
目录
在日常技术探索的漫漫长路上,不经意的瞬间总能触发一段新奇旅程。就像今天,我随手点开 “LeetCode” 官网,指尖轻触 “题库”,瞬间被拉回了几年前的青涩时光 —— 我的刷题记录竟还定格在那道经典的 “两数之和”,彼时初涉力扣的青涩模样如在眼前。
心里犯起嘀咕,当年这题莫不是靠着答案才勉强通过?一股不服输的劲儿涌上心头,当下决定花两分钟重温旧题。本以为手到擒来,代码在键盘上噼里啪啦敲完,自信满满地提交,没想到换来的却是无情的 “运行错误”。
屏幕上那刺眼的提示,像极了学生时代考试失利的红灯。要是换做屏幕前的你,能一举拿下这道题吗?来吧,让我们一同深入剖析这道 “LeetCode” 必刷之 “两数之和”,看看其中暗藏哪些玄机。
给定一个整数数组nums 和一个整数目标值target,请你在该数组中找出和为目标值target 的那两 个整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1]
初涉此题,多数人脑海里蹦出的第一招便是暴力枚举。
通俗来讲,就是一股脑遍历整个数组,逐个寻觅target - x 的身影。不过这里头有个小窍门,前面已经 “验过” 的元素就没必要再跟当前元素x 配对了,毕竟题目限定每个元素只能用一次,所以目光只需聚焦在x 后面的元素群里找target - x 就行。
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
for (int i = 0; i < numsSize; ++i) {
for (int j = i + 1; j < numsSize; ++j) {
if (nums[i] + nums[j] == target) {
int* ret = malloc(sizeof(int) * 2);
ret[0] = i, ret[1] = j;
*returnSize = 2;
return ret;
}
}
}
*returnSize = 0;
returnNULL;
}
时间复杂度:O(N2),其中 N 是数组中的元素数量。最坏情况下数组中任意两个数都要被匹配一次。
空间复杂度:O(1)。
说起来,这题对基础薄弱的小伙伴不太友好,就像我,一开始愣是没瞅见注释,把结算结果错塞到returnSize 里,闹了个不大不小的笑话。
仔细琢磨,暴力枚举之所以耗时,症结就在于找target - x 时太 “磨蹭”,时间复杂度居高不下。那有没有 “快刀斩乱麻” 的妙招呢?哈希表应运而生,它就像一把精准导航的钥匙,能闪电般定位目标元素,把找target - x 的时间复杂度从 O (N) 断崖式降至 O (1)。
struct hashTable {
int key;
int val;
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(int ikey) {
struct hashTable* tmp;
HASH_FIND_INT(hashtable, &ikey, tmp);
return tmp;
}
void insert(int ikey, int ival) {
struct hashTable* it = find(ikey);
if (it == NULL) {
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey, tmp->val = ival;
HASH_ADD_INT(hashtable, key, tmp);
} else {
it->val = ival;
}
}
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
hashtable = NULL;
for (int i = 0; i < numsSize; i++) {
struct hashTable* it = find(target - nums[i]);
if (it != NULL) {
int* ret = malloc(sizeof(int) * 2);
ret[0] = it->val, ret[1] = i;
*returnSize = 2;
return ret;
}
insert(nums[i], i);
}
*returnSize = 0;
returnNULL;
}
在第一层循环里面,先去哈希表中查找是否有 key 为target - nums[i]的值,如果查到了就分配一片空间并将计算结果返回,反之就将键值对nums[i], i插入哈希表中。
为了让大伙理解更透彻,特意奉上一张官方视频讲解中的配图(见下图),图文并茂,一目了然。
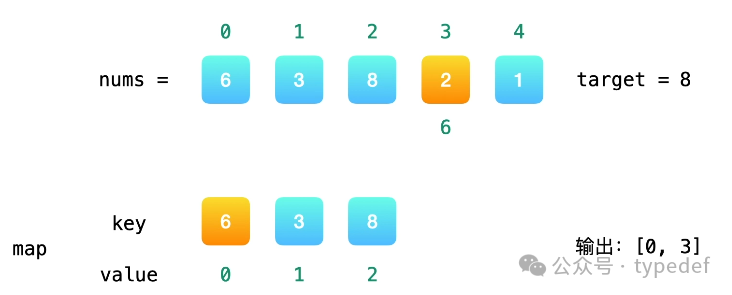
顺带提一嘴,后面章节会详细拆解 UT_hash_handle 以及 HASH 函数,这里先卖个小关子。
时间复杂度:O(N),其中 N 是数组中的元素数量。对于每一个元素 x,我们可以 O(1) 地寻找 target - x。
空间复杂度:O(N),其中 N 是数组中的元素数量。主要为哈希表的开销。
值得留意的是,官方解法也并非十全十美,像struct hashTable* hashtable 定义哈希表时忘了初始化指针,这可是个暗藏隐患的 “雷区”。uthash 作者再三强调,此处务必初始化为 NULL。

大伙日常写代码可得长点心,野指针这玩意儿,一旦冒头,那就是程序崩溃的 “定时炸弹”。
这道题一抛出,网友们的吐槽那叫一个热闹非凡,让我们来看一下吧。
有人相爱,有人夜里开车看海,有人leetcode第一题都做不出来。
哈希表是什么、我连两个for都想了很久,你给我说哈希表。
别跟我谈什么空间复杂度,时间复杂度,我解题就是一手暴力枚举,自信提交,运行错误。
是谁力扣第一题都做的磕磕巴巴,原来是我。
看题之前我是心高气傲,看题之后我是生死难料。
单纯c语言角度看,这题用c 比用其他语言要麻烦,因为一上来就涉及到了最麻烦的指针。
哈希表,你太让我陌生了。
我开发到现在也没用到哈希算法。
今天咱就抱着学习的态度来学习一下哈希表。
哈希表是一种高效的数据结构,它通过哈希函数将键(Key)映射到表中的位置,从而实现快速查找、插入和删除操作。
哈希函数将键转换为数组索引,使得每个元素都能直接定位到其存储位置,理想情况下,这种映射关系使得查找、插入和删除操作的时间复杂度接近 O(1)。
在使用哈希表求解时,结构体中使用了一个UT_hash_handle类型,这个类型是什么?在哪里?
C语言的标准库中没有哈希表的函数可以使用,需要包含第三方头文件uthash.h,第三方库链接放到最后了。
UT_hash_handle类型在uthash.h头文件定义如下,通过其中的成员看出是通过双向链表实现哈希表的。
typedef struct UT_hash_handle {
struct UT_hash_table *tbl;
void *prev; /* prev element in app order */
void *next; /* next element in app order */
struct UT_hash_handle *hh_prev; /* previous hh in bucket order */
struct UT_hash_handle *hh_next; /* next hh in bucket order */
constvoid *key; /* ptr to enclosing struct's key */
unsigned keylen; /* enclosing struct's key len */
unsigned hashv; /* result of hash-fcn(key) */
} UT_hash_handle;
uthash 是一款极为精巧的工具,代码量仅约 1000 行 C 代码。它借助宏的形式巧妙实现,进而天然具备内联特性。它对哈希表项目的操作提供了完备支持,在功能层面,支持如下操作。
#include /* printf */
#include /* atoi, malloc */
#include /* strcpy */
#include "uthash.h"
struct my_struct {
int id; /* key */
char name[21];
UT_hash_handle hh; /* makes this structure hashable */
};
struct my_struct *users = NULL;/* important! initialize to NULL */
void add_user(int user_id, const char *name) {
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* id already in the hash? */
if (s == NULL) {
s = (struct my_struct*)malloc(sizeof *s);
s->id = user_id;
HASH_ADD_INT(users, id, s); /* id is the key field */
}
strcpy(s->name, name);
}
struct my_struct *find_user(int user_id) {
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* s: output pointer */
return s;
}
void delete_user(struct my_struct *user) {
HASH_DEL(users, user); /* user: pointer to deletee */
free(user);
}
void delete_all() {
struct my_struct *current_user;
struct my_struct *tmp;
HASH_ITER(hh, users, current_user, tmp) {
HASH_DEL(users, current_user); /* delete it (users advances to next) */
free(current_user); /* free it */
}
}
void print_users() {
struct my_struct *s;
for (s = users; s != NULL; s = (struct my_struct*)(s->hh.next)) {
printf("user id %d: name %s\n", s->id, s->name);
}
}
int by_name(const struct my_struct *a, const struct my_struct *b) {
returnstrcmp(a->name, b->name);
}
int by_id(const struct my_struct *a, const struct my_struct *b) {
return (a->id - b->id);
}
const char *getl(const char *prompt) {
staticchar buf[21];
char *p;
printf("%s? ", prompt); fflush(stdout);
p = fgets(buf, sizeof(buf), stdin);
if (p == NULL || (p = strchr(buf, '\n')) == NULL) {
puts("Invalid input!");
exit(EXIT_FAILURE);
}
*p = '\0';
return buf;
}
int main() {
int id = 1;
int running = 1;
struct my_struct *s;
int temp;
while (running) {
printf(" 1. add user\n");
printf(" 2. add or rename user by id\n");
printf(" 3. find user\n");
printf(" 4. delete user\n");
printf(" 5. delete all users\n");
printf(" 6. sort items by name\n");
printf(" 7. sort items by id\n");
printf(" 8. print users\n");
printf(" 9. count users\n");
printf("10. quit\n");
switch (atoi(getl("Command"))) {
case1:
add_user(id++, getl("Name (20 char max)"));
break;
case2:
temp = atoi(getl("ID"));
add_user(temp, getl("Name (20 char max)"));
break;
case3:
s = find_user(atoi(getl("ID to find")));
printf("user: %s\n", s ? s->name : "unknown");
break;
case4:
s = find_user(atoi(getl("ID to delete")));
if (s) {
delete_user(s);
} else {
printf("id unknown\n");
}
break;
case5:
delete_all();
break;
case6:
HASH_SORT(users, by_name);
break;
case7:
HASH_SORT(users, by_id);
break;
case8:
print_users();
break;
case9:
temp = HASH_COUNT(users);
printf("there are %d users\n", temp);
break;
case10:
running = 0;
break;
}
}
delete_all(); /* free any structures */
return0;
}
https://leetcode.cn/problems/two-sum/solutions/434597/liang-shu-zhi-he-by-leetcode-solution/https://github.com/troydhanson/uthashhttps://troydhanson.github.io/uthash/userguide.html在日常的开发工作里,大家有没有像我这般,基本就靠着if、switch、for 这些基础语句结构一路“闯荡江湖”,很少主动去调用那些精妙复杂的算法呢?
真挺好奇的,评论区留下你的答案。
END
点赞、转发加关注,一键三连,好运年年
关注公众号后台回复数字688或668可获取嵌入式相关资料
往期推荐
为什么推荐大家去考软考高级,因为政府补贴已到账

程序员必看:浮点数精度问题全解析

C语言编程新手:如何判断结构体(struct)相等?
加个变量,程序崩了

