

关注+星标公众号,不错过精彩内容

来源 | 网络
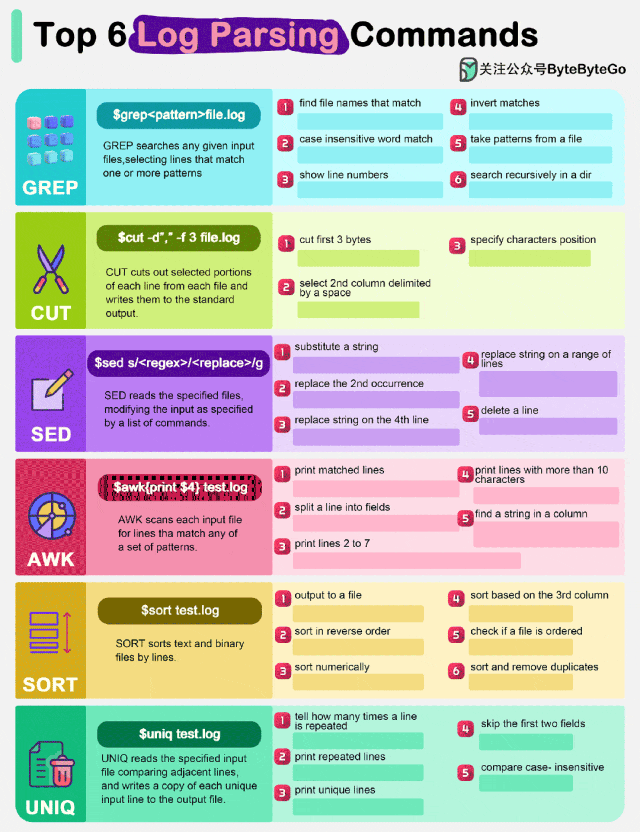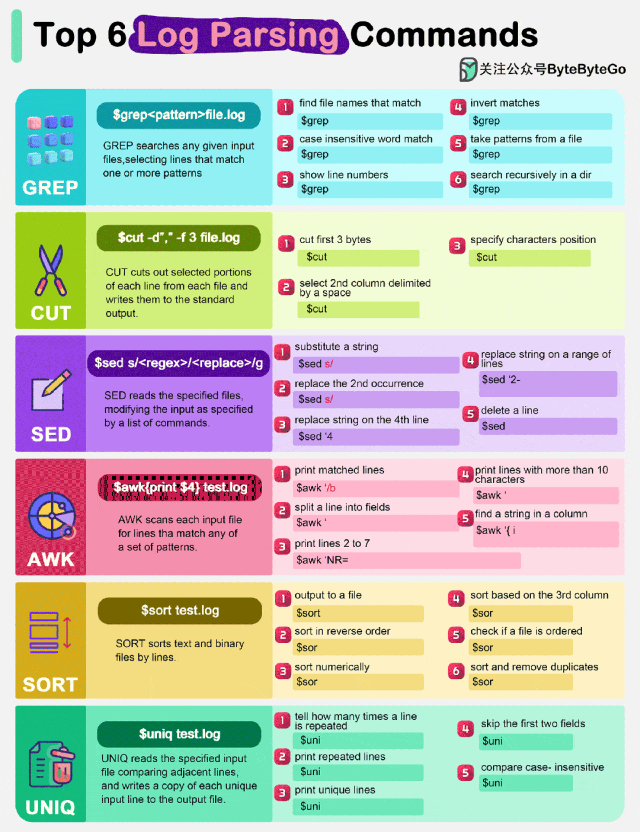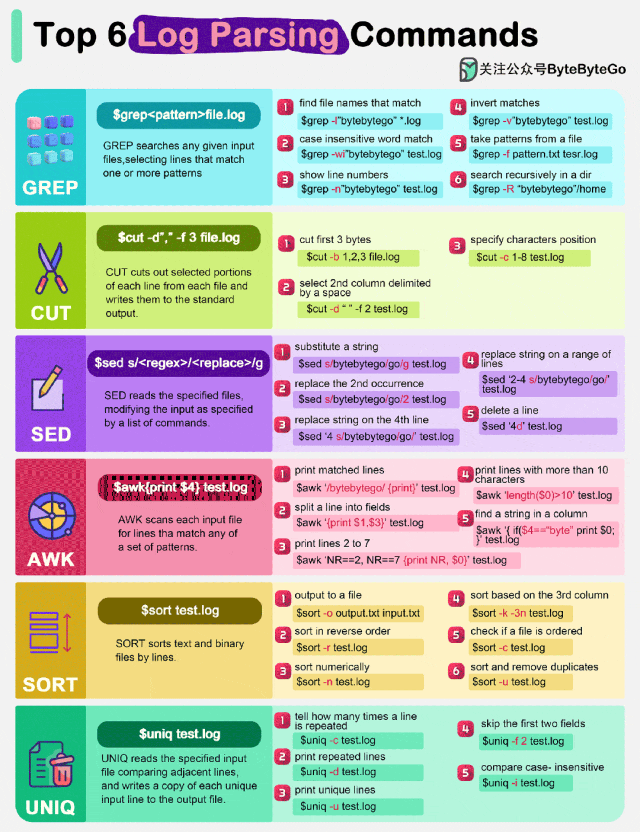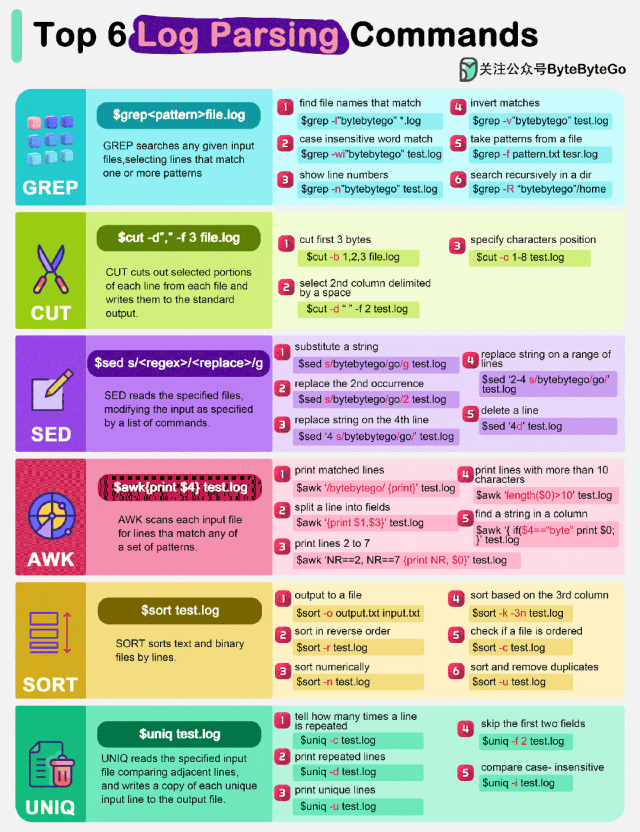
GREP 是一个强大的文本搜索工具,用于在给定的输入文件中查找与一个或多个模式匹配的行。它支持正则表达式,使得搜索更加灵活和强大。例如,grep 'pattern' filename 会在 filename 中查找包含 pattern 的所有行。
CUT 命令用于从每个文件中的每一行中提取特定的部分,并将其写入标准输出。它通常用于从结构化的文本文件中提取数据。例如,cut -d ' ' -f 8 filename 会从 filename 中提取每行的第 8 个字段,其中 -d ' ' 指定了字段分隔符为空格。
SED(流编辑器)是一种文本处理工具,用于读取指定文件并根据命令列表对输入进行修改。它可以执行各种文本操作,如替换、插入、删除等。例如,sed 's/old/new/g' filename 会将 filename 中的所有 old 替换为 new。
AWK 是一种强大的文本处理语言,用于扫描每个输入文件并查找与一组模式匹配的行。它支持复杂的文本处理和数据分析。例如,awk '{print $1}' filename 会打印 filename 中每行的第一个字段。
SORT 命令用于对文本和二进制文件的行进行排序。它可以根据不同的键和排序规则进行排序。例如,sort -k 1,1 filename 会根据第一列对 filename 进行排序。
UNIQ 命令用于读取指定的输入文件,比较相邻行,并将每个唯一输入行的副本写入输出文件。它通常与 sort 命令一起使用,以确保输入是有序的。例如,uniq -c filename 会统计 filename 中每行的出现次数,并在每行前面加上计数。
假设我们有一个日志文件 access.log,其格式如下:
216.67.1.91 - leon [01/Jul/2002:12:11:52 +0000] "GET /index.html HTTP/1.1" 200 431
我们需要找到访问路径 /api/payments 的前 10 个 IP 地址。可以使用以下命令组合来实现:
grep '/api/payments' access.log | cut -d ' ' -f 1 | sort | uniq -c | sort -rn | head -10
各部分的作用解释:
grep '/api/payments' access.log
cut -d ' ' -f 1
sort
uniq -c
sort -rn
head -10
通过这些命令的组合,我们可以高效地从日志文件中提取所需的信息。
声明:本文部分素材来源网络,版权归原作者所有。如涉及作品版权问题,请与我联系删除。
------------ END ------------

●专栏《嵌入式工具》
●专栏《嵌入式开发》
●专栏《Keil教程》
●嵌入式专栏精选教程
关注公众号回复“加群”按规则加入技术交流群,回复“1024”查看更多内容。
