
固态硬盘( Solid State Drive,SSD )在大型数据中心中发挥着重要作用。SSD故障会影响存储系统的稳定性,造成额外的维护开销。为了提前预测和处理SSD故障,本文提出了一种多视角多任务随机森林( MVTRF )方案。MVTRF基于从SSD的长期和短期监测数据中提取的多视图特征预测SSD故障。特别地,采用多任务学习,通过同一模型同时预测什么类型的故障以及何时发生。本文还提取了MVTRF的关键决策来分析为什么会发生故障。这些故障细节将有助于验证和处理SSD故障。在来自数据中心的大规模真实数据上对提出的MVTRF进行评估。实验结果表明,与现有方案相比,MVTRF具有更高的故障预测准确率,准确率平均提高了46.1 %,召回率平均提高了57.4 %。
以往的工作仍然面临以下挑战。首先,大部分基于SSD故障进行预测都建立在一个或几个短期监控日志上,而较少关注SSD的长期日志。然而,通过分析,一些SSD故障可能并不体现在短期的局部信息中,而是隐藏在长期信息中。少数工作使用长短时记忆( LSTM )等序列模型直接从长期数据中学习,但SSD监测数据的序列长度过长且长度差异较大,影响序列模型的性能。对于长期数据,它们的趋势和分布对于判断SSD故障实际上很重要。第二,尽管失效预测对可能失效的SSD进行了筛选,但对验证和处理失效缺乏指导性建议。操作者只知道一个故障可能发生,而不知道它是什么,何时以及为什么会发生。预测或分析更多的失效类型、寿命(故障前剩余工作时间)、失效原因等信息,有助于操作人员验证是否是内部SSD失效,判断采取何种措施以及是否具有紧迫性。例如,运营商会以不同的紧急程度处理不同类型的故障,并测量。
从腾讯云数据中心采集了三星PM1733和PM9A3固态硬盘的大规模SSD监测数据集。该数据集包含了腾讯数据中心30多万个不同寿命的SSD在9个月内超过7000万条监控日志。日志信息由SSD序列号、服务器序列号、时间戳和SSD内部属性值组成。除了SMART属性外,三星还定制了更多的内部属性来增强SSD的自我监控能力,使得预测和分析更多的故障信息成为可能。PM1733共有40个内部属性,PM9A3共有85个内部属性。本文将所有这些属性,包括标准的SMART属性和自定义属性统称为Telemetry属性。
PM1733和PM9A3的故障列表也由腾讯公司提供。列表中包含了腾讯运营商收集的SSD故障信息,包括故障SSD的序列号、故障上报日期、故障描述以及处理时间和措施。清单中共有409条失效记录。经操作人员检查,大部分为SSD故障,少数为服务器背板等其他设备的故障。
通过分析腾讯故障列表中的故障描述和处理措施,故障可以分为8种类型,在不同的时间采取不同的措施来处理不同类型的故障。这些失效类型分别称为Check Failed、Cancelling I / O、Media Error、SSD Drop、Fail Mode、PLP、Read Only和可靠性降级,相关描述如表1所示。
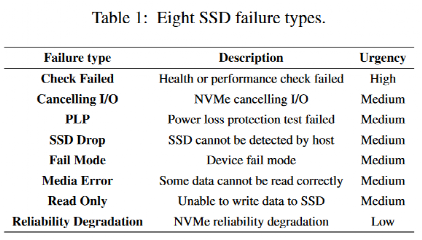
图1和图2分别比较了具有nand_bytes_write和temperature属性的失效SSD和健康SSD的数据分布。横坐标为桶指数,纵坐标为落在桶中的数据比例。图1显示失效SSD和健康SSD的nand_bytes_write值大部分落在桶1 -桶7中。然而,在后期桶中,失效SSD的值比健康SSD有更大的比例。由图2可知,在温度属性的第20 ~ 23个桶中,故障SSD和健康SSD的数据分布差异较大,但在第17个桶之前的分布较为相似。总的来说,失效SSD和健康SSD存在一定差异,但在某些范围内的分布相似。
为了进一步区分失效SSD和健康SSD的属性相似分布,深入探究了长期遥测数据的统计量分布差异。即每个SSD的每个属性在长时间内的多个值落入桶中,计算每个桶中这些值的数量占所有桶中值数量的比例,称为桶比例。
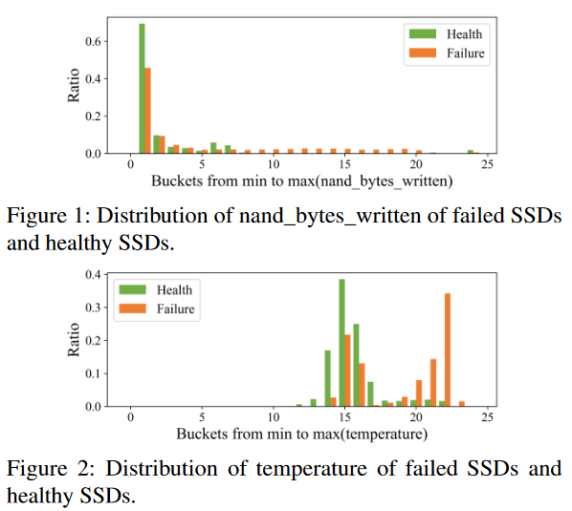
对于nand_bytes_write属性,图3给出了桶1 - 7的长期数据的桶比例,横坐标仍为桶指数,纵坐标为长期数据的桶比例。表明在这些值分布相似的桶上,失效SSD和健康SSD的长期数据的桶比例分布不同。在nand _ bytes _ write较小的桶3 ~ 7上,健康SSD的长期数据的桶比例明显大于故障SSD。这表明,健康的固态硬盘在长期中受到的写操作更少,因此更不容易发生故障。对于温度属性,图4给出了图2中分布较为相似的桶17之前的长期数据的桶比例。在低温桶1 ~ 13中,健康SSD长期数据的桶比例明显较大,说明低温有利于SSD健康。总之,基于长期SSD数据的统计,失效SSD和健康SSD之间的差异有被放大的趋势。
接下来,分析Telemetry属性的长期变化趋势,以探究故障SSD和健康SSD之间的差异。由于同一台服务器上的大多数SSD的工作负载通常是相似的,因此在故障发生之前,比较故障SSD与同一台服务器上其他健康SSD的属性变化趋势。图5展示了不同失效类型的失效SSD主要异常属性的变化趋势。横坐标表示采集时间,纵坐标表示属性值。从图5可以看出,同一服务器上健康SSD的属性趋势相似,而故障SSD的属性趋势在长期上存在差异。此外,失效SSD的曲线可能涉及缓慢变化、快速变化和稳定等多个阶段。

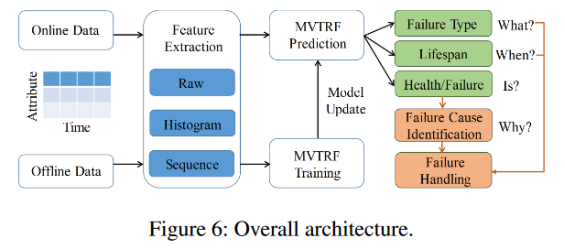
多视角多任务随机森林( MVTRF )方案的总体架构如图6所示。MVTRF设计主要遵循3个思路:1 )设计长期数据的分布和趋势相关特征以捕捉长期失效模式;2 )将不同视角的特征结合分组学习和联合决策,准确预测SSD故障;3 )预测并提取详细的故障信息,提高故障处理效率。
根据先前对SSD故障征兆的观察,可以发现SSD故障不仅体现在短期数据的异常值上,还隐藏在长期数据的分布和趋势上。将长期数据直接输入到LSTM等序列模型中是一种选择。但由于使用周期不同、采集不规范等原因,不同SSD的遥测日志数量相差很大。序列模型很难处理如此不同长度的序列数据。此外,过长的序列也会影响序列模型(例如, LSTM在长序列情况下存在梯度消失问题)的性能,导致过高的计算复杂度和开销。
为了避免直接使用长期数据,通过从长期数据中提取特征来表示其分布和趋势。引入基于桶统计量的直方图特征和序列相关特征,可以刻画序列波动和变化的程度。直方图特征和序列相关特征从长期数据中提取关键信息,丢弃冗余信息。这些特征和短期原始数据构成了SSD故障预测的多视图信息。
经过预处理和数据清洗后,遥测日志数据为原始特征。假设经过数据清洗后剩余N个属性,定义SSD第T次遥测数据的原始特征为DT = { a1T,a2T,..,anT,..,aNT },其中a1T,a2T,..,anT,..,aNT为N个属性的值。主要使用原始特征来捕获属性的短期异常值,因此它们默认来自单个遥测日志。
4.1.2 直方图特征
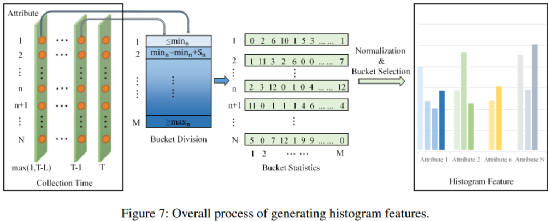
直方图特征利用了先前提到过的桶概念。首先对SSD进行长度为256的日志收集,因为256个日志大致跨度在三个月以上能够覆盖失效症状的时间跨度。依据最小值和最大值在100个桶上进行分布,最终筛选出有效的桶分布。
4.1.3 序列相关特征
提出序列相关特征来表示SSD的长期原始特征DT - L - DT的波动和趋势。引入变异系数来表征属性的波动性,引入峰度和斜率来表征属性的趋势性。为了捕捉长期数据中可能存在的多个变化阶段,还在时间维度( G默认为4)中将DT - L - DT等分为G段,并分别计算每段的变异系数、峰度和斜率。
变异系数。变异系数可以衡量属性在较长时期内的离散程度。相对于方差或标准差,变异系数可以消除不同属性、不同SSD的不同尺度的影响。第n个属性第g段的变异系数CVARng的计算公式如下:

峰度。峰度反映了一个属性长期分布的陡峭程度。第n个属性的第g段峰度KURTng的计算公式如下所示:

斜率。斜率可以反映某一属性随时间的变化趋势。第n个属性第g段的斜率SLOPEng计算如下:
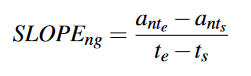
在同一台服务器上,故障SSD的某些属性的变化趋势可能与其他健康SSD有较大差异。因此,对于上述的CVAR、KURT和SLOPE,分别计算它们在一个SSD上的值与同一服务器上其他SSD相同特征的平均值的差值,定义为CVAR _ diff、KURT _ diff、SLOPE _ diff。然后,将所有N个属性的G个窗口的CVAR、KURT、SLOPE和CVAR _ diff、KURT _ diff、SLOPE _ diff进行拼接,得到N × G × 6的SSD序列相关特征。
为了学习提取特征的模式,选择随机森林作为基模型,原因有三。首先,已有研究证明了随机森林在SSD失效预测上的良好性能。其次,随机森林由多棵决策树组成,每棵决策树通过对特征的一系列判断将样本分为不同的类。其可解释性较好,有助于通过判断过程进一步识别失效原因。第三,与神经网络相关模型相比,随机森林的计算复杂度更低,有利于减少离线训练和在线预测过程中的开销。
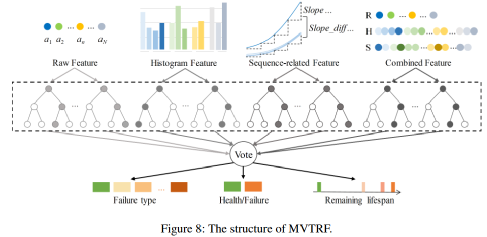
如图8所示,随机森林的所有决策树被平均分为四个集合,分别学习原始特征、直方图特征、序列相关特征和组合特征。然后,对四个集合的所有决策树进行投票,得到最终的预测结果。投票最多的类为预测类,投票份额为置信概率。通过这种方式,将来自不同视图的特征进行组合以获得最终的判断。
三个任务的具体定义如下。
1 ) 故障预测。将其定义为二分类任务。将健康SSD和失效SSD的数据分别标记为0和1。
2 ) 故障类型预测。将其定义为多分类任务。健康SSD和失效SSD的数据分别标记为0和1 - O。数据集有8种失效类型,因此O = 8。
3 ) 剩余寿命预测。回归更适合该任务,但为了与上述两个任务保持一致,也将其定义为多分类任务。将距离故障一周以上的数据标记为0,距离故障一天到一周的数据标记为1,距离故障一天以内的数据标记为2,距离故障时间前后的数据标记为3。
在生产环境中,一些SSD异常实际上可能是由其他设备的故障引起的,例如服务器底板。当预测到故障时,操作员需要了解故障的症状和原因,以准确确认设备故障。事实上,使用随机森林算法的原因之一在于其可解释性。随机森林基于决策树,决策树本质上是一系列阈值决策。它符合人类的思维,即通过多种判断的综合得出最终结果。通过分析决策过程,可以揭示为什么会出现失败,从而识别失败的症状和原因。然而,随机森林是多个决策树的集合,很难分析如此多的决策过程。因此,本文提出相似决策抽取( SDE )方法,从MVTRF中的多棵决策树中获取关键决策,以反映整体决策过程,发现失效原因。

图9展示了SDE的工作原理,包括三个步骤。首先,每个决策由于其区分能力被决策树选择,提取多个决策树中出现频率较高的相似决策作为关键决策。两个决策在满足以下条件时被认为是相似的:1 )两个决策的特征和决策逻辑(即≤或>)相同;2 )两种决策的决策阈值相似,两个阈值的差值在∝(默认为10 %)内。本文为每个决策在其他决策树中寻找相似决策,并将相似决策的数量作为该决策的权重。
在计算出所有决策的权重后,第二步是去除冗余的相似决策。借鉴非极大值抑制思想,SDE保留权重较高的决策作为关键决策,舍弃权重较低的相似决策。主要过程如下。1 )对所有决策的权重进行排序;2 )从未处理的决策中选择权重最高的决策;3 )删除与本决策类似的其他决策;4 )重复上述操作2和操作3,直到所选决策的权重小于全局最高权重的一半。这样,冗余的相似决策由权重较高的关键决策表示。最后,可以将具有相同特征和决策逻辑的关键决策的权重进行整合,保留最严格的阈值(即>的最大值和≤的最小值)来显示异常值。
通过SDE提取的关键决策可以揭示故障原因,从而有助于确认是否为SSD内部故障。许多故障的关键决策涉及SSD内部错误(例如,过多的媒体错误、坏块或程序故障),表明SSD发生故障。当关键决策涉及通信或环境,如PCI错误或温度时,操作员除了需要检查SSD外,还需要检查外部设备(例如背板)或环境。关键决策揭示的失效原因能够显著提高操作者验证失效的效率。
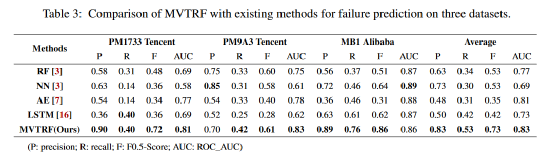
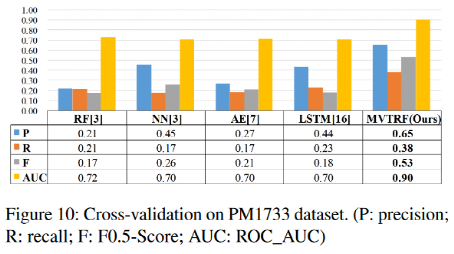
从表3和图10都可以看出,MVTRF在各个指标上都有着不错的提升。
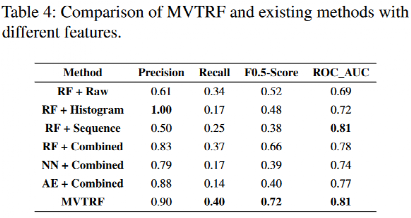
表4展示了在PM1733腾讯数据集上的结果。原始特征关注异常属性值,易于判断,因而其召回率相对较高。而短期原始特征无法捕捉到长期信息中的一些失败症状,因此ROC _ AUC最低( 0.69 ),难以发现更多在较低的判别阈值下SSD失效。直方图特征和序列相关特征反映了长期数据的分布和趋势,可以发现更多的失败症状,因此它们的ROC _ AUC更高。组合特征包含上述3个特征。由于包含多视角信息,组合特征的RF在各个指标上表现良好。
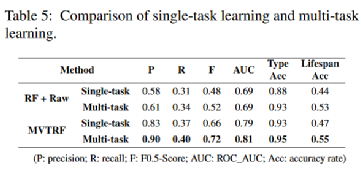
在原始特征的基线RF和MVTRF上,评估了多任务学习对每个任务的影响。表5比较了两种模型在单任务学习和多任务学习下对三种任务的表现。对于失败预测,通过多任务学习和预测,性能较好,两个模型的F0.5 - Score平均提高了0.05。
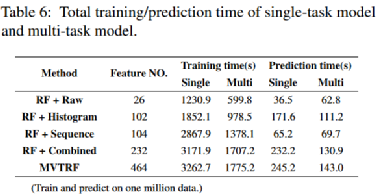
使用单个模型进行多任务学习的另一个好处是,与使用3个模型预测3个任务相比,可以减少模型训练和预测时间。表6展示了不同特征的维度,并比较了基于这些特征在三个任务上单独训练/预测和联合训练/预测所需的总时间。表6显示,在大多数情况下,采用多任务学习可以减少训练/预测时间。这也说明MVTRF的训练/预测时间主要取决于维度最高的组合特征的训练/预测时间。此外,基于多任务学习的MVTRF在三分钟内完成百万条遥测数据的预测,能够完全支持大规模SSD的在线实时预测。
根据MVTRF模型的决策过程,本文提出了SDE来获取关键决策并找到导致失效的原因。表7展示了失效SSD的决策过程中提取的关键决策。SDE从总共3825个原始决策中提取出5个关键决策并赋予其权重。
将这些关键决策重新应用到所有数据中,根据它们引入的误报来评估它们的有效性。由表7可知,权重最高的决策仅有3次虚警,说明提取的关键决策具有较强的区分能力。然后,通过结合后续的关键决策来消除所有的虚警。可以得出结论,SDE方法提取的决策是关键的,能够代表主要的决策过程。根据关键决策,认为导致该故障的直接原因是介质误差( media _ error _ slope > 126.44 , media _ error > 6015.5)的快速增加,因此被验证为SSD的内部故障。此外,温度的变化和磨损水平的变化可能是(温度_ kurt < = -1.11 ,磨损_ level _ max _ kurt > -0.047)的潜在影响因素。

本文还从所有失效SSD的判断过程中提取了几组关键决策来评估关键决策的整体判别能力,如表8所示。结果显示,对于失败的固态硬盘,共有53,663个决策,而SDE方法提取了49个关键决策。将这些关键决策重新应用到所有数据中,获得了与所有原始决策相同的精度和召回率。49个关键决策在区分失效SSD和健康SSD上的表现与原始的53,663个决策几乎相同,说明了所提SDE方法的有效性。然后,基于这些决策可以识别和分析故障原因,为验证和处理SSD故障奠定基础。
