 点击上方蓝字关注我们
点击上方蓝字关注我们
微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
思想核心
Visual Transformer的结构
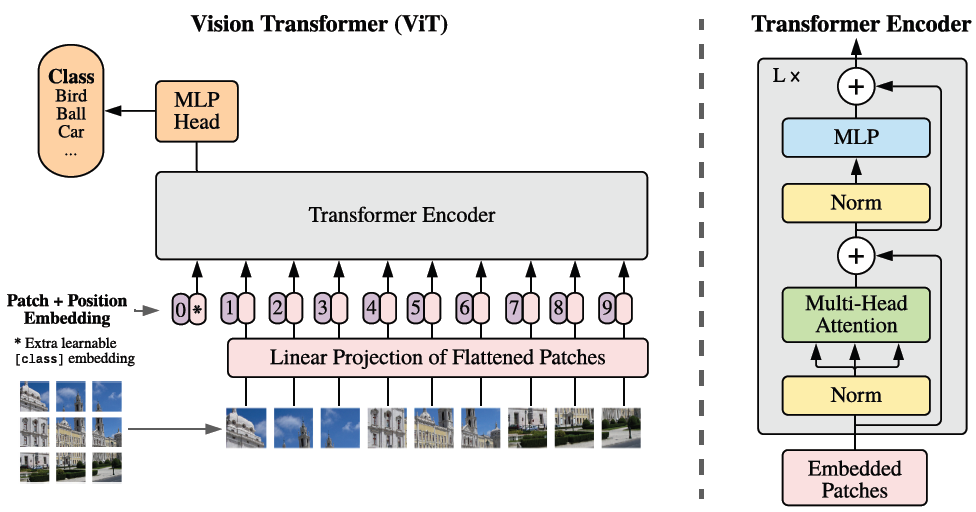 Visual Transformer是基于Transformer模型基础之上修改输入与输出部分,实现从词嵌入token输入到图像像素编码嵌入输入的改变。具体做法如下:
Visual Transformer是基于Transformer模型基础之上修改输入与输出部分,实现从词嵌入token输入到图像像素编码嵌入输入的改变。具体做法如下:
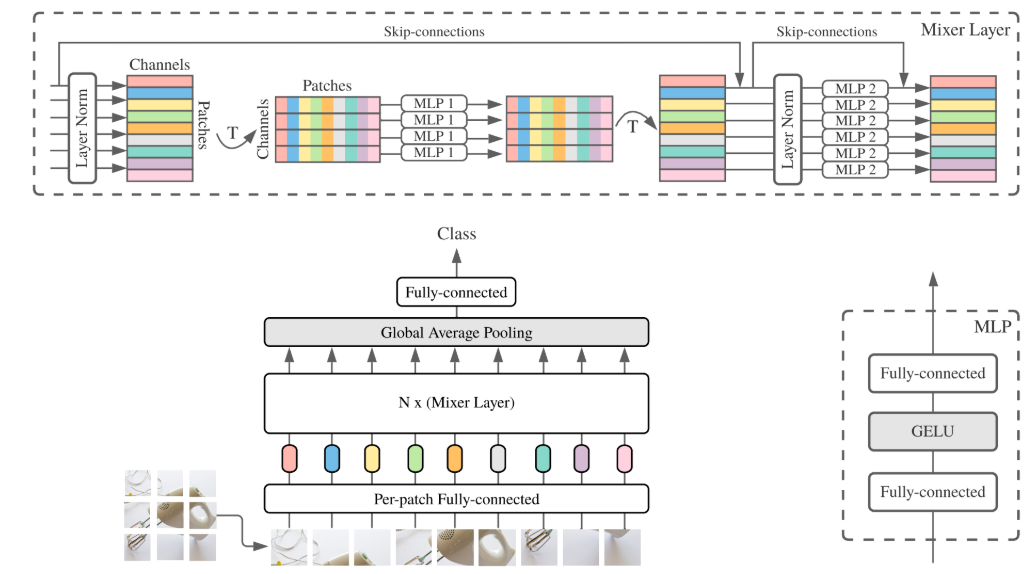
优势与不足

总结

原价:498
折扣:399
推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
总结 | OpenCV4 Mat操作全接触
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
YOLOv8 OBB实现自定义旋转对象检测
初学者必看 | 学习深度学习的五个误区
YOLOv8自定义数据集训练实现安全帽检测

