AI 查询引擎可高效处理、存储和检索大量数据,以增强生成式 AI 模型的输入。

数据是 AI 应用的燃料,但企业数据的量级和规模往往会使其使用成本高且耗时,难以有效利用。
根据 IDC 的 Global DataSphere1,到 2028 年,企业每年将产成 317ZB 数据——包括 29ZB 的独特数据——其中 78% 是非结构化数据,44% 为音频和视频数据。由于数据量巨大且类型多样,大多数生成式 AI 应用只会使用所存储和生成数据总量的一小部分。
为了在 AI 时代蓬勃发展,企业就必须找到利用其所有数据的方法。这一点无法依靠传统的计算和数据处理技术来实现。相反,企业需要一个 AI 查询引擎。
什么是 AI 查询引擎?
简而言之,AI 查询引擎是将 AI 应用或 AI 智能体与数据连接的系统。它是代理式 AI 的关键组成部分,充当企业或机构知识库与 AI 赋能的应用之间的桥梁,能够实现更准确、具有上下文感知的响应。
AI 智能体构成 AI 查询引擎的基础,它们能够收集信息并开展工作以协助人类员工。AI 智能体将从众多数据源收集信息,计划、推理并采取行动。AI 智能体可以与用户交流,也可以始终保持在后台工作,获取人类的反馈和互动。
实际上,AI 查询引擎是一个复杂系统,用于高效处理大量数据、提取和存储知识,并对这些知识进行语义搜索,确保其能够被 AI 快速检索和使用。
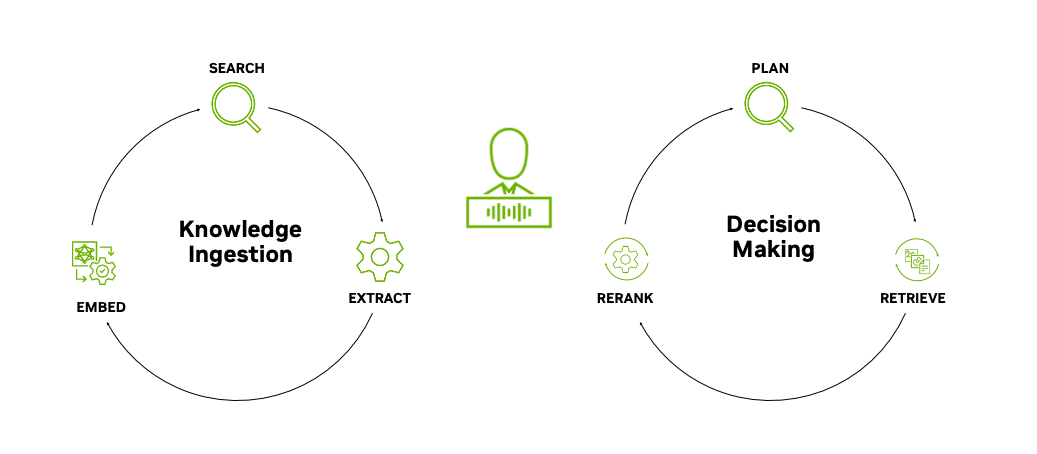
AI 查询引擎处理、存储和检索数据——将 AI 智能体与洞察力关联。
AI 查询引擎从非结构化数据中解锁智能
企业的 AI 查询引擎将能够访问以多种不同格式存储的知识,而从非结构化数据中提取智能是其实现的最重要进步之一。
为产生洞察,传统的查询引擎依赖于结构化查询和数据源,例如关系数据库。用户必须使用类似于 SQL 的语言制定精确的查询,且结果仅限于预先定义的数据格式。
相比之下,AI 查询引擎能够处理结构化、半结构化和非结构化数据。常见的非结构化数据格式包括 PDF、日志文件、图像和视频,通常存储在对象存储、文件服务器和并行文件系统中。AI 智能体使用自然语言与用户进行交流。这使其能够通过访问不同的数据源来解读用户意图,即便意图是模糊的。这些智能体能够以对话形式提供结果,以便用户能够理解。
这种能力使其能够从任何类型的数据中获得更多的洞察和智能——而不只是整齐排成行和列的数据。
例如,DataStax 和 NetApp 等公司正在构建 AI 数据平台,使客户能够为其新一代应用提供 AI 查询引擎。
AI 查询引擎的主要功能
AI 查询引擎具有以下几项关键能力:
多样化数据处理:AI 查询引擎能够访问和处理各种数据类型,包括来自多个来源的结构化、半结构化和非结构化数据,如文本、PDF、图像、视频和专业数据类型。
可扩展性:AI 查询引擎能够高效处理 PB 级数据,使 AI 应用能够快速获取所有企业知识。
精确检索:AI 查询引擎提供高精度、高性能的嵌入、向量搜索以及来自多个来源的知识重新排序。
持续学习:AI 查询引擎能够存储并整合来自 AI 赋能应用的反馈,创建一个 AI 数据飞轮,并根据反馈完善模型以及逐渐提高应用的有效性。
检索增强生成(RAG)是 AI 查询引擎的一个组成部分。RAG 利用强大的生成式 AI 模型作为数据的自然语言接口,允许模型在响应生成过程中访问和整合来自大量数据的相关信息。
使用 RAG,任何企业或组织都能够将其技术信息、政策手册、视频和其他数据转化为有用的知识库。AI 查询引擎可以依靠这些数据源为客户关系、员工培训和开发人员生产力等领域提供支持。
其他信息检索技术和知识存储方法也正在研究和开发中,因此预计 AI 查询引擎的能力将会迅速进化。
AI 查询引擎的作用
借助 AI 查询引擎,企业能够充分发挥 AI 智能体的作用,将员工与海量企业知识建立连接,提高 AI 生成回答的准确性和相关性,处理和利用以前未开发的数据源,并创建数据驱动的 AI 飞轮以持续改进其 AI 应用。
例如,提供个性化、全天候的客户服务体验的 AI 虚拟助手;用于搜索和总结视频的 AI 智能体;用于分析软件漏洞的 AI 智能体或 AI 研究助手。
AI 查询引擎在原始数据和 AI 赋能的应用之间架起一座桥梁,将在帮助组织从数据中提取价值方面发挥重要作用。
NVIDIA Blueprint 能够帮助企业着手将 AI 与其数据连接。
了解关于 NVIDIA Blueprint 的更多详情,并在 NVIDIA API 目录中试用:https://build.nvidia.com/blueprints
来源:IDC,Global DataSphere Forecast,2024 年
点击“阅读原文”或扫描海报二维码,观看 NVIDIA CEO 黄仁勋在拉斯维加斯现场发表的 CES 开幕主题演讲精彩回放。

