

大模型加速上车,AI智能座舱竞争更显白热化。
诚然,在语言大模型为核心的多模态能力加持下,智能语音助理能够理解复杂的语言指令,实现知识问答、文本生成等,以及根据上下文进行逻辑推理,提供更智能、准确的回答,其水平成为了各OEM座舱差异化竞争的关键要素。
“2024年开始,车载语音助手的核心技术路径,已经慢慢转成大模型了;相对传统技术,大模型的核心优势之一就是理解能力、上下文关联的能力特别强。”云知声联合创始人、副总裁李霄寒表示。
很明显,座舱语音作为座舱娱乐和交互功能的重要入口,与大模型有着极高的契合度。尤其是自2022年底以ChatGPT为代表的大语言模型发布,国内外诸多玩家也在积极探索以大模型为基础的智能体(Agent)。
其中,云知声在2023年5月就发布了自研的山海大模型,交出了在AGI领域的第一张答卷。
彼时,其山海大模型的语言生成、语言理解、知识问答、逻辑推理、代码能力、数学能力、安全合规能力七项通用能力,及插件扩展、领域增强、企业定制三项行业落地能力已经处于业界前列。
在此基础上,云知声通过快速整合具体业务场景的相关知识与规范,已经打造了医疗病例生成Agent、交通客服Agent、智能座舱Agent等典型的行业Agent应用。
具体到智能座舱领域,云知声依托山海大模型重构了语音识别、语义理解、语音合成的全链路语音方案。基于大模型的理解与生成能力,其方案深度赋能用车、出游、主动关怀、健康、通用聊天等多个细分场景。
而自去年5月中旬,OpenAI推出GPT-4o,凭借突破性的智能交互能力,掀起了新一轮的多模态大模型新浪潮。与此同时,云知声也在突破更深层次的自然语言理解和多模态交互。
同年8月,云知声顺势推出了山海多模态大模型,通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出,带来实时多模态拟人交互体验,开启AGI新范式。
得益于过去几年不断补强的语音技术栈和大模型能力,搭载云知声语音解决方案的车型已经陆续量产,其客户包括吉利、上汽等。
这也意味着,云知声作为国产大模型的一道缩影,已经初步跑通了座舱语音大模型的技术、产品和商业化路径。

座舱语音加速迈向真人工智能
于用户而言,影响其座舱语音使用频率和体验感的因素包括两点:一是使用门槛要足够低,二是语音交互能做到真正的人工智能。
而站在语音供应商的角度,要想做到以上几点,技术层面的衡量标准,一定是“听得清”、“听得懂”并且“答得好”。
其中,“听得清”是整个座舱语音的基建。毕竟所有座舱语音交互功能的实现,前提条件一定是“听得清”。
但要想做好这一点,并非易事,必须做好座舱语音整体硬件结构设计、软件算法等,这非常考验语音技术栈基础能力,包括降噪、回声消除、音区分离等。
这也恰恰是云知声的强项所在。
例如,云知声打造的降噪解决方案,实际降噪后语音信噪比可达20db以上,实现了音区精确分离,可确保车内对话清晰;回声消除后的语音信回比提升达到 35dB以上;降噪后的蓝牙通话方案,MOS分可以达到4.0以上(最高5分)。

值得一提的是,目前云知声在降噪层面的技术逻辑,已经全部基于数据驱动的神经网络实现。在此基础上,其语音唤醒、语音识别等能力也明显更强。
据统计,在端到端唤醒时延数百次测试中,搭载云知声语音技术的语音助理,最快可达220ms以内;离线识别首字上屏速度小于600ms,在线识别首字上屏速度小于700ms。
另外,“听得懂”作为迄今为止语音座舱最大的挑战之一,有望在大模型的加持下,赋能整个座舱语音做到真正的人工智能。
即在语音技术栈基础之上,结合大模型,语音助理可以做到更快的语义响应速度、更准确的意图理解和上下文跨越理解等,是现阶段座舱语音互相角力的重点。
比如,在山海大模型的加持下,云知声的语音助理的语义平均响应时延达300ms,意图理解准确率达95%,可实现复杂上下文跨域理解、语义纠错等。
而在“听得清”和“听得懂”的技术前提下,“答得好”是用户衡量座舱语音智能化程度最重要的指标之一,其关键点在于以语音助理为交互入口,集成更多的服务,包括多媒体播放、实时导航、车控,以及故障灯释义、维修手册等。
“语音助理什么都能听得懂,即便能做到这一点,假如座舱交互提供的服务只有有限的几类,那用户问到第N +1类服务的时候,再聪明的助理也只能说‘对不起不支持’,在用户看来这个助理就是不智能的。”李霄寒介绍道。
All in大模型,赋能主机厂座舱语音产品领先
“2025云知声将All in大模型,所有的车载语音技术方案都用大模型来做,旨在通过新的技术路线,带来新的体验和价值,赋能客户的座舱语音产品上市发布时,在行业内是具备领先性的,这是我们的目标。”李霄寒谈到。
不难发现,占领新一轮座舱语音大模型的技术高地,是接下来OEM在智能座舱差异化方面的技术竞争焦点。
毕竟,现阶段的座舱语音交互,大多还是由语音、文本两套大模型系统组成。其整体交互链路和流程,首先由用户发起语音请求,车机麦克风拾音之后,再调用语音增强能力接口,对音频做回声消除、噪音抑制等预处理。
此后,预处理后的音频需进行识别转写,转写后的文本再通过文本大模型进行语义理解,并给出语义理解的结果,输出文本回复再转化为语音回复。
从应用层面来看,这也极大地影响着用户体验。
一方面,人机对话过程由语音转成文字,再做理解并输出结果,在时间上存在一定的延迟。
另外,语音转变成文字后,会丢失较多的信息,比如情绪信息。即用户分别用愤怒和心平气和的态度说同样的话,得到的回复可能是完全一样的,显然与语音助手追求“拟人”相悖。
“只有把语音和文本两个大模型合并,语音助手才能变成真正听得懂人话的助理,尤其是在做意图理解时,不光能理解文字,还能读懂声音里蕴含的情绪等其它信息,并做出差异化的回复,因此2025年语音大模型会成为主流。”李霄寒表示。
而借助山海大模型,云知声在语音识别、语义理解、语音合成等方面,均已采用大模型技术,实现了语境理解、情绪感知、反馈学习等核心交互能力的增强,赋能座舱体验在不断优化与提升。
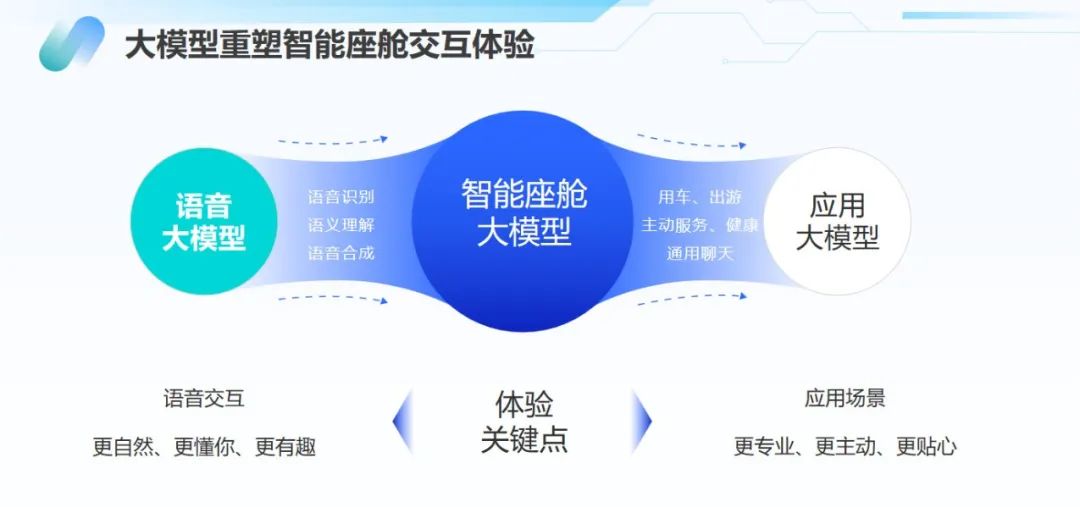
比如,在语义理解方面,意图理解大模型彻底解决了过往在意图分类、深度语义理解、多轮交互时的人机对话痛点,在影视问答、旅游推荐、娱乐闲聊、用车问答等高频6大领域准确率超过95%,且大模型语义平均响应时间为300ms。
另外,在语音合成方面,语音大模型支持情感化语音合成,用户可以选择自己喜爱的声音和人设,或者专属声音定制语音包,并支持多语种TTS合成,极大地提升了交互趣味性。
“以语音大模型为主的多模态大模型上车,到底要向用户提供哪些有价值的功能?这是值得供应商和OEM深思的问题,因为大模型上车一定要有价值,能够让用户容易使用,并且愿意使用。”李霄寒向高工智能汽车提到。
站在用户和OEM的角度思考座舱语音产品定位,坚定All in大模型的云知声,在业务层面也有了更清晰的规划。
据介绍,一方面云知声将提供完整的语音座舱解决方案,覆盖降噪、唤醒、识别、理解、语音合成,以及各类开发平台,云端、端侧的功能等;另一方面,针对语音座舱设计比较完善的客户,将以组件的方式提供服务,比如降噪、语音合成等可单独提供模块。
另外,云知声还将继续贴近OEM客户,包括驻厂提供更好、更快的座舱语音服务等,旨在成就客户座舱语音产品具备至少三个月的领先性。
决胜2025年座舱语音交互,云知声及其大模型的实际表现值得期待。


