任何单个GPU、XPU或其他AI加速器都无法满足AI工作负载的巨大计算需求。为了满足这一需求,需要成千上万个,甚至不久的将来可能需要数十万个这样的加速器协同工作,共同分担处理负载。
以Llama3为例,仅预训练阶段就需要超过700TB的内存和16,000个加速器。与其他AI模型一样,其处理参数预计每四到六个月就会翻一番。
这种大规模并行处理和持续增长给支撑AI集群的网络结构带来了巨大的压力,更具体地说,给集群内部所有加速器之间的数据传输通道(即互连)带来了巨大的压力。
为了满足更大规模AI集群对更高带宽和更低延迟互连的需求,超以太网和超加速器链路(UALink)等新兴标准应运而生。我们最近率先发布的超以太网和UALink IP解决方案,将支持大规模AI集群的横向和纵向扩展。

AI基础结构的横向和纵向扩展
为了满足现代工作负载日益增长的计算需求,AI集群需要同时进行横向扩展(通过网络结构)和纵向扩展(在机架内)。
超以太网解决了横向扩展问题,通过提供高性能、与供应商无关的链路,它能够将多达百万级的节点连接成一个庞大的AI网络。UALink解决了纵向扩展问题,通过提供高速、低延迟的链路,可将一千个以上的AI加速器连接在一起。
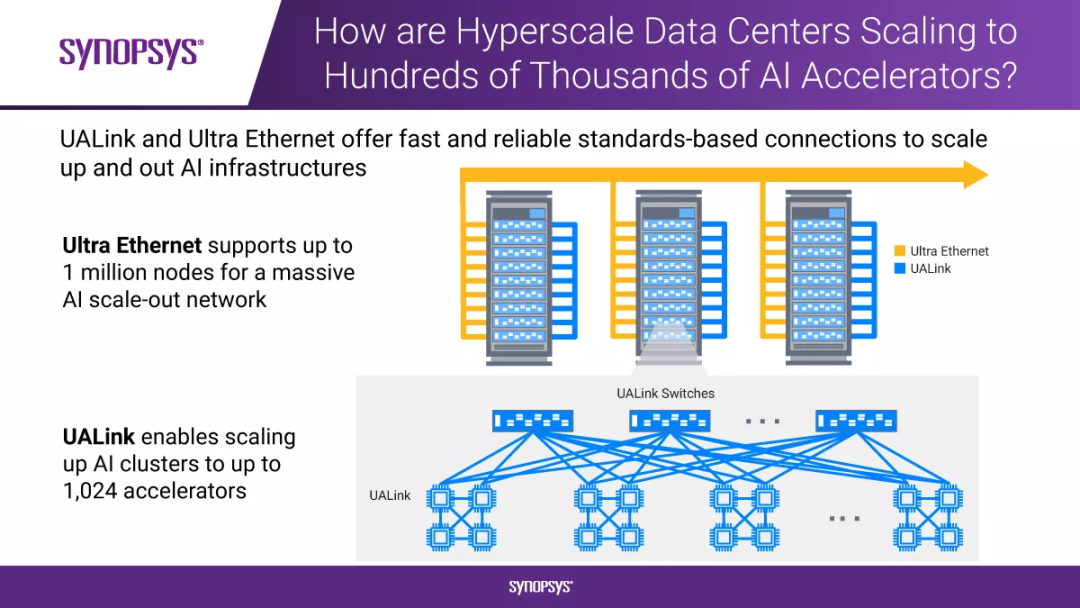
采用这些开放的行业标准协议,可以避免供应商锁定,并灵活扩展处理性能和规模。这为构建和升级超大规模数据中心及高性能计算(HPC)环境提供了灵活性,并保护了用户的投资。
作为超级以太网联盟(UEC)和UALink联盟(UAC)的活跃成员,我们正在帮助塑造和推动这些新兴标准,以促进下一代AI和HPC架构的发展。
业界率先发布的超以太网和UALink IP解决方案
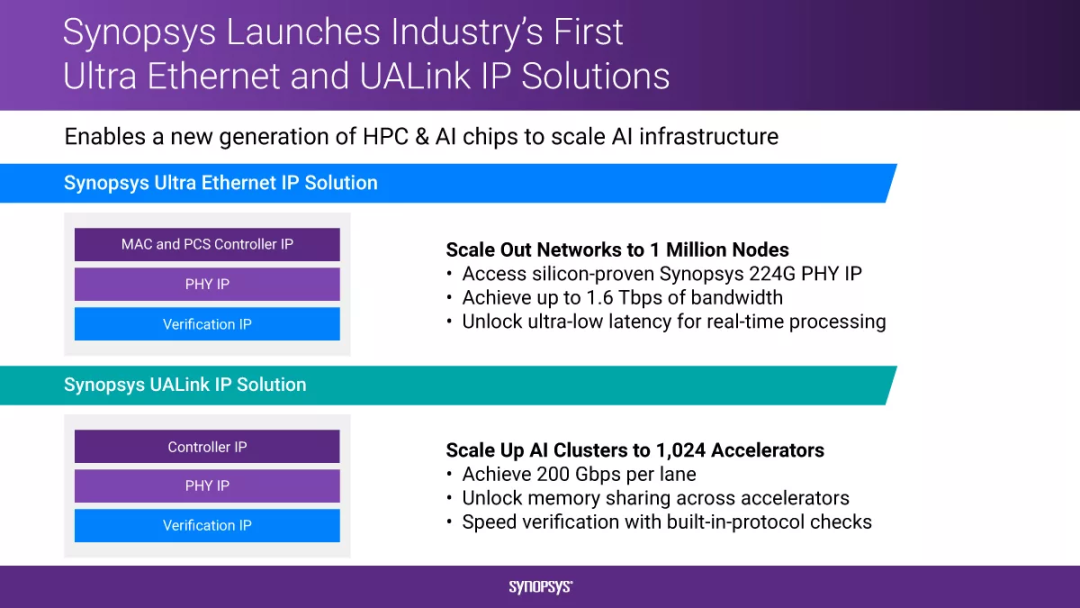
新思科技推出超以太网IP和UALink IP解决方案,以满足高带宽、低延迟互连的需求,这些解决方案提供了扩展当今和未来AI和HPC架构所需的接口。
我们的超以太网IP解决方案基于经验证的技术,能够提供1.6 Tbps的惊人带宽和超低延迟,可用于横向扩展大规模AI网络。我们的UALink IP解决方案能够提供每通道高达200 Gbps的传输速度,并支持内存共享,可用于纵向扩展加速器连接。
这两种解决方案都基于我们先进的以太网和PCIe IP(已成功助力客户实现5,000多次流片),能有效降低采用超以太网和UALink互连开发新一代半导体、片上系统(SoC)及AI加速器的风险,并缩短产品上市时间。
新思科技处于AI和HPC设计创新的前沿,提供广泛的高速接口IP组合。我们为PCIe 7.0、1.6T以太网、CXL、HBM、UCIe以及最新的超以太网和UALink提供完整且安全的IP解决方案,进而推动AI和HPC在性能、可扩展性、效率和互操作性等方面达到新的高度。
点击阅读原文了解更多关于新思科技超以太网IP和UALink IP的信息
如需了解更多信息,请扫描下方二维码联系我们