堆和栈是计算机内存管理中的两个重要区域,它们各自承担着不同的角色与责任,以满足程序运行期间多样化的内存需求。
1
为什么要分为堆和栈
管理不同生命周期的数据
栈:主要用于管理函数调用过程中的局部变量等。
当函数被调用时,相关的数据被压入栈中,函数执行完毕后,这些数据就被弹出栈,释放内存。
就像你去餐厅吃饭,服务员给你拿来一套餐具,等你吃完离开,服务员就会把餐具收走,为下一位顾客准备。
这样可以高效地管理那些生命周期与函数执行相关的短期数据。
堆:用于存放那些生命周期不确定的数据,比如动态分配的对象。
你可以把堆想象成一个巨大的仓库,你可以根据需要随时去租用一块空间来存放你的物品(数据),而且只要你不主动归还(释放内存),这块空间就一直为你所用。
提高内存使用效率
栈的内存分配和释放非常快速,因为它的操作方式简单,遵循 “后进先出” 的原则。
这就像是在自动售货机前排队买饮料,先来的人先买完离开,后面的人紧跟着上前,秩序井然,效率很高。
堆的灵活性则允许程序员在运行时根据实际需求动态地分配和释放内存大小。
比如你在玩拼图游戏,一开始不知道需要多大的空间来摆放拼图碎片,但是随着游戏的进行,你可以根据实际情况从堆中申请合适大小的空间来放置碎片。
支持不同的编程需求
栈适合存放那些在函数内部使用的临时数据,因为它的自动管理机制可以避免程序员忘记释放内存而导致的内存泄漏问题。
比如你在写一篇文章,草稿纸上的临时笔记在你完成文章后就可以自然地丢弃,不需要特意去管理。
堆则为那些需要长期存在或者大小不确定的数据提供了存储场所。
比如在开发一个图形绘制软件时,用户绘制的图形可能数量和大小都不确定,这时候就需要从堆中分配内存来存储这些图形数据。
2
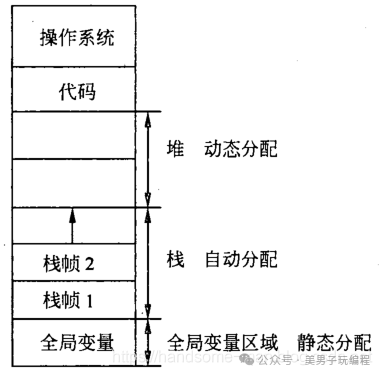
如何理解堆和栈
栈:高效的临时存储区
从功能上看,栈就像是一个有条不紊的办公桌面。
当你开始一项任务(函数调用)时,你把需要用到的工具(局部变量等)放在桌面上,任务完成后,你把工具收拾起来(内存释放)。
它的特点是快速、自动管理,适合存放那些短期使用、生命周期与函数执行相关的数据。
从操作方式上看,栈是 “后进先出” 的,就像一摞盘子,最后放上去的盘子会最先被拿走。
每次函数调用就像是在盘子堆上放一个新盘子,函数返回时就把这个盘子拿走,恢复到之前的状态。
堆:灵活的动态存储区
堆可以想象成一个大型的储物仓库,你有一把钥匙(指针)可以打开仓库的门,存放或取出你需要的物品(数据)。
它的特点是灵活性高,可以根据需要动态分配和释放内存大小,但需要程序员手动管理内存的分配和释放,否则可能会出现内存泄漏等问题。
从使用场景上看,当你需要创建一个对象或者存储一些大小不确定的数据时,就可以从堆中申请内存。
比如在开发一个游戏时,游戏中的角色、道具等可能会不断变化,需要从堆中分配内存来存储这些动态的数据。