

面向全场景NOA的规模化普及,黑芝麻智能重磅推出了新一代智能驾驶计算芯片。
12月30日,黑芝麻智能正式推出了面向下一代AI模型更高性能、更高效率的芯片平台——华山A2000家族,包含A2000 Lite、A2000和A2000 Pro三款产品,可以满足NOA、Robotaxi等不同等级的自动驾驶需求。

华山A2000家族芯片平台
据了解,A2000家族的芯片集成了业界领先的CPU、DSP、GPU、NPU、MCU、ISP和CV等多功能单元,实现了高度集成化和单芯片多任务处理的能力,算力最大是当前主流旗舰芯片的4倍,且原生支持Transformer模型。
当前,高阶智驾“下沉”之战已经打响,“降本增效”已经成为了各大主机厂普及高阶智驾的唯一路径。
根据《高工智能汽车研究院》数据显示,2024年1-10月,中国市场(不含进出口)乘用车前装标配L2及以上智能驾驶功能搭载率提升至54.66%。在这其中,20-30万元价位区间乘用车前装标配NOA占到整体市场搭载量的41.25%,而9月份该价格区间搭载NOA的交付量已经反超30万元以上价位车型。
然而,市场上可以支持NOA等高阶智驾的计算方案却屈指可数,主机厂不仅在降低硬件成本上面存在一定的壁垒,还很难实现高阶智驾方案的差异化竞争。
黑芝麻智能华山A2000家族芯片平台的推出,无疑为高阶智驾的规模化普及提供了新选择。
为全场景通识智驾而生
当前,端到端(E2E)和大模型技术已经成为推动智能驾驶产业发展的核心动力。黑芝麻智能认为,算法的未来发展将更加聚焦于提升效率和性能,而随着行业步入大模型时代, Transformer算法结构和混合模型架构将引领新的技术潮流。
因此,黑芝麻智能提出全场景通识智驾概念,基于知识范式将驾驶场景的信息引入到知识增强的表示空间中,这些信息可以被推导为场景语义空间中的通用知识,随后通过知识的反映来推断场景,从而指导实现更好的智能驾驶体验。
简单来说,通识智驾具备实现高级感知、决策和执行的通用能力,能够全面覆盖城市道路、高速公路、昼夜变化以及各种气候条件的不同场景。
预计从2025年开始,高阶智驾能力逐渐成为标配,多传感兼容、支持多种模型算法开发以及更具性价比和成本控制的方案,才能满足市场和客户的增长需求,推动自动驾驶技术的普及和经济效益提升。

智驾计算的多维挑战
黑芝麻智能认为下一代自动驾驶计算芯片不仅需要满足高算力、高带宽、平台化设计的需求,还需要配合友好通用的工具链以及全栈化解决方案,以满足自动驾驶技术的快速落地和持续迭代。
据了解,华山A2000家族包括A2000 Lite、A2000和A2000 Pro三款产品。其中,A2000 Lite专注于城市智驾,A2000支持全场景通识智驾,而A2000 Pro则是为高阶全场景通识智驾设计,最高算力是当前主流旗舰芯片的4倍。
具体来看,华山A2000家族采用了新一代ISP技术,具备4帧曝光和150dB HDR,在隧道和夜间等场景下表现更好,显著提升了图像处理能力。单芯片数据闭环的设计,使得数据在智驾功能正常运行的同时能够实现全车数据的脱敏、压缩、编码和存储,为算法的迭代和创新提供坚实基础
此外,A2000家族的灵活扩展性,允许多芯片算力的扩展,以适应不同级别的自动驾驶需求,产品组合全面覆盖从NOA到Robotaxi的广泛应用场景。
值得注意的是,华山A2000家族芯片不仅在智能汽车领域展现出强大的性能,还能够支持机器人和通用计算等多个领域。据了解,A2000芯片能够满足机器人的“大小脑”需求,推动机器人产业从原型开发阶段迈向大规模量产。
核心IP再创性能天花板
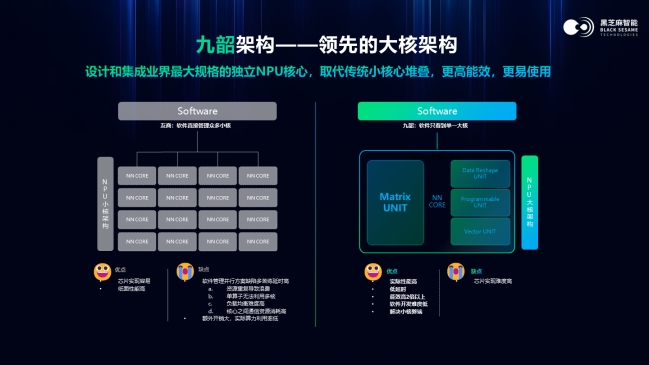
在推出华山A2000家族芯片平台的同时,黑芝麻智能还重磅推出了自研 NPU 新架构——黑芝麻智能“九韶”。据悉,这是黑芝麻智能为满足自动驾驶技术需求而推出的高性能 AI 芯片的计算核心。
新一代通用 AI工具链BaRT和新一代双芯粒互联技术BLink两大创新,共同赋能“九韶”计算性能的充分发挥和灵活扩展,构成了一个强大的智能驾驶技术底座,为 A2000 家族性能跃迁保驾护航。
自研 NPU 新架构——“九韶”
资料显示,九韶NPU采用了领先的大核架构,支持智驾大模型的实时推理,降低算法计算的延迟,基于优先级抢占的机制为处理复杂计算任务提供了强有力的支撑。
同时,九韶NPU也是业界最高安全等级的NPU,高安全等级能够避免模型推理过程中的随机错误和失效,支持训练与部署的一致性,确保了自动驾驶系统的高安全性和确定性。
九韶NPU的特点包括高算力、高能效和高带宽,这是智能驾驶技术向更高阶迭代的基础。它支持包括INT8/FP8/FP16在内的混合精度,集成了针对高精度精细量化和Transformer的硬加速,能够简化开发者在量化和部署过程中的工作。
此外,九韶架构还具备低延时和高吞吐的三层内存架构,包括大容量高带宽的NPU专用缓存、核心模块片内共享缓存,以及对称的双数据通路和专用DMA引擎。提升了性能和有效带宽,降低了对外部存储带宽的依赖,在性能、带宽和成本之间取得了极致平衡。
为了充分发挥九韶架构的潜力,黑芝麻智能研发了新一代通用AI工具链BaRT。BaRT支持多种流行框架和模型的转换,原生兼容PyTorch的推理API,支持Python编程部署。这使得开发者能够更加便捷地利用九韶架构进行AI模型的开发和部署。
BaRT的另一个优势是支持业界主流的Triton自定义算子编程,允许开发者使用Python语言编写Triton自定义算子,这些算子可以被自动化编译成硬件加速代码,从而进一步加速开发者AI模型的部署。
为了满足不同等级自动驾驶的算力需求,新一代双芯粒互联技术BLink技术为算力扩充提供了高效解决方案。BLink支持Cache一致性互联的高效C2C(Chip-to-Chip)技术,能够扩展支持更大规模模型的算力需求,为算法长期演进做好准备。
通过BLink技术,A2000家族芯片能够实现软件单OS跨片部署,支持高带宽C2C一致性连接,满足NUMA跨芯片访存要求,简化软件开发和部署的难度。
很显然,伴随着华山A2000家族芯片的发布,黑芝麻智能的自动驾驶芯片矩阵将更加丰富,进而全面赋能全场景通识智驾走向“标配时代”。


