

从20世纪50年代起,AI技术经历了70多年的发展。其间多种技术曾占据不同时代的高位,而当时间来到21世纪20年代,抵达我们今天正在经历的新一轮AI崛起,预训练大模型毫无疑问就是这个时代的主角。
那么,究竟是谁点燃了这次AI爆发的星星之火,推开了大模型的大门?相信你把这个问题抛给不那么了解AI的朋友,他也会脱口而出:是OpenAI啊。但就像大模型会出现幻觉一样,最近外网全面热议的一件事告诉我们,这个答案也可能掺杂了一些幻觉成分。
Scaling Law规模化法则,也被称为大模型的尺度定律。这一定律揭示了大语言模型的模型性能与其规模、训练数据集大小,以及训练资源之间存在着一种可预测的关系。也就是说投入资源越多,模型规模越大,最终的模型效果也就可能越好。从AI模型走向AI大模型,以及采取预训练机制的必要性都是由此而产生。因此Scaling Law也被业界广泛认为是模型预训练的第一性原理。
但就这项核心理论的起源,最近却有一项讨论火爆外网。根据AI大佬爆料,以及《南华早报》等权威媒体的报道,中国科技巨头百度比OpenAI更早发现了这一原理。这也意味着中国AI在大模型时代的前瞻性探索上可能更为超前。
而“AI突破总来自百度”这一现象的背后,更展示了体系化AI创新的核心价值。如何在全球AI竞赛的大背景下,全面释放出百度的体系化AI创新价值,将是未来中国AI发展的核心课题。

事情的起源是这样的。11月12日,在Lex Fridman的播客节目中,Anthropic联合创始人&CEO Dario Amodei探讨了Claude、AI模型的扩展规律、AGI、AI未来等多个话题。其中,作为AI领军人物的Dario Amodei也谈到了Scaling Law这个关键规律的发现。他提到了他最早发现这个规律,始于此前在百度工作时的相关研究。根据资料显示,Dario Amodei于2014 年 11 月到2015 年 10 月期间在百度工作,当时他在百度硅谷人工智能实验室(SVAIL)工作,致力于将深度学习模型扩展到大规模高性能计算系统。
Dario Amodei提到,2014年与吴恩达在百度研究AI的时候,他就已经发现了模型发展的规律Scaling Law,“随着你给它们提供更多数据,随着你让模型变大,随着你训练它们的时间越来越长,模型的表现开始越来越好。当时我并没有精确地衡量,但我和同事们都非常非正式的感觉到,给这些模型的数据越多、计算越多、训练越多,它们的表现就越好”。

这个说法很快也得到了其他途径的权威证明。11月27日,Meta研究员、康奈尔大学博士候选人Jack Morris在X上表示,“大多数人不知道,关于Scaling Law的原始研究来自2017年的百度,而不是2020年的OpenAI”。
这个说法的来源是,在百度于2017年发表的论文《DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY》论文当中,已经对Scaling Law做出了详细研究,并探讨了机器翻译、语言建模等领域的Scaling现象。业内人士认为,这篇论文的重要性被严重忽视了。
而透过这次全球AI界的正本清源,我们真正能够看到的是百度在AI领域的前瞻性与系统化创新能力。很多AI的答案总是由百度来找到,已经成为业界的全新共识。

十年之前,互联网技术正在持续发展,移动时代正处在高位。当时几乎没有哪家科技公司愿意从眼前的利益中抽身,去看看更遥远的未来。
但如果每家科技企业都固守短期利益,那么当科技拐点到来,下一轮技术突破开启,整个社会的科技竞争力不足就会暴露出来。我们只能重复一次又一次科技模仿者的角色。
好在百度决定打破这个循环,用预判能力提前点燃AI的星星之火。这种预判性,已经为百度,乃至为整个中国AI领域带来了极大效益。比如尽管外部刚刚爆料出百度更早发现Scaling Law的信息。但百度早已经基于对Scaling Law的研究和理解,很早就投入到预训练大模型的工作当中。于是可以在全球第一梯队发布大模型技术,率先打造投入应用的AIGC产品。

早在2013年1月的百度年会上,李彦宏宣布成立了深度学习研究院,并亲自任院长。李彦宏认为,“这应该是全球企业界第一家用深度学习来命名的研究院”。这意味着,在全球大多数科技企业对AI的认知停留在科幻电影的阶段,百度已经率先将AI技术作为学术研究与业务落地的发展方向,继而开始体系化、系统化进行AI创新。
多年以来,百度在硬件、基础软件、模型算法、业务落地等维度进行了AI探索。后来的事实也证明,对单项AI技术的投入只能是模仿,只有从源头上进行体系化研发投入,才能提供源源不断的AI创新成果。由李彦宏的前瞻性出发,启动搭建的百度AI系统,让百度十年来成为AI人才、AI技术与AI基础设施的策源地。

从人才角度看,全球AI人才看到了百度AI的未来,争相加入到这个体系中来。比如说2014年,吴恩达加入百度并在研究院首席科学家,担任百度公司首席科学家,负责百度研究院的领导工作。2014年5月19日,百度宣布任命吴恩达博士为百度首席科学家,全面负责百度研究院。同样在2014年,Dario Amodei斯坦福博士后毕业后加入百度硅谷AI实验室。之后,Dario amodei又招募了Jim fan来百度实习。这些人后来都成为AI爆发的全球领军人物,将百度的AI积淀带向世界。
从业务发展的角度看,百度在自然语言处理、机器视觉、知识图谱等领域打下了坚实的技术底座,并率先将AI技术带到搜索、信息流、地图、自动驾驶等核心业务,全面迭代了科技行业与AI技术的关系,为未来千行百业的智能化指定了航标。
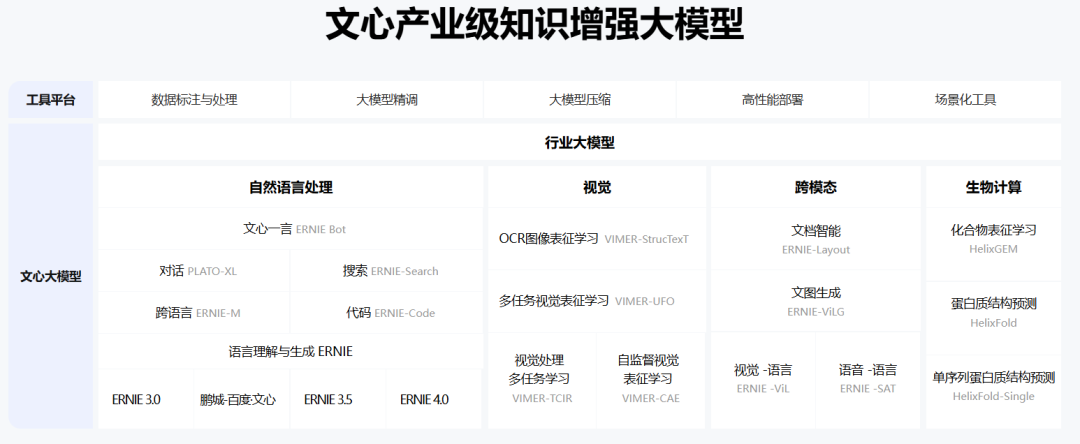
从基础设施的角度看,百度打造的飞桨+文心大模型体系已经成为AI开发者与产业智能化共同依托的技术底座。目前,飞桨文心开发者数量已达1808万,服务了43万家企业,创建了101万个模型。百度已经成为AI模型与AI开发者的摇篮。
不至Scaling Law,百度在AI领域点燃了无数星星之火。它们燃烧盛放,成为中国AI在全球赛场上的动力引擎。

时间来到今天,预训练大模型驱动全球新一轮科技革命。在这个阶段当中,百度凭借跨越十年的AI洞见,以及由此打造的体系化AI创新,全面提升了中国AI的发展加速度。
比如说,百度在2019年发布了第一代文心大模型,几乎与OpenAI处于同一时期;2023年,百度是全球第一家推出生成式AI产品的科技大厂,让中国用户有了与无时间差的AI革命体验。
今天,百度文心大模型日调用量已经超过15亿。对比今年5月2亿的日调用量,半年时间达到了原来的7.5倍,对比一年前5000万的日调用量,达到了30倍。文心已经真正成为中国预训练大模型的底牌与王炸。

而把百度的前瞻能力与体系化AI创新,放在更大的全球科技竞赛背景中看,会发现其有着极其深远的意义。
日前,外媒Axios援引知情人士消息,美国候选总统特朗普计划任命一位人工智能部长(AI czar),以协调联邦政策和政府对新兴技术的使用。“AI部长”将在集中公共和私人资源方面发挥作用,确保美国在全球范围内占有人工智能发展的领先地位。这预示着特朗普下一个任期内AI技术发展将加速迎来变局。AI对于社会经济、国家战略的意义正被推升到史无前例的高度。
在全球AI竞赛的必然趋势下,百度的深入积累的AI技术路径、研究方法与工程化实践、应用探索,都将成为未来中国AI加速度的来源。
如何透过Scaling Law的全球热议,看清百度AI基座的不可替代性,并将这种价值应用在未来必将发生的AI竞赛中,将是中国AI接下来一个深刻且富有想象力的命题。

