

现在最前沿、最被学界追捧、被产业界寄予厚望的自动驾驶技术,是什么?
地平线创始人余凯博士最新的朋友圈揭晓了答案:

Vision Mamba,全球年度AI论文高引TOP 3,也被认为是Transformer最强挑战者——Mamba架构在视觉领域的“飞跃式”进展。
背后核心团队,和端到端开山之作UniAD一样,来自华中科技大学和地平线的联合。
Vision Mamba首发于机器学习顶会ICML 2024,截至目前根据谷歌学术的数据,一共被引用865次。
横向来看,2024一整年内arxiv一共收录了超过40000篇AI相关论文,而其中被引用次数最高的是Meta的Lama 3,被称为“阻击GPT4”的最强开源大模型,它的引用次数为1690次。
第二名引用次数超过1100次,是来自Mixstral AI的Mixstral 8x7B模型。
Vision Mamba位列Top 3。
目前在Github上Vision Mamba项目已经收获3100星:
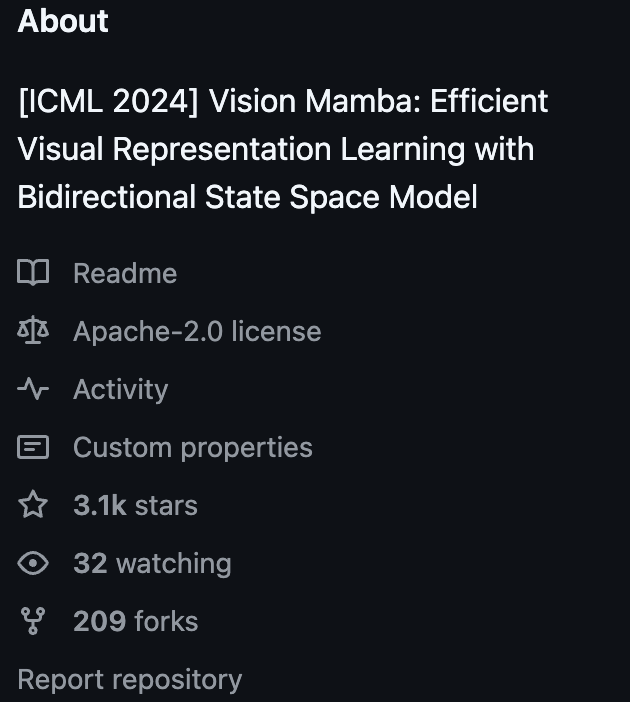
同时也引起了热议并获得极高评价。
比如有很多AI学者在Medium上发文解析Vision Mamba,给予的评价包括但不限于:“视觉表征学习的最新飞跃”、“比ViT(ransformer)更强”等等。

有人认为Vision Mamba会改变整个计算机视觉的游戏规则,因为Vision Mamba迭代更快、模型更小、计算资源占用更小,同时还有不可思议的高性能…

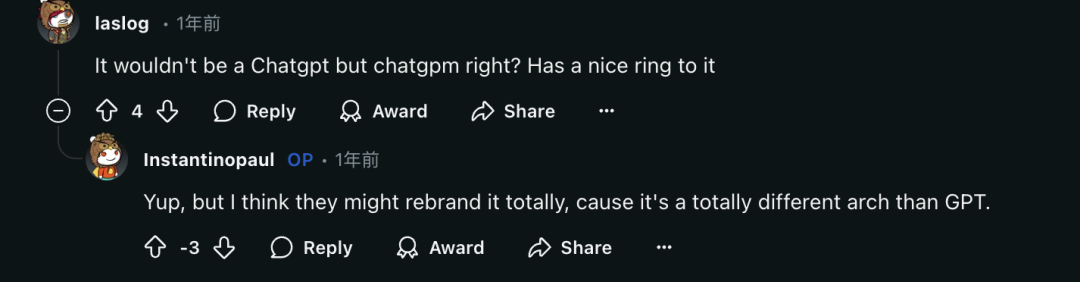
甚至有人认为,ChatGPT(ransfoemer),以后说不定会被ChatGPM(amba)取代:
当然也有人提出客观质疑,比如Vision Mamba终极价值考量应该是能否扩张到万亿参数、后续能否支持多模态:

为什么Vision Mamba本身能在1年时间内快速成为被频繁引用成果,并同时引起广泛讨论,其实已经有网友一针见血:
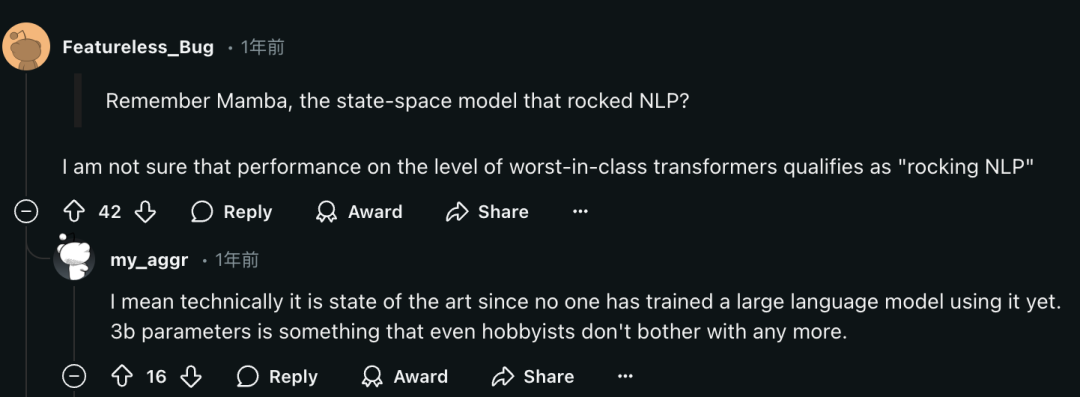
从纯技术角度看,Mamba架构首次应用到大语言模型,就震撼了整个NLP领域。
而Vision Mamba,则是业内首个Mamba架构在计算机视觉领域的通用主干网络模型。
搞明白Vision Mamba厉害在哪的前提,还需要快速科普一下被称为Transformer终结者的Mamba架构。
2023年底,Mamba架构由FlashAttention作者Tri Dao和CMU助理教授、Cartesia AI联合创始人及首席科学家Albert Gu在去年年底提出:

初衷是为了解决Transformer架构大模型的痛点:处理长文本算力消耗巨大,因为Transformer的关键操作机制包括先用查询向量和键向量相乘得到nxn的矩阵,再对得到的矩阵归一化,最后在乘以分数。
所以复杂度主要取决于输入序列长度,且是2次方指数关系:
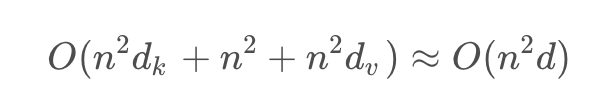
Mamba核心能力来自状态空间模型(SSM)的一个变种S4,通过状态变量对动态系统进行建模,能够捕捉系统状态随时间的变化以及观察到的数据与这些状态之间的关系,不再依赖线性输入。
Mamba其实是将SSM集成进了一个简化的端到端神经网络架构中,不需要注意力机制,甚至也不需要MLP(多层感知器)模块,快速推理方面表现出色(比Transformers高5倍的处理速度),并且随着序列长度的增加,其性能线性增长,在处理长达百万长度的序列时表现更佳。
自然而然,Mamba在视觉领域的应用被高度关注。但由于 Mamba 特有的架构,需要解决两个挑战,即单向建模和缺乏位置感知。
为了应对这些问题,研究者提出了 Vision Mamba (VIM) 块,它结合了用于数据依赖的全局视觉上下文建模的双向 SSM 和用于位置感知视觉识别的位置嵌入。
Vision Mamba的基本框架是这样:
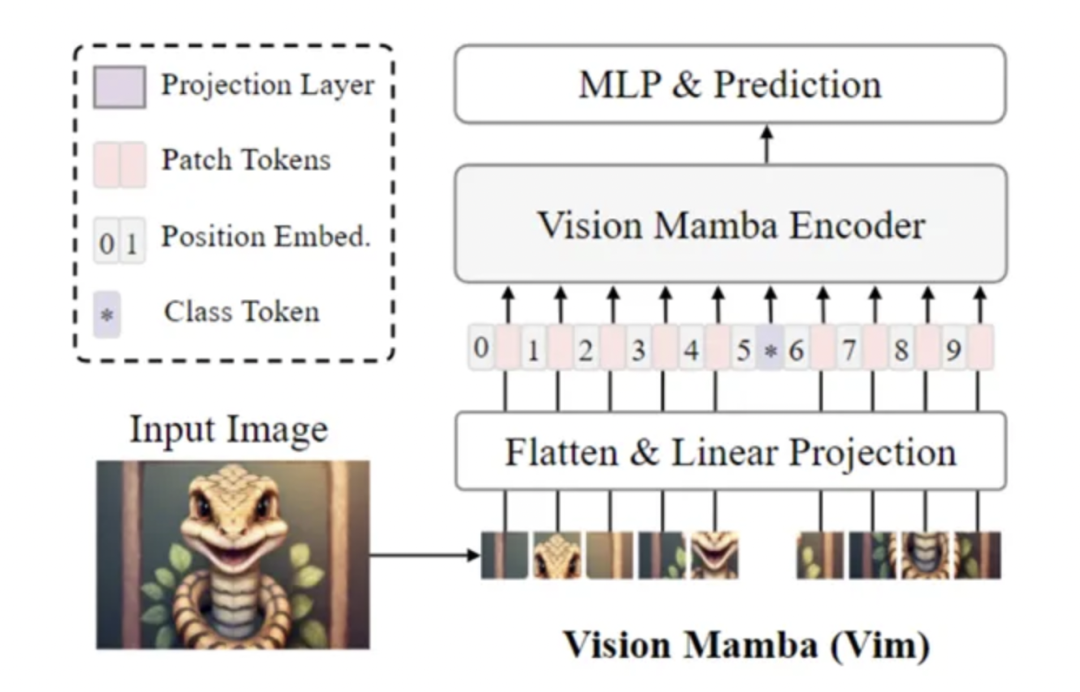
首先将图片变成一个个图块,并神经网络的Flatten(2D变1D)以及映射方式将其变成向量,并加上位置嵌入。而最后放入VIM块中即完成。

应该也发现了,这个架构中最重要的就是这个Vision Mamba block!
让我们简单看看这个块具体有啥用。
VIM编码器结构是这样:
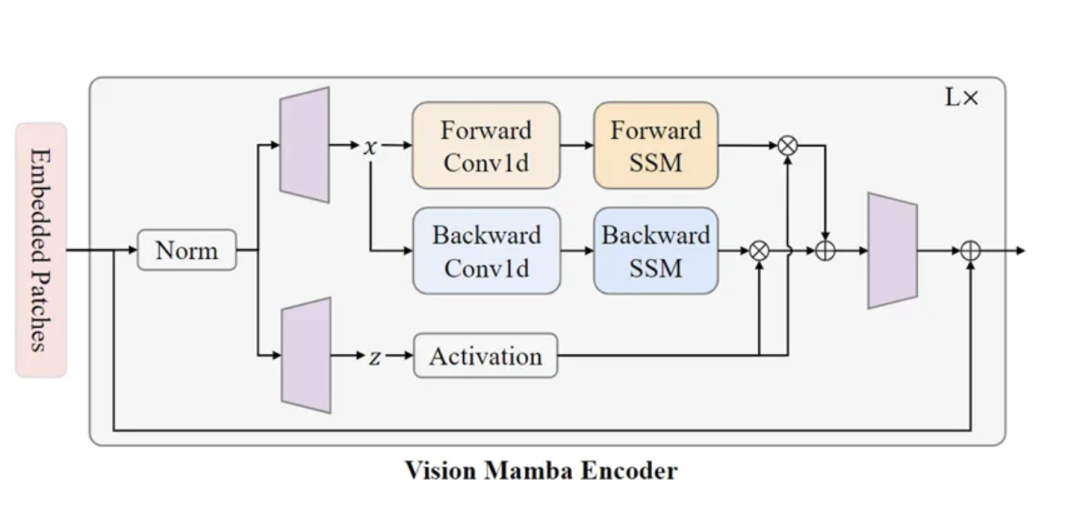
大致上与Mamba本身相同,但仍有创新。
因为原生的Mamba本身是为了处理文字,只能处理一维向量的序列。但是在视觉任中,模型需要具备空间感知理解的能力。
因此研究团队在模型中加入双向SSM,从图像的不同方向捕捉信息,提供更全面的空间采集能力。
而演算具体进行流程如下:

此外,VIM块中的位置嵌入提供了对空间信息的感知,使VIM在密集预测任务中具有更强的鲁棒性。
以往基于SSM的方法会用傅立叶转换加速卷积,但在Mamba 模型中,并非每个部分都会与卷积等价(如算法 1 第 11 行),并不能用同样的方式实现加速。
所以作者提出了三个用于加速的方法
首先是IO 效率。在GPU里面有HBM 与 SRAM 两个重要的元件,而这部分的加速主要是减少从 HBM 到 SRAM 的 IO 过程。
第二是内存效率,意思是使用训练到一半的中间状态来计算中间值,思路与原生Mamba相同。
最后是计算效率,可以用一张图、一切两行式子说明:
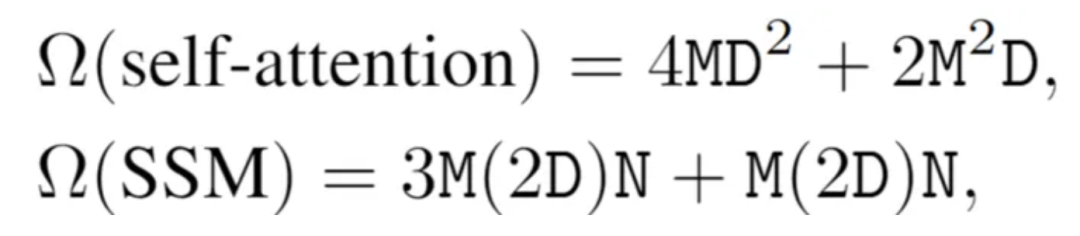
其实不难发现,Vision Mamba的基本思路不复杂,就是将传统的 ViTs 中Transformer主导的注意模力块换成Mamba主导的VIM块,并以此做相应的适配处理。
有点像张无忌,吸收各派武功精髓,融汇贯通成自家绝学。
在 ImageNet 分类任务、COCO 对象检测任务和 ADE20k 语义分割任务上,与 DeiT 等成熟的视觉 Transformers 相比,VIM实现了更高的性能,同时还显著提高了计算和内存效率。
例如,在对分辨率为 1248×1248 的图像进行批量推理提取特征时,VIM 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存:
总结一下,Vision Mamba突破之处,在于利用双向状态空间模型 (SSM) 进行全局视觉上下文建模和位置嵌入,标志着对传统注意力机制路径依赖的突破。
这种方法同时实现了算法对视觉数据的位置上下文的掌握理解,以及对计算资源的高效利用。
正是因为Vision Mamba展现出的特性,才让它有希望彻底改变实时视频数据分析和大规模图像处理等任务——也就是自动驾驶的核心挑战。
本文共同一作朱良辉、廖本成,都是华中科技大学电子信息与通信学院博士生在读。
Qian Zhang和Xinlong Wang 则分别来自地平线和北京智源研究院。
本文通信作者王兴刚博士,是一作朱良辉、廖本成的导师,国内计算机视觉领域近年冉冉升起的学术新星。

王兴刚主要从事基础模型、视觉表征学习、目标检测分割跟踪等领域研究、在IEEE TPAMI、IJCV、CVPR、ICCV、NeurIPS等顶级期刊会议发表学术论文60余篇,谷歌学术引用2.7万余次,入选Elsevier 2023中国高被引学者。担任CVPR, ICCV, ICIG等会议领域主席等等。
被誉为端到端视觉大模型源流,深刻影响国内、全球自动驾驶技术、商业发展的UniAD,一作同样出自王兴刚博士的Vision lab团队,也同样是和地平线、商汤这样的顶尖AI玩家合作成果。
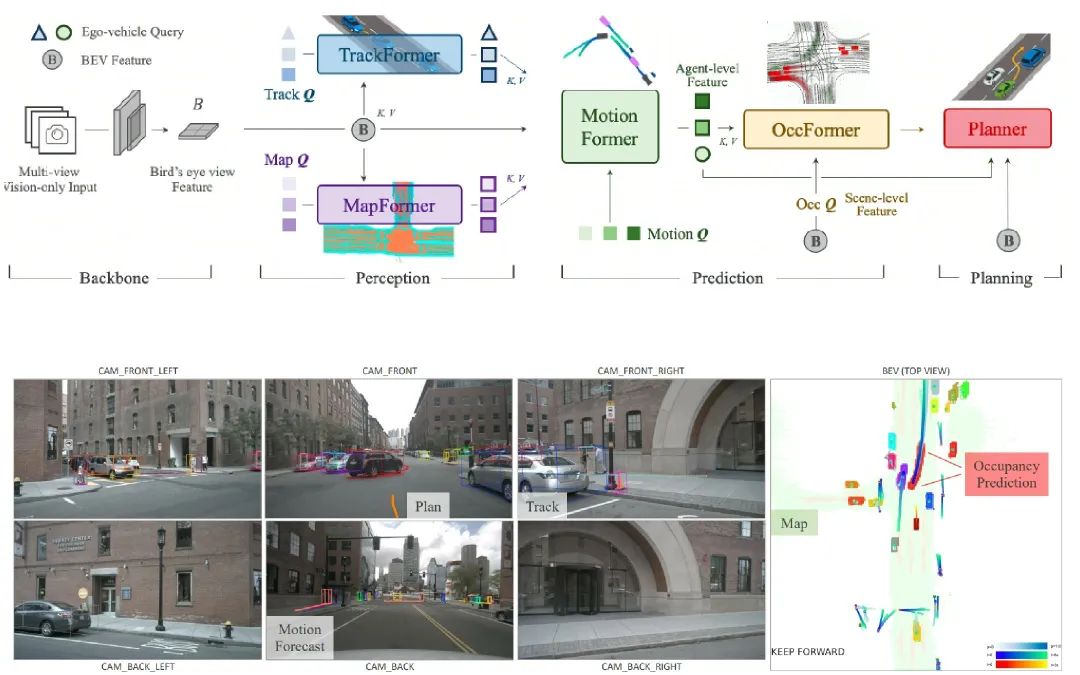
其实,Mamba架构应用在视觉领域有不少尝试,但Vision Mamba的是首个通用型架构,意义不止自动驾驶。
它展现的思路和优秀性能,可能鼓励全AI行业探索神经网络架构的进一步升级创新,尤其是对于专门的数据类型。
从这个角度看,从之前的UniAD到现在的Vision Mamba,华科、地平线在计算机视觉、自动驾驶领域已经走到最前沿,接连实现硬核技术的开天辟地,以及成果快速转化落地。
论文地址:https://arxiv.org/abs/2401.09417
Github项目地址:https://github.com/hustvl/Vim
— 联系作者 —

— 完 —
智能车2024年度评选结果
在经过广泛征集、专业推荐,以及智能车参考垂直社群的万人票选后,智能车2023年度评选结果正式发布。涵盖三类奖项:
· 十大智能车领军人物
· 十大智能车车型
· 十大智能车技术方案/产品
在汽车工业迎来百年未有之大变局时,我们希望能以此提供智能维度的参考和注脚。
其中,十大智能车技术方案/产品是:
<< 左右滑动查看更多>>
— 完 —
【智能车参考】原创内容,未经账号授权,禁止随意转载。
点这里👇关注我,记得标星,么么哒~











