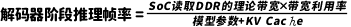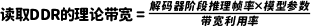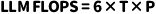汽车产业目前处于多项变革同时发生的时期,科技进步推动变革产生,新变革催生新的需求。智能座舱作为汽车市场下个阶段的竞争焦点,各主机厂正试图通过产品差异化来占据市场优势。用户对汽车座舱功能的需求维度也在不断拓展,智能座舱开始成为消费者日常生活的一个延伸,一个可移动的生活空间。未来的智能座舱将更多地兼顾“内容”、“服务”甚至是“主动智能”的升级。
那么,对于即将在未来投入应用的前沿技术,以及那些已经在实践中得到应用的技术成果,智能座舱领域又有着怎样的期待和展望呢?
虚拟现实
车载游戏
车手互联
多模态交互
大语言模型
舱驾一体化
本文小结
*注:本文作者张慧敏的新书《智能座舱:架构、原理与车规级芯片》近日出版,该书系统地剖析了智能座舱的多个子系统、基础软件及应用/服务的原理与架构,以及底层技术SoC的原理与实践。虚拟现实(VR)和增强现实(AR)技术,一度非常火爆。VR技术给用户提供一个交互式的虚拟三维空间,通过感知单元提供视觉,触觉,听觉等感官的模拟,让人们进入虚拟世界。VR需要用户使用特定的头盔形成一个密闭的虚拟空间。AR技术则不然,它是以现实世界为主体,通过全息投影镜片把显示内容与现实世界叠加。戴上AR眼镜,用户将可以接收与真实世界相关的数据化信息。虚拟现实技术将为智能座舱提供更强大的沉浸式体验。为了支持虚拟现实和增强现实技术,智能座舱需要满足如下的电子技术要求。1. 出色的图形渲染能力
虚拟现实和增强现实技术是通过人的眼睛,营造一个通过视觉而感知的虚拟世界。因此,出色的图形渲染能力必然是VR和AR技术的首选要求。对于人眼的感知能力而言,当显示屏幕的像素密度达到60PPD(Pixel Per Degree,即每度视场角包含的像素数目)时,人眼便无法分辨出单个的像素颗粒,这种状态通常被称为“视网膜屏”效果。若一个VR/AR眼镜的视场角(FOV)达到100°,那么为了在这个视场范围内都达到视网膜屏的效果,单眼的水平方向就需要至少6000个像素(这里假设视场是水平方向的,且PPD均匀分布)。另一方面,所谓的4K屏幕,其分辨率为3840*2160(UHD, 超高清分辨率),双眼就要求达到2*3840*2160的分辨率。因此,分辨率越高,用户观看VR/AR的体验效果就越好。 同时,由于VR/AR的显示屏距离眼球太近,为了避免用户产生眩晕不适,我们需要调节镜片与眼部的瞳距,并提升刷新率。针对VR/AR眼镜的显示帧率,最好是能达到120帧/秒。这个图形渲染的要求已经超过了当前手机SoC芯片的显示分辨率。因此,智能座舱芯片要想能使VR和AR的体验效果达到最佳,就要提升CPU、GPU、VPU、DPU以及DDR带宽和显示接口的能力。一般SoC芯片采用的MIPI DSI接口无法满足要求,需要考虑使用DP或者HDMI接口。2. 多元的交互能力
VR/AR技术为用户构建了一个沉浸式的虚拟世界,而为了实现真正的交互和沉浸感,用户与系统的交互方式显得尤为重要。简单的信息接收已不能满足现代VR/AR体验的需求,用户期望能够更自然地与系统沟通。目前,手部交互和语音交互是两种主流的人机沟通方式。用户可以通过VR手柄、游戏摇杆等传统设备与系统互动,这种方式虽然经典但稍显局限。为了更贴近真实世界的交互体验,穿戴式设备如手套、指环等逐渐受到青睐,它们为用户提供了更为直观和自然的操作方式。而手势识别技术的兴起,更是为VR/AR交互带来了新的革命。借助舱内摄像头,用户的手部动作被精准捕捉,进而实现3D手势识别。这种交互方式无需额外的物理设备,让用户能够更自由地与系统沟通,大大增强了沉浸感和真实感。 当然,未来的交互方式还有巨大的探索空间。随着脑机接口等前沿科学研究的深入,我们或许可以期待一种更为直接和高效的交互方式的出现。那时,用户只需通过意念即可与系统沟通,这将为VR/AR技术带来前所未有的变革。3. 超强的感知能力
座舱内的虚拟现实技术,与普通VR/AR眼镜相比,具有得天独厚的优势,因为它能充分整合和利用车载传感器的强大感知能力。举例来说,架构师可以巧妙地将车外摄像头捕捉到的沿途美丽风景实时投射到VR/AR眼镜中,使用户能够在享受虚拟世界的同时,也不错过旅途中的任何一处迷人景致,从而实现旅行拍摄和记录的独特功能。更有趣的是,用户在虚拟世界中的刺激冒险也能被投射到车载屏幕上,让家人和朋友一起分享游戏的欢乐和紧张刺激。这种互动不仅增强了用户与家人之间的情感联系,也让虚拟现实的体验更加丰富多彩。而为了进一步提升沉浸感,汽车的空气悬挂系统、座椅的通风和按摩功能、空调和香氛的控制系统,以及支持环绕立体声的音频系统,都被巧妙地融入到虚拟现实体验中。这些智能系统的联动,让用户在虚拟世界中遨游时,能够感受到更为真实和震撼的视听触感,从而获得前所未有的沉浸式体验。4. 强大的计算能力
智能座舱在VR/AR应用中的计算能力是其核心优势之一。为了减少用户戴上VR/AR设备后可能出现的眩晕感,智能座舱的计算单元会进行一系列精密的计算和补偿操作。例如,智能座舱的计算单元能够通过摄像头追踪用户的眼球注视焦点,然后计算并渲染针对用户的显示区域。这一功能对于调整VR/AR内容的呈现方式至关重要,可以确保用户所看到的内容始终与其视线方向保持一致,从而减少视觉上的不适感。 为了提供更加自然的虚拟现实体验,智能座舱需要实时计算VR/AR设备的6Dof(6 Degrees of Freedom,六个自由度)空间自由度。这意味着设备可以在X-Y-Z三个轴方向上转动,具体分为YAW(绕Y轴)、Pitch(绕X轴)、Roll(绕Z轴)的旋转,再叠加空间运动的定位信息(在三个轴方向上的移动),从而实现6个自由度的精确控制。通过这种计算,智能座舱能够精确地知道设备在空间中的位置和朝向,进而对显示屏投射进行运动补偿,以消除因设备移动或用户头部运动导致的画面抖动或错位,从而大大减少用户的不适感觉。图1所展示的是一个面向未来的AR眼镜应用场景,其中,AR眼镜被用于显示导航信息。第一个车载游戏的具体时间已经难以考证,但据资料显示,早在上个世纪80年代,一些汽车品牌如丰田和本田就开始尝试在车载娱乐系统中加入简单的电子游戏功能。这些游戏通常比较简单,例如“贪吃蛇”、“俄罗斯方块”等,目的是为了在长途旅行中给乘客带来一些娱乐。然而,这些早期的车载游戏功能并没有得到广泛普及,因为当时的电子游戏技术还比较初级,而且车载娱乐系统的硬件和软件也相对简单。随着智能座舱的普及,车载游戏开始与座舱的智能化技术相结合,产生了更加多样化的游戏形式和体验。 在车载游戏领域,“3A大作”这一词汇近来备受瞩目。所谓“3A大作”,即指那些成本高、规模大且品质卓越的单机游戏。它们以绚丽的画面、充实的游戏内容及深层次的体验吸引着无数玩家。特斯拉曾经在Model S车型上演示了3A游戏,例如《赛博朋克2077》、《巫师3:狂猎》、和《刺客信条:奥德赛》。在这些游戏中,玩家可以进行角色扮演,探索广阔的世界并完成任务。然而,引入这些游戏必须要考虑到软硬件的生态问题。例如,这些游戏运行在与Steam Deck(一个掌上游戏发行平台)相同的Linux版本之上,其运行硬件平台是AMD公司的x86 CPU和RDNA GPU(独立显卡)。一般基于ARM的SoC还不能运行类似的游戏。1. 车载3A游戏技术路线
在座舱中引入3A游戏大作,可以考虑如下3条技术路线:使用x86芯片平台构建座舱SoC是一种可行的方式。相比移动端的ARM架构,x86芯片平台具有强大的计算能力,可以满足3A游戏大作的高性能需求。x86平台搭配运行的操作系统是Linux系统,这意味着基于Steam(一个电子游戏数字发行平台)的大量游戏可以直接在这个系统上运行。其庞大的游戏库和持续的更新都为座舱提供了持续的游戏内容。因此,x86的生态系统已经满足了许多3A游戏大作的要求,为游戏开发者提供了便利。Android手机类游戏的崛起不容忽视。以《原神》为例,这款游戏凭借其精致的画面、丰富的世界观和深入的角色定制赢得了全球玩家的喜爱。它的受欢迎程度不仅仅在于游戏本身的品质,更在于Android平台为其提供了广泛的用户基础和便捷的更新机制。与其他平台相比,《原神》在Android上的表现更加出色,其优化后的版本可以充分利用ARM平台CPU和GPU的性能,为用户提供流畅的游戏体验。 当前,新能源车智能座舱采用ARM架构和Android操作系统的比例很高。将手机上的3A游戏移植到座舱上,成本较低,花费较少,具有广泛的用户基础,是一条可行的道路。还有一种可行的方式是采用游戏机投屏方式。这种方式可以利用已有的游戏机和游戏资源,不需要进行大量的开发和移植工作。例如任天堂公司发布的Switch、索尼公司的PS5和微软公司的Xbox等(以上三者都是流行的游戏机硬件设备)。这些主流游戏机都支持投屏功能。通过HDMI线缆或者DP线缆,这些机器可以将游戏画面投屏到座舱内部的中控大屏上。用户可以在座舱内享受到与家庭游戏机相似的体验。这些游戏机已经拥有庞大的游戏库,且持续更新,确保了游戏的多样性和新鲜感。同时,由于是直接从游戏机投屏,所以在画面质量和流畅度上都有很好的保障。2. 智能座舱SoC能力要求
为了直接通过座舱的计算平台运行3A游戏,智能座舱SoC需要满足如下一些条件:如果我们希望通过座舱SoC直接运行3A级游戏,那么不论是选用x86平台还是ARM平台,高性能的GPU都是不可或缺的。通常情况下,在ARM平台上,SoC内部会直接集成嵌入式的GPU IP核;而x86平台则往往会采用一块独立于SoC的GPU。x86平台下的独立GPU算力可以远超ARM架构下的GPU,其从个人计算机环境继承而来的桌面级GPU的图形渲染管线更能为游戏场景增添惊艳的光影效果。然而,采用更强大的GPU也会带来空间布局和散热等更为复杂的挑战。因此,在设计座舱域控制器时,必须全面权衡高性能GPU所带来的利弊。有时会需要采用主动降温方式,但这样又增加了成本。 不同的座舱平台在运行3A游戏时会消耗不同的电能。ARM架构通常配备嵌入式GPU,其供电功率一般约为十几瓦。而x86架构的独立GPU在运行游戏时,供电功率可能高达120瓦。对于外置式游戏机而言,三大游戏机的供电需求差异显著。Switch作为一款掌上游戏机,可通过USB Type-C线进行快速充电,其供电功率为33瓦。PS5和Xbox则属于家用游戏机类别,体积更大,对电源功率的要求也更高。PS5需通过电源插座供电,其额定功率为350瓦。Xbox则分为两个版本:Xbox Series S的电源功率为165瓦,而Xbox Series X的电源功率高达330瓦。因此,若智能座舱内需支持游戏机投屏功能,就必须考虑供电能力是否充足,以及是否配备了220V电源插座。这些因素将对车载供电能力的分配和座舱内部布局产生影响。将家用游戏机的画面投屏到座舱内部大屏幕,这与将游戏机投屏到客厅的电视机或电脑显示屏类似。Switch游戏机可以通过其壳体上的USB Type-C接口直接输出DP视频信号,同时也可通过一个转接底座,将DP信号转换成HDMI信号输出。而PS5和Xbox游戏机则都只支持HDMI视频信号输出。因此,座舱SOC需要配备DP或HDMI视频输入接口。这种有线投屏方式能够实现10ms以内的视频信号延迟,这对于动作交互类游戏的体验至关重要。图2展示了特斯拉汽车在智能座舱内支持3A游戏的场景。
最早的车机与手机互联案例是利用蓝牙技术拨打电话。由于相关法规禁止驾驶员在驾驶时使用手持电话进行通话,但驾驶员在行车过程中又有通话的需求,因此,将车载麦克风和音响通过蓝牙技术与手机相连,便实现了非手持式通话功能。这种蓝牙互联的需求逐渐成为了刚性需求。
随后,车机和手机互联的进一步实现案例是苹果公司的CarPlay。CarPlay于2013年首次推出,通过与汽车制造商的合作,使用户的苹果手机能够与汽车仪表盘和中控台无缝连接,从而提供了多样化的功能。例如,通过CarPlay,用户可以轻松使用电话、短信、导航、音乐和其他应用程序,同时支持语音控制或触控操作。除苹果外,谷歌也推出了类似的系统——Android Auto,它可以将Android手机上的应用投屏到汽车中控台上。对于苹果公司的CarPlay技术而言,它提供了两种将苹果手机与座舱系统互联的方式:一是通过USB数据线进行有线连接,二是利用蓝牙和Wi-Fi技术进行无线连接。在连接建立后,iOS设备的操作界面和各种应用程序功能会投射到车载屏幕上,用户便可通过车载屏幕和语音指令来操作iOS设备上的功能,例如导航、音乐播放和拨打电话等。CarPlay使用的互联技术是一组包含iAP2(iOS Accessory Protocol, version 2)协议的协议族,这些协议共同负责建立和维护CarPlay会话(CarPlay Session)。从技术层面讲,其无线连接的底层实现是基于Wi-Fi P2P(点对点)协议的,这种协议使得两个Wi-Fi设备无需通过接入点(如无线路由器)即可实现直接通信。 1. 公有无线投屏协议
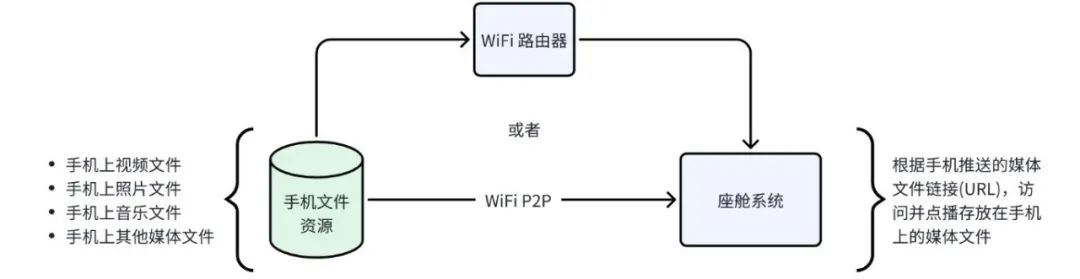
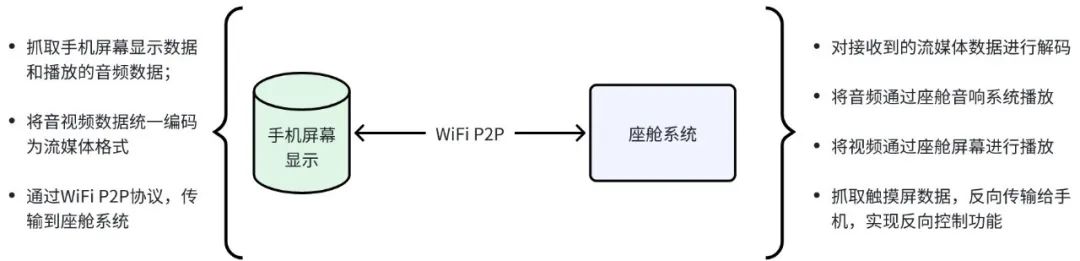
一般来说,车机与手机实现无线互联的协议分为公有和私有两大类。公有协议通常包括DLNA和Miracast两种。DLNA(Digital Living Network Alliance,数字生活网络联盟)由索尼、英特尔、微软等公司发起成立,旨在实现个人计算机、移动设备、消费电器之间的无线网络和有线网络的互联互通。DLNA技术主要以实现内容分享功能为主,可以灵活地实现网络文件链接和流媒体的推送,具有连接速度快、协议轻量的优点。由于它只提供内容分享功能,并不需要在发送端进行屏幕捕获、编码等工作,因此对发送端的处理能力要求较低。DLNA也被称为“Push Mode”,即推送模式。在这种模式下,手机与座舱系统连接到同一个Wi-Fi网络。当需要互联时,手机发送一个视频资源的地址链接给座舱系统,后者通过该地址链接获取视频文件并开始在线播放。手机可以控制座舱系统的播放进度、音量等。从图3可以看到,DLNA技术的底层协议可以通过Wi-Fi路由器实现手机和座舱SoC的互联。此时手机甚至可以不在座舱内部,可以远程将手机上的音视频文件推送给智能座舱系统进行播放。当然DLNA也可以采用Wi-Fi P2P作为点对点直联方式,实现车机和手机之间的互联。 Miracast是另一种用于无线投屏的技术,由Wi-Fi联盟发布,也被称为Wi-Fi Display。它基于Wi-Fi P2P(Peer to Peer,点对点)技术,实现了音视频数据的无线传输与播放。自2012年10月起,Google发布的Android 4.2版本开始支持Miracast功能。由于它是一个开放的标准,并且得到了Android平台的支持,市面上支持Miracast的设备开始大量出现。在Miracast的R1版本中,仅实现了屏幕分享功能,并不支持通过网络链接方式传输音视频流文件。无论发送端播放的文件是何种格式,Miracast都会将抓取的屏幕内容编码为H.264格式后再进行传输。这样,发送端与接收端都采用固定的格式进行编解码,从而有效减少了兼容性问题。然而,屏幕的抓取与编码过程需要消耗大量的计算资源,这不仅对发送端的性能和配置提出了较高要求,而且还需要发送端提供硬件编码接口以提升编码效率。在R2版本之后,Miracast开始支持“Mirror Mode”和“Push Mode”两种模式。其中,“Mirror Mode”,即镜像模式,是直接抓取手机屏幕数据,编码为H.264等流媒体格式后,再传输到座舱系统的投屏方式。图4展示了基于Miracast的无线投屏系统框架。从图4可以看到,Miracast技术的底层协议通过Wi-Fi P2P协议实现车机和手机的互联。它最重要的功能就是可以采用“Mirror Mode”实现投屏。这样的场景使用灵活性更高。 2. 私有车手互联协议
在进行车机和手机互联时,一个主要的应用思路是将手机的计算能力扩展到座舱系统上。由于汽车电子的特性,座舱系统的算力平台必须符合车规要求,这通常意味着座舱内的SoC芯片性能会弱于同时期的消费类电子芯片。例如,智能手机芯片的算力逐年提升,而座舱SoC芯片却只能以三年或更长的周期进行更新换代。鉴于这种算力分享的需求,汽车主机厂提出了新的要求,即通过私有协议实现手机和座舱系统的互联互通。这种连接不仅实现了Wi-Fi无线投屏的功能,还能将座舱的计算需求发送到手机端,利用手机芯片的资源进行计算,然后再将结果返回给座舱系统。这种私有协议的实施方式取决于各个厂家的具体实现途径,但它能为用户带来更加优质的体验效果。以蔚来汽车的“NIO Link”协议为例,其目标是构建以车辆为中心的全景移动互联技术,该技术融合了车辆和手机的多端软硬件能力,旨在连接用户、产品、服务和社区,为用户带来全新的移动互联体验。具体来说,在蔚来设计的手机NIO Phone上,实现了一个实体按键,即“NIO Link”车控键。这个按键不仅能在车内控制车辆功能,如空调调节、音乐控制、氛围灯切换等,还能在车外进行远程控制,如远程遥控空调、车辆召唤等功能。此外,NIO Link协议还支持天空视窗技术,该技术可以将手机屏幕的“第二画面”投射到中控大屏上,从而实现手机和车机的双应用并行运行,且可以左右灵活拖动。这种投屏技术适用于会议系统或手机游戏等场景,实现了手机资源与座舱资源的共享使用。人机交互模式在座舱内部的表现,一直以来都是评判智能座舱的核心标准。在非智能时代,用户只能通过各类按钮来操控车内功能。然而,随着中控大屏的兴起,大部分功能被整合到屏幕上,用户开始通过触摸屏来控制车辆功能。从触觉的角度来看,触摸屏与实体按键在操作感受上并无显著区别。直到语音助手的诞生,座舱内部的人机交互方式才实现了质的飞跃。通过对话,车载智能语音助手能够识别并执行人的指令,从而部分实现了对人类操作的替代。之所以说“部分”,是因为在实际使用中,车载智能语音助手有时难以精确理解人类的需求。例如,当用户说出“打开空调通风功能”时,智能语音助手可能会错误地理解为打开车窗,而非启动空调的通风模式。
此外,车载智能语音助手还无法识别对话的上下文,也无法与座舱内的多人同时展开对话。这种局限性使得语音助手显得缺乏人性化。未来,智能座舱的演进方向将是能够融入环境、像正常人一样对话、并能协助乘客的智能机器人。如今,人们对座舱的人机交互模式提出了更高的要求,即实现多模态交互。最迫切的需求是将触觉、听觉和视觉相结合,以打造更加智能、精准的交互方式。目前多模交互已经锁定了几个研究的方向。1. 面部情绪识别
情绪识别是一种新兴的交互方式,可以通过识别驾驶员或者乘客的情绪来提供个性化的服务。研究方向包括情绪识别算法、生理信号分析等方面的技术,以提高情感识别的准确性和可靠性。
情绪识别的原理主要是基于对人类情感的理解和情感特征的提取。人类的情感通常会伴随着一些生理反应,如心率、呼吸、语音等的变化,这些生理反应可以被检测和识别。同时,人类的情感也会表现在面部表情、肢体动作等方面,这些也可以被用来识别情感状态。情感识别技术通过综合分析这些特征,来判断一个人的情感状态。情绪识别的算法可以分为两类:一类是基于规则的方法,另一类是基于机器学习的方法。基于规则的方法是通过分析人的语音、表情等特征,来判断其情感状态。这种方法需要事先定义好各种情感的特征,因此准确度有限。基于机器学习的方法则是通过训练大量的情感数据来让计算机自动识别情感状态。这种方法需要大量的标注数据,但准确度较高。 随着Transformer模型(一种基于自注意力机制的深度学习模型)在越来越多的领域得到应用,多模态识别可以采集人类面部图像和语音数据,并使用Transformer模型来分析和识别人物的情感。举一个例子,我们可以在智能座舱内部使用DMS和OMS摄像头采集驾乘人员的面部图像,使用车载麦克风采集语音对话数据。而后,使用适当的算法和模型从面部图像中提取情感相关的特征,例如使用卷积神经网络(CNN)进行特征提取。对于语音数据,可以使用梅尔频率倒谱系数(MFCC)等特征进行提取。这些特征输入到Transformer模型的Encoder(编码器)部分进行进一步的处理和特征提取。在Decoder(解码器)部分,可以使用情感分类任务的目标函数来训练模型,使其能够识别不同情感的特征。2. 多人对话并发
在当前已投入使用的智能座舱语音助手中,存在一个显著的痛点,即无法支持多人同时对话。每当座舱内有其他用户提出问题时,他们总是需要先使用特定的唤醒词来激活语音助手,然后才能进行对话。这种操作会打断之前用户的对话进程,给用户带来不连贯的体验。为了解决这个问题,我们可以采用基于规则的对话管理和上下文管理策略来实现多人对话上下文的继承。我们需要构建一个对话的上下文状态模型,这个模型会记录对话的参与者、当前讨论的话题以及历史交流信息等。通过精细的对话管理,系统能够追踪每个参与者的交流意图和需求,从而确保对话的流畅性和内容上的连贯性。 必须确保所有对话参与者都能访问和共享统一的上下文信息。这可以通过采用共享内存或者云端存储等技术手段来实现,以确保信息的准确无误和一致性。我们需要根据对话的上下文状态来制定合理的上下文继承策略。例如,在多轮次的对话过程中,系统可以继承前一轮对话中的关键信息和指令,以便于在接下来的对话中继续使用。同时,随着对话的深入和用户需求的变化,我们需要灵活地调整上下文继承的方式和内容。借助自然语言理解技术,我们可以对用户输入进行深度语义分析。这有助于系统更准确地把握用户的意图和需求,从而更好地维护对话的上下文状态,并继承相关信息。系统应根据上下文状态和继承策略,实时调整对话的进程和交互模式。这可能包括基于历史信息预测用户的意图,或根据话题的转变来更新交互内容,从而提升对话的针对性和效率。总之,以上所提的处理方式只是上下文管理众多可能性中的一种。这个领域的研究仍处于前沿探索阶段,各种解决方案都在不断地演进和优化中。3. 3D手势操控
3D手势识别是智能座舱中新兴的操控方式之一。以后排娱乐屏为例,在一些乘用车车型中,车顶的中央位置会配备一块显示屏幕,旨在为第二排和第三排的乘客提供优质的观影体验。然而,如何操控这块屏幕却成为了一个体验上的挑战。若采用触摸屏方式,由于距离的限制,第三排乘客难以触及;若采用语音控制,未经训练的用户可能会遇到下达指令的困难;而使用遥控器操控,则存在遗失设备的风险。针对上述各种不足,一种简单方便的操控方式是采用3D手势识别技术。 通过3D深度相机,我们可以采集用户的手部动作数据。随后,这些数据会经过预处理并被分割成独立的手势。利用深度学习算法,我们从这些手势中提取特征,并进行持续的跟踪和预测,从而准确地识别用户的手势动作并判断其意图。最终,用户的动作会被转化为具体的控制指令,例如隔空点击屏幕的某个图标或滑动屏幕进行切换等。这种操控方式不仅有效避免了上述方法的各种弊端,而且为用户带来了极为自然和流畅的体验。4. 多模融合
多模态交互是一个综合性的技术,它融合了多种感知技术来提升人机交互的体验。例如,动作识别、目光追踪、语音识别、触摸控制等,都是多模态交互的重要组成部分。这些技术分别对应了人类的五大感知:视觉、听觉、触觉、嗅觉和味觉。- 动作识别和目光追踪与视觉:动作识别和目光追踪技术可以捕捉和分析用户的身体动作和眼球移动,从而实现更加自然和直观的人机交互。这些技术类似于人类的视觉功能,能够“看到”并理解用户的动作和意图。
- 语音识别与听觉:语音识别技术能够识别和解析用户的语音指令,为用户提供了一种更加便捷和自然的交互方式。这与人类的听觉功能相似,通过声音来接收和理解信息。
- 触摸控制与触觉:触摸控制技术允许用户通过触摸屏幕或其他设备来进行操作,提供了一种直观和易用的交互方式。这与人类的触觉功能相呼应,通过触摸来感知和操作物体。
- 香氛系统与嗅觉:在座舱内部,有一个重要的与人类的嗅觉相关的系统,即香氛系统。虽然人类的嗅觉在人机交互中不直接对应某种操作,但香氛系统可以通过释放不同的气味来影响用户的情绪和体验,从而提升交互的舒适度。
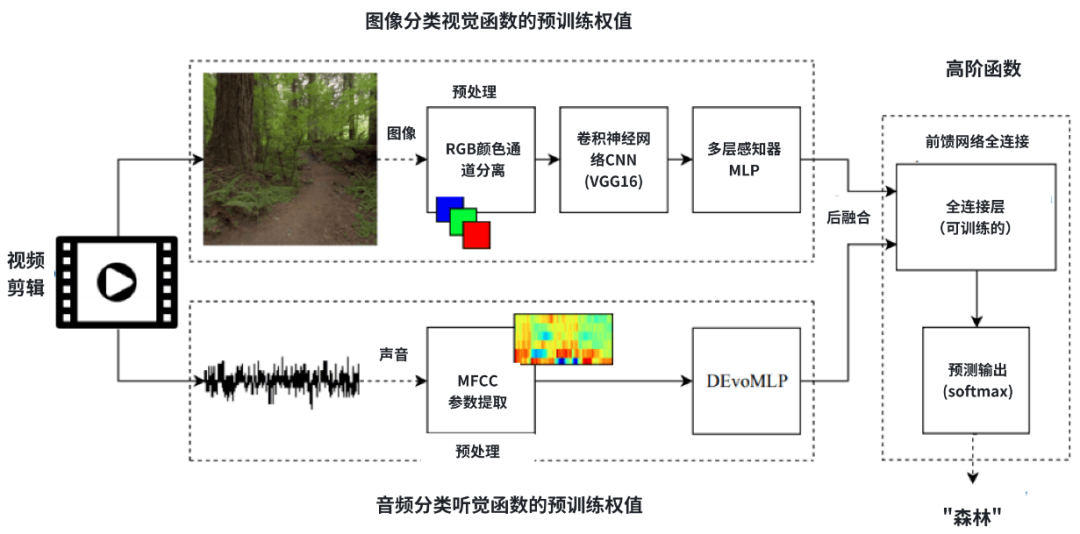
至于味觉,目前在多模态交互中的应用相对较少。或许在未来,当科技不断发展,人工智能技术与脑机接口技术实现了融合之后,可以将人类的味觉引入到座舱的交互体系中来,这将为人机交互领域带来新的可能性和创新点。 在多模态交互中,各种感知技术的融合为提升人机交互体验带来了巨大的潜力。手势识别技术和视觉识别技术作为计算机视觉技术的一部分,在数据融合技术的支持下,能够显著提升交互的智能性和准确性。数据融合技术的关键作用在于,它能够将来自不同传感器的数据进行整合,利用AI算法对这些数据进行深度分析和处理。例如,通过融合视觉传感器和音频传感器的数据,系统可以对人脸、动作、姿态、唇语、语音等多种信号进行综合辨识,进而提高识别的准确度。这种跨模态的数据融合不仅增强了系统的感知能力,还使得交互更加自然和智能化。从图5可以观察到,在一段视频剪辑的处理流程中,图像数据与声音数据被分别送入预处理模块。它们随后通过专门的视觉与听觉神经网络进行分类处理。这些神经网络的预测结果被进一步进行后融合处理。在基于一定规则和权重的综合推测下,多模系统最终输出了该视频的主题预测:森林。 最早的车载语音助手功能相对简单,只能识别人类语音,将其转换为文本,并理解和执行一些基础指令。由于车载计算机的计算能力受限,这些任务通常由云端的AI算法处理。然而,这种模式在响应的实时性和可靠性上存在明显的限制。随着ChatGPT(一款基于大语言模型的聊天机器人程序)的兴起,公众对车载语音助手的期待也随之提升。人们期望车载语音助手能像ChatGPT一样“智慧”,能进行自然而流畅的对话,帮助用户正确使用汽车的各种功能,甚至能与用户进行情感沟通,提供更加自然和温馨的体验。这正是大语言模型(LLM,Large Language Model)的魅力之所在,它推动着车载语音助手不断走向智能化,越来越贴合人类的期待。在给出大语言模型的定义之前,我们首先来看一下表1,它总结了大语言模型的发展历程。 | |
| NLP是一种让计算机理解和分析自然语言的技术,包括词法分析、句法分析、语义理解等。通过这些技术,NLP可以将输入的问题进行分词、词性标注、句法分析等处理,从而理解问题的含义和上下文。 |
| 在Transformer模型提出之前,NLP(自然语言处理)领域主要使用基于规则的方法和统计机器学习方法进行分析和处理。基于规则的方法主要是指人类手工编写规则和模板,用于对语言进行解析和生成。这些规则通常针对特定的语言现象或任务,需要语言学家和程序员共同协作。基于规则的方法虽然精度较高,但可扩展性和灵活性较差,且需要大量的人力物力。 |
| 随着神经网络模型的广泛应用,NLP进入了LLM时代。LLM是指大规模的语言模型,通常使用大规模的文本数据对模型进行训练,以学习语言的语法、语义和上下文信息。有多种类型的神经网络模型都可以支持LLM,如递归神经网络(RNN)、长短时记忆网络(LSTM)和Transformer等。这些模型都能够在大规模的文本数据上进行训练,从而生成高质量的语言表示,并应用于各种NLP任务,如文本分类、情感分析、问答系统等。 |
| Transformer模型的出现,标志着NLP设计迈向了一个新的里程碑。它由Google公司提出,在NLP中使用Transformer模型来生成回答。Transformer模型是一种基于自注意力机制的深度学习模型,通过多层的自注意力机制和注意力权重来捕捉输入文本的上下文信息,从而生成更加准确和相关的回答。在训练过程中,Transformer会使用大量的语料库进行训练,通过优化目标函数来最小化预测结果与真实结果之间的差异,从而不断提高回答的准确率和相关性。从此,大语言模型突破了参数和算力的限制,进入了参数越多,数据越大,效果越好的状态。 |
| 随着Transformer模型的成功应用,OpenAI公司开始尝试将其应用于更大规模的训练数据,从而诞生了GPT(Generative Pre-trained Transformer,生成式预训练Transformer模型)。GPT-1和GPT-2模型在更大的数据集上进行训练,并使用无监督学习进行预训练,从而提高了模型的语言生成和理解能力。GPT-3模型进一步扩大了训练规模,使用更复杂的架构和更大的数据集进行训练,从而产生了更加丰富和准确的语言生成能力。GPT被设计成可以支持多轮对话的模型,能够根据上下文信息生成更有针对性的回复。这种能力有助于提高对话系统的自然度和交互质量。 |
| 随着GPT模型的不断发展,OpenAI公司在GPT-3的基础上开发了Instruct GPT模型。Instruct GPT采用了与GPT-3相同的架构和参数数量,但在训练过程中引入了人类专家指导,以提高模型的语言生成质量。这种训练方式使得Instruct GPT能够生成更加准确、清晰和有逻辑性的语言输出。 |
| 代码训练能力的提升是GPT3到GPT3.5的重要迭代之一。在GPT3的基础上,OpenAI增加了Codex模型,让它阅读大量的代码,从而能够理解和生成代码。 |
| RLHF的全称是reinforcement learning from human feedback,通过构建人类反馈数据集,训练一个reward(评估)模型,模仿人类偏好对结果打分,是GPT-3后时代LLM越来越像人类对话的核心技术。 |
| ChatGPT是OpenAI在GPT系列模型的基础上开发的一种专门用于对话生成的模型。ChatGPT以Instruct GPT和GPT 3.5模型为基础,在训练过程中使用了大量的对话数据,以提高模型的语言生成和对话生成能力。同时,Chat GPT还针对对话生成任务进行了优化,能够更好地捕捉上下文信息,生成更加自然和个性化的对话回复。 |
表1深刻地总结了大语言模型的发展历程。大语言模型(LLM)是一种能够理解和生成自然语言文本的深度学习模型,具备强大的语言处理和生成能力。 从最初的自然语言处理(NLP)开始,人们就希望计算机能理解人类的语言,并能实现像人类一样的对话。神经网络模型的出现推动NLP技术进入了大语言模型时代,随后Transformer模型与GPT系列的诞生,更是让大语言模型演变成了我们今天所看到的“智能”机器人对话程序。综合来看,ChatGPT的出现,使大多数人深刻认识到大语言模型将会改变人类社会和人类的生活方式。ChatGPT是一种革命性的AI应用,它为人类提供了一种全新的方式来调用算力和数据。在ChatGPT正常运行的背后,GPT-3.5是其不可或缺的支撑力量。GPT-3.5的本质是学习人类存放在互联网上的知识,并将其整合成大型语言模型。只要模型足够庞大,参数足够丰富,它就能从中检索出相关信息,并以此为基础生成回答。2. 大语言模型在车上的应用方式
在车载智能语音助手中应用大语言模型,有两种不同的方式,一种是云端运行,另一种是车端运行。智能座舱会采集人类的语音,并通过车载无线模块将这些语音数据传输到云端。在云端,大语言模型会识别这些语音数据并生成相应的回答,然后再将这个回答传回车内。只要数据传输速率足够快,人们几乎感觉不到对话中的任何延迟。这种实现方式相对简单。汽车制造商可以选择自建云端服务器,或者租用商业化的云服务。在云端部署大语言模型后,车载计算机系统就只需实现语音识别功能。这样做可以减少车载系统的资源需求,进而降低车辆成本。在网络信号不佳或网络带宽受限的情况下,智能语音助手的性能会大幅下降,可能出现响应迟钝或完全没有回应的情况。同时,从个人隐私和数据安全的角度来看,云端处理用户语音数据存在一定的风险,这会引起部分用户的担忧。此外,当在云端实现大型语言模型时,还需要考虑到多用户并发访问的性能和容量问题。如果不能及时扩展计算和网络资源,就可能无法满足日益增长的用户需求和数据规模。这种方法的构想是,利用车载中央计算平台的算力,在智能座舱域的计算芯片上直接部署大型语言模型。在此方案中,智能座舱会通过语音识别或多模态交互来收集用户的问题,并直接在车端通过大语言模型进行计算,从而生成回答。这种方法的主要优势在于其减少了对网络的需求。由于所有的计算都在车端进行,因此可以避免因网络信号不足或带宽受限而导致的响应延迟或无法回答的问题。此外,车端计算还能更有效地保护用户隐私和数据安全,因为用户的语音数据无需上传到云端进行处理。然而,这种方法面临的最大挑战是对车载中央计算平台的算力有较高要求。部署大语言模型需要强大的计算能力,这意味着需要高配置的计算芯片以及高效的算法优化。同时,为了维持大语言模型的性能和准确性,必须定期更新模型和算法,这无疑会增加额外的维护成本。人们也找到了一些方法来解决面临的问题,例如,采用OTA技术进行模型的升级就是一种可行的方法。3. 车端运行大语言模型可行性探讨
下面,我们来探讨在车端实现大语言模型的可行性。
尽管ChatGPT-3.5和ChatGPT-4的表现令人印象深刻,但OpenAI公司并未将其开源,这导致我们难以对ChatGPT进行深入的量化分析。幸运的是,Meta公司(原Facebook公司)将他们的大语言模型LLaMA(Large Language Model Family of Meta AI )进行了开源。这使得我们能够根据模型的详细信息和运行结果,来探讨在智能座舱内部署LLaMA的可行性。
不论是ChatGPT还是LLaMA,大语言模型的基本处理流程都是相似的。假设我们向LLaMA模型提问:“床前明月光的下一句是什么?”我们来看看它是如何生成答案的。其推理过程和步骤详见表2。 | | |
| | LLM的输入数据是一段文本,可以是一个句子或一段话。文本通常被表示成单词或字符的序列。我们需要将问题转化为机器可以处理的格式。这通常包括将文本分成一系列的词(token)。在这个例子中,输入数据将是“床前明月光的下一句是什么?” |
| | Tokenization 是一个在自然语言处理和文本分析中常用的术语,指的是将连续的文本(如句子、段落)拆分成一系列离散的词素或标记的过程。这些词素或标记被称为“tokens”。它帮助将文本转化为机器可以理解和处理的形式。在这个例子中,输入数据被拆分成“床前”,“明月”,“光”,“的”,“下”,“一句”,“是”,“什么”。 |
| | 在Embedding过程中,每个Token(如“床前”)会被转换为固定大小的向量。这个向量的具体值是由模型的训练过程确定的,是模型学习到的语义信息的表示。每一个Token对应的嵌入向量,保存在模型的嵌入层权重文件中。这些权重文件通常在模型训练过程中保存,并在推理时用于计算嵌入向量。 |
| | 由于Transformer模型需要知道每个token在句子中的位置信息,因此需要在每个token的嵌入向量上添加位置编码(Position Encoding)。位置编码告诉模型每个token在句子中的位置,帮助模型理解上下文信息。 |
| | 接下来,将带有位置编码的嵌入向量输入到LLaMA模型的Transformer结构中进行推理。LLaMA模型由多个自注意力层和跨注意力层组成。这些层会对输入进行变换和更新,逐步生成输出。 |
| | 在Transformer模型中,每个token的生成依赖于之前的token。因此,我们使用自回归的方式逐步生成输出。这意味着我们先生成第一个token,然后使用这个token作为输入来生成第二个token,以此类推,直到生成完整的答案。在这个例子中,我们从“床前明月光的下一句是”开始,然后逐步生成每个后续的词,直到得到完整的诗句“疑是地上霜”。 |
| | 最后,我们需要对模型的输出进行处理,以获得最终的答案。这可能包括去除停用词、将输出转换为文本格式等。在这个例子中,最终的答案将是“疑是地上霜”。 |
从表2的推理过程可以看到,一个大语言模型的推理过程,需要查询“token”的权重。这就引出了大语言模型的一个重要指标:参数大小。大语言模型的参数大小,指的是模型中用于学习和生成文本的权重参数的数量。参数大小是衡量模型复杂度及其所需存储空间的关键指标。当我们提及大语言模型的参数大小为7B或13B时,“B”代表“Billion”,即十亿。因此,7B意味着模型包含70亿个参数,而13B则表示模型包含130亿个参数。这些参数在训练过程中被学习,旨在描绘语言的复杂模式和生成有意义的文本。参数大小对模型的表现和性能具有重要影响。通常来说,更大的参数规模使模型能够捕捉更复杂的语言模式和语义信息,但同时也提升了模型的复杂性和训练成本。在进行Transformer推理时,这些参数权重文件需加载到NPU的计算单元中。模型参数越多,其回答往往更为精确。然而,相应地,它对NPU计算资源和主存储器(DDR)传输带宽的要求也更高。(1)DDR带宽需求
要计算DDR带宽需求,首先需要了解不同参数规模的模型对DDR存储空间的需求。表3总结了不同参数规模的LLaMA模型所需要的存储空间。从表3可以看到,参数规模为7B的模型,假如参数精度为int4,那么每一个参数需要用到0.5字节来保存。70亿*0.5=3.5GB。如果参数精度为fp32,那么每一个参数就需要使用4字节来保存,这时模型的大小就是70亿*4=28GB。根据Transformer模型的自回归机制,计算每个“Token”时,需要加载模型权重文件。由于NPU内部用于高速计算的片内随机存取存储器(RAM)空间有限,我们不可能将整个模型都完全加载到NPU的高速RAM空间中,而只能采用动态加载方式。比如说,我们如果采用7B模型,精度为int4,那么每次计算都需要分批从主存储器读取3.5GB大小的模型参数文件到NPU中进行计算。在上述公式中,KV Cache是NPU的片上缓冲区,它用于存储在Transformer自注意力机制中计算得到的键-值对(key-value)。这些键-值对在自回归解码的后续时间步骤中被重复使用,这样就避免了重复计算的开销。与模型参数所占的空间比较,KV Cache的数值相对较小。因此,在计算过程中我们可以忽略KV Cache。在此前提下,再考虑到DDR的带宽利用率通常设定为80%,其理论带宽的计算公式为:假设我们希望做到每秒能计算30个Tokens,那么DDR理论带宽就需要达到30 (tokens/s) * 3.5(GB) / 0.8=131GB/s。如果将每秒Tokens降低到20,则DDR带宽需求也就相应地降低到20(tokens/s) * 3.5(GB) / 0.8 = 87.5GB/s。(2)NPU的算力需求
除了DDR带宽的需求之外,我们再来看看如何计算LLaMA模型所需要的算力资源。FLOPS(Floating Point Operations per Second),即每秒浮点运算次数,是衡量计算速度的单位。它通常以MFLOPS(每秒一百万次浮点运算,即10^6次)、GFLOPS(每秒十亿次浮点运算,即10^9次)和TFLOPS(每秒一万亿次浮点运算,即10^12次)等单位来表示。 根据资料,推理Transformer和大语言模型时,所需算力(FLOPS)的计算公式为:其中,T代表Tokens数目,P代表模型的参数数量。以7B模型为例,假设需要达到30 tokens/s的推理速度,那么FLOPS = 6 * 30 * 7 *10^9 = 1260*10^9。也就是1.26TFLOPS。根据以上计算可以得出结论:如果我们要在智能座舱端侧进行大语言模型的推理,那么对SoC芯片的DDR带宽和NPU算力都有一定的要求。这些要求与所采用的大语言模型的参数大小、参数精度以及推理速度需求都密切相关。相对而言,在车载环境中运行大语言模型时,对DDR带宽的性能要求比对NPU算力的要求更高。在智能座舱的演进过程中,舱驾一体化成为了一个极具现实意义的议题。众多行业专家都认为,舱驾融合代表着未来的发展趋势。以中央集中式区域控制的EEA架构为例,它在宏观意义上已经实现了舱驾融合。在分布式域控制器的EEA架构中,智能座舱域控制器和自动驾驶域控制器被分别置于不同的“盒子”内,二者之间通过以太网相连,虽然可以传输一些控制信息,但基本上是在各自独立运行。然而,在中央计算平台的架构下,智能座舱SoC和自动驾驶SoC被整合在同一个盒子中,并通过高速总线(例如PCIe)相连,其带宽可达数十GB每秒。这样的技术环境使得智舱SoC和自驾SoC能够实现一定程度的算力共享。简而言之,它们可以相互配合,协同完成任务。这种做法不仅有效地实现了算力的共享,还能共享外部传感器,从而推动了舱驾融合的实现。例如,车载前视摄像头是自动驾驶域中用于视觉感知的关键传感器,其采集的图像被应用于自动驾驶系统。在智能座舱域中,同样需要一个前视摄像头来捕获图像,以实现行车记录仪的功能。若能实现舱驾融合,自动驾驶SoC可先处理车载前视摄像头的图像信息,随后通过PCIe总线将其传递给智能座舱SoC,从而实现资源的共享使用。对于智能座舱域而言,这不仅能节省一颗摄像头的成本,还能减少ISP的开销。类似这种算力共享的应用场景不胜枚举,从成本降低的角度来看,舱驾融合具有显著的实用价值和广泛的客户需求。 1. 自动驾驶系统分级
在深入探讨舱驾融合的功能之前,我们先来简要回顾一下自动驾驶的功能及其所需的硬件架构。首先,我们需要明确一个概念:目前所谓的自动驾驶技术,实际上仍属于高级辅助驾驶系统(ADAS,Advanced Driver Assistance Systems)的范畴,在自动驾驶等级中位于L3级别以下。根据ADAS功能的不同,业界各厂家通常将自己的产品定位为从L2级别到L2+++级别。对于自动驾驶等级的划分,业界已达成一定的共识,具体如表4所示。 | | | | | | |
| | | | | | |
| | 通过驾驶环境对方向盘和加减速中的一项操作提供支持,其余由人类来做 | 通过驾驶环境对方向盘和加减速中的多项操作提供支持,其余由人类来做 | 由无人驾驶系统完成所有的操作,根据系统要求,人类提供适当的应答 | 由无人驾驶系统完成所有的操作,根据系统要求,在限定道路和环境条件下,人类不一定提供适当的应答 | 由无人驾驶系统完成所有的操作,不限定道路和环境条件,人类无需提供应答 |
| | | |
| | |
| | |
| | | |
表4为我们讨论自动驾驶提供了分级的参考依据。我们必须认识到,目前的自动驾驶系统仍处于L3级别以下,还无法保证完全实现有条件的自动驾驶目标。当讨论L2+++级别的自动驾驶系统时,我们需要对其进行分解,以便更清楚地了解在哪些具体情况下可以实现舱驾一体化。 | | | | | | |
| | 这是一种通过车载传感器感知前方车辆的距离和速度,自动调节车辆的巡航速度,与前车保持安全的距离的技术 | | | | |
| | 这是一种通过车载摄像头或雷达监测车辆的位置,并向驾驶员发出警告或主动纠正方向盘,确保车辆不偏离所在车道的系统 | | | |
| | 通过雷达和摄像头等传感器实时监测车辆周围的环境和障碍物,在侧方和后方安全范围内为驾驶员提供提醒和警告,以辅助驾驶员进行安全变道 |
| | |
| | 通过车辆上的传感器和高级算法,自动驾驶系统可以实时检测周围的交通状况,并判断是否可以安全地进行变道。如果条件允许,ALC系统会自动进行转向操作,辅助车辆完成变道。 |
| | |
| | 该系统通过摄像头识别交通标志和限速标志,并发出提示信息 |
| | |
| | 一种在交通拥堵情况下自动控制车辆行驶的技术,包括加速、减速、转向等操作。 |
| | |
| | 在城市道路上,UDS可以通过感知周围环境,提供辅助驾驶功能,如自动避障、自动识别行人等。 |
|
| |
| | 通过传感器监测驾驶员的生理状态,如疲劳、酒驾等,并在必要时发出警告 | | | | |
| | 通过传感器来时刻监测前方车辆,判断本车与前车之间的距离、方位及相对速度,当存在潜在碰撞危险时对驾驶者进行警告。 | | | |
| | 该系统通过雷达或摄像头检测车辆盲区内的物体,并在侧后视镜上显示警示标志或声音警告 |
| | |
| | LDW系统提供智能的车道偏离预警,在驾驶员无意识(未打转向灯)偏离原车道时,发出警报 | | | |
| | 是基于环境感知传感器,如毫米波雷达或摄像头来感知前方可能与车辆、行人或其他交通参与者发生的碰撞风险,并通过系统自动实施制动的主动安全技术 | | | |
| | 一种典型的L2级别功能,它可以监测车辆四周的影像,并利用图像畸变还原、视角转化、图像拼接、图像增强等技术,形成全车周围的一整套视频图像,让驾驶员清楚查看车辆周边是否存在行人、移动物体、非机动车、障碍物并了解其相对方位与距离。 | | | | |
| | 利用车载传感器(一般为超声波雷达或摄像头)识别有效的泊车空间,并通过控制单元控制车辆进行泊车 |
| | |
| | 在APA自动泊车技术的基础之上发展而来的,可以通过手机遥控实现泊车入位,它解决了停车位狭窄,难以打开车门的问题 |
| | |
| | HPP通过车辆的传感器来学习、记录、储存我们平常上下车的位置、停车的操作、停车行进路径以及停车固定位置等,然后当我们再次驾车到达这些地点时,可以实现车辆自动泊入终点附近已被HPP系统记忆的车位 |
|
| |
| | AVP代客泊车功能主要依赖于传感器、通信技术等,通过这些技术,车辆可以在不需要驾驶员干预的情况下,自动寻找停车位,并进行泊车。当驾驶员需要取车时,只需要通过手机等设备发出指令,车辆就会自动从停车位驶出,并停到指定的位置。 |
|
| |
从表5可以看出,入门级的L2 ADAS系统能满足最基础的辅助人类驾驶员操控汽车的任务。它的主要作用是缓解驾驶员的疲劳,并为驾驶员提供必要的警告信息,从而有助于减少事故和意外的发生。NOP(Navigate On Pilot)指的是在导航辅助的情况下,车辆可以根据导航路径自动巡航行驶,这包括自动进出匝道、自动调整车速、智能变换车道等功能。NOP系统依赖于高精度地图、导航系统以及各种车载传感器来实现这些功能。NOA(Navigate on Autopilot)则更注重在整个驾驶过程中的自动化和智能化。与NOP相比,NOA在功能上可能更加全面和高级,它包括自动泊车、自动变道、自动超车、自动巡航等多种功能,并且能够根据道路信息和交通状况做出更加智能的驾驶决策。一般来说,NOA不依赖高精地图,可以通过车载传感器自主感知、决策和规划,实现城区道路的自动驾驶,而NOP则通常只能在高速道路上应用。2. ADAS系统对硬件资源的依赖
根据入门级L2系统、NOP系统和NOA系统在功能上的不同划分,它们对硬件资源的需求也各不相同。表6展示了这三类ADAS系统所依赖的硬件资源条件。需要注意的是,由于各厂商采用的自动驾驶算法不同,对ADAS系统的理解也有所差异,因此他们在硬件资源的选择上也会有所不同。所以,这个表格中所列举的情况并不能适用于所有厂商,仅作为参考。 | | | | |
| | | | |
| | | |
|
| | |
|
| | |
| | | | |
|
| | |
|
| | |
| |
|
| |
| |
|
| |
| | | | |
| | | | |
| | | | |
|
| | | 11V5R1L(11个摄像头+5个毫米波雷达+1个激光雷达) |
从表6可以明显看出,根据所需实现的目标不同,ADAS系统的硬件资源需求也会有所不同。若我们考虑实现舱驾一体化,那么就需要深入探究在不同目标下如何实现舱驾的有效融合。具体来说,各种目标对于NPU算力的需求、接入摄像头的数量,以及是否需要激光雷达的支持等方面都存在显著差异。而这些硬件需求上的差异,进一步导致了整个系统架构的多样性。3. 舱驾一体化架构探讨
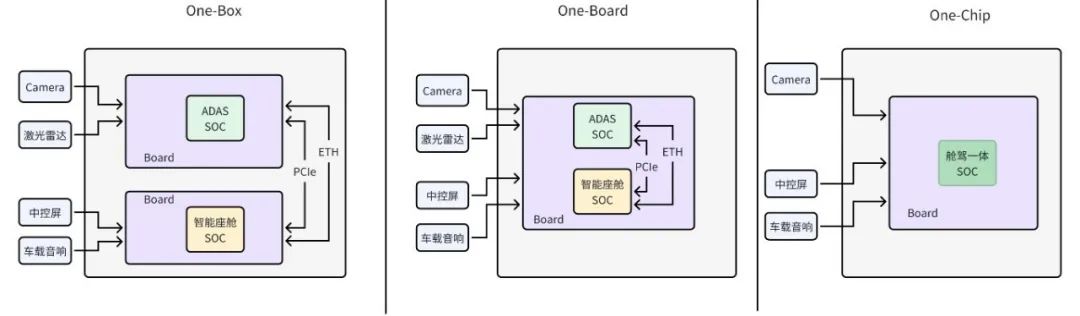
一般来说,舱驾一体化分为“One-Box”,“One-Board”,“One-Chip”这三种不同的架构,如图6所示。从图6可以看到,在上述三种架构中,“One-Box”方案实际上是将座舱域控制器与自动驾驶系统域控制器集成到单一的ECU内,这样做不仅有助于减少外部线束的使用,还能在一定程度上达成算力的共享。“One-Board”方案则是将自动驾驶SoC与智能座舱SoC集成在同一块电路板上,进而能够减少电路板和外围电子元器件的数量,进一步削减了硬件成本。而“One-Chip”方案,则将两颗SoC芯片整合为一颗。这种方案,虽然从表面上看似能最大程度地节省成本,但它高度依赖于高算力芯片的研发,同时还需要在软件层面确保两个域之间的安全隔离。因此,对于以上3种技术架构,我们仍然需要进行进一步的技术分析。以“One-Chip”方案为例,我们对舱驾融合的技术可行性进行初步分析。智能座舱域和自动驾驶域对算力的需求各不相同。智能座舱主要负责多媒体处理任务,因此对CPU、GPU、NPU、DPU和VPU等算力资源的需求颇高。相较之下,自动驾驶域的主要计算任务则聚焦于视频采集的图像处理和深度计算,它依赖于CPU、ISP和NPU的算力资源。若要在单一的SoC芯片上同时满足这两个领域的需求,就必须在算力、带宽、外设接口、内存以及能效比等多个维度上进行全面的权衡与考量。由此可见,设计一款能同时应对智能座舱域和自动驾驶域需求的SoC芯片,无疑是一项艰巨的挑战,需要全方位地综合考虑诸多因素。根据HARA分析的结果,智能座舱域和自动驾驶域在功能安全需求上存在显著差异。具体而言,智能座舱域中仅有少数功能需满足ASIL-B级别的安全标准,而自动驾驶域的大部分功能则必须达到更高的ASIL-D级别安全标准。这就要求SoC在设计时需更加重视安全因素,如电源域隔离、安全岛设计、双核锁步架构以及内存故障检测等。此外,在软件设计层面,为实现智能座舱域和自动驾驶域之间的功能隔离,需引入Hypervisor虚拟机技术和内存访问隔离机制等软件层面的安全措施。 在舱驾一体化的需求驱动下,SoC厂商不可避免地需要更深入地涉足自动驾驶算法的开发工作。在分布式域控制器时代,自动驾驶系统的SoC供应商仅负责供应SoC芯片及基础软件,例如操作系统和深度学习框架等。以英伟达为例,其仅需提供Orin(英伟达第3代ADAS SoC)芯片和DRIVE OS(英伟达自研操作系统),而自动驾驶算法的开发则可由主机厂独立完成,或由算法Tier1厂商来提供。然而,随着舱驾一体化时代的到来,座舱系统与自动驾驶系统实现了深度融合,这就要求SoC厂商必须为客户提供全方位的软硬件解决方案。因此,SoC厂商需要自主研发自动驾驶算法,或采用深度定制的方式来满足客户需求。这无疑增加了舱驾一体化的实施难度。主机厂推行舱驾一体化的核心目的在于降低成本。然而,根据表15-6所示,不同级别的自动驾驶系统对硬件资源的需求是存在差异的。以当前顶级的自动驾驶SoC为例,其单颗芯片并不能满足NOA(导航辅助自动驾驶)的要求。因此,期望通过单颗芯片实现舱驾一体化是不切实际的。更为可行的方案是采用能满足入门级L2自动驾驶需求的舱驾一体化单芯片。由于采用入门级(L2)自动驾驶系统的车辆主要面向中低端市场,因此其售价不会过高。这一市场定位又进一步限制了舱驾一体化芯片的成本空间。换言之,成本过高的舱驾一体化芯片将难以被市场接受。4. 舱驾一体化的尝试
目前,英伟达和高通两家公司已在舱驾一体化领域展开了初步的探索,试图在这一方向上寻求突破。英伟达推出的舱驾一体化芯片名为“Thor”。这款芯片在单颗芯片上能提供高达1000TOPS的深度学习算力(专为自动驾驶系统设计)或9200GFLOPS的GPU算力(适用于智能座舱系统)。其实现舱驾一体化的方式是通过将GPU内部的三个GPC(Graphics Processing Cluster,图形处理集群)单元进行分隔使用。若要实现L2级别的ADAS系统与座舱系统的融合,“Thor”芯片会将两个GPC单元分配给ADAS系统,而将一个GPC单元分配给智能座舱系统。这样,ADAS系统可获得600TOPS的算力,而座舱系统则享有3700GFLOPS的算力。 高通公司则推出了名为SA8775的舱驾一体化芯片。该芯片在智能座舱SoC芯片的基础之上,强化了安全岛的设计并提升了NPU的算力。其实现舱驾一体化的原理是通过Hypervisor虚拟机进行隔离,从而将系统划分为座舱域和自动驾驶域两大部分。在Hypervisor之上,ADAS系统在支持实时操作系统的虚拟机中运行,负责处理摄像头和人工智能计算等任务。而智能座舱系统则在Android虚拟机中运行,负责处理座舱域的相关任务。从功能角度来看,SA8775所支持的ADAS等级并不算特别高。总的来说,单芯片的舱驾一体化技术目前仍处于探索阶段,一些芯片厂商已将其视为实现业务差异化的创新点。而在实际使用中,基于中央计算平台架构(实际上等同于“one-box”或者“one-board”)的舱驾一体化技术已经投入运行。本文对智能座舱的演进道路进行了深入的思考和系统的推理。在汽车智能化浪潮的推动下,为了满足人们日益增长的出行需求和舒适度要求,同时也为了应对激烈的市场竞争,各种新技术层出不穷,并被广泛应用于智能座舱的设计与制造中。我们深刻地认识到,市场需求是推动技术不断进步的核心力量,也是激发创新思维的源泉。正因如此,智能座舱的演进旅程尚远且充满变数,其最终的发展形态在现阶段仍然难以预见。我们相信,在未来的探索与发展中,智能座舱将以更加人性化、智能化和多样化的面貌呈现在我们面前。 张慧敏,蔚来汽车数字架构部智能座舱架构设计师、西安交通大学硕士。深耕嵌入式软件与智能手机芯片架构设计多年,已获专利授权15项。曾任紫光展锐芯片架构设计师,主导5G手机芯片及新能源汽车智能座舱系统架构设计,拥有丰富的实战经验。同时,他积极分享专业知识,于知乎平台开设“智能座舱架构与芯片”专栏,撰写多篇科技文章,广受业界好评。