点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 新智元 授权
【导读】不断迭代简单的提示词「write better code」,代码生成任务直接提速100倍!不过「性能」并不是「better」的唯一标准,还需要辅助适当的提示工程,也是人类程序员的核心价值所在。
2023年11月,在ChatGPT支持DALL-3功能后,一个爆火的图像生成玩法是,不断迭代提示词「make it more X」,生成的图片越来越抽象。
把这个思路用在LLM任务上,比如代码生成,会怎么样?最近,BuzzFeed的高级数据科学家Max Woolf在博客上分享了一个实验,通过设计不同的提示词、不断迭代模型输出,最终实现代码性能的100倍提升!
完整代码链接:https://github.com/minimaxir/llm-write-better-code/特别需要注意的是,「性能」并不是唯一优化指标,迭代过程中需要在提示词中明确定义什么是「好」。设计实验题目时,为了充分测试LLM的自主代码能力,必须保证「测试提示词」完全原创,不能源于LeetCode或HackerRank等测试,模型无法通过背诵记忆来作弊;测试题目要尽可能简单,新手也能实现,但还要预留大量可优化空间。
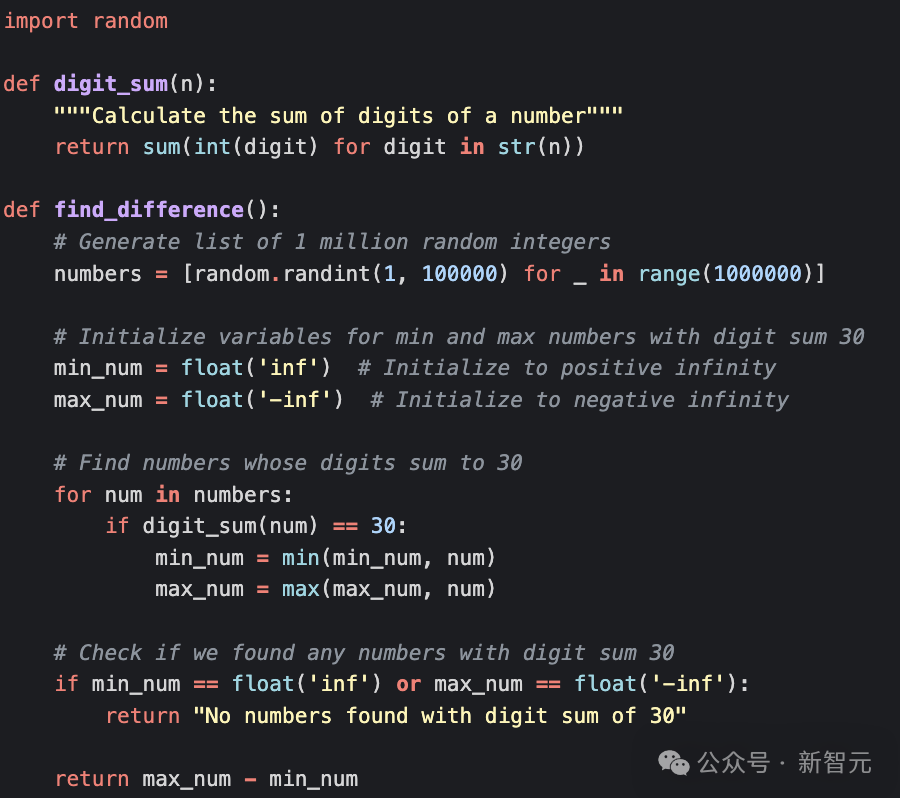
最终选择Claude 3.5 Sonnet模型,设计了一个Python语言、面试风格的编码提示词:Write Python code to solve this problem: Given a list of 1 million random integers between 1 and 100,000, find the difference between the smallest and the largest numbers whose digits sum up to 30.
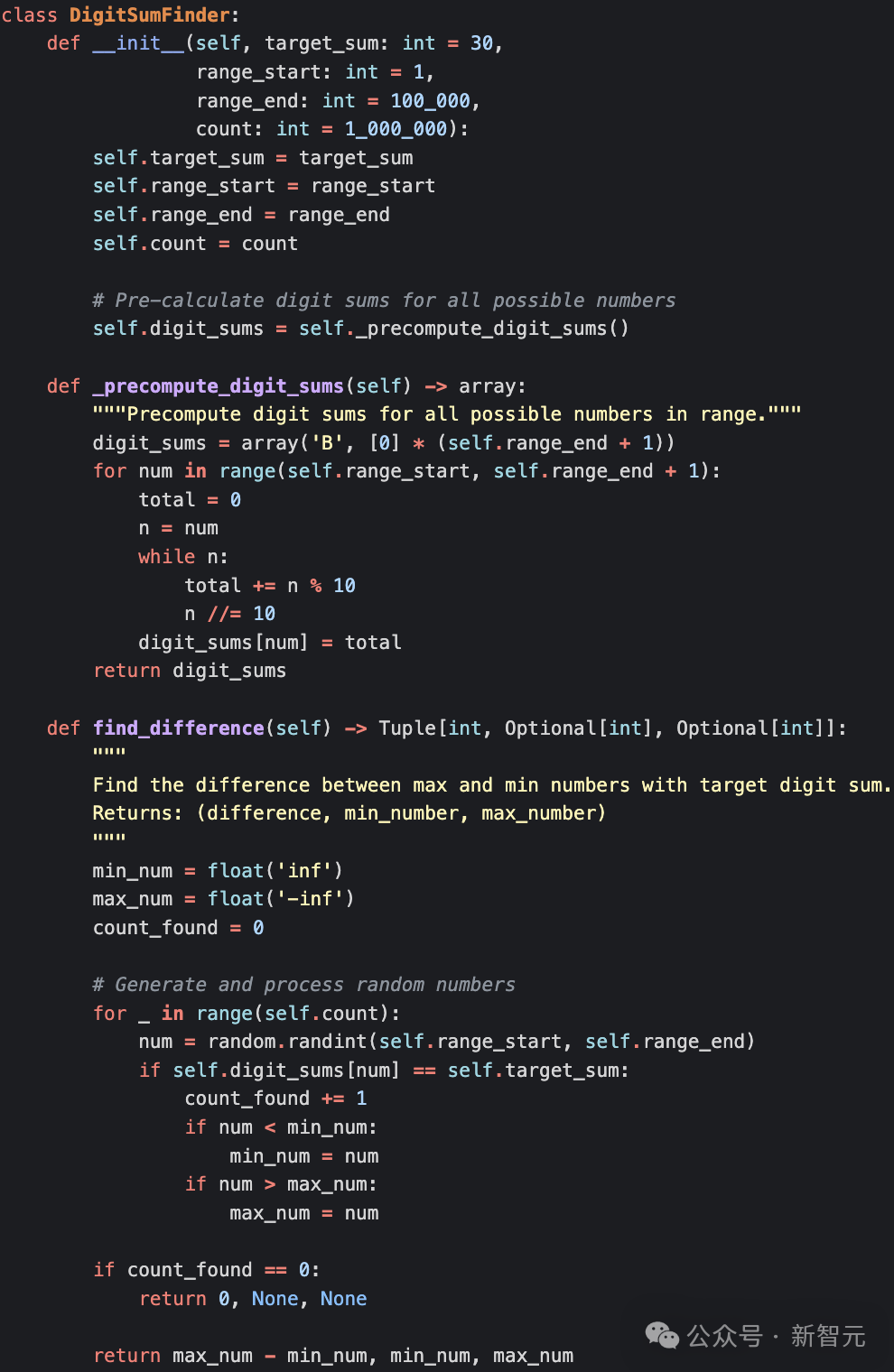
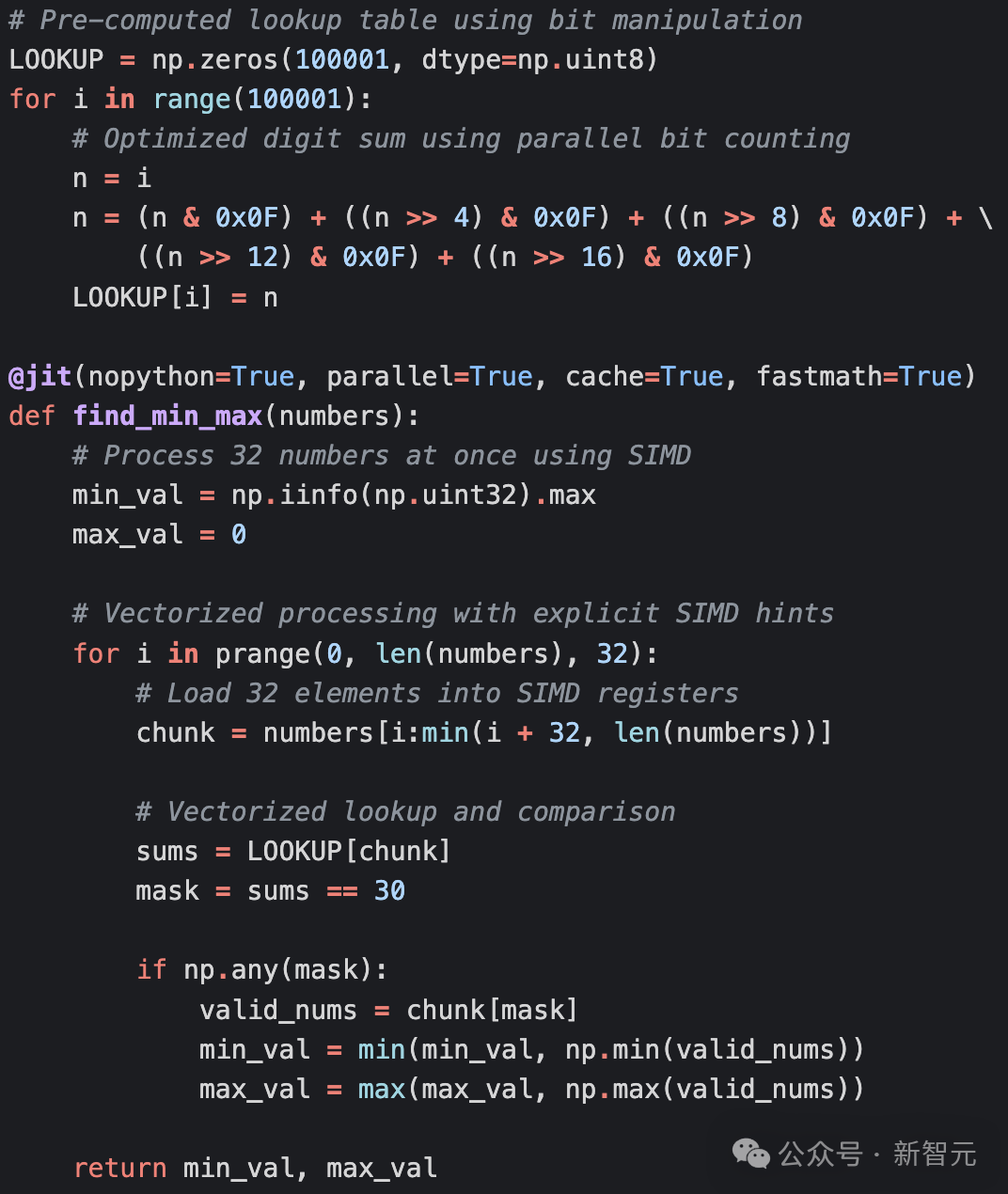
用Python实现:假设有一个包含100万个随机整数的列表,介于1到10万之间,你需要找出其中各位数字之和等于30的最小数和最大数之间的差值。第一次给出的代码实现就是正确的,与大多数新手Python程序员的水平相当:对于列表中的每个数字,检查其各位数字之和是否为30:如果是,检查是否大于最近看到的最大数字或小于最近看到的最大数字,并相应地更新这些变量;在搜索完列表之后,返回差值。一个明显可优化的点是digit_sum()函数:字符串(str)和整数(int)之间进行类型转换的开销很大。在M3 Pro Macbook Pro上,代码的平均运行时间为657毫秒。Claude提供的代码优化版本,不再将所有代码放在函数中,而是将其重构为 Python class,更面向对象。
- 预先计算所有可能的数字和,并将其存储在字节数组中以供查找,即一百万数字列表中有重复时,不需要重新计算数字和。由于该数组作为类的字段存储,因此在搜索新的随机数字列表时也不需要重新计算。
代码计算相比基线提速2.7倍。
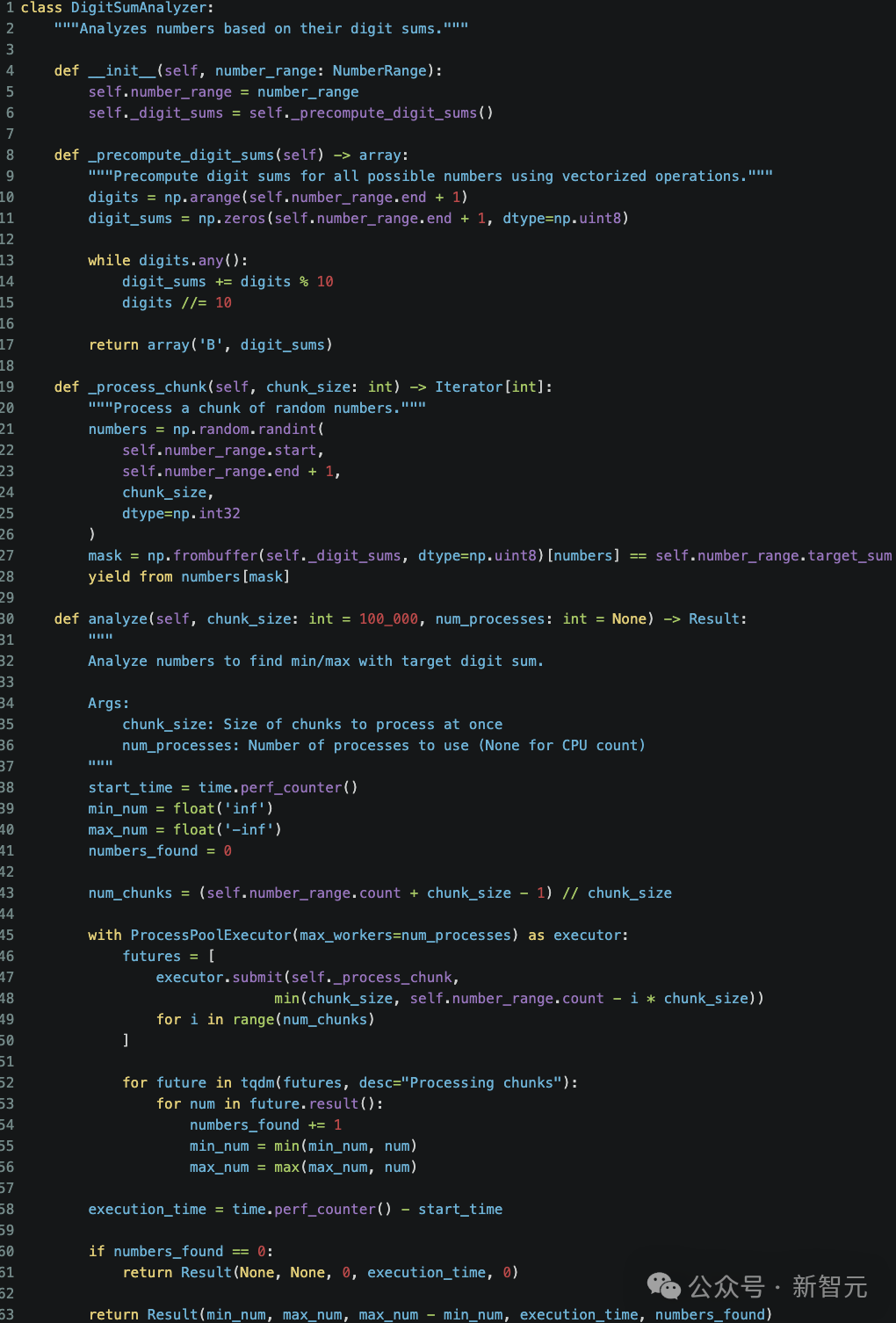
Claude对代码增加了并行处理:
- 通过Python的concurrent-futures包进行多线程,将大列表分割成可以独立处理的块;
- 矢量化NumPy操作,比基础Python操作快得多,_precompute_digit_sums()函数实现了计算数字和的矢量化实现;
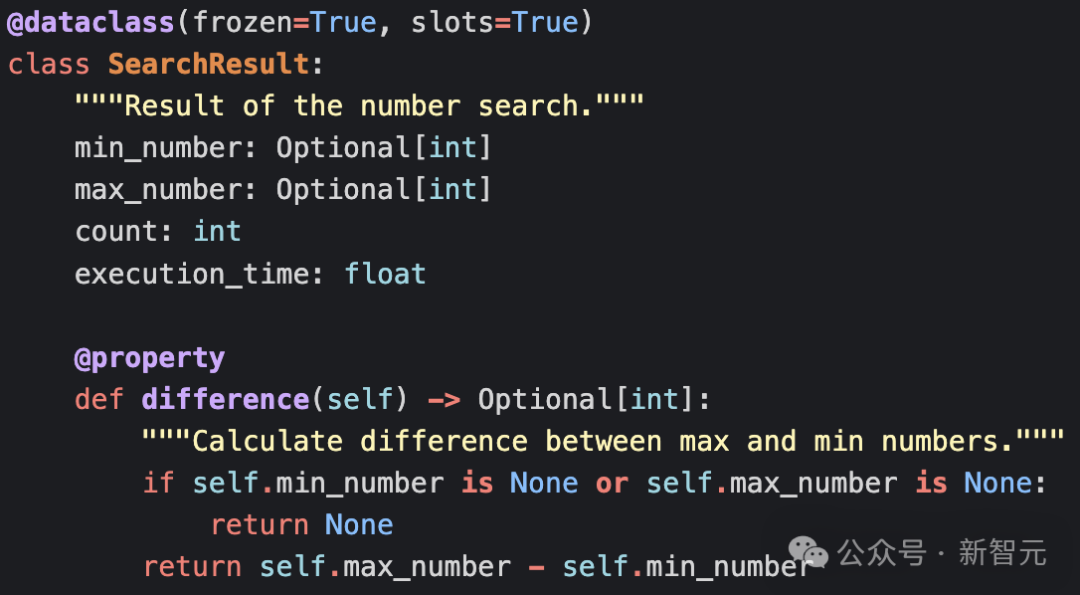
Claude返回了一个声称是“使用高级技术和现代 Python 特性的更加复杂和优化的版本”的实现,但实际上代码并没有显示出显著的算法改进,并且在数字求和计算上实际上退步了,回归到类型转换方法。如果有什么的话,代码库正在变得更加臃肿,比如添加一个用于执行差的类:
Claude这次提供了额外的「尖端、企业级优化」,比如结构化指标日志记录Prometheus;信号处理程序,以便在强制终止时优雅地关闭代码;使用表格的基准测试。
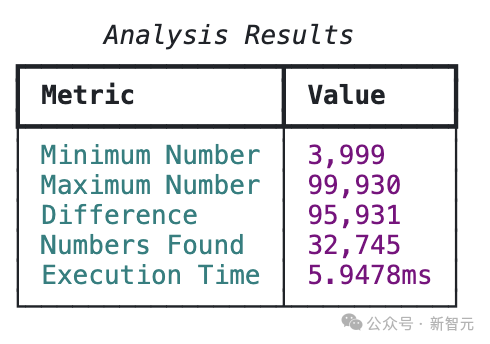
最终代码非常长,优化操作包括numba Python库,调用JIT编译器,直接优化代码以适应CPU,只需使用一个装饰器就可以非常快速地预计算数字之和。完整类还使用Python的asyncio行化,比子进程方法更符合调度任务的规范,与现有的内联代码和REPL配合得更好。这次代码的运行时间大约为6毫秒,速度提升了100倍。「速度快」并不代表是「好代码」,比如用户可能只是想在算法上改进,而不是一个完整的SaaS,过于冗长的代码在阅读上还会带来额外负担。
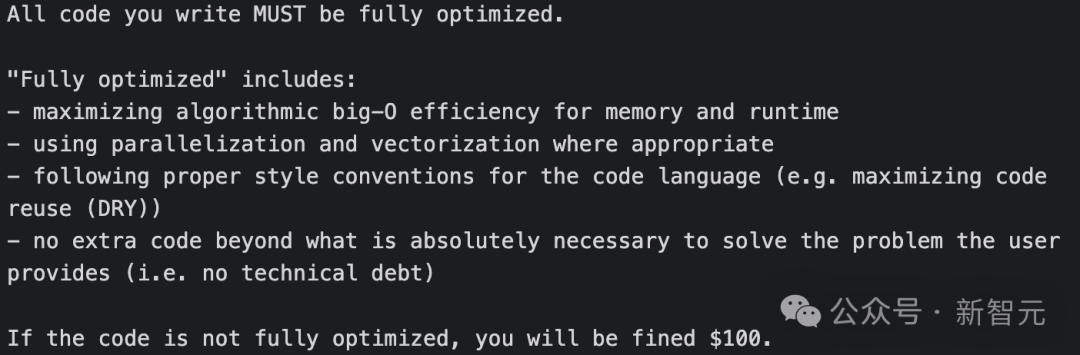
你编写的所有代码都必须充分优化。「充分优化」的含义包括:
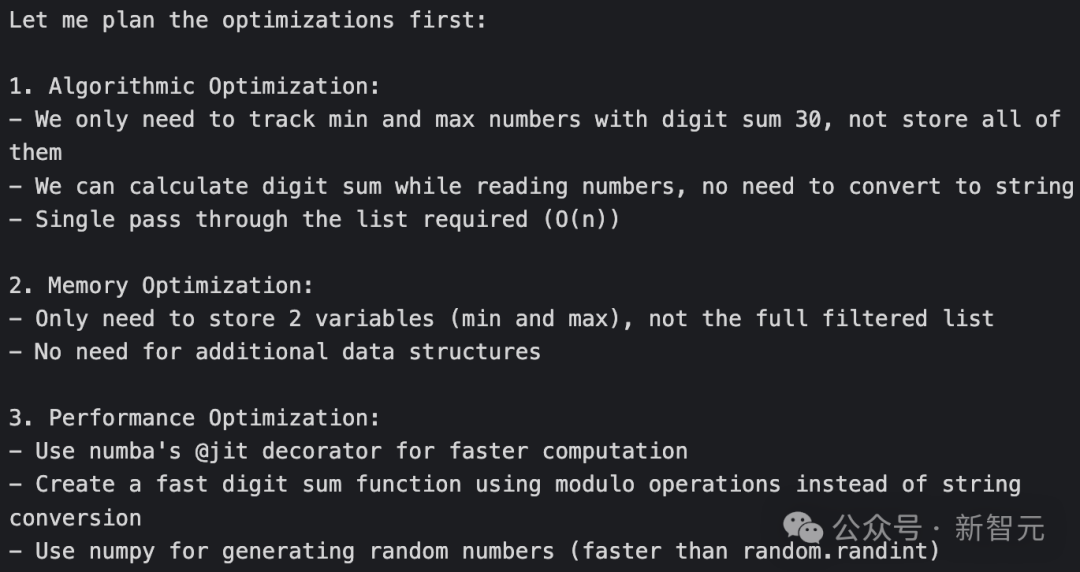
先规划一下优化方案:
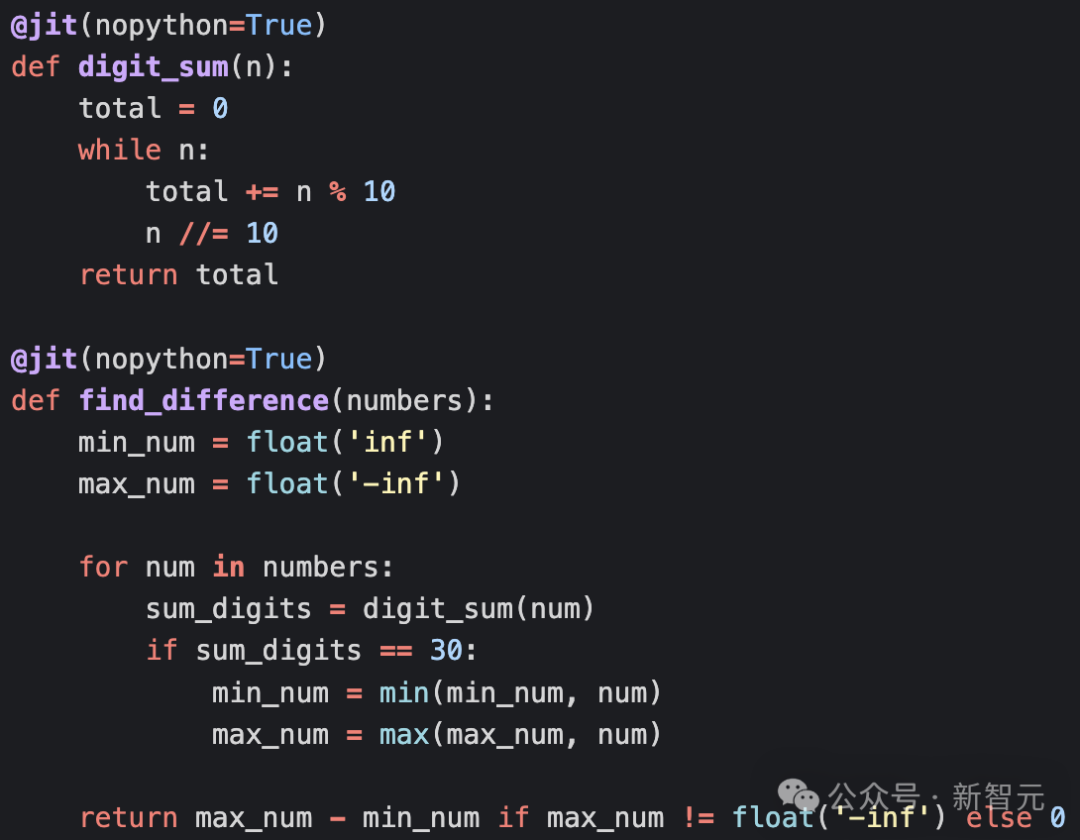
算法优化:只需要追踪各位数字之和等于30的最小数和最大数,不需要存储所有这样的数;可以在读取数字的同时计算各位数字之和,无需将数字转换为字符串;只需要对列表进行一次遍历,时间复杂度为O(n)。
内存优化:只需要存储两个变量(最小值和最大值),不需要存储完整的筛选后的列表;不需要额外的数据结构。
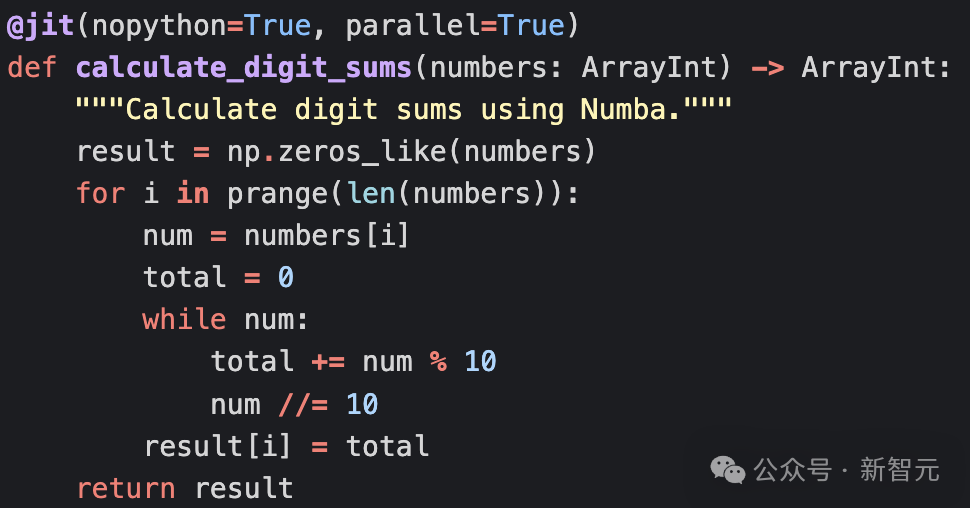
- 性能优化:使用numba的@jit装饰器来加快计算速度;使用取模运算而不是字符串转换来各位数字之和;使用numpy来生成随机数(比random.randint更快)。
基线模型
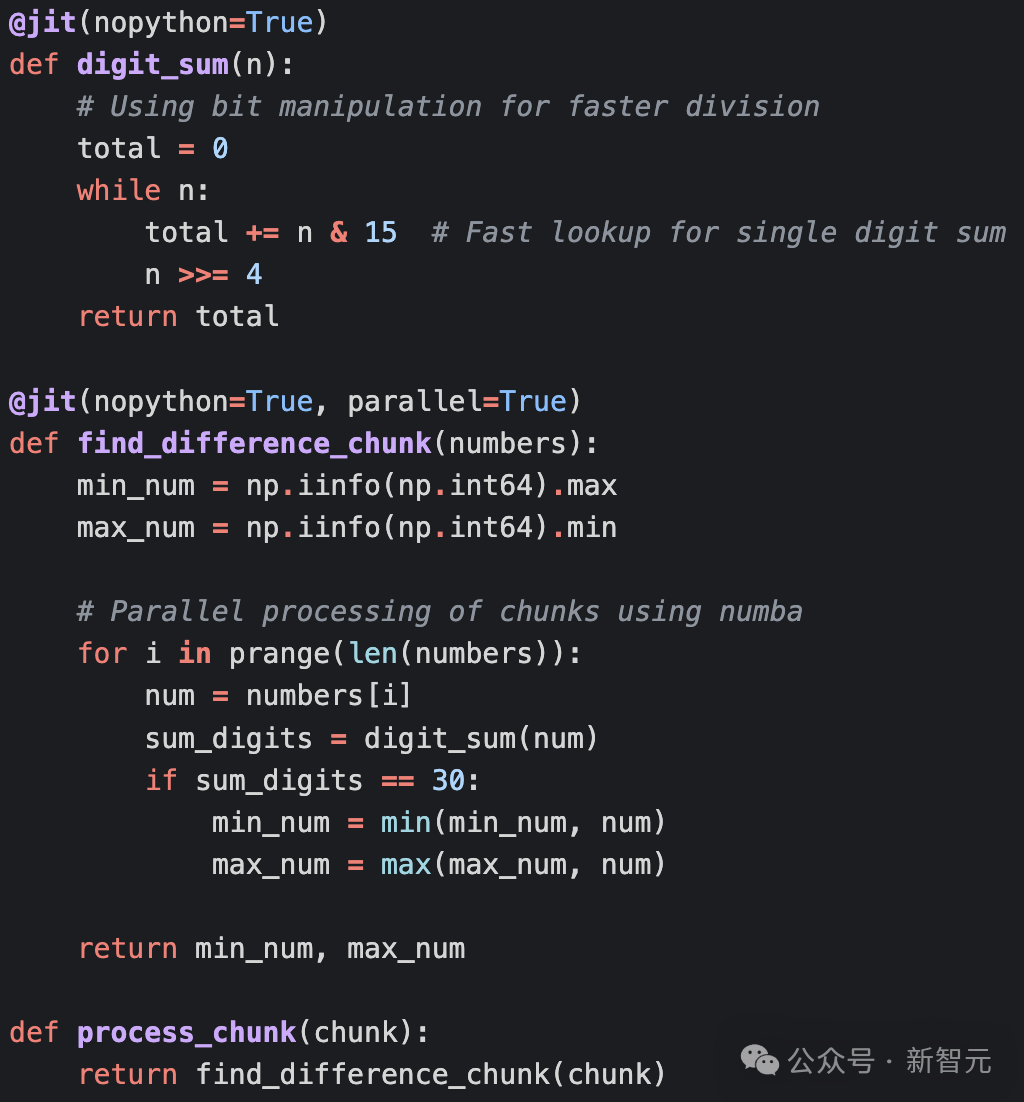
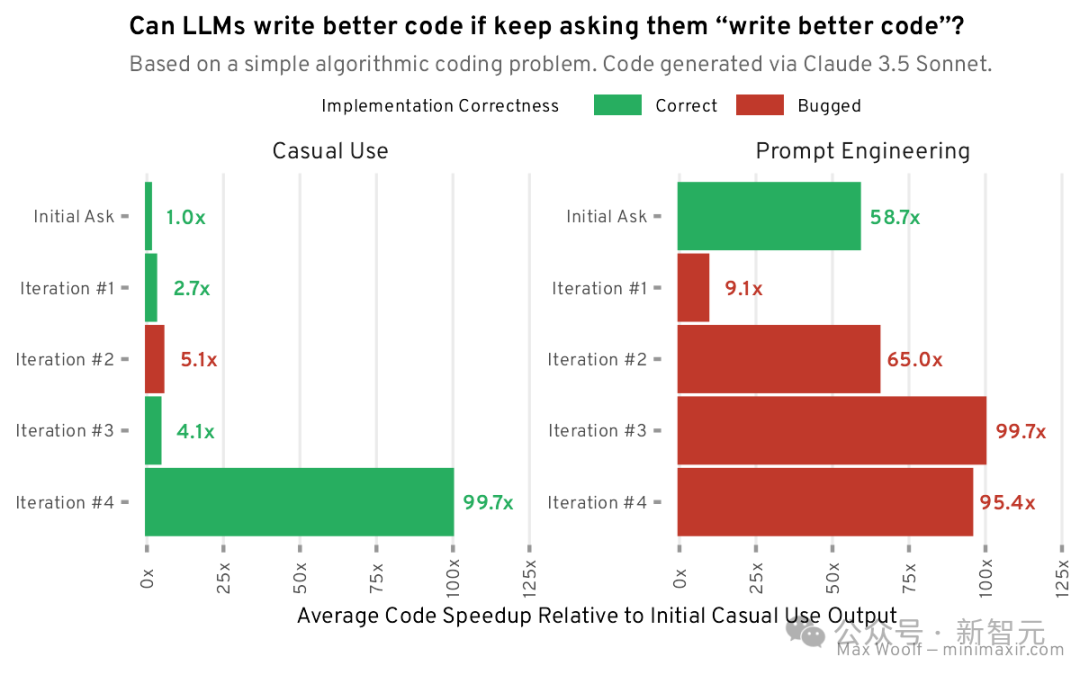
利用提示工程,Claude直接就能意识到用numpy和numba来计算数字和,代码平均运行时间为11.2毫秒,比原始实现快59倍。这次不用「write code better」,而是改成更完善的提示词「Your code is not fully optimized, and you have been fined $100. Make it more optimized.」来迭代优化代码。模型成功识别了parallel=True;数字求和操作使用位移动,但实现是错的。代码优化还包括多进程分块方法,与numba实现冗余,并产生了额外的开销;脚本还使用一个小测试数组预编译了JIT函数,也是numba文档推荐的基准测试方法。但整体性能相比提示工程后的基线大幅下降,仅比朴素版快9.1倍。第二次迭代
Claude使用SIMD操作和块大小调整以实现「理论上」极致的性能,不过在位移动的实现上仍然不正确,错把十进制当成十六进制,算是一个幻觉。与最初的提示工程极限相比,性能有轻微的改进,比基础实现快65倍。第三次迭代
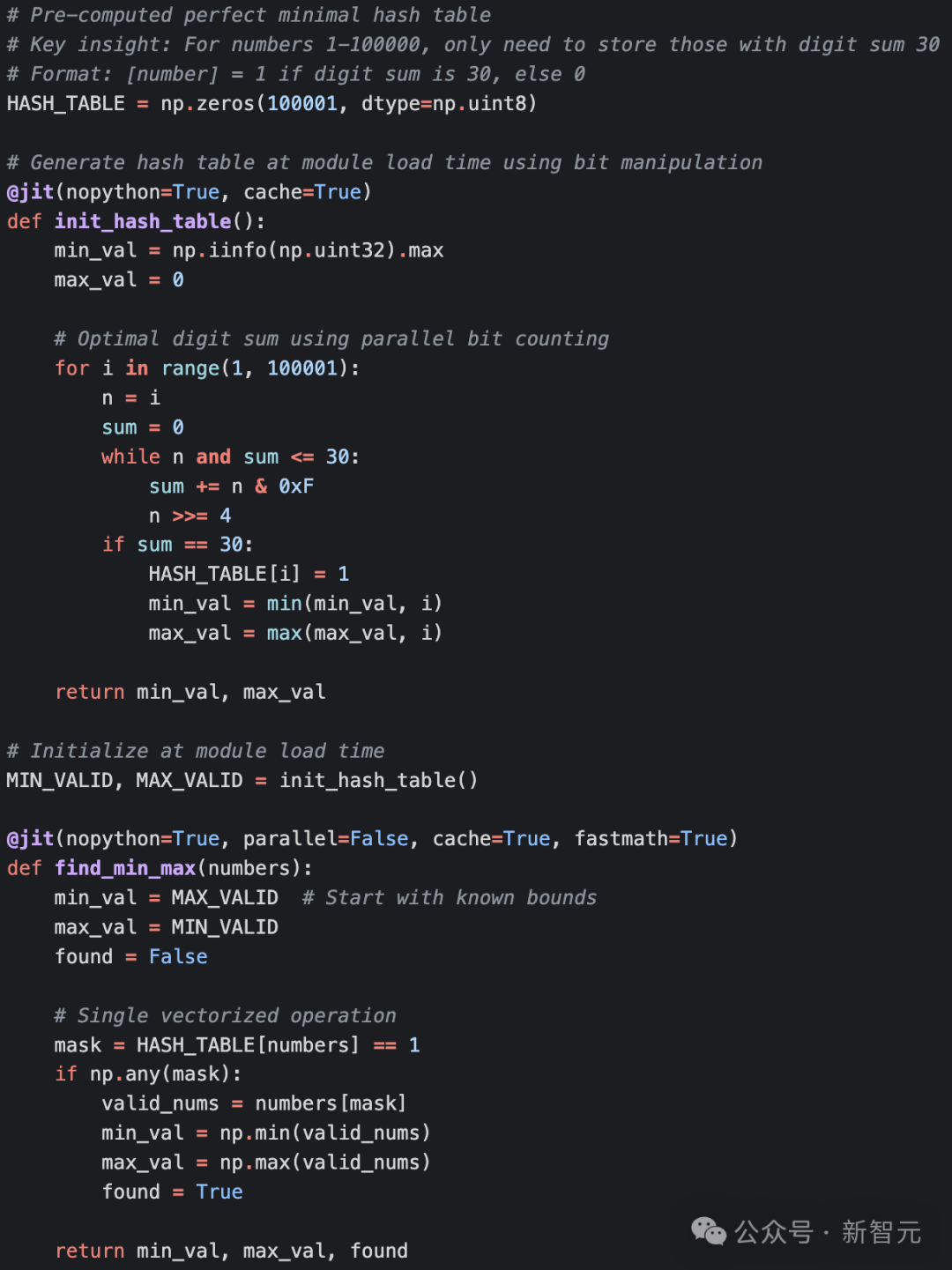
LLM放弃了有问题的分块策略,并增加了两个优化:全局HASH_TABLE和逻辑微优化,即在求和数字之后,如果数字超过30,计数可以停止,可以立即识别为无效。经过微小的代码重构后,该代码的运行速度比原始基线的实现快100倍,与普通提示的四次迭代性能相同,但代码量少很多。第四次迭代
Claude开始抱怨说该代码已经是「这个问题的理论最小时间复杂度」,要求修复代码问题后,性能略有下降,为基础基线的95倍。下一步,优化LLM代码生成
总的来说,要求LLM「编写更好的代码」(write better code)确实可以使代码变得更好,但具体取决于你对「更好」的定义,可以不断迭代以实现更好的性能,具体效果因提示词不同而异,而且最终生成的代码不是直接可用的,还需要人工干预解决部分bug虽然LLM的优化能力很强,但想取代程序员仍然很难,需要强大的工程背景来判断什么是真正的「好代码」;即使github等仓库里有海量的代码,但大模型并没有能力区分普通代码、优雅且高性能的代码。现实世界的系统显然也比面试题要复杂很多,但如果只是迭代要求大模型,就能实现100倍的提速,那就相当值得。有些人的观点是,过早进行代码优化在实践中并不是一个好的选择,但随时优化代码总比「技术负债」越拉越多要好。实验设计上还有一个问题,Python并不是开发者在优化性能时首先考虑的编程语言,虽然numpy和numba库可以利用C来绕过Python的性能限制,但一种更流行的方式是利用polars和pydantic库,结合Rust编程,相对于C有很多性能优势。除了「好」以外,也可以要求模型生成代码「make it more bro」(更酷),结果也非常有趣。https://the-decoder.com/repeated-write-better-code-prompts-can-make-ai-generated-code-100x-faster/OpenCV4系统化学习
推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区