近年来,人工智能(AI)广泛普及,迅速成为了一项变革性技术。AI依托于机器学习(ML)算法,而这需要消耗大量算力。传统上,开发者依靠图形处理单元(GPU)来执行这些ML算法。GPU最初专为图形渲染而开发,事实证明,它非常适合执行机器学习的矩阵和矢量运算。然而,AI硬件领域正在发生巨大变化。计算要求越来越复杂,高能效需求日益显著,在这样的环境下,专门从事特定领域AI处理器的初创公司纷纷涌现。这些初创公司正在开发专用AI处理器,其架构针对ML算法进行了优化,与通用GPU相比,效能功耗比实现了显著提升。
随着AI技术的不断发展,对更强算力和更高能效的需求将持续增长。根据Semianalysis的分析,预计到2028年,AI数据中心的电力需求将超过非AI数据中心,占全球数据中心电力消耗的一半以上,而目前这一比例还不到20%(图1)。
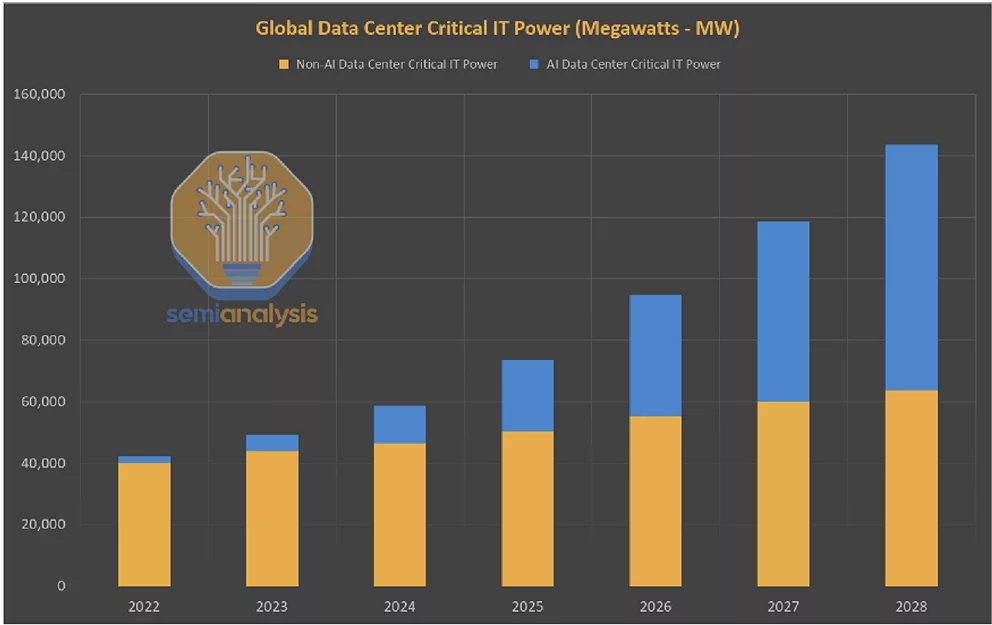
▲ 图1 AI数据中心和非AI数据中心的电力需求趋势
数据中心行业正在努力减少电力需求,逐步摒弃传统的空气冷却系统,转而采用成本较高但效果显著的液冷技术。然而,仅仅依靠外部冷却技术的进步是不够的。为了应对不断攀升的电力需求,AI硬件开发者还必须在系统设计层面进行创新,探索更全面的电力优化途径。

新思科技基础IP如何实现低功耗开发
开发片上系统(SoC)时,开发者可以优化各个阶段设计的功耗,包括架构层面、实现层面和底层技术层面等。新思科技基础IP可以帮助开发者定位目标领域(图2)。SoC的功耗主要源于电路切换引起的动态功耗以及漏电功耗(或静态功耗)。动态功耗在处理器执行指令工作负载时产生,与CV^2f成正比,这里的C表示被充放电的电容,V表示工作电压,f表示电路时钟频率。无论处理器处于空闲还是活跃状态,都会产生漏电功耗,并且随阈值电压、晶体管尺寸和温度而变化。在架构层面,可通过采用电源门控、动态电压频率调整(DVFS)等电源管理技术来降低整体功耗。在实现和工艺技术层面,设计优化以及对逻辑单元和嵌入式存储器工作条件的精细管理会直接影响功耗。让逻辑单元和存储器在维持所需性能的同时,尽可能在更低电压下工作,同时借助专用单元减少活跃节点上的电容,都大大有助于降低功耗。
凭借多代基础IP优化积累的丰富经验和深厚实力,新思科技在AI SoC的功耗优化中扮演着关键角色。新思科技基础IP提供的先进解决方案,包括经过高度优化和验证的逻辑库、通用输入输出(GPIO)和嵌入式存储器。凭借丰富的单元集,新思科技协同优化逻辑库和IO与电子设计自动化(EDA)工具,充分利用工艺技术的优势,实现了功耗、性能和面积(PPA)的更优平衡。新思科技存储器集成了针对ML算法的关键特性,大大缩小了AI芯片的面积,节省了大量功耗。
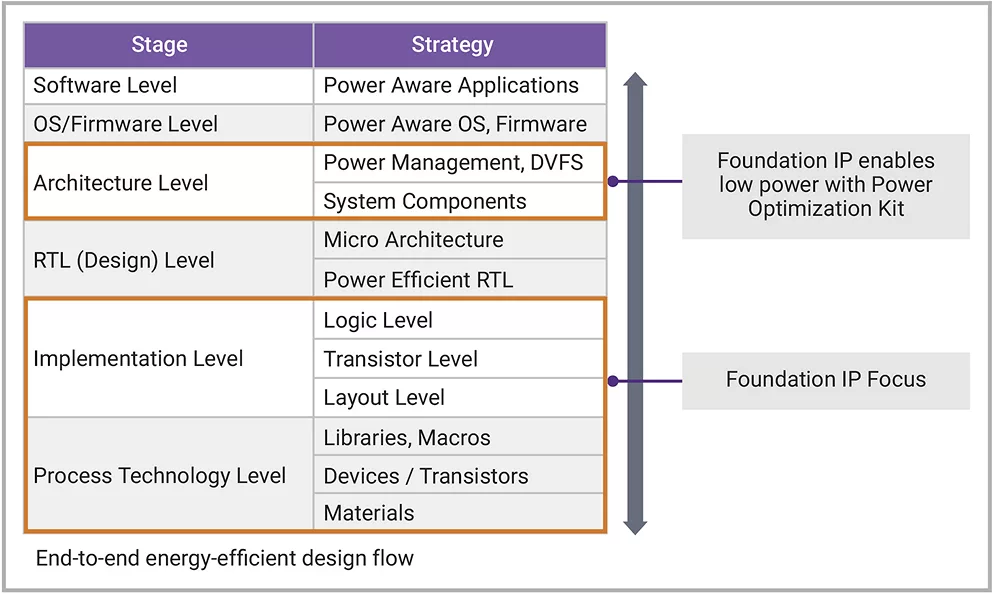
▲ 图2 端到端高能效设计流程
接下来我们将深入探讨新思科技基础IP如何帮助降低功耗,特别是AI处理器的功耗。
能够与新思科技存储器实现间距匹配的专用逻辑单元:在AI处理器中,无论是训练还是推理任务,大量的计算活动(70-90%或更多)都用于乘积累加(MAC)运算,这是矩阵乘法和卷积的基础。新思科技提供的逻辑库包含AI处理器专用的复杂逻辑,支持MAC功能。这些单元具备融合乘加能力等特性,有助于减少设计的净长度和整体电容,从而显著降低动态功耗。对于AI芯片而言,集成高能效存储器同样重要。在ML模型中,特别是在推理任务中,参数权重存储在存储器中,MAC单元会频繁访问相关内容以进行计算(图3)。新思科技协同优化了存储器和逻辑单元物理布局的尺寸和间距,使得二者相互协调,从而提供与MAC单元间距匹配的嵌入式存储器,这种集成设计策略缩短了互连的布线长度,在这类特定应用中已证明能减少33%的功耗。
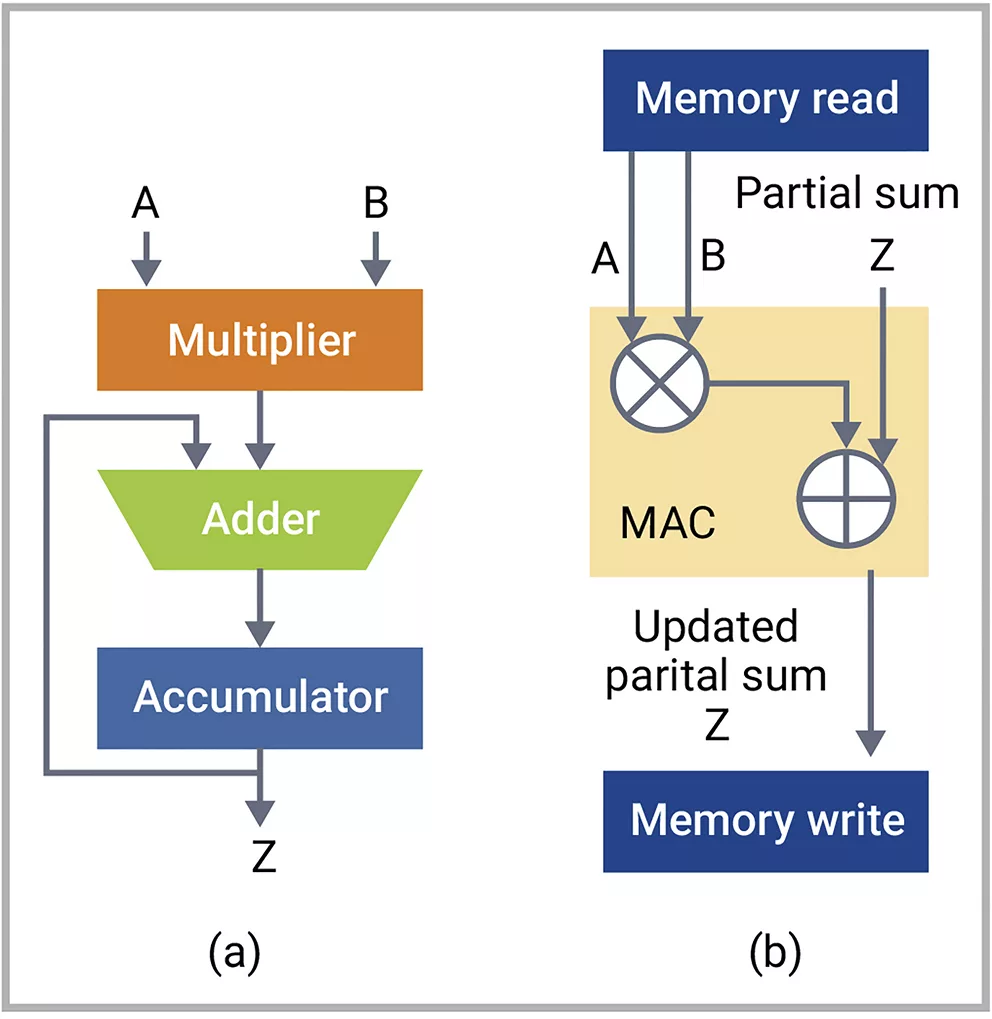
▲ 图3(a)MAC单元框图;(b)MAC单元的存储器读写
可定制的超低电压库:设计在超低供电电压下(特别是0.5V以下)运行的芯片极具挑战性,需要非常谨慎的设计和验证。但低供电电压会带来巨大的功耗收益,因为动态功耗与供电电压的平方成正比,降低电压将能大幅减小功耗。AI处理器通常依靠海量并行任务来提高性能。新思科技通过其可定制的超低电压逻辑库来实现低功耗芯片设计。这些库基于详尽的高质量验证,采用先进的特征分析技术,在广泛的工艺、电压和温度(PVT)条件下进行测试。低电压设计会导致降低噪声裕量和增加对制造误差的敏感度。当供电电压较低时,信号对电路下一阶段状态的驱动能力下降。此时信号会表现为脉冲状,通过电路传播的时间更长。这种延迟会影响电路的关键时序参数,包括建立时间和保持时间。为解决这个问题,新思科技基础IP开发者综合考虑了更多因素,例如轨到轨脉冲检查、针对片上误差(OCV)的额外时序裕量、保持时序的高sigma要求以及时钟斜率建议。芯片单元会经过高sigma蒙特卡洛仿真以进行鲁棒性验证,并谨慎使用基于矩的库误差格式(LVF)可对制造误差的概率性质进行精确而详细的建模(图4)。
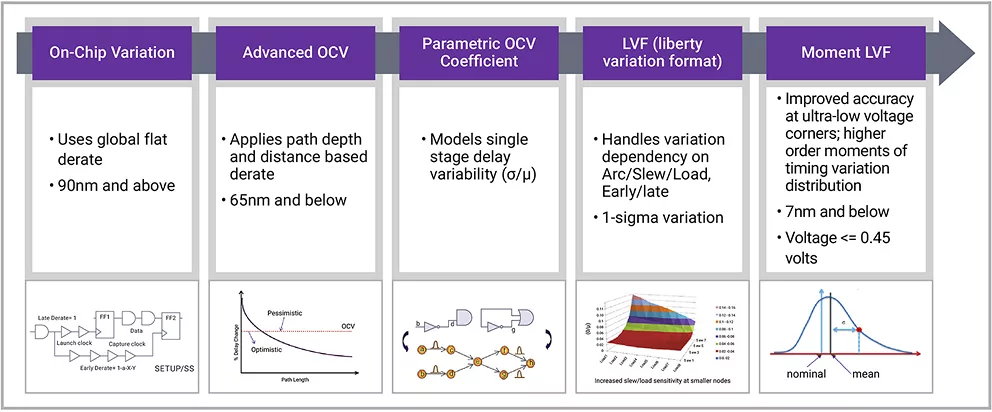
▲ 图4 低供电电压下片上误差的复杂性不断增加
具有驱动力分级的逻辑单元:驱动力高的逻辑单元拥有更大的尺寸,因此功耗更大,其漏电流也往往更高。对于非关键路径,我们已经使用高电压阈值(VT)单元优化了功耗,通过使用具有驱动力分级的单元来进一步降低功耗。新思科技逻辑库组合包括一系列这样的驱动力分级单元,包括驱动强度小于一的单元。
功耗优化套件:为了进一步降低功耗,新思科技在其标准单元平台中提供功耗优化套件(POK)。该套件包括各种专用逻辑单元,旨在实现先进的电源管理技术。其中的电源开关和隔离单元在不用时会开启模块关闭功能,从而帮助降低静态功耗;该套件还包括电平转换器,可根据性能要求让不同模块在不同的电压下运行,从而帮助降低动态功耗。此外,POK还具有隔离单元、保持触发器和电平转换器的多位变体,可帮助减小净长度和整体单元面积。
超低漏电IO:在具有AI芯片的SoC中,片上组件虽然在低电压下运行,但需要连接到运行电压更高的片外组件。支持这种电压差的GPIO设计极具挑战性,大多数公司都会采用电平转换器,而这会带来不必要的面积和功耗。新思科技提供一套全面的超低漏电IO,支持低至0.5V的电压。这些IO还支持1.8V IO供电,提升了整体系统可靠性。含有AI芯片的SoC尺寸也更大,需遵循严格的静电放电(ESD)保护标准。新思科技提供的IO解决方案具有强大的ESD保护功能,能够处理高达CDM 7A的电流,进而有助于实现更高效、更可靠、更具成本效益的AI SoC设计。
非易失性存储器和基于锁存器的存储器:新思科技提供丰富的先进存储器解决方案,包括嵌入型磁阻式随机存取存储器(MRAM)和电阻式随机存取存储器(RRAM),其密度明显高于传统SRAM。对于训练数据存储等以读取为主的应用,用MRAM或RRAM替代SRAM或片外DRAM可以显著提高系统级PPA。这些非易失性存储器(NVM)缩小了芯片面积并减少了所需的组件数量。此外,与DRAM不同,这些器件无需持续供电来维持数据状态,因此无需频繁刷新周期,从而降低了静态功耗并减少了漏电流。新思科技还提供基于锁存器的存储器,可以为较小的内存实例节省大量空间。这些对于需要许多小内存实例的特定AI功能(如激活和池化)来说特别有用。此外,新思科技还提供专门的多端口存储器,可同时处理多个内存访问请求,有助于缓解内存瓶颈并提高整体性能。
存储器的稀疏性和转置支持:在许多ML模型中,有相当一部分的计算数据是零值字,在读/写操作期间会跳过它们,从而达到省电的效果。为了利用这种数据稀疏性,新思科技在其存储器中推出了一项创新功能WAZ(Word All Zero),通过检测并跳过零值,此功能可降低60%的功耗。此外,新思科技还开发了一种以转置格式将数据存储在存储器中的方法。这意味着要在存储器中对齐矩阵单元,以匹配计算过程中的访问模式。因此,矩阵运算的执行速度更快,在节能的同时,还提高了整体效率。
总结
随着应用要求和AI技术的发展,开发算力强大且节能的AI处理器已成为普遍需求。无论是基于GPU的传统架构,还是一些不断发展优化的AI架构,都在将能效曲线推向极限,为支持CPU和前几代GPU而优化的传统库和存储器产品已无法满足当今严苛的AI SoC设计需求。新思科技作为基础IP领域的佼佼者,20多年来秉承创新精神,始终致力于优化PPA,持续推出专业解决方案,以应对半导体行业错综复杂的设计挑战。在强大研发团队和杰出应用开发者的双重助力下,新思科技利用其在逻辑库、IO和嵌入式存储器方面的专业知识,提供一系列出色的可调解决方案,从而全方位增强AI芯片的性能。
如需了解更多信息,请扫描下方二维码联系我们