

在本文来自于encord,从VLM 算法架构,原理,到应用方向,挑战难点方面探讨VLM 的架构、评估策略和主流数据集,以及该领域的主要挑战和未来趋势。 通过了解这些基础方面,读者将深入了解如何将 VLM 应用于医疗保健、机器人和媒体等行业,汽车行业属于机器人板块,熟悉VLM可以帮助理解当前自动驾驶产品,算法挑战以及发展趋势。 是一篇带有深度的科普文章,文章比较长而且需要一定的算法基础和强烈兴趣爱好来读。
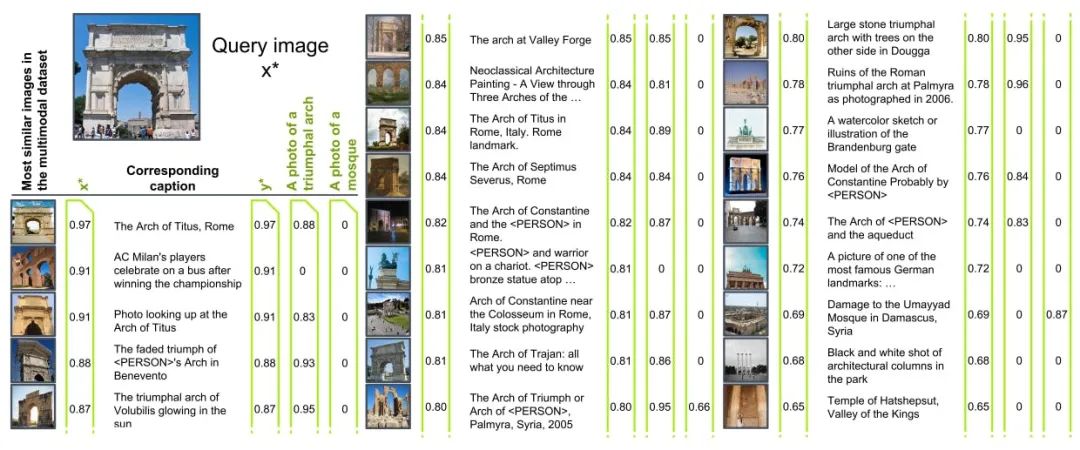
对比学习。
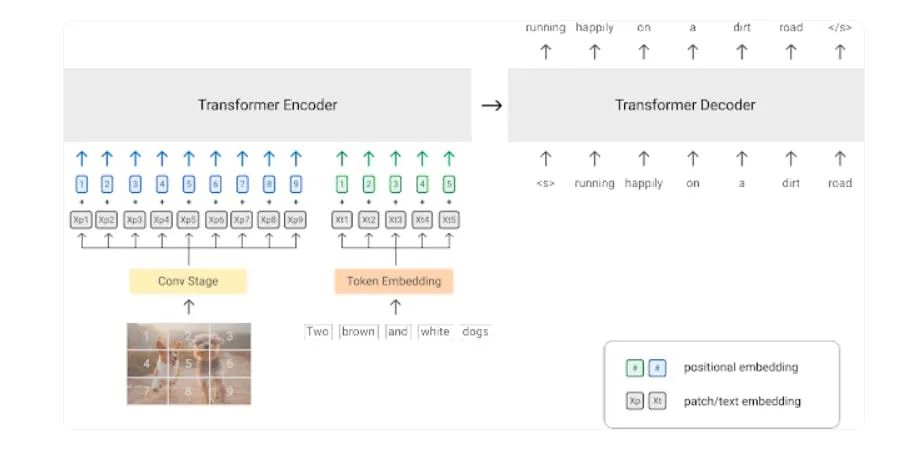
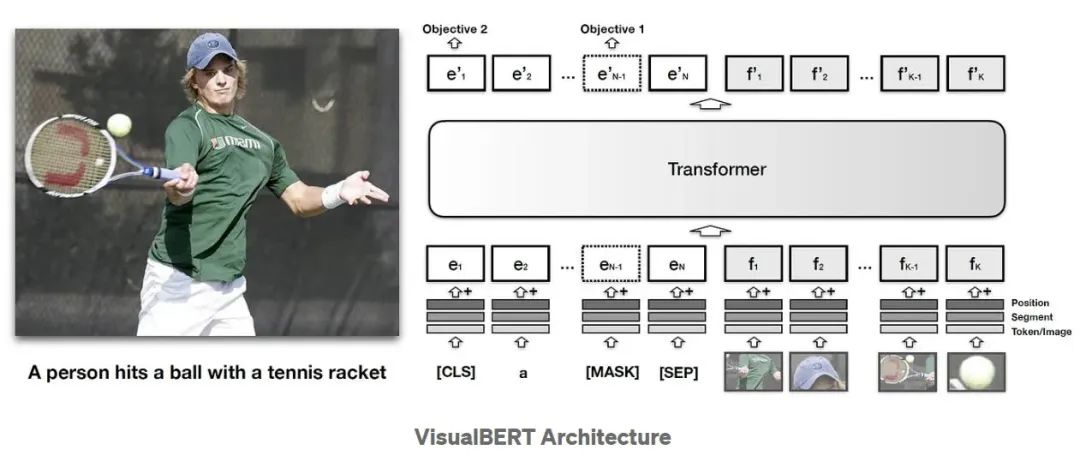
掩蔽语言图像建模。

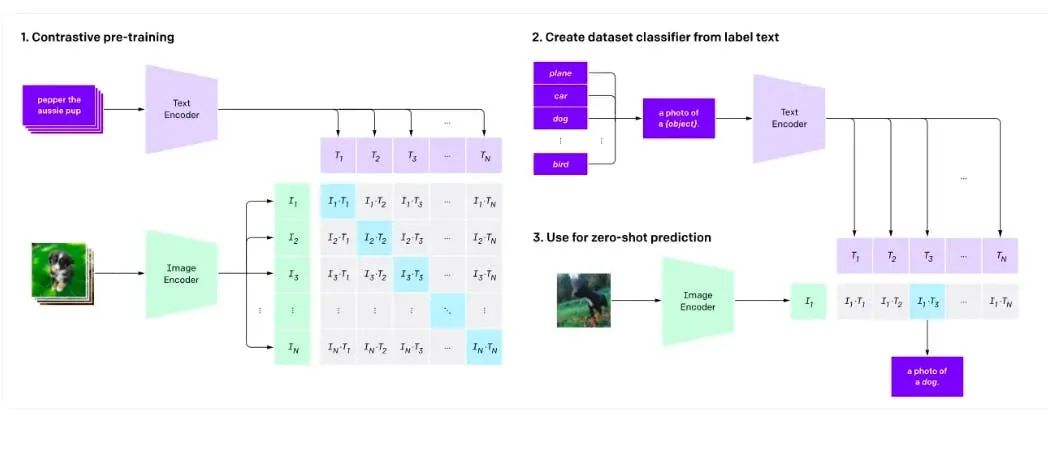
在预训练期间训练文本和图像编码器以学习图像-文本对。
将训练数据集类别转换为标题。

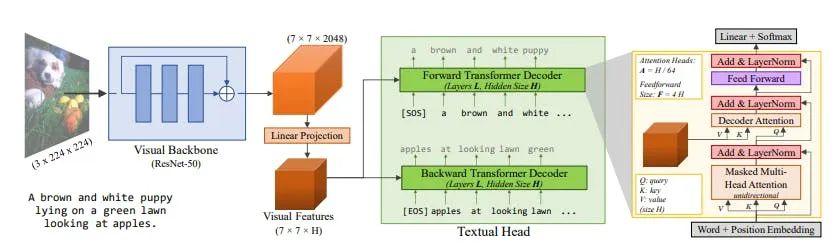
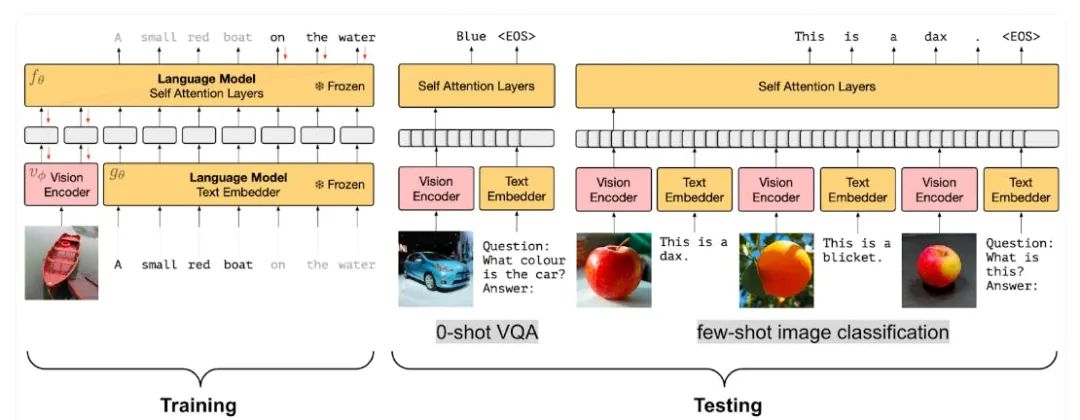
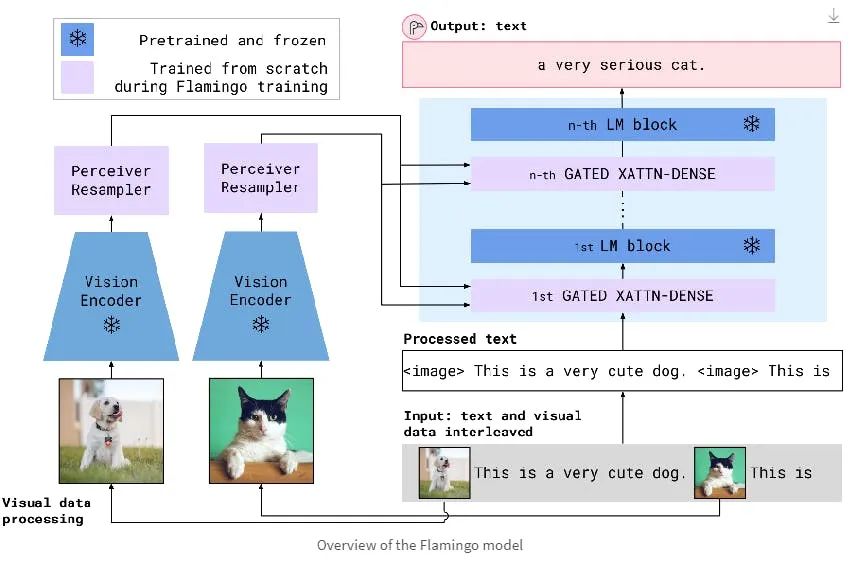
Frozen Architecture
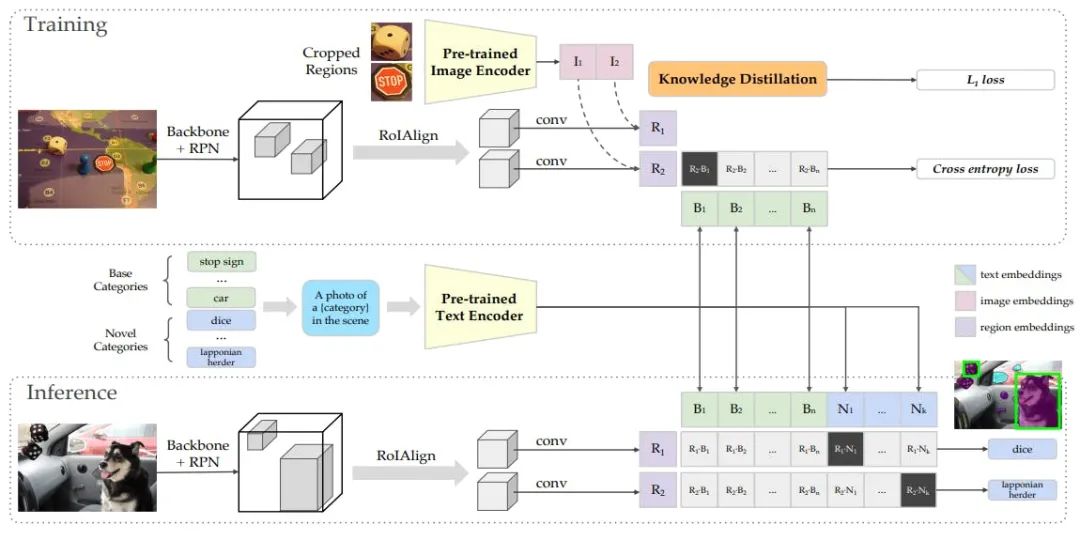
模型复杂性。
数据集偏差。



视觉语言模型是一种同时理解图像和文本数据模式的多模式架构。
他们使用 CV 和 NLP 模型来关联来自两种模态的信息(嵌入)。
存在几种 VLM 架构,旨在将视觉语义与文本表示关联起来。
尽管用户可以使用自动评分来评估 VLM,但更好的评估策略对于构建更可靠的模型至关重要。
*未经准许严禁转载和摘录-参考资料:

相关推荐
AI 巨头 Nvidia 英伟达在汽车领域做什么?
