


OpenAI 最近推出了其新的推理模型 o3,该模型在 ARC 数据集上大幅超越了之前的最佳性能(SOTA),并在具有挑战性的 FrontierMath 数据集上取得了令人惊叹的结果。很明显,该模型在推理能力方面是一个重要的进步。
然而,最近关于人工智能进展停滞的报道中包含了一种对进展速度的悲观情绪。许多人可能仍然在思考大型语言模型(LLM)扩展法则,这些法则预测计算、数据和模型大小的增加将导致更好的模型,是否已经“遇到了瓶颈”。我们是否达到了基于变换器的 LLMs 当前范式的可扩展性极限?
除了首次公开发布的推理模型(OpenAI 的 o1、Google 的 Gemini 2.0 Flash,以及即将在 2025 年发布的 o3)之外,大多数模型提供商似乎都在进行表面上看似渐进式的现有模型改进。从这个意义上说,2024 年基本上是一年的发展巩固,许多模型在本质上已经赶上了年初的主流模型 GPT-4。
但这掩盖了像 GPT-4o、Sonnet 3.5、Llama 3 等“主力”模型(即非推理模型)所取得的实际进展,这些模型在 AI 应用中最为频繁。大型实验室一直在推出这些模型的新版本,这些新版本在各个任务上都推动了 SOTA 性能,并且在编程和解决数学问题等任务上带来了巨大的改进。
不可忽视的是,2024 年模型性能的改进主要是由训练后和测试时计算的扩展所驱动的。在预训练方面,新闻并不多。这导致了一些猜测,即(预训练)扩展法则正在崩溃,我们已经达到了当前模型、数据和计算所能达到的极限。
在这篇文章中,将回顾 LLM 扩展法则的历史,并分享对未来方向的看法。从外部预测大型 AI 实验室的进展是困难的。对 2025 年 LLM 扩展可能如何继续的总结:
预训练:有限 - 计算扩展正在进行中,但我们可能受限于足够规模的新高质量数据;
训练后:更有可能 - 合成数据的使用已被证明非常有效,这可能会继续下去;
推理时:也很有可能 - OpenAI 和 Google/Deepmind 在今年开始了这一趋势,其他参与者将跟进;同时,注意开源复制;在应用层面,我们将看到越来越多的代理产品。
什么是 LLM 扩展法则?
在深入探讨之前,什么是 LLM 扩展法则?简而言之:它们是关于规模(以计算、模型大小和数据集大小衡量)与模型性能之间相关性的经验观察。
有了这个背景,让我们看看我们目前的位置以及我们是如何走到这一步的。
计算最优的预训练 - Kaplan 和 Chinchilla
最初的扩展法则指的是 LLMs 的预训练阶段。Kaplan 扩展法则(OpenAI,2020)建议,随着、预训练计算预算增加,应该更多地扩展模型大小而不是数据。这意味着:给定 10 倍的训练预算增加,应该将模型大小扩展 5.5 倍,数据扩展 1.8 倍。
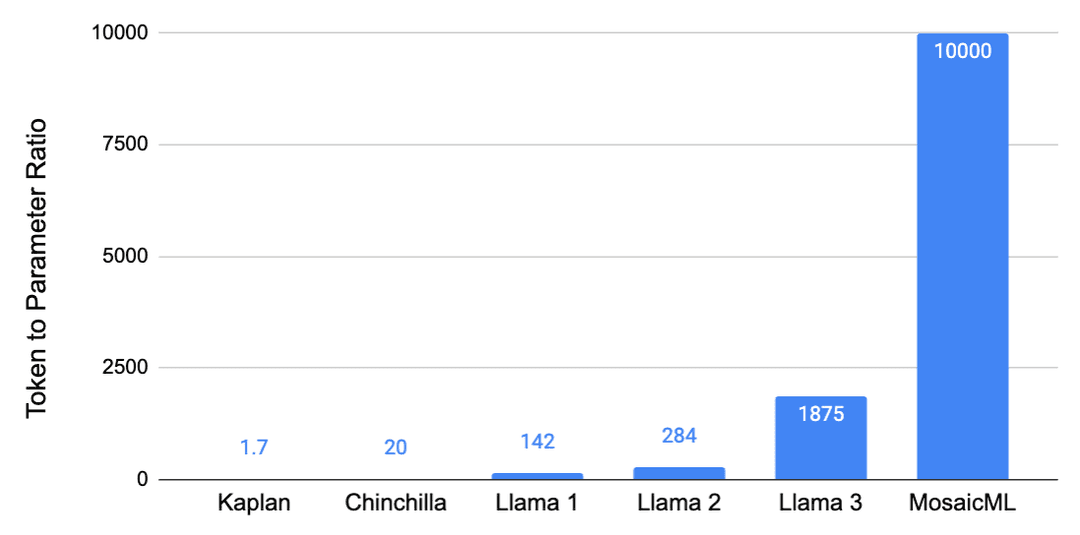
2020 年由 OpenAI 发布的 GPT-3,很可能遵循了这些扩展法则,并且在给定其大小的情况下,训练数据量异常少。也就是说,它有 1750 亿参数,但仅在 3000 亿token上进行了训练,这相当于大约 1.7 个token/参数。
这些原始扩展法则存在一些缺陷,例如没有考虑嵌入参数,并且通常使用相对较小的模型来估计扩展法则,这并不一定适用于大型模型。Chinchilla 扩展法则(Deepmind,2022)纠正了一些这些缺陷,并得出了非常不同的结论。
特别是,数据的重要性比以前认为的要大得多,因此模型大小和数据应该与计算同等比例地扩展。这些新发现表明,像 GPT-3 和当时发布的其他模型实际上是严重欠拟合的。一个像 GPT-3 这样的 1750 亿参数的模型应该在大约 3.5T token上进行训练才能达到计算最优,这大约是 20 个token/参数。或者,通过反向论证,像 GPT-3 这样的模型应该小 20 倍,即只有 150 亿参数。
Chinchilla 陷阱:优化推理
仅仅遵循 Chinchilla 扩展法则会导致“Chinchilla 陷阱”,即你最终会得到一个太大、因此在大规模推理时运行成本过高的模型。例如,在 Touvron 等人(Meta,2023)的 Llama 1 论文中,指出损失在 Chinchilla 最优之后继续下降。Llama 1 模型以高达 142 个token/参数的比例进行训练,这是最小的(70 亿)模型,训练在 1T 标记上。这一趋势继续出现在 Llama 2(Meta,2023)中,token翻倍至 2T,导致高达 284 个token/参数的比例。最后,也在 Llama 3(Meta,2024)中出现,比例高达 1,875 个token/参数(80 亿模型在 15T tokne上训练)。训练这些小型模型更长时间使它们达到出人意料地高性能,且在推理时运行成本较低。
这种证据不仅来自 Llama 3 模型训练在极高的token参数比例上,而且来自文献。例如,Sardana 等人(MosaicML,2023)估计了考虑推理时计算的扩展法则。在他们的实验中,他们训练了高达 10,000 个token/参数 的模型比例,并发现损失在 Chinchilla 最优之后继续下降。这些图表很好地说明了训练小型模型更长时间的点,以及如何导致如果预期有足够高的推理需求,总成本更低。
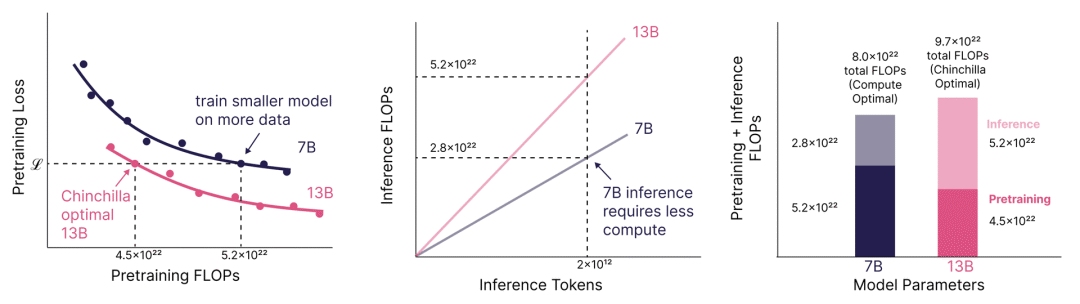
Sardana et al. (2023)
测试时间计算扩展
不用说,随着数据和参数越来越多地训练模型,计算成本越来越高。在 Llama 3 论文中,旗舰模型的训练使用了 3.8×10^25 FLOPs,这是 Llama 2 的 50 倍。根据 EpochAI,截至 2024 年 12 月,已知的最大训练预算是在 Gemini Ultra 的情况下,为 5×10^25 FLOPs。计算量非常大,尤其是如果考虑将其扩大几个数量级的话。
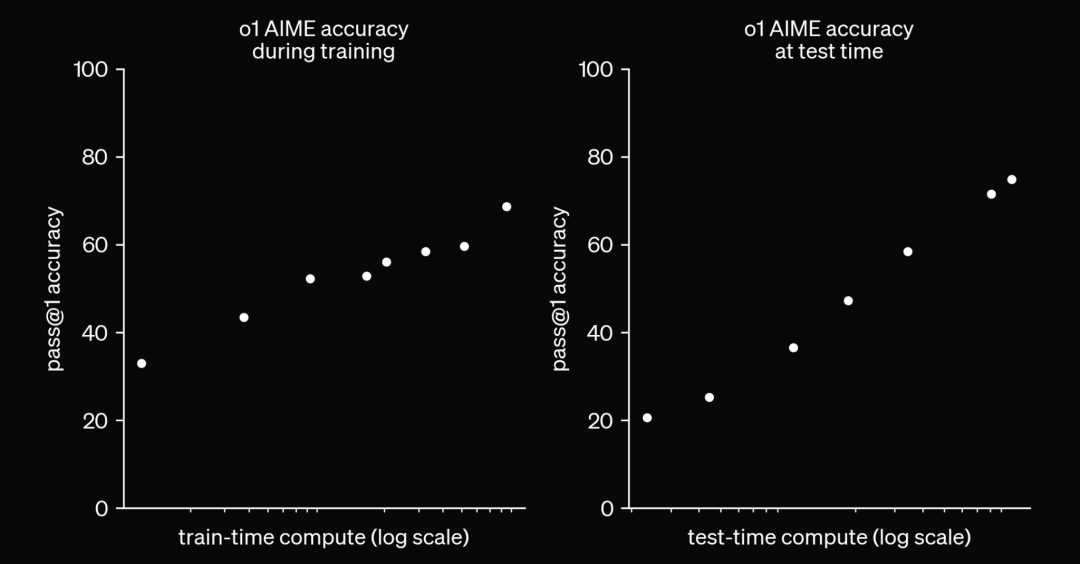
OpenAI 2024
作为回应,2024 年发布了像 OpenAI 的 o1 和最近的 o3 这样的模型,这些模型利用测试时计算来生成预测。所以,这些模型不是立即生成答案,而是在测试时生成思维链,或使用 RL 技术来生成更好的答案。通俗地说,可以说我们给了模型更多时间来“思考”再给出答案。这催生了一种完全不同的 LLM 扩展法则,即测试时计算。
推荐听听 OpenAI 的 Noam Brown 的有趣演讲,他谈到了他在训练用于玩扑克、国际象棋、Hex 等游戏的模型时学到的经验,以及测试时计算如何使 SOTA 性能成为可能,这些性能仅通过扩展训练计算是无法实现的。
例如,如果存在训练和推理时间计算之间的权衡,即可以用 10 倍的训练预算换取 15 倍的推理时间计算增加,那么在训练计算已经非常昂贵而推理计算非常便宜的情况下,这样做是有意义的。
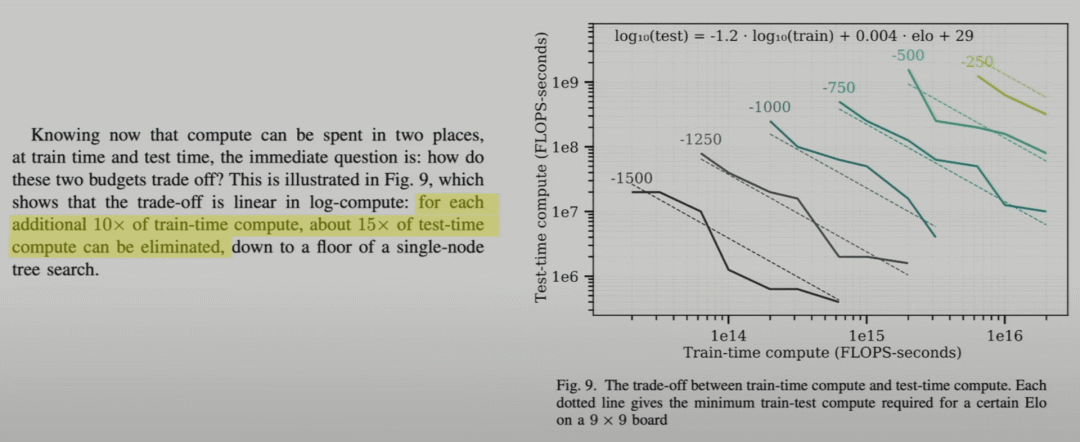
Jones (2021)
扩展法则是否仍然有效,还是我们已经遇到了瓶颈?
这是个大问题,从大型实验室外部很难回答。让我们回顾一下他们内部的说法,同时要意识到他们的陈述可能存在一些偏见。
Anthropic 的 Dario Amodei 表示:“我见过这种情况发生很多次,真的相信扩展可能会继续,而且其中有一些我们还没有在理论上解释清楚的魔力。”
OpenAI 的 Sam Altman 则表示:“没有遇到瓶颈。”
此外,公司仍在扩大他们的数据中心,xAI 的 Colossus 集群托管了 10 万个 H100 节点,并计划将其扩展到至少 100 万个。
尽管在扩展计算能力时存在工程挑战和能源瓶颈,但这一过程正在进行中。然而,计算能力只是 LLM 扩展法则中的一个因素,另外两个因素是模型大小和数据。有了更大的集群,也可以在给定时间内训练更大的模型。不过,数据的扩展则是另一回事。
EpochAI 估计,在索引的网络中有 510T 个token的数据可用,而已知的最大数据集是大约 18T 个token(Qwen2.5)。看起来似乎还有很大的空间可以扩展数据,但其中大部分数据质量较低或重复。再加上从 1-2 年前开始,互联网上新增的大量文本是由 LLM 生成的。尽管还有可能的新数据源可用,例如转录互联网上的所有视频,或者使用不在开放互联网上的文本(例如专有数据),但低垂的果实已经被采摘了。
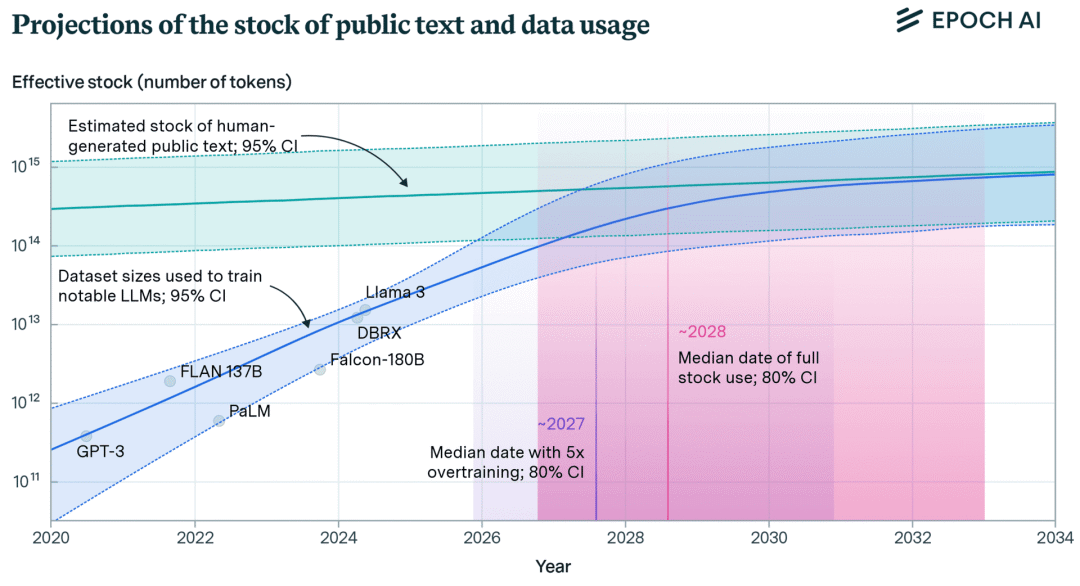
EpochAI
扩展的边际效益递减实际上正是幂律关系所预期的。也就是说,为了获得第一单位的改进,需要 1 单位的数据,然后是 10 单位用于下一个改进,接着是 100 单位,以此类推。正如 Yann LeCun 所说,这适用于所有“长尾”领域,即随着数据集大小的增加,输入的多样性不断增长的领域,如对话和问答。
从扩展法则的方程式和图表来看,应该清楚地认识到这些关系是有极限的,这一点也得到了 Kaplan 原始论文[3]的认可。原因在于自然语言中固有的熵,以及损失无法降低到零。因此,虽然目前看来性能似乎只是随着计算、数据、模型大小的对数线性增长,但最终它必须趋于平稳。问题不在于是否会趋于平稳,而在于何时会发生。
我们现在已经达到了这个点了吗?很难回答,因为这不仅仅是简单地将计算或数据再扩展一个数量级并看看会发生什么。AI 实验室正在构建大型的新集群,这将使他们能够更长时间地训练模型,并观察损失是否继续以相同的速度减少。据我们所知,我们还没有在 10 万个 H100 节点上训练这些模型,更不用说 100 万个了,所以很难判断我们还能将训练损失降低多少。更重要的是,我们只有一个互联网,所以扩展数据是一个更困难的问题。正如我们从 Kaplan 扩展法则中知道的,只有当模型不受这些因素之一的限制时,这些法则才成立。

Ilya Sutskever在NeurIPS 2024
然而,鉴于那些利用测试时计算的模型所表现出的令人印象深刻的表现,以及OpenAI 的 o3 的发布,很明显,扩展测试时计算是未来的发展趋势。
如下面的图表所示,当扩展测试时计算时,在具有挑战性的 Arc 数据集上的性能提升是相当显著的。从 o3 low到 o3 high,模型被赋予了 172 倍更多的计算资源来生成答案。它平均每道题使用 5700 万个token,相当于 13.8 分钟的运行时间,而在低计算设置中,它每道题仅使用 33 万个token,即每道题 1.3 分钟。
根据 Noam Brown 的说法,这只是开始。明年,我们可能会让模型运行数小时、数天甚至数周来回答真正具有挑战性的问题。
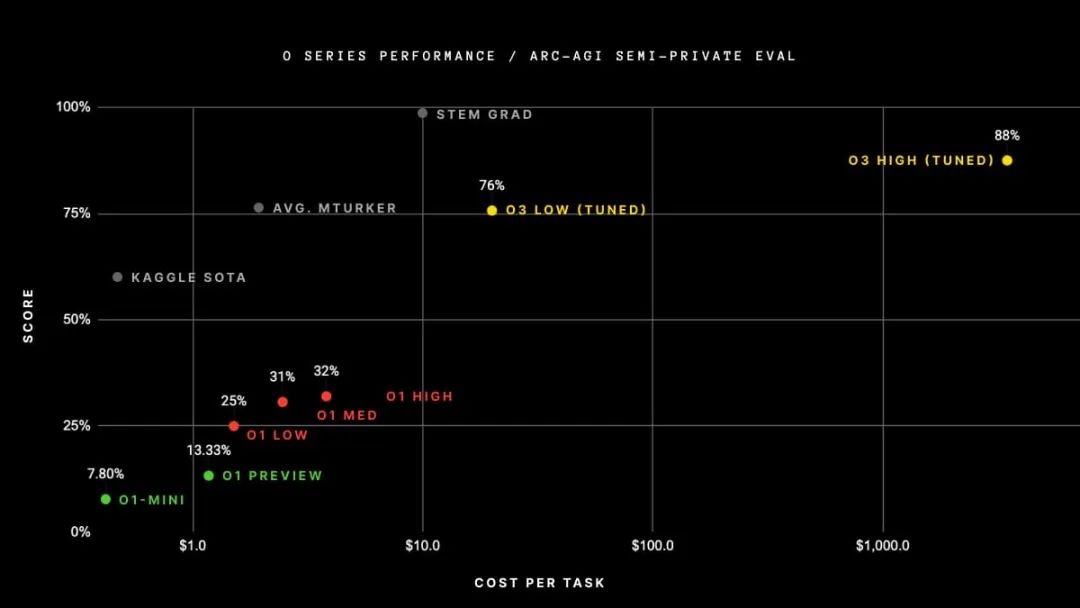
Arc Prize网站
结论
鉴于目前的发展势头和硬件部署情况,人们将会尝试通过投入更多的计算资源来进一步推动扩展法则。这可能是在训练方面,通过延长预训练时间或在训练后投入更多资源,但尤其在推理方面,通过让模型“思考”更长时间后再给出答案。
公众可能并不总是能够接触到最大的模型,这些模型可能性能最佳,但运行成本过高。像 GPT4o 或 Sonnet 3.5 这样的模型,可能更适合用于推理的小型模型。而拥有 4050 亿参数的 Llama 3 模型,虽然相当庞大,但可以作为小型模型的优秀教师模型,或者用于生成合成数据。
今年的趋势,肯定会延续到 2025 年(在一年的这个时间点上,这是一个容易做出的预测):
代理(Agents)
测试时计算(Test-time compute)
合成数据(Synthetic data)
代理实际上也是测试时计算的一种方式,但这种方式比大型实验室更易于公众和应用开发者接触。尽管如此,大型实验室也在大力投资代理技术。
测试时计算是关键。正如我们在 o1 Gemini 2.0 Flash 和 o3 中所看到的,这些将是解决需要更复杂推理的用例,或者在需要权衡一些训练计算以换取更多推理计算的情况下的解决方案。
至于合成数据,它主要用于训练后,但也可以将清理互联网视为一种合成数据生成的方式。从今年的 LLM 论文中可以看出,合成数据对于 SFT 在数学和编程等任务上的性能提升非常重要。在某些领域,合成数据比其他领域更有用,所以不确定它是否真的能够填补人类撰写数据缺失的空白。
因此,本文的结论是,我们可能已经达到了一个点,即预训练扩展法则并没有完全崩溃,但可能正在放缓,这并不令人惊讶。这主要是因为我们已经耗尽了大量高质量文本的来源。
然而,这并不意味着该领域不会再有任何进展,因为预训练只是拼图的一部分。正如我们所见,扩展测试时计算和使用合成数据,很可能是未来进展的主要驱动力。至少到目前为止,我们可能只是处于测试时扩展法则的早期阶段,所以还有很大的改进空间。
总之,这是我们看到的 2025 年 LLM 扩展最具潜力的方向:
预训练:有限 - 计算扩展正在进行中,但我们可能受限于足够规模的新高质量数据;
训练后:更有可能 - 合成数据的使用已被证明非常有效,这可能会继续下去;
推理时:也很有可能 - OpenAI 和 Google/Deepmind 在今年开始了这一趋势,其他参与者将跟进;同时,注意开源复制;在应用层面,我们将看到越来越多的代理产品。
参考文献:
[1] T. Brown et al. Language Models are Few-Shot Learners, 2020.[paper]
[2] J. Hoffmann et al. Training Compute-Optimal Large Language Models, 2022.[paper]
[3] J. Kaplan et al. Scaling Laws for Neural Language Models, 2020.[paper]
[4] H. Touvron et al. LLaMA: Open and Efficient Foundation Language Models, 2023.[paper]
[5] H. Touvron et al. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023.[paper]
[6] Llama Team, AI @ Meta. The Llama 3 Herd of Models, 2024.[paper]
[7] N. Sardana et al. Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws, 2024.
原文链接:https://www.jonvet.com/blog/llm-scaling-in-2025
高端微信群介绍 | |
创业投资群 | AI、IOT、芯片创始人、投资人、分析师、券商 |
闪存群 | 覆盖5000多位全球华人闪存、存储芯片精英 |
云计算群 | 全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
AI芯片群 | 讨论AI芯片和GPU、FPGA、CPU异构计算 |
5G群 | 物联网、5G芯片讨论 |
第三代半导体群 | 氮化镓、碳化硅等化合物半导体讨论 |
存储芯片群 | DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
汽车电子群 | MCU、电源、传感器等汽车电子讨论 |
光电器件群 | 光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
渠道群 | 存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代

