

礼让动物采摘水果——最近, 智能车大赛AI视觉组 的题目已经发布,我们先为大家探探路。
前一期,逐飞科技给大家带来了一篇开幕大作:智能车竞赛,AI视觉组赛题浅析 ,对该组别的核心赛题任务进行了拆解详述。其中一个重中之重,想必也是大家最为关心的一个赛题,图案识别,可以说这也是这个组别中最有AI味道的部分。

那么这次,小编就为大家带来如何制备数据集并将其部署在i.MX RT上。
首先,请大家允许小编简要的“吐槽“下这个简单而又复杂的任务,任务本体是对动物和水果进行分类,其中动物类包括:狗、猫、马、猪、牛五类,水果类包括:苹果、橘子、葡萄、香蕉、榴莲五类。
大家可能也注意到了,小编使用了一对完全对立的词汇形容这次任务。简单vs复杂,还请听小编徐徐道来。
说任务简单,首先从所要识别的图像本身来说,比赛所用到的图像均为全身或是整体图片,我们可以窥探出两点小秘密:
其一,待检测图片内部只包含其中一种物体,也就是说不会涉及到多物体检测,不用采用OD类模型(OD是object detection的简称,一般模型体量会比较大,执行耗时比可比图像分类多几十倍,但好处在于可以一次性检出画面上所有的待检物体,并且提供位置信息)来做。
其二,待检测图片背景不复杂,通俗点讲,全图只有待检物体本身,大大降低背景噪声的引入对分类模型的影响。

现在再来说说为什么任务复杂。任务本身是一个典型的十分类问题。CNN领域有一些经典的十分类问题,拿最耳熟能详的例子,cifar10和LeNet-5为例,数据集本身的体量很大,每一子类都有1w的可用数据,而本次比赛,我们能够提供的预制数据集数量不会很大,每一类仅有400+。
同时,尽管i.MX RT目前被称作地表最强MCU,但毕竟是MCU。对于一些体量比较大的模型,还是会有点捉襟见肘,颇有一种心有余而力不足的挫败感,这里,小编也要强调一下,这种挫败感的根源,不是来自于对大模型的不支持,而是说,处理的速度会比较慢,会耗费大量的时间来进行目标的识别。
当然了,算力和模型精度是一对欢喜冤家,往往好的模型,体量都不会太小,这也就使得,同学们在设计模型的时候,要通盘考虑,如何设计出一款小而精的模型,脱颖而出。
赛题分析至此,干货开始,以下所提到的代码或是数据集,都可以在github上找到,链接:https://github.com/CristXu/smartcar.git。同时,所涉及到的一些专业知识,小编只会简单描述,感兴趣的亲们,可以自行查阅理解,或是私信小编。
首先,我们要找“粮食”——数据集,这是深度学习赖以生存的基础,好的数据集往往能够达到事半功倍的效果。比较通用的一个查找数据集的方法,是利用一类叫做“爬虫“的工具。
网络爬虫实际上就是一个自动提取网页的程序,通过读取网页的URL代码,获取我们想要的图片信息。小编已经为大家准备了一些待训练图片,放到了网上,感兴趣的同学可以优先动手。当然,如果发现训练的效果不是很好,鼓励大家自己对数据集进行扩充。
有了后勤补给,可以开始整军备战了。首先要派出我们的将军,负责统战全局。这里小编推荐Keras担此大任。
Keras是一个用python编写的深度学习API,在机器学习平台Tensorflow上运行,换句话说他以Tensorflow为后端,作为神经网络的推理引擎。最近的Tensorflow也“高清复刻“了Keras的API。
Keras的API非常直奔主题,可以让人尽快地将构想转变为结果,简化研究过程。正如官网对他的评价:简单,灵活,强大。
这里要提醒一下版本匹配,这是开源软件的常见槽点。我们用的是,Keras:2.2.4,Tensorflow: 1.14.0,有条件的同学也可以安装Tensorflow的GPU版本,请注意保持版本一致。
下面开始介绍如何让这位将军听话,乖乖带兵打仗而不会拥兵自重。
Keras有两种排兵布阵的方式,一种是Sequential方式,一种是Function方式。
前者像是穿冰糖葫芦,每一个小兵都是一个单独的个体,小兵之间是顺序排列的,不能前后颠倒,不能互通有无,可以想象成排队报数。而Function方式,像是食堂放饭,各自为战,各自组队,可以一起吃,也可以分开吃,但是,不管怎样,最终我们还是一个整体,还是要去攻占敌军山头的。
简单的说,Sequential方式使用简单,但是,只能搭建那些串行网络。而Function方式,则可以根据不同需求,进行排列布阵,形成各种各样的阵型,搭配到一起使用,就像是编程时候用到的函数。
本文将主要介绍如何利用Sequential方式进行派兵布阵。
为了留给大家足够的发挥空间,小编先抛出一块简陋的砖:定制一个具有3层卷积+1层全连接的简单卷积神经网络。
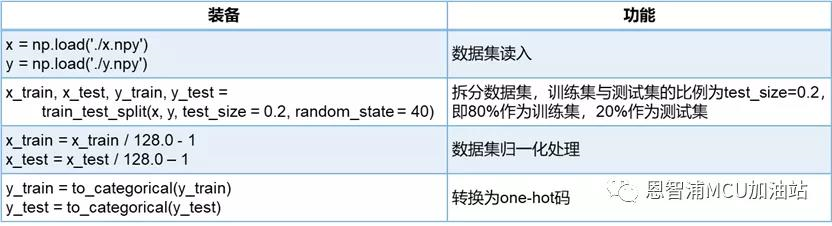
战前准备,用过python的同学都知道,我们要去军火库抬装备:

有了装备和人员编制,食物也要备好。
这里要介绍一个数据预处理的概念,在进行深度神经网络训练时,一般往往要求输入的数据范围在(-1,1)或(0,1)之间,因此,我们要对数据进行归一化处理,并将标签数据转换为one-hot码.
举个栗子,本文要训练一个10分类的网络(对10种物体进行分类),那么要将标签(图片所对应的类别号)转换为长度为10,并且仅有其所对应的类别号的位置的数据为1,其余均为0,这样一组n维向量就被称为one-hot码,以方便网络进行迭代学习。
同时,需要对数据集进行拆分,将其划分为训练集与测试集,训练集用于模型自身迭代,测试集用于诊断模型能力。
粮食备好了,到了号令全军的时候了,拿虎符:
| 虎符 | 功能 |
|---|---|
| model = Sequential() | 声明模型构建模式为Sequential形式 |
布阵, 相信不用再一一报数了,至此我们构建了一个拥有3Conv+1Dense的CNN:
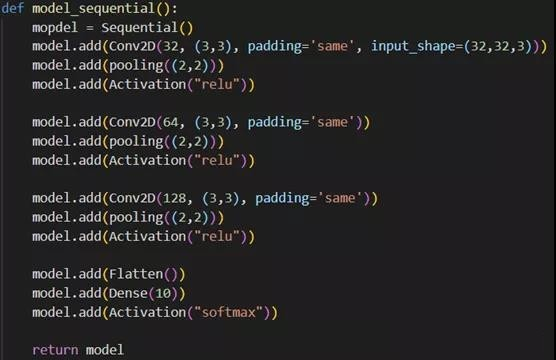
阵型有了,谁来让他们听话呢?政委:优化器要粉墨登场了, 负责模型的调优,这里要强调一点,学习率(lr)的设置有讲究,过大的学习率会提高模型的学习速度,但是太大了可能反而适得其反,还可能会导致模型无法得到最优解;而过小的学习率,会导致训练速度过慢,陷入局部最优不能自拔,选择上要进行试错调整:
指挥官一声令下,等待号令,这里的评价标准,我们选择categorical_crossentropy,这也是专门适用于多分类问题的损失函数:

全军操练, 这里的epochs代表总共迭代遍历数据集多少多少次,batch_size为一次迭代需要使用多少数据。小了能让模型迭代快,但是训练效果容易震荡,还妨碍学到全局特征;大了能让学习过程更平稳,但模型收敛效率会下降,还可能陷入局部最优。

在这里,还要介绍一位好朋友,

这个函数负责模型的保存,会将训练过程中遇到的最好结果即时保存下来。
经过一段等待,我们会得到如下一个喜人的结果,我们的模型在训练集上达到了接近100%的精度,但在测试集上约有68.85%的top1精度,看似不太好。不过,考虑到数据集的质量,还是可以接受的,而且,对于赛题要求,只要top5正确就可以了。当然了,这只是一块砖,期待同学们能弄出更加厉害的模型:

看上面那个不断下降的”loss”,就是在训练集上对误差最主要的评估。
不出意外的话,会在.models/这个文件夹下见到中途保存的模型文件,接下来,我们来介绍如何进行模型的部署。这个模型很小,所以咱们优先使用性能最佳的nncu工具,对于10层以上的大模型,就可能是在大模型上偏重精度的tf更合适了。
同学们应该是已经了解或是知道一个叫做NNCU的传奇工具,可以参考AI机器学习实战之电磁智能车篇,这篇推文里面有对于如何使用NNCU工具的说明。
在此,假设同学们已经转换出了模型,命名曰:model.nncu,c语言形式的调用方式,亦请参考推文。
本文中,为了方便同学们使用,小编和战友们特意添加了python形式的API进行调用,软件会适配在openART套件中,到时,可以联合本教程一同享用。
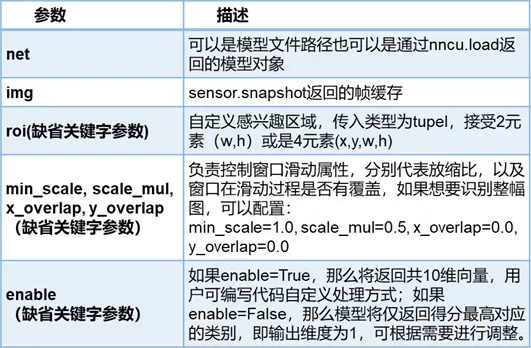
1. 模块导入:import nncu、 2. 模型导入:nncu.load(path,[weit_cache=])

4. 执行:nncu.classify(net, img, [roi=, min_scale=, scale_mul=, x_overlap=, y_overlap=, enable=])
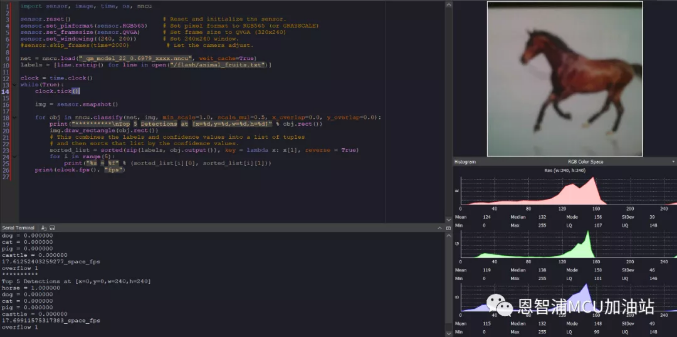
实机运行结果如下,模型文件名称为_qm_model_22_0.6979_xxxx.nncu,还有需要注意的是标签文件路径需要动态调整,例如小编将标签文件放到了位于flash上的文件系统,如果同学们插入了sd卡,这个路径要相应的修改为/sd/animal_fruits.txt:
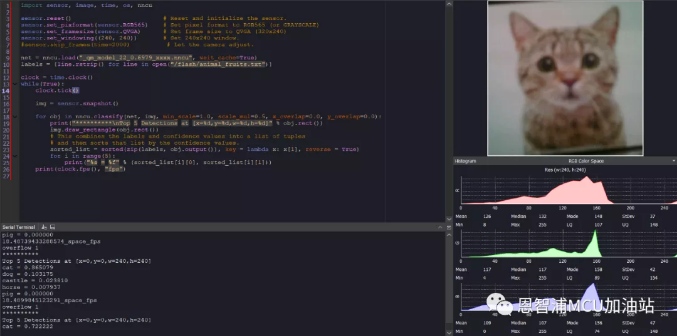
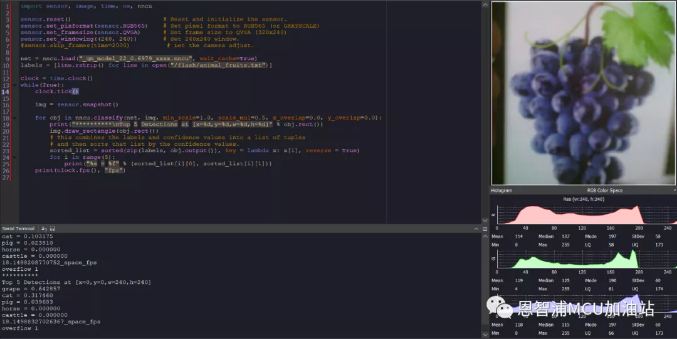
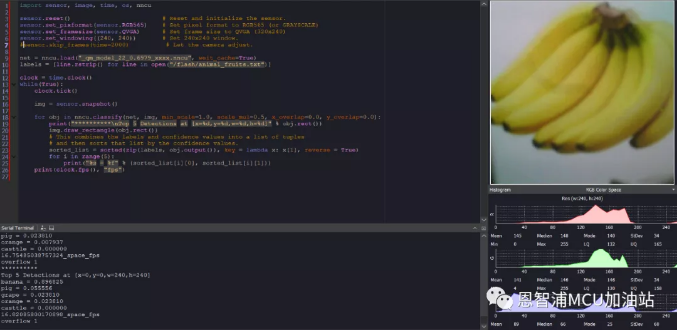
至此,完成了从数据集制备到模型部署的所有工作,同学们是不是已经迫不及待要上手一试了呢?
没有板子的同学,可以先在PC上优化模型,代码可参考我传到github的代码,train.py 和test.py分别用来模型的训练以及测试,欢迎大家踊跃提问,文中所有用到的模型,数据集,以及脚本文件均存放于github上。
再重复一遍链接:https://github.com/CristXu/smartcar.git
注:本文来自于恩智浦MCU加油站的推文:智能车大赛AI视觉组参考答案
