geometry ”(海量几何),非常适合渲染全景光追,模型复杂度可提升上百倍。
按照NVIDIA的说法,Blackwell的三角形交互处理效率比Ada架构再次提升了2倍(对比首次加入光追的Turing则提升8倍),而显存占用量降低了25%。
3、优化AI精度与大模型
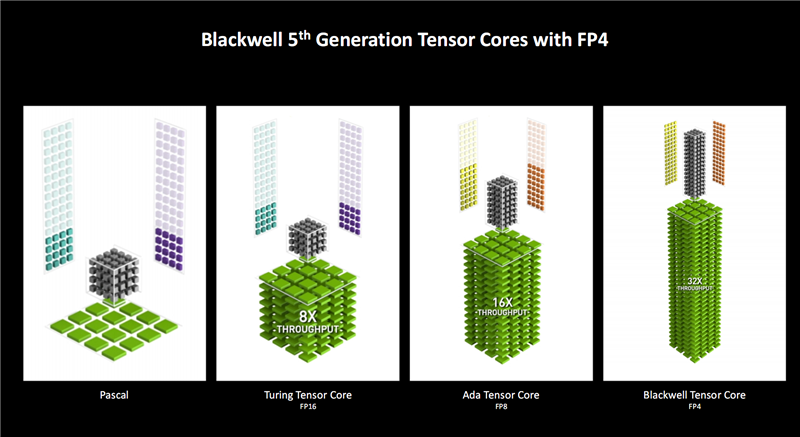
随着架构与Tensor Core的迭代,支持的数据类型越来越多,支持的精度越来越低,速度也越来越快。
Turing架构在原有FP32精度的基础上首次支持FP16浮点精度,对比Pascal在吞吐量上提升了8倍之多,而之后的Ampere架构没变。
Ada Lovelace增加了FP8浮点精度,吞吐量再次翻番。
Blackwell又首次增加了FP4精度,性能也继续翻番,当然它同时也支持FP8、FP16、FP32,因此灵活性更强,可以随时处理不同精度的数据和负载。
数据精度更低,所需要的处理能力和带宽更少,速度自然更快,这也就是Blackwell宣称性能提升X倍的一个主要原因。
当然,低精度数据格式的缺点是准确性会有牺牲,需要根据实际情况选择最合适的精度。
INT32、INT16、INT8、INT4、FP32、FP16、FP8、FP8、TF32、BF16等等都是模型的量化级别,主要区别在于浮点数的位数和量化的方式。
一般来说,位数越少,量化越多,模型越小,速度越快,但精度也越低,有点像文件压缩,反之亦然。
高精度模型体积庞大,数据丰富,训练、微调、推理需要更长的时间,对算力要求更高,而通过低精度量化,可以缩小模型体积,降低硬件要求,提高运行速度,但输出效果会相应降低。
具体选择什么样的精度,取决于实际情况所需,尤其是运行于什么样的设备、需要什么样的结果。
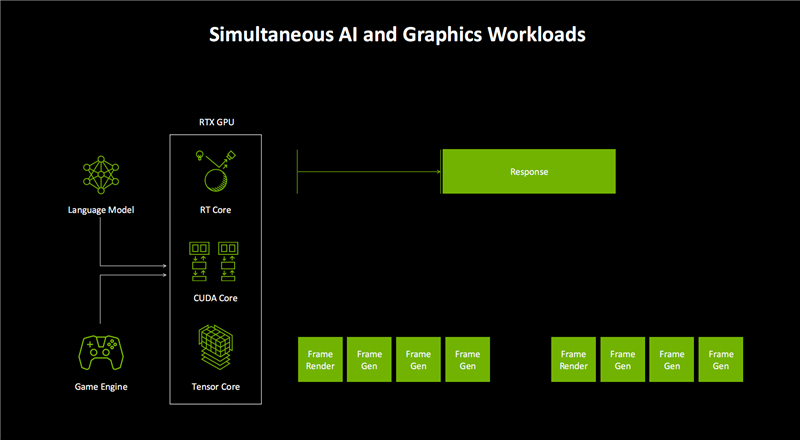

这就是之前说的AMP(AI管理处理器)的作用示意图。
它会对输入的不同指令类型进行自动识别、区分,包括AI语言模型、游戏引擎两大类,然后按照最适合执行的硬件单元,分配给CUDA Core、RT Core、Tensor Core去分别执行。
特别是大语言模型(LLM),会被优先处理、执行和响应,同时帧渲染和帧生成的节奏也会更加紧凑、协调,多帧生成提供一致的画面生成时间。
4、更高能效

为了在提升性能的同时控制功耗、保持高能效,Blackwell也下了不少功夫,尤其是在移动端,也对Max-Q做了全新升级。
其中时钟门控(Clock Gating),数据无效时关闭寄存器的时钟;电源门控(Power Gating)可关闭空闲模块的电源;
进一步加入的电路门控(Rail Gating),更是可以进一步在空闲或待机时,关闭大部分的计算模块。
这些节能措施不仅适用于笔记本电脑GPU,台式机GPU同样可以从中获益。

Blackwell还支持加速频率切换(Accelerated Frequency Switching),相比之前的时钟控制器,对于时钟频率的响应切换速度提升了上千倍,进入睡眠或唤醒的速度也提升了几个量级。
同时,通过在动态负载中加快时钟调整速度,整个SM单元的效率也大大提升。
简单地说,这可以让GPU在需要时更稳定地运行在更高频率,而一旦完成工作可以快速将频率降到最低,进入睡眠等待状态。
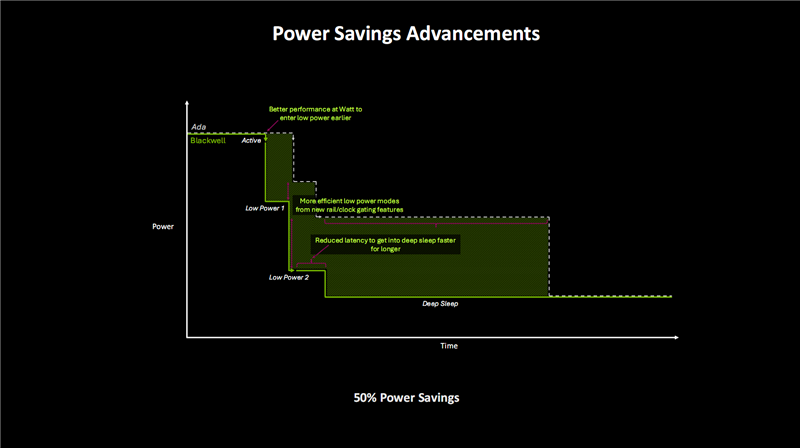
更高的性能可以让Blackwell在更短的时间内完成工作,从而尽快转入低功耗模式。
新的电路/时钟门控又大大提高了低功耗模式的效率,使之功耗状态更低,而更低的延迟可以让GPU更快地进入睡眠状态,并保持更久。
NVIDIA表示,Blackwell比上代可以节省多达50%的功耗。
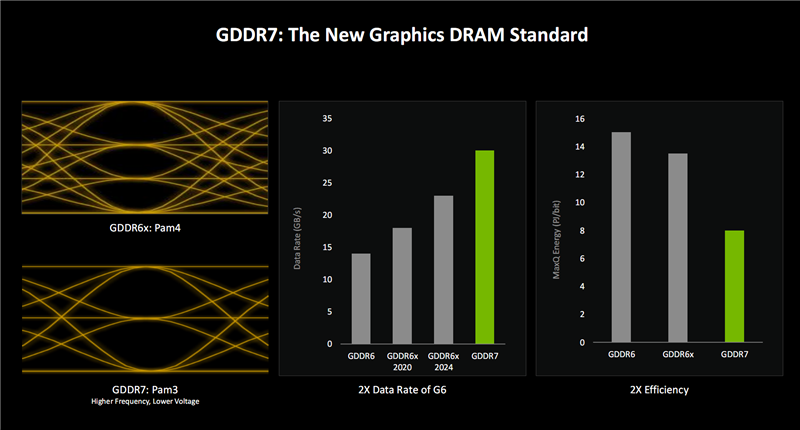
GDDR7显存就不用说太多了,首次采用PAM3信号编码机制,相比于GDDR6 PAM2、GDDR6X PAM4,将每时钟周期的数据传输从1/2位增加到3位,自然显著提升了传输带宽。
GDDR7目前的数据率已经达到30Gbps,未来可以轻松超过40Gbps,三星的研究甚至到了42.5Gbps。
同时,GDDR7还可以显著降低能耗,基本是GDDR6的一半左右。

对媒体能力方面,Blackwell终于将DisplayPort的支持从1.4a版本提升到了最新的2.1,并且支持最高的UHBR20模式,单通道带宽就有20Gbps,最多可以四个通道并行,总带宽高达80Gbps,相当于1.a的几乎10倍。
藉此,Blackwell系列可以支持高达8K 165Hz规格的显示器。
NVDEC解码引擎升级到第九代,NVENC编码引擎升级到第六代。
AV1格式升级支持到UHQ超高质量模式,HEVC(H.265)格式升级支持到MV-HEVC(多视图), H.264解码能力翻倍,色度格式则从4:2:0升级到4:2:2。
【RTX神经网络渲染:实时光追新境界】
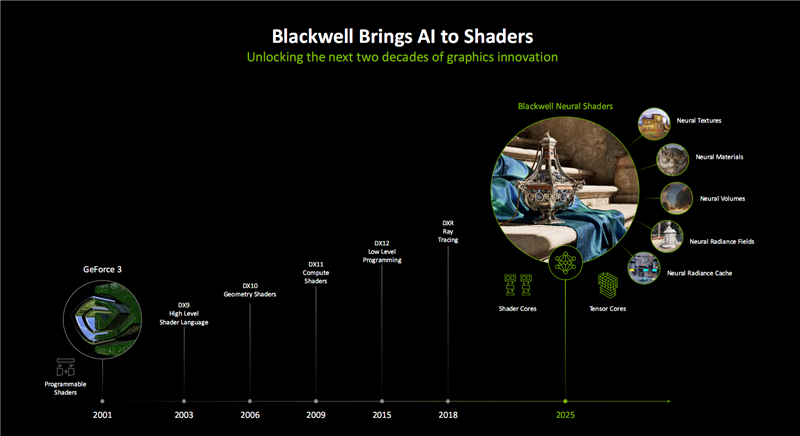
二三十年来,GPU渲染技术一直在创新突破,从2001年NVIDIA推出可编程着色器之后,着色器、编程语言不断演进,尤其是2018年实时光追的加入堪称一次革命性的飞跃。
如今,Blackwell首次引入神经网络着色器,将更多AI的力量融入其中,又为开发者带来了全新的编程方式。
这其中又分为多种细分技术,适用于不同对象的开发,包括神经网络纹理压缩(Neural Texture)、神经网络材质(Neural Material)、神经网络体积(Neural Volume)、神经网络辐射场(Radiance Filed/利用深度学习从部分二维图像集中重建复杂三维场景)、神经网络辐射缓存(Radiance Cache/NRC),等等。
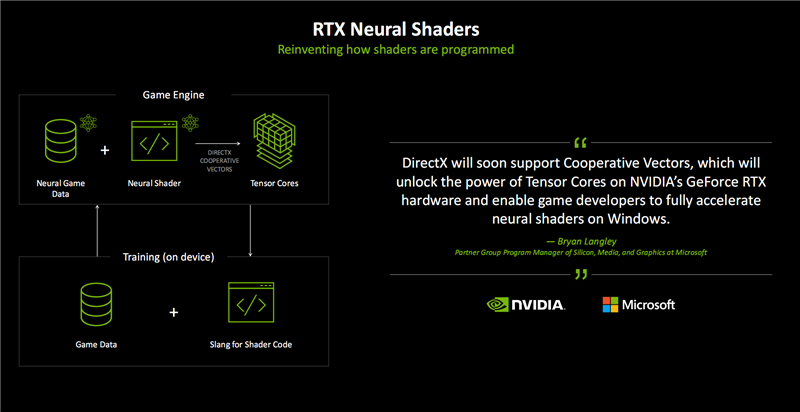
这就是RTX神经网络着色器的工作流程示意图,涉及到神经网络处理游戏数据、神经网络着色器、Tensor Core、Slang着色器编程语言、端侧训练等诸多环节,形成一个不断增强的闭环。
其中,Cooperative Vector(协作矢量)是一个全新的API,可以让开发者很方便地在DirectX游戏与应用中无缝集成神经网络图形技术,加速访问AI加速器硬件。
这项技术已经得到微软的大力支持,未来将会成为DirectX的一部分,能让开发者充分挖掘RTX Tensor Core的潜力,从而在Windows系统上通过神经网络着色器加速游戏开发。
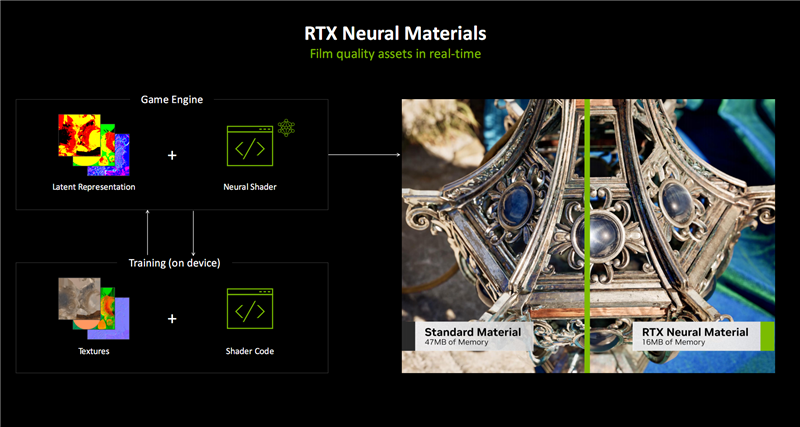
RTX神经网络纹理、RTX神经网络材质可以简单地理解为更高效、高质量的AI纹理与材质压缩。
它能分层保留更多的材质细节,处理速度可提升5倍之多,而且显存占用空间更小,甚至只需原来的1/7,大大降低硬件负担。
当然,它也可以在同样的显存空间内压缩保存更多材质,从而大大丰富画面细节,比如金属表面的锈迹、宝石表面的纹理,都能结合光线照射,更精致地呈现出来。
这种效果在以往需要漫长的渲染,只能在影视里展现,而现在可以做到实时呈现,从而放在游戏中。

RTX神经网络辐射缓存(NRC)利用实时游戏数据训练的神经网络,更准确高效地估算游戏场景中的间接光照。
它只需追踪有线的光线数量,结合实施自我训练网络,利用AI的力量,去预测、推算出大量的后续光线反射、弹跳,更准确地渲染场景的间接光照效果。
这不仅大大提升了路径光追的质量,也减少了需要追踪的光线数量,从而同时提升画面质量与运行帧数。


NRC关闭、开启效果对比:尤其注意地砖的阴影效果,而帧率是差不多甚至可以更高的。

基于神经网络着色器渲染技术,NVIDIA已经开发出了多个应用实例,包括用于皮肤的RTX Skin、用于脸部的RTX Neural Face、用于毛发的RTX Hair。
我们知道,人类皮肤其实是半透明的,传统渲染只能处理皮肤表面的纹理材质、光照效果,RTX Skin则使用了次表面散射(Subsurface Scattering/SSS)的方式,模拟光线穿透半透明材料的效果,就像“穿透”皮肤表层,从而获得更真实的柔和、自然感。

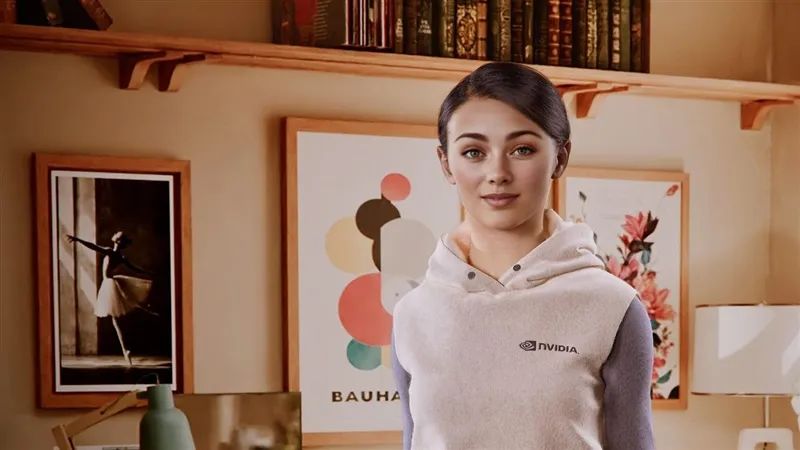
人脸渲染一直是巨大的难题,很细微的偏差也很容易被看出来,稍有不慎就会引发“恐怖谷效应”,让人感到极为不适。
RTX Neural Face基于在超级计算机上提前学习和训练的成千上万张人脸数据集,只需要简单的光栅化渲染人脸、3D姿态数据,就可以通过生成式AI模型,实时推断、渲染出更自然的人脸,效果,包括不同的角度、光照、情感、表情、遮挡等等。
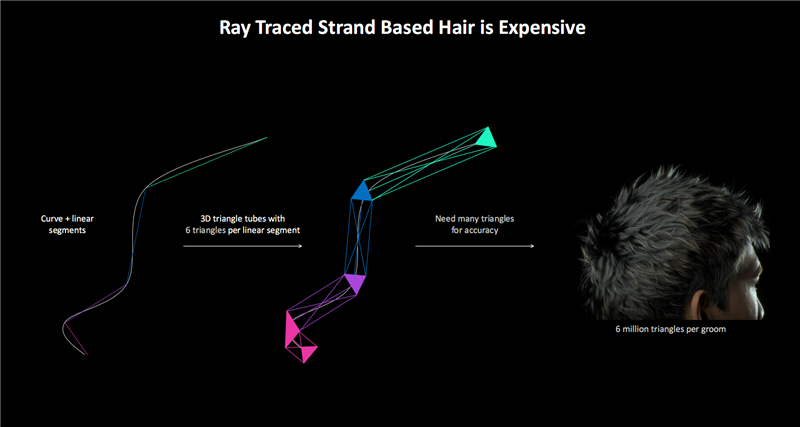

毛发的自然处理同样是老大难问题,往往涉及到海量的数据与计算。
传统渲染使用大量三角形来获得更自然的毛发效果,一般每根毛发需要30个三角形,整个人类发型就得大约400万个三角形。
如果使用光追的包围盒层次加速结构(BVH),计算量就会异常庞大,只能降低精度或者减少毛发数量。
Blackwell的线性扫描球体(LSS)技术,将三角形替换为球体,可以更精准地呈现毛发形状,使得实时的毛发光追成为可能,还能减少显存占用。
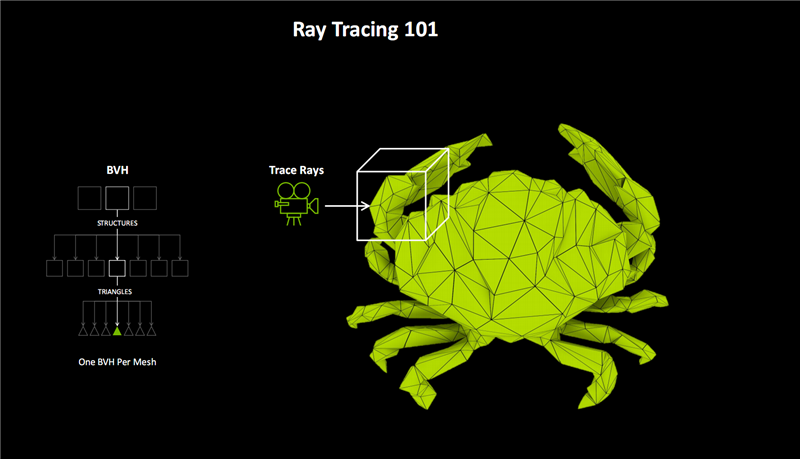
虚幻引擎5提出了一套名为Nanite的几何系统,通过上亿的海量三角形构建复杂的光追场景,但需要极高的硬件性能,比如《黑神话:悟空》对于显卡的苛刻要求大家有目共睹。
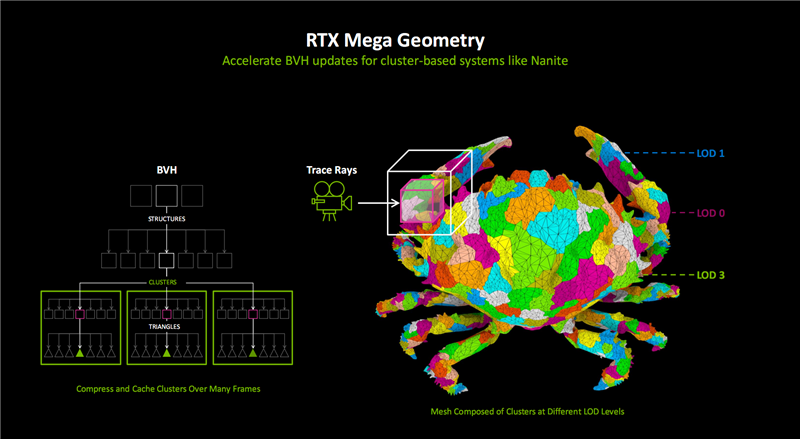
为解决这一挑战,NVIDIA提出了更高效的海量三角形几何渲染方法“RTX Mega Geometry”。
它可以快速、智能地生成、处理、渲染100倍于传统方法的光追三角形集群,并结合Ada架构上引入的OMM处理材质的透明度,同步提升光追性能和图像质量,从而在复杂场景中获得逼近现实的真实光照效果。
RTX Mega Geometry将会很快加入NvRTX的虚幻引擎分支,帮助虚幻引擎Nanite更高效地完成光追场景渲染。

左为传统光追渲染,右为Mega Geometry渲染:尤其注意栏杆投影,传统渲染有明显缺失

传统渲染的三角形数量

Mega Geometry渲染的三角形数量

渲染场景
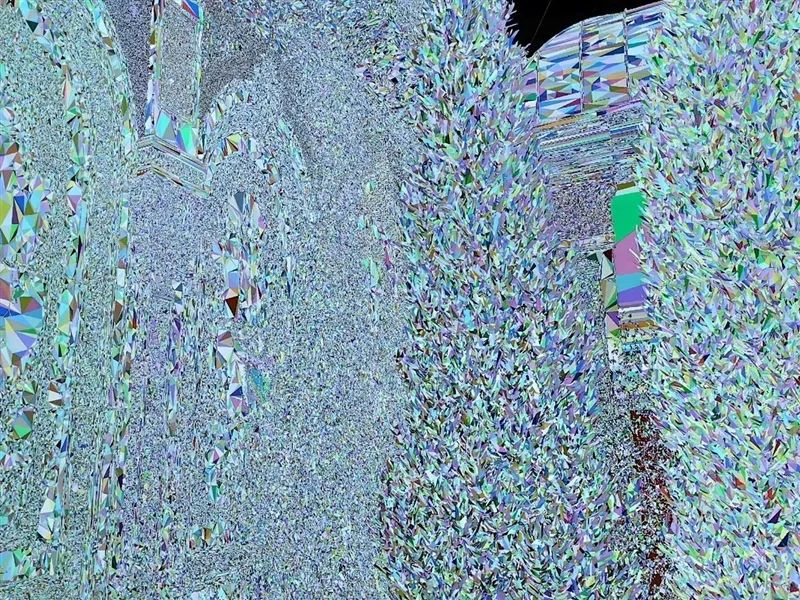
实时渲染的三角形数量

同样场景下传统渲染的三角形数量


三角形数量已经多得“模糊一片”

【DLSS 4:性能轻松提升至8倍】
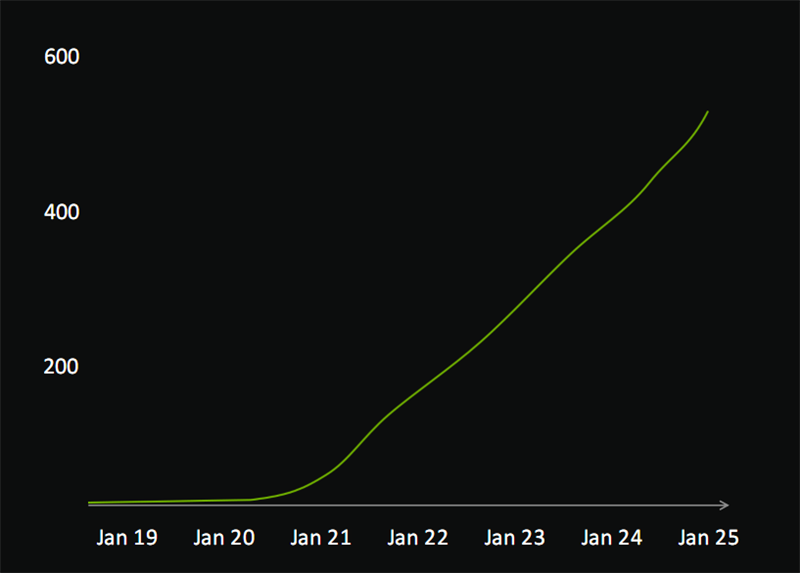
NVIDIA DLSS其实就是基于RTX Tensor Core的神经网络渲染技术。
经过6年来的不断演进,DLSS目前已有超过540款游戏和应用支持,2024年前20大游戏中有15款支持,超过80%的RTX显卡玩家都会开启,游戏总时间超过30亿小时。
可以说,无论是技术创新,还是普及程度,NVIDIA DLSS都始终远远领先于AMD FSR、Intel XeSS。
全新的DLSS 4引入了2020年DLSS 2发布以来的最重磅升级:
DLRR光线重建、DLSR超分辨率、DLAA抗锯齿都在传统CNN(卷积神经网络)模型的基础上,引入了Transformer模型支持,这也是图形领域的第一个实时Transformer应用场景。
Transformer正是ChatGPT、Flux、Gemini等前沿AI大模型使用的基础架构,引入到DLSS之后参数量增加2倍,计算性能提升4倍,可以显著增强画质、提升稳定性、减少伪影,提供更多的细节表现。
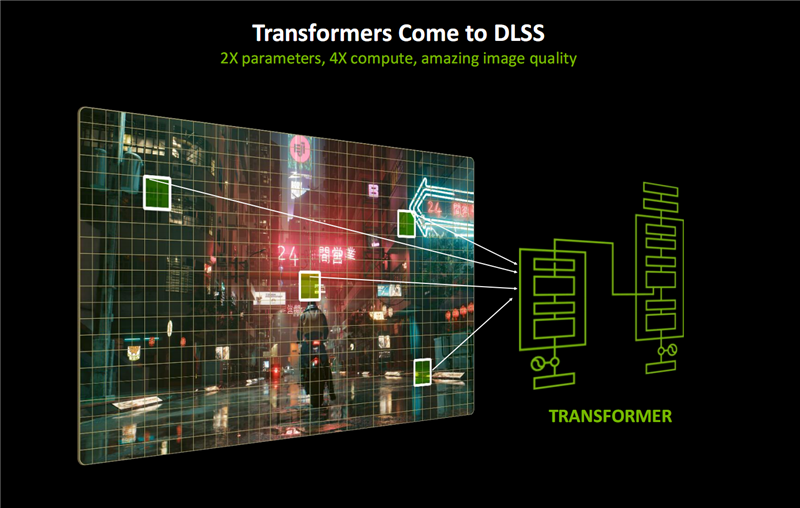
此前,DLSS采用CNN架构,通过分析局部上下文、追踪连续帧画面有关区域的变化,来预测、生成新的像素和画面,其应用潜力已经基本被挖掘殆尽
DLSS Transformer模型采用Vision Transformer,可以通过自注意力操作(Self-Attention),来评估整个画面、多个帧画面中每个像素的相对重要程度。
由于采用了2倍于CNN模型的参数量,更深入地理解场景,DLSS Transformer生成的像素具有更好的稳定性、更少的伪影、更丰富的运动细节、更平滑的边缘。
最大的好消息是,DLSS Transformer并不是RTX 50系列独享的,所有的RTX GPU都能使用。


在密集型光追的处理上,比如光线重建,Transformer模型可显著提升画质,尤其是在光照条件复杂的场景中。
比如《心灵杀手 2》,DLSS 4处理的铁丝网区域更稳定,电线区域的闪烁完全消除。

再比如《地平线西之绝境》,DLSS 4下的背包纹理细节更丰富、清晰,整体清晰度也大大提高。
由于是第一次采用Transformer模型架构,DLSS 4仍有一些不足之处,比如图像伪影仍然会偶尔出现、超性能模式优化不够到位,但未来发展空间更大,会持续改进升级。
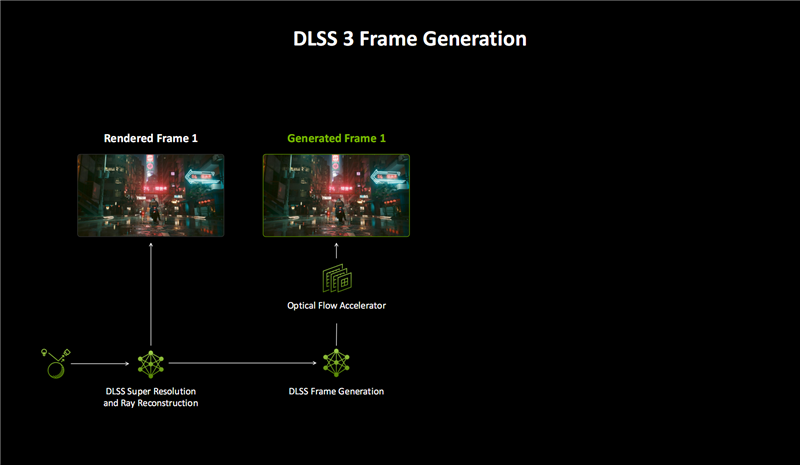
DLSS 4的另一大革新是多帧生成(MFG),AI可以生成更多的像素和帧。
DLSS 3首次加入了帧生成(FG),首先结合DLSR超分辨率、DLRR光线重建,渲染一个帧画面。
然后通过AI模型和游戏数据,比如运动矢量、深度等,再借助RTX 40 GPU的光流加速器硬件,获得一个额外的帧画面。
换言之,每生成一个帧画面,都需要大量的软硬件协同,开销非常大,效率也不够高。
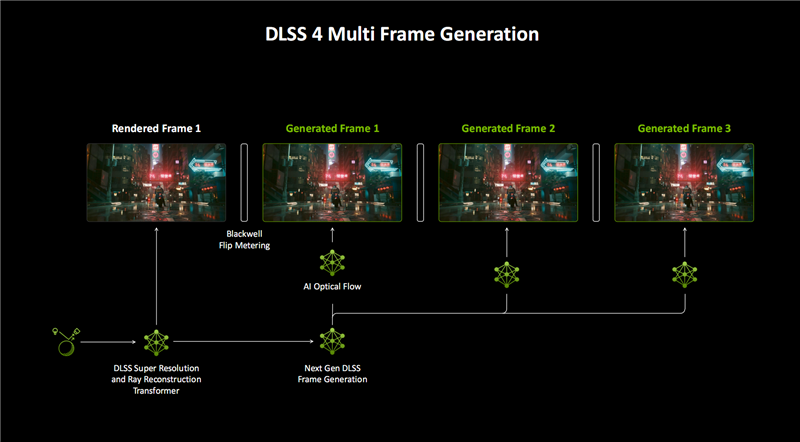
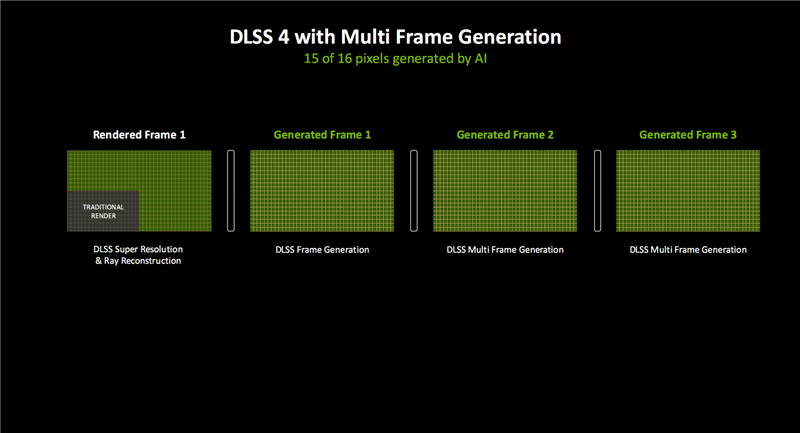
DLSS 4的多帧生成(MFG)技术引入新 模型之后,全新AI模型生成帧画面的速度提升了40%,显存占用降低了30%,而且只需运行一次,就能为每个传统渲染帧额外生成多达三个帧。
再配合超分等一整套DLSS技术,可以将帧率提升至传统渲染的最多8倍!
软硬结合,DLSS 4可以生成16个像素中的15个(之前是7/8),同时保证出色的画质、流畅度和延迟。
同时,RTX 50的多帧生成模型不再需要 光流加速器硬件,而是使用效率极高的AI模型代替它来加速光流场的生成,从而显著降低额外帧生成的计算开销。
当然,GPU 仍然需要在几毫秒的时间里,为每一个渲染帧运行超分辨率、光线重建、多帧生成等5个AI模型,这时候第五代Tensor Core就发挥了其关键作用,可将AI处理性能提升最多2.5倍。

比如在《战锤40K:暗潮》中,RTX 5090 D显卡,4K分辨率,DLSS 4多帧生成可将性能从124FPS提高到137FPS,同时显存占用从9GB降至8.6GB。
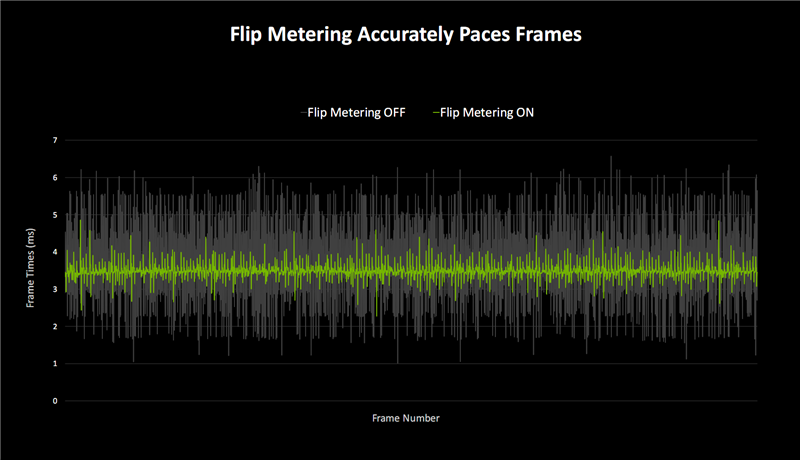
流畅度方面,DLSS 3 帧生成技术使用CPU Pacing技术控制帧画面显示。
在这种情况下,节奏差异会随着附加帧数的增加而越发严重,导致每两帧之间帧节奏不一致,进而影响流畅度,直观表现就是卡顿。
Blackwell DLSS 4则改成了基于硬件的Flip Metering,使用显示引擎控制帧节奏逻辑,更精确地管理显示时间,从而平稳处理错综复杂的多帧生成过程。
Blackwell的显示引擎也做了改进,像素处理能力提高一倍,从而支持更高分辨率和刷新率,满足Flip Metering、DLSS 4的要求。

《赛博朋克2077》在不同DLSS下的性能对比:DLSS 2搭配超分辨率,可将性能提升至3倍,延迟降低大约50%;
DLSS 3.5搭配帧生成、光线重建,可再次将性能翻倍,延迟基本不变;
DLSS 4搭配多帧生成、Transformer模型,性能可达8倍之多,而延迟仍然只有一半左右。


《黑神话:悟空》现场演示DLSS 4多帧生成技术,性能轻松可达原生的8倍甚至更高!

正因为有了DLSS 4,RTX 5090或者RTX 5090 D这样的顶级显卡,就可以在4K分辨率下获得几百FPS的超高性能,完全可以匹配并发挥240Hz及以上高刷显示器的潜力。
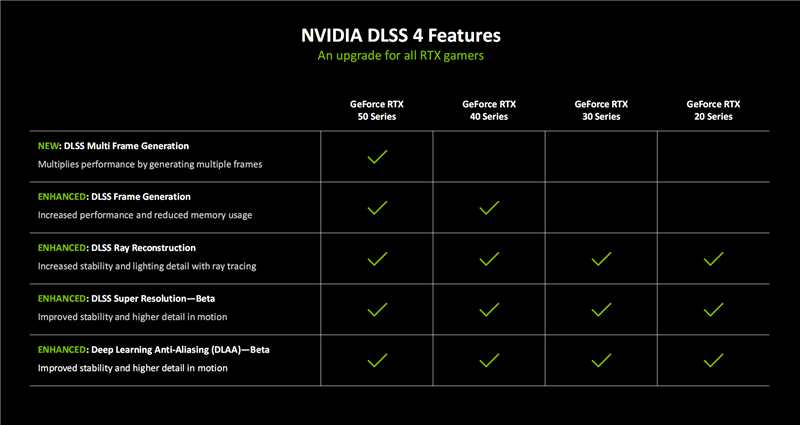
DLSS发展至今,已经是一整套不同技术的结合,而不同的GPU显卡的支持程度也截然不同。
早期的RTX 20、RTX 30系列支持DLAA抗锯齿、SR超分辨率、RR光线重建。
RTX 40系列增加了FG帧生成,RTX 50系列则又独享MFG多帧生成。
这倒不是NVIDIA故意不让老产品支持新技术,而是新技术依赖老产品所没有的硬件单元,比如RTX 50系列的多帧生成,就离不开第五代Tensor Core。



目前已有75款游戏和应用确定在RTX 50系列显卡上市首日支持DLSS 4和多帧生成技术。
第一批首发游戏包括《心灵杀手2》《赛博朋克2077》《夺宝奇兵:古老之圈》《星球大战之绝地:幸存者》等 。
同时,后续还会有大量游戏更新支持DLSS 4技术,包括《永劫无间》《漫威争锋》《微软飞行模拟2024》《黑色国度》《毁灭战士:黑色时代》《沙丘:觉醒》《黑神话:悟空》等等。
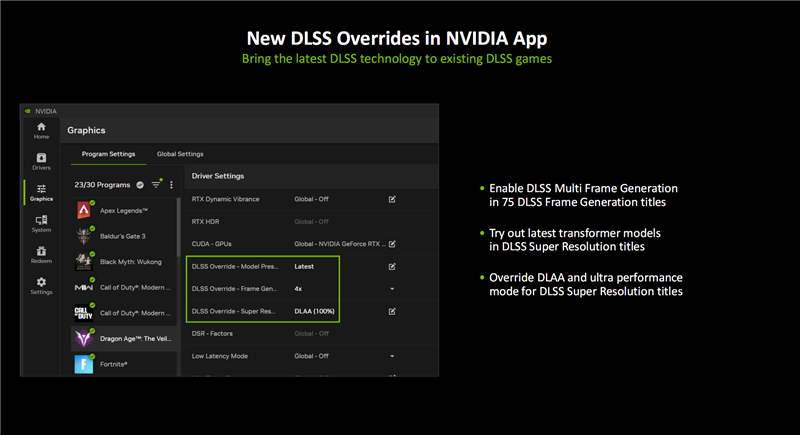
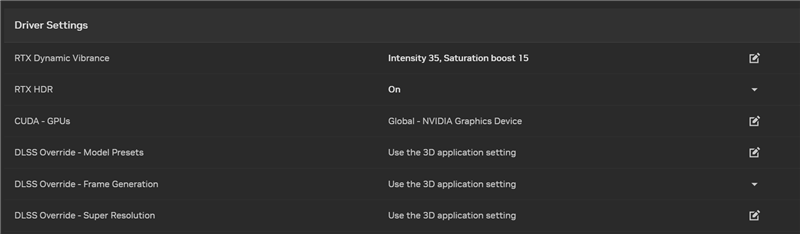
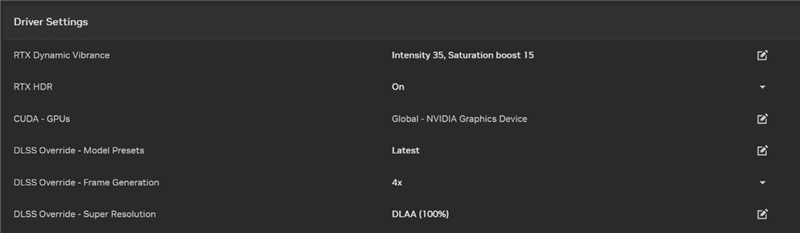
如果游戏还没有更新支持DLSS的最新模型和功能,NVIDIA App也会随着RTX 50系列的上市而更新,提供专门的DLSS Override优化设置选项。
新选项位于图形、程序设置界面中的“驱动设置”,可以为每个支持的游戏启用不同的DLSS选项:
模型预设:游戏DLSS开启,RTX 50/40系列用户可以使用最新的帧生成模型,所有的RTX用户都可以使用基于Transformer架构的DLSS超分辨率、DLSS光线重建模型。
帧生成:游戏帧生成开启,RTX50系列用户即可启用多帧生成技术。
超分辨率:游戏超分辨率开启,所有RTX系列用户都可以使用DLAA抗锯齿,或者超级性能模式。
随着新模型在更多游戏中完成测试,有有越来越多的游戏加入DLSS优化设置支持列表。
【NVIDIA ACE:当游戏角色“活”过来】
几十年发展下来,虽然游戏画面越来越精致,游戏角色越来越像真人,但是NPC交互始终都是程序化的、固定化的,毫无乐趣可言。
2003年,NVIDIA就推出了数字人生成套件ACE,又打造了游戏助手G-Assist(来自2017年的一个愚人节创意),去年的CES 2024、台北电脑展上我们都实地体验了一番。

NVIDIA ACE可以利用先进的生成式AI本地小模型,在游戏、应用中生成可自然交互的虚拟数字人物,即时响应玩家的交互,包括文字、语音甚至视觉。
同时有Audio2Face(A2F)等AI模型可以生成丰富、自然的面部表情,Riva自动语音识别(ASR)可以用于多语言语音翻译。
目前,NVIDIA正在将ACE的应用范围,从对话型NPC,扩展至拥有自主意识的游戏角色,它能利用AI像真人玩家一样感知、计划和行动。
在生成式AI的加持下,ACE可以打造生动、动态的游戏世界,队友能够理解并支持玩家完成目标,而敌人则能灵活地应对玩家的战术。
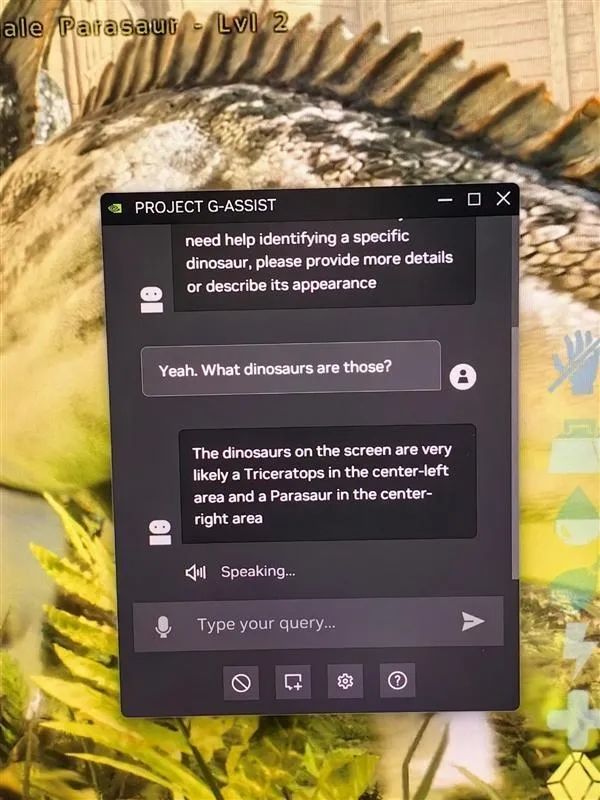
G-Assist可以帮助玩家回答有关生物、物品、背景知识、任务、关卡BOSS等方面的问题,而且是根据玩家不同进程的个性化交互,从而免去查找攻略或反复尝试的麻烦。
它甚至能帮助玩家测试本机游戏的帧率、延迟、1%低帧等性能参数,并提供优化建议。
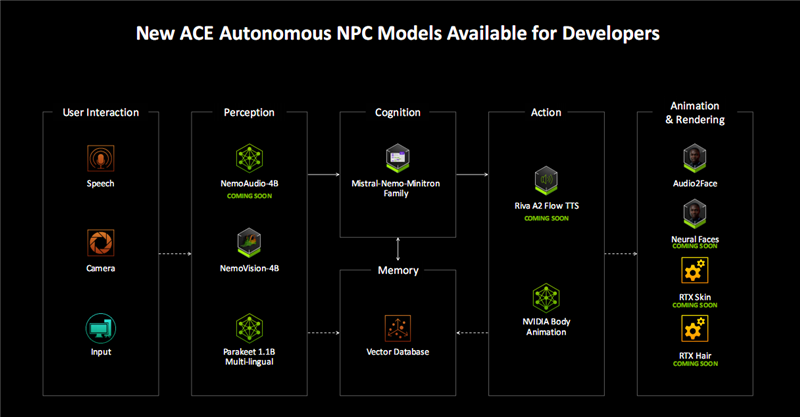

如今,NVIDIA ACE套件得到了极大增强,在多个环节都有全新技术加持。
比如在感知环节,新增了NemoAudio-4B,一种新的音频+文本输入和文本输出小语言模型,能够描述游戏环境的声景。
比如在最终的动画与渲染环节,基于Blackwell神经网络渲染的RTX Face、RTX Skin、RTX Face等新技术,配合Audio2Face,可以生成更加栩栩如生的游戏人物角色。

CES 2025现场,NVIDIA有展示了多个游戏中的AI应用,包括《永劫无间手游》PC版、《绝地求生》、《动物朋克》、《传奇5》。
其中的AI队友、AI NPC、AI BOSS都变得栩栩如生,仿佛有了自己的自主意识,或者和你交互对话,或者和你共同打怪,或者有针对性地与你对战。
另外,《诛仙世界》《inZOI》、《Dead Meat》、《AI People》、《异形:侠盗入侵》等游戏也将陆续加入ACE AI角色或系统。
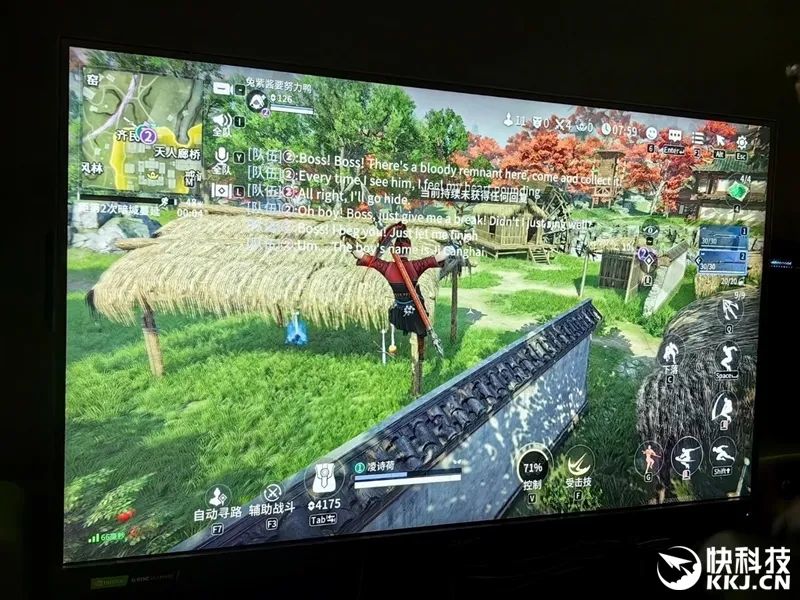
比如《永劫无间手游》PC版,NVIDIA ACE 提供支持的AI队友可以与玩家组队,并肩作战,找到所需的特定道具,交换装备,提供解锁技能的建议,并做出有助于取得胜利的战斗决策。
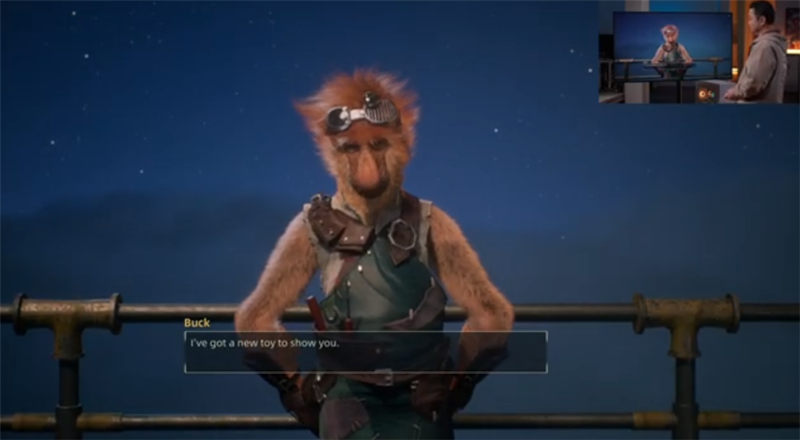
比如《动物朋克》,首次在端侧实现了游戏内的 Diffusion图像生成,引导玩家在云海之上的漂浮厨房展开对话和互动。
玩家可与盟友讨论在任务中收集到的情报,也可前往码头设计一艘新战舰,帮助雷顿(Rayton)与机械帝国作战。

再比如《传奇5》,AI会评估真人玩家的装备和设置,将其与过去的对战进行比较,然后确定取得胜利的最佳行动方案。
因此,每一位玩家的BOSS对战都是独一无二的,即便是玩家再次击杀已经被打败的BOSS,结果也可能完全不同。

小结:
从硬件架构变革幅度上看,Blackwell算不上一次颠覆性的突破,但是在GPU发展史上,它注定是浓墨重彩的一笔,因为它将AI融入到了方方面面,甚至可能是图形渲染技术演化 的一次重要转折点。
按照传统的GPU发展思路,我们只能暴力增加GPU规模,包括增加晶体管与计算核心数量、提升频率与功耗,来达成更好的性能,获得更好的画面和帧率。
尤其是在摩尔定律越走越困难,先进制程工艺已经无法像从前那样带来显著收益,半导体行业尤其是GPU行业,更需要重新思考如何更好地走下去。
如今在AI的加持下,一条新路正在越走越宽,从图形画面的渲染,到光线路径的追踪,再到游戏角色的塑造,都可以借助AI更高效地达成更好的效果。
或许你会认为这是投机取巧,这是作弊,但其实,这或许才是GPU乃至整个半导体发展的未来。
当然,现在下定论还为时过早,一切还是留给时间去检验吧。
目前,我们正在对RTX 5090D进行紧张的评测,将在第一时间为大家奉上,敬请期待!

