
缘起:Open-Channel
01
1.1 Open-Channel SSD的出现
传统的NVMe SSD,对于上层的系统来说,是一个通用型的块设备层。由3于使用和磁盘相同的通用块I/O接口,传统NVMe SSD的控制权并不在SSD。受该接口限制,传统SSD的FTL具有一定局限性,因而成为了SSD性能和效率的瓶颈。这些限制包括SSD底层策略,例如:数据放置位置、I/O调度、磨损均衡、以及其他涉及SSD的应用效能优化。这些缺点并不是由于硬件限制引起的,而是传统NVMe SSD设计决定的。这时候,一种新的想法Open-Channel开放接口SSD产生了,顾名思义,开放接口把SSD底层接口开放给主机,这样做有什么好处呢?
· 主机控制权
主机端可以根据自身的业务来控制盘的行为,包括写入顺序,写在哪个NAND的Block上,什么时候擦除和写入,取代传统的SSD firmware控制权。基于主机对自身读写行为及业务运行的负载感知了解,可以从主机端直接进行优化处理。
· I/O隔离
对于用户端应用架构(multitenant architecture),I/O隔离有助于解决由于物理资源共享导致不同逻辑分区不可避免地影响到彼此的性能表现,Open-Channel SSD里面的每个PU(NAND操作基本单元)在物理上是隔离的,主机端可以决策对哪个PU物理位置进行操作。
· 可预测和可控制的命令时延
由于主机控制所有命令的操作,并知道每一个物理PU上正在执行的(或者pending的)所有NAND操作,所以主机对自己下发后的读写命令时延就有准确的把握。
1.2 Open-Channel SSD的实现
为了实现上述功能和控制,Open-Channel SSD实现了把大部分传统NVMe SSD FTL功能从SSD Firmware内部迁移到上层的主机端,迁移的功能有Data Placement, Garbage Collection, L2P table , I/O Scheduling, Wear Leveling等。
FTL功能上移后,为了实现上述功能,Open-Channel SSD将本来位于NVMe SSD上Firmware中的对NAND Flash管理和控制的部分功能,交给了主机端的应用软件。让应用根据自身的业务特点,对盘上的NAND Flash进行有效的管理,如下图所示。很多情况下,主机端的应用管理,可以有效避免垃圾回收等后台操作对前端应用I/O请求的影响,更好控制QoS和延迟。
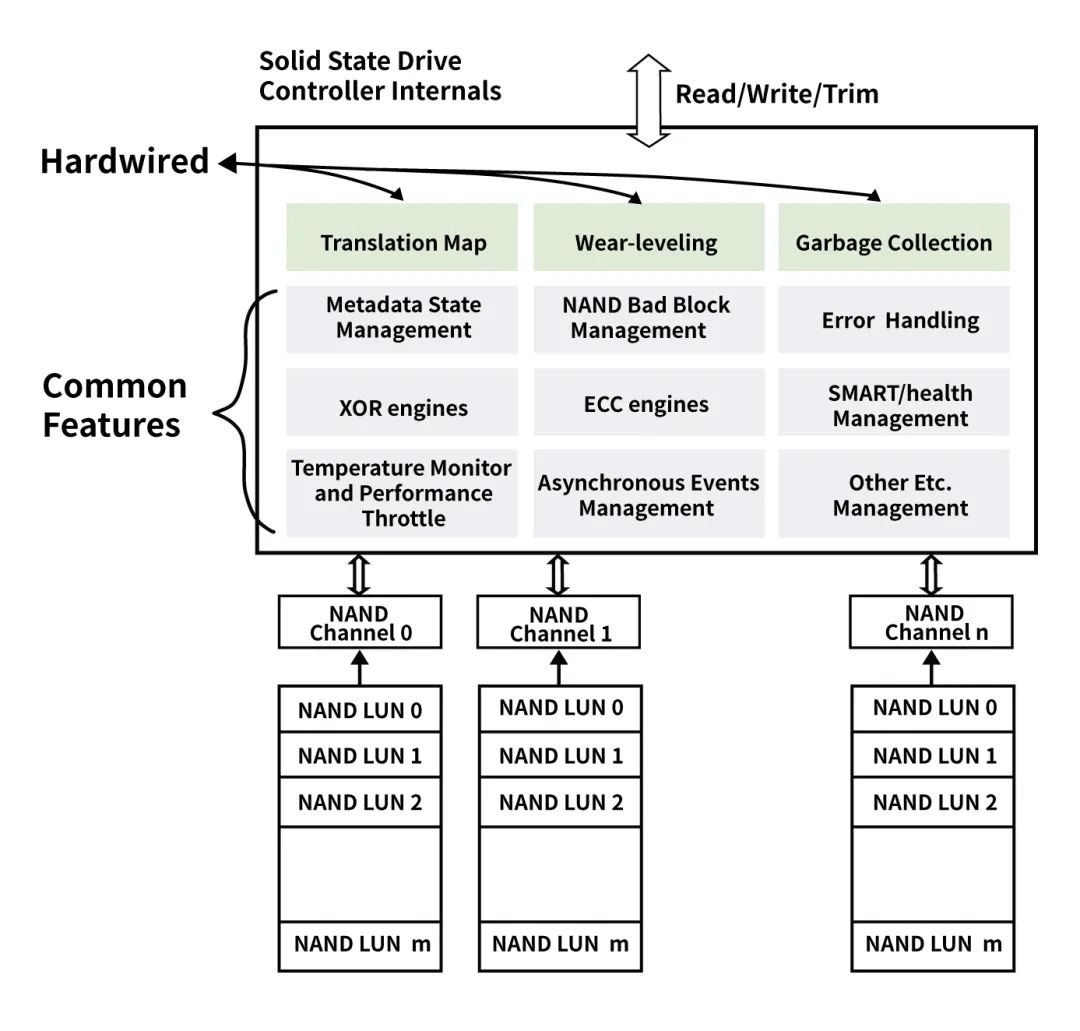 普通NVMe SSD架构
普通NVMe SSD架构 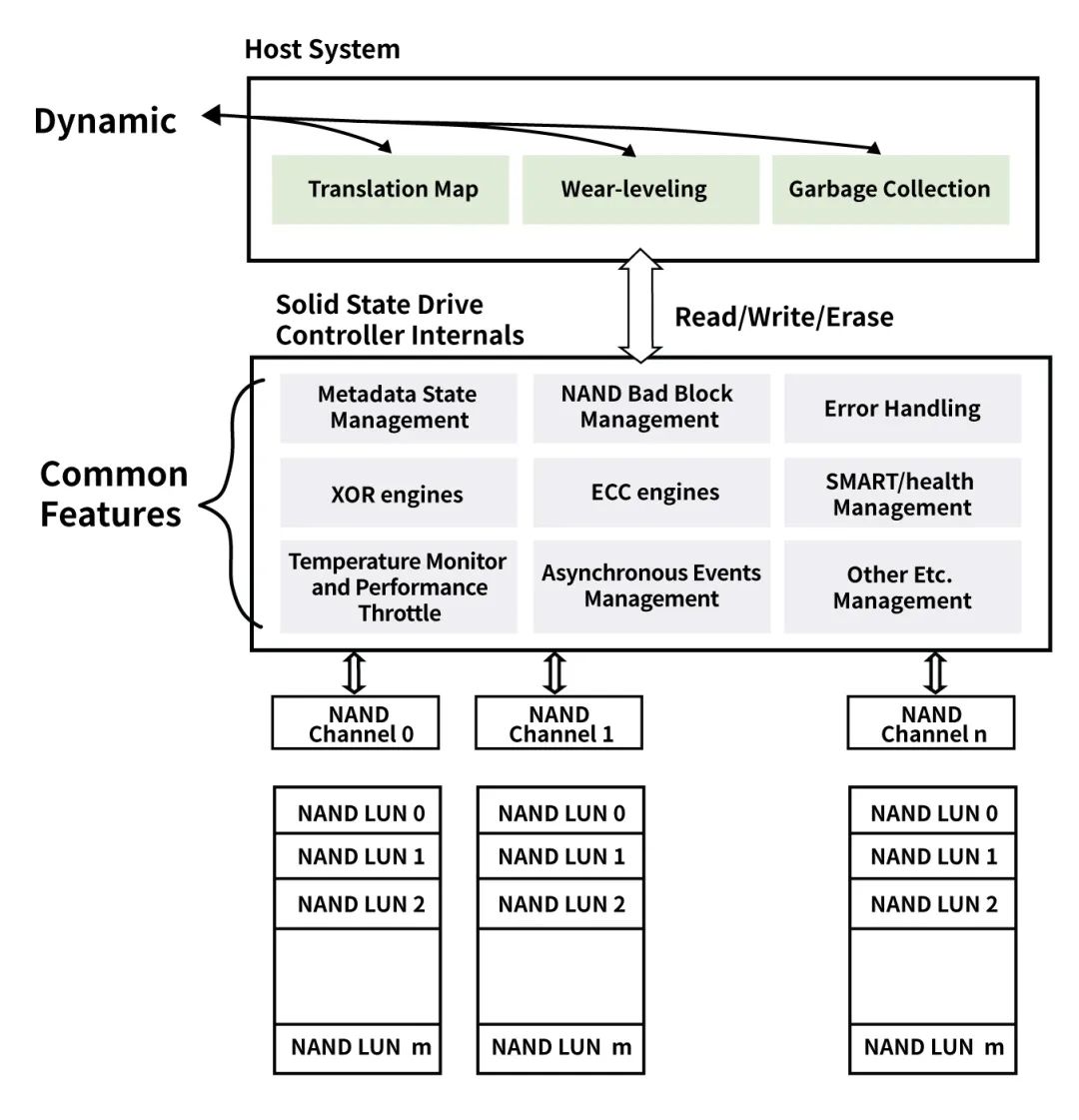
Open-Channel SSD架构
与此同时,Open-Channel SSD向主机展示出内部NAND布局的细节,主机可以决定数据实际存放的物理位置。这样,Host就可以根据IO请求的发起方,将IO 数据写到不同的位置,实现不同应用、用户数据的物理隔离,达到更好的QoS效果。
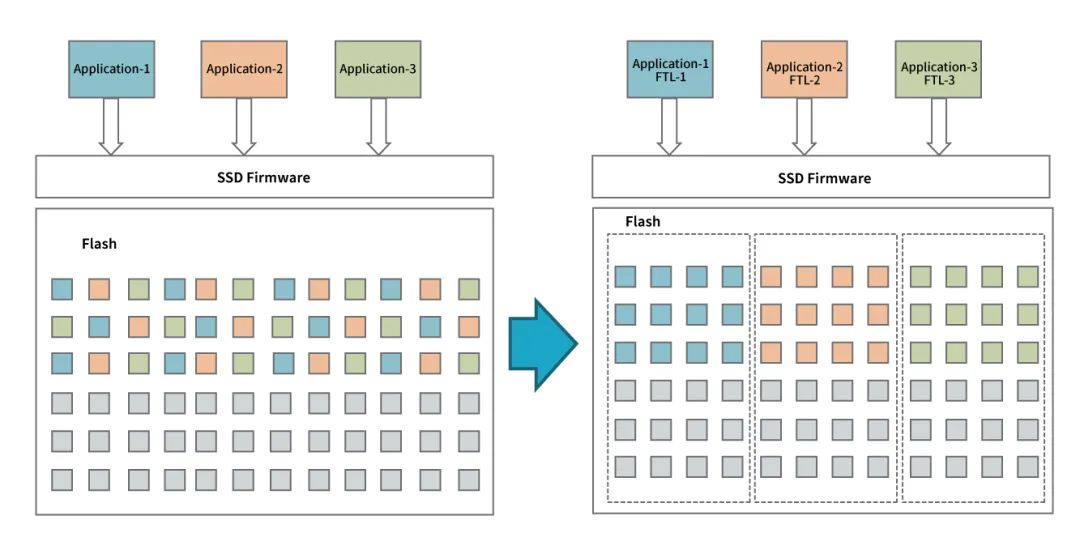
传统NVMe SSD vs Open-Channel SSD NAND布局 (来源[2])
为了实现NAND物理位置的定义,Open-Channel Spec定义了[3]:
· Chunk
Chunk是指一系列连续的逻辑块。在一个Chunk内,主机侧只能按照逻辑块地址LBA顺序写入,如果要重新写入前面写过的某个逻辑块,需要重启该逻辑块所在的Chunk。
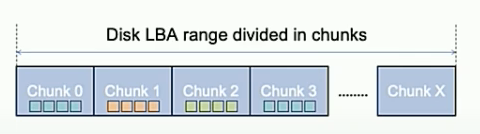
Chunk示意图
· 并行单元(Parallel Unit,PU)
SSD是通过并行操控闪存来实现高速读写的。PU是SSD内部并行资源的一个单位,主机侧可以指定数据写到哪一个PU上,一个PU可能包含一个或多个闪存Die。
· 不同的PU可以完全做到物理隔离;
· 值得说明的是,在最新的NVMe协议里面,I/O determinism已经解决了物理隔离的问题,而在Open-Channel提出的时候,尚没有标准解决方案,这也是Open-Channel的价值所在。
Chunk和PU逻辑拓扑图如下:
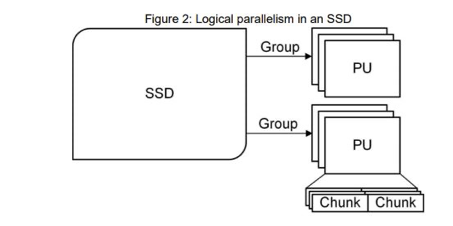
Open-Channel SSD逻辑拓扑图
· 很多Chunk组成了PU;
· 很多PU组成了Group(其具体定义,请读者参阅Open-Channel 协议);
· 很多Group组成了SSD。
在Open-Channel SSD中的逻辑块地址(LBA)的概念被重新定义,它包含了PU、Chunk和Group的信息。

LBA Encoding格式
从实际应用的部署情况来看,Open-Channel SSD主机端实现了一个复杂的FTL(Flash Translation Layer), 替代SSD中本已健壮成熟的Firmware层实现的功能,来管理NAND flash和数据存放。而且Open-Channel Specification 仅仅定义了Open-Channel涉及的最为通用的部分。不同厂商的SSD产品特性不同,它们或者难以统一,或者涉及敏感内容,不便公开,实际Open-Channel产品往往在兼容Open-Channel Spec的基础上,各有一部分私有定义。不同业务方的需求独特,往往需要在自己的FTL内加入定制化的内容。因此,至今尚未有通用的Open-Channel SSD和针对独特业务的通用FTL。这些制约严重影响了Open-Channel的发展速度。
当前全球市场,实现了Open-Channel SSD商用的厂商只有Shannon Systems。部分互联网头部厂商基于Shannon Systems的代码和产品定制化自己的Open-Channel SSD产品用于业务效能提升。
进化:ZNS更进一步
02
2.1 Open-Channel SSD的缺点
然而Open-Channel也有以下缺点:
· 需要主机侧软件层面的支持,或者重新增加一个软件层来匹配原来的软件堆栈。目前其软件生态并未完善,有些上层应用需要的改动比较大;
· 主机侧存储开发人员需要透彻了解SSD内部原理,并且实现定制的FTL;
· 主机侧与SSD分工协作复杂,尤其是在处理后端纠错过程,以及解决数据在闪存上的数据磨损问题的时候。
最后为了规避上述问题,有没有可能既可以做到允许主机侧尽量自由摆放数据,同时有标准的软件生态呢?答案就是ZNS,它作为Open-Channel的下一代协议被提出来。ZNS协议由NVMe工作组提出,旨在:
· 标准化Zone接口;
· 减少设备端的写放大问题;
· 更好配合上层软件生态;
· 减少OP,节省客户成本;
· 减少DRAM使用,毕竟DRAM在SSD中的成本举足轻重;
· 增加带宽,减少时延。
那ZNS都说了什么?什么是Zone?以及它能否以及如何达成上述目标呢?
2.2 ZNS实现模型
Zoned Namespace NVME Spec起草作者和Open-Channel SSD Spec作者是同一人,两个标准有很大的相似性,所以ZNS可以说是Open-Channel的进化,是在Open-Channel基础上更加商业化和标准化的实现。
相对于传统的NVMe Namespace, Zoned Namespace将一个Namespace的逻辑地址空间切分成多个Zone。如下图所示,Zone是Namespace内的一种固定大小的子区间,每个Zone都有一段LBA(Logical Block Address, 逻辑地址空间)区间,这段区间只能顺序写,而且如果要覆盖写,则必须显示的进行一次擦除操作。这样,Namespace就可以把NAND内部结构的边界透露给主机,也就能够将地址映射表等内部管理工作交由主机去处理,从而减少写放大、选择合适的GC(Garbage Collection, 垃圾回收)时机。
Zone的基本操作有Read, Append Write,Zone Management 以及Get Log Page,如下图所示。Zone大小可以采用Open-Channel中Chunk的大小为单位,即与NAND介质的物理边界为单位。Zone Log Page也会与Open-Channel Spec 2.0中的Chunk Info Log相似。
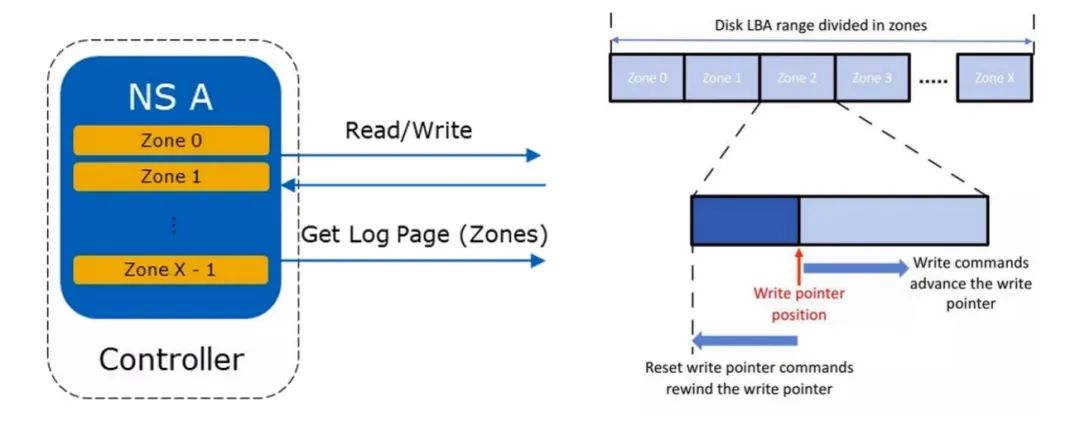
Zone的基本操作
与Open-Channel相比,Zone的地址是LBA(Logical Block Address, 逻辑块地址),Zone X的起始地址与Zone X-1的结束地址相连,Zone X的结束地址与Zone X+1的起始地址相连,Zone的容量总是小于等于Zone的逻辑大小。这样一来,Zone Namespace就可以避免Open-Channel里繁琐的各类地址转换。

Zone的大小和地址示意图
对比传统NVMe SSD,Zoned Namespace优点:
· 更高效的垃圾回收GC操作
机械硬盘中文件系统可以直接将新数据写入到旧数据存储的位置,可以直接覆盖旧数据。在固态硬盘中,如果想让某个存有无效数据的块写入新数据,就需要先把整个块擦除,才可以写入新的数据。固态硬盘并不具备直接覆盖旧数据的能力,所谓GC(垃圾回收)是指把目标擦除位置现存有效数据重新转移到其他闪存位置,然后把包括无效数据的该位置彻底擦除的过程。ZNS把LBA直接展示给上层应用,由上层应用来调度的GC操作,ZNS SSD由于Zone内顺序写、无覆盖写因此GC操作比Open Channel更高效可控, 从而性能也比较稳定。
· 延迟可预测
传统的NVMe SSD GC的时机和耗时对于应用是不可控的,ZNS读、写、擦和GC的实际完全由主机和应用掌控,相比于传统NVMe SSD延迟表现更稳定。
· 减少OP
传统NVMe SSD会预留一部分空间(Over Provisioning)用于垃圾回收GC和磨损均衡WL,通常OP空间占整个SSD容量的7-28%,OP空间对用户时不可见的。ZNS SSD有更高效的GC机制,除了保留极少量OP空间用于替换坏块,并没有其他会大量消耗NAND空间的情况,并且ZNS固件本身所需要的运行空间远低于传统NVMe SSD。
· 成本更低
ZNS的架构特点,导致可以使用更少的DRAM,以及更少的OP,因此相对传统NVMe SSD的成本有较大程度的降低。
最后,综上ZNS有着以上的理论优势,实测性能如何呢?如下图[1],ZNS SSD由于Zone内顺序写、无覆盖写及可控的GC操作等特性,同样稳态满盘条件下,ZNS盘展现出的写性能和原始Host写数据带宽呈线性1:1关系,无由盘内数据搬移如垃圾回收导致的写性能损失。同时在线性增长的Host写数据带宽条件下(0-1GiB/s),ZNS SSD展现出可预测的读时延(线性增加)。
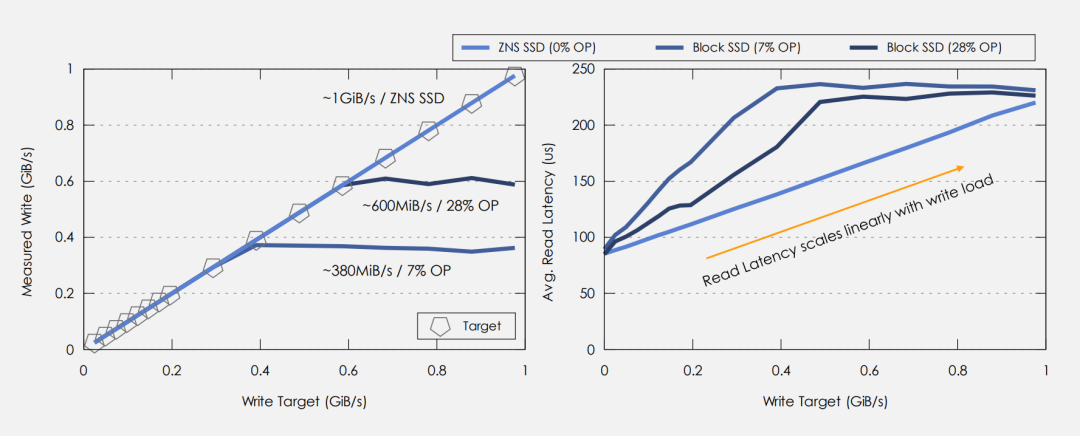
ZNS vs 传统SSD展现的Raw IO特性
实例:Shannon Systems SP4
ZNS盘评测 SP4 ZNS SSD介绍
03
1) SP4 ZNS 固件特性:
Support 8 Open Zone
Support 4K over-write
Zone Index:
Zone Capacity:8~9 GB
Active Zone/Open Zone Number(max):8
Total Capacity:8 TB
2) FIO Benchmark
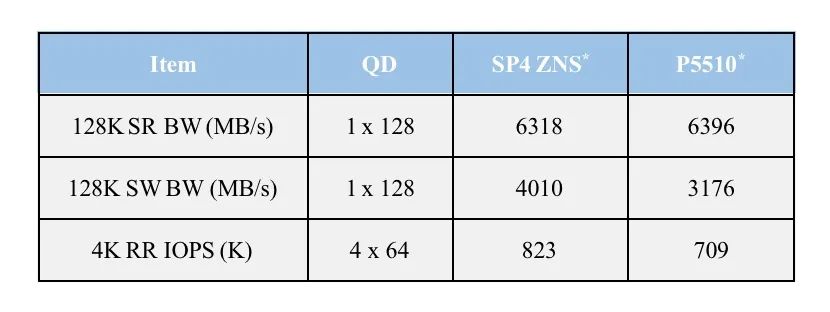
* SP4 ZNS in FIO zbd mode; P5510 in FIO regular mode
结论:SP4 ZNS盘在FIO zbd模式下的性能测试,相比较于P5510传统盘模式下的测试,128K连续读性能基本相同,但128K连续写性能提升26%,4K随机读性能提升16%。
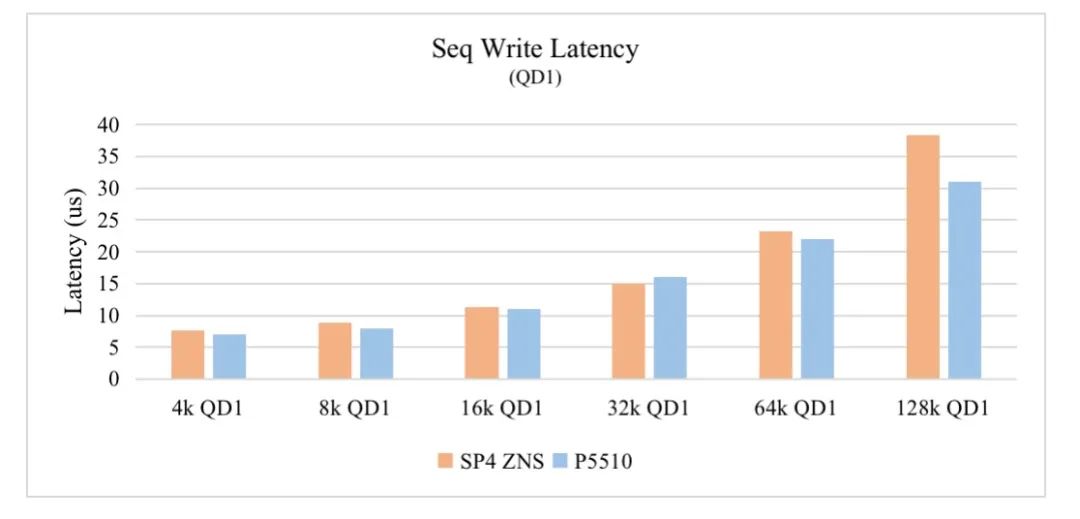
SP4 ZNS vs P5510 QD1连续写时延对比
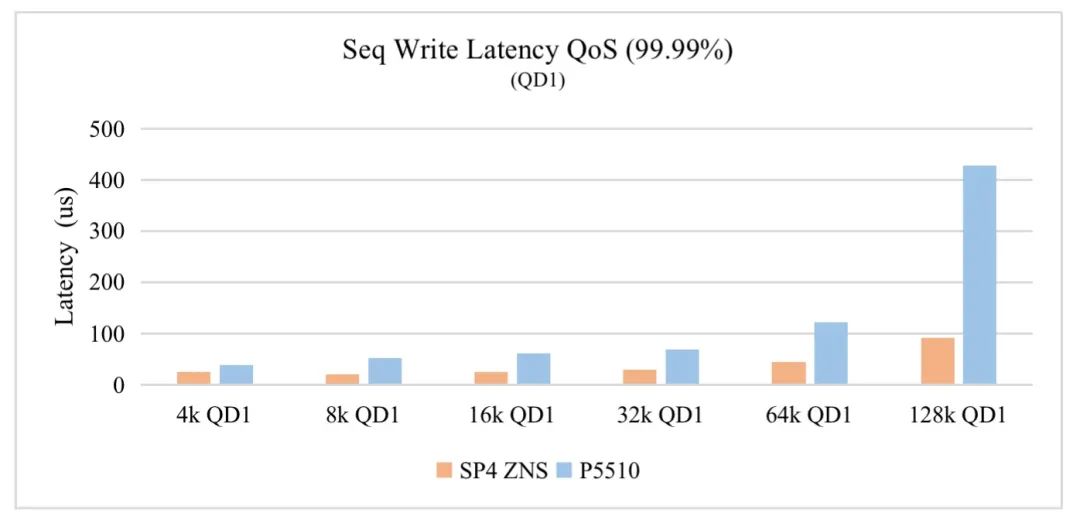
SP4 ZNS vs P5510 QD1连续写99.99%时延对比

SP4 ZNS vs P5510 QD1随机读时延对比
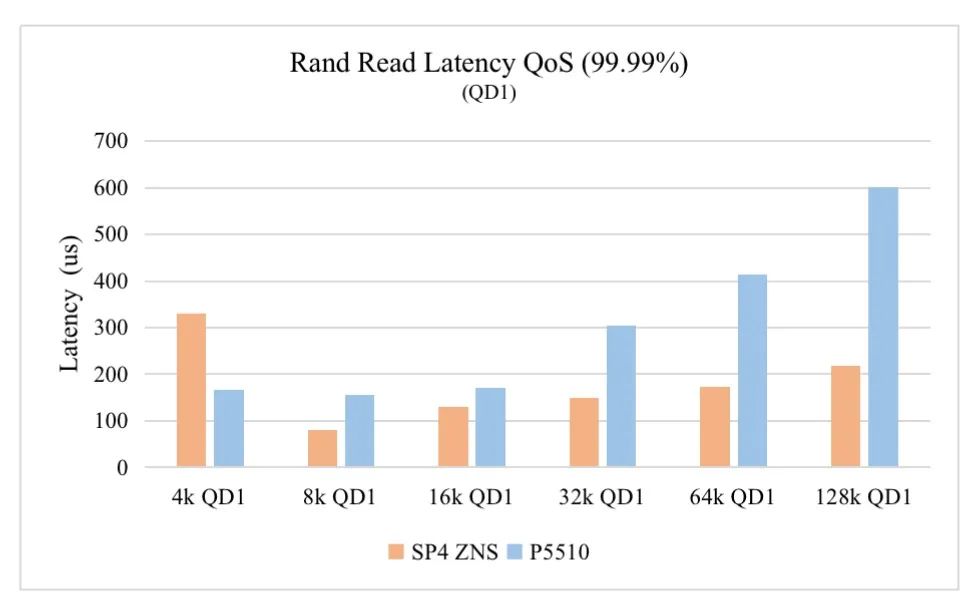
SP4 ZNS vs P5510 QD1随机读99.99%时延对比
结论:相比较P5510, SP4 ZNS盘连续写和随机读 QD1时延,不同的Sector Size下,均不同程度的大幅减少,例如128K QD1 99.99% QoS, 连续写是P5510的1/4, 随机读是P5510的1/3。同样8K/16K/32K/64K QD1 99.99% QoS对比参见如上图表。
ZNS生态探索:
RocksDB + ZenFS + ZNS SSD
04
1) 通用数据库引擎和NAND Flash物理特性的冲突
机械硬盘可以对一个块原地修改,但是NAND Flash因为使用寿命和物理特性的限制(块擦写次数寿命,块写前要先擦除),需要最大限度均衡地写所有块,频繁读写Flash上的同一个块,会快速缩短这个块的寿命。基于这个原因,要求对NAND Flash上的块进行顺序写,即写完一个块后写下一个块。数据库存在很多频繁更新数据的场景,这些数据很多时候都会位于不同的块上,此时需要把要修改的块的数据拷贝出来,修改后写入一个新的块,并把旧块标记为可回收,这个Copy-Write Back过程会浪费性能。所以,一种符合闪存物理特性的数据库引擎对提升数据库和闪存性能很重要。
2) RocksDB一种专为闪存设计的数据库
针对闪存的物理特性,出现了一批新型数据库,知名度和使用最广泛的是RocksDB,从LevelDB发展而来的KV数据库。RocksDB特点是对于WAL日志只会append,对于已经落盘的数据文件不会修改,这是针对闪存特性做的设计。
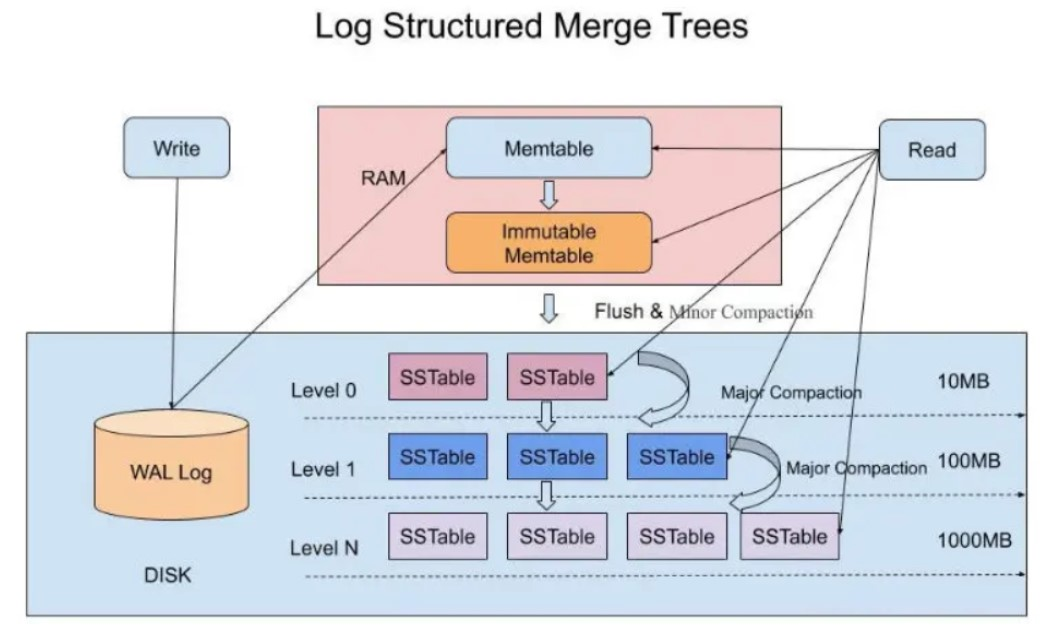
RocksDB存储结构 (来源[4])
RocksDB特点是数据先写内存的memtable,当memtable写满后会被锁定变成immutable memtable禁止修改,Flush线程会把immutable memtable刷到盘上。Rocksdb盘上文件是分层的,Level 0, Level 1…Level N, Level 0的文件最新,Level 1的次之,依次类推。
Compaction过程:参看上图,上层Level中sst文件数量达到指定数量,会执行压缩功能,把多个sst文件进行去旧压缩合并成新的sst文件并写入到下层Level,这些被合并的sst文件会被删除。
RocksDB的性能优化,一个memtable大小超过配置的write_buffer_size大小,会被标记为immutable memtable,当所有memtable包括immutable memtable数量达到max_write_buffer_number时,此时Rocksdb将会停止写入,直到Flush线程把immu memtable刷到disk后,写入才能继续。因此当通过iostat看到盘有较长空闲时间时,那么增大max_write_buffer_number减少盘的空闲时间,可降低写失速现象。
增加max_background_flushes刷盘线程数量也会提升写入速度。由于每次写操作都会先写wal日志,所以关闭wal对写性能有一定提升,但是会导致宕机后数据丢失的风险,一般wal都会开启。
增加compaction线程数量max_background_compactions可提升压缩sst文件速度。写盘速度造成Backpressure,当NVMe命令延迟过大会降低flush和compaction速度,从而会造成停止写memtable。
最后,CPU性能可能是影响读写性能的重要因素。
3) ZenFS为ZNS + RocksDB设计的用户态文件系统
ZenFS由Western Digital主导,ZenFS可以作为一个plugin编译进RocksDB,作为RocksDB的backend filesystem,封装对ZNS块设备的管理操作。ZenFS依赖libzbd管理和获取ZNS的Zone信息,读写块设备时通过pread、pwrite系统调用,并且专门针对ZNS实现了一个简易的用户态文件系统。
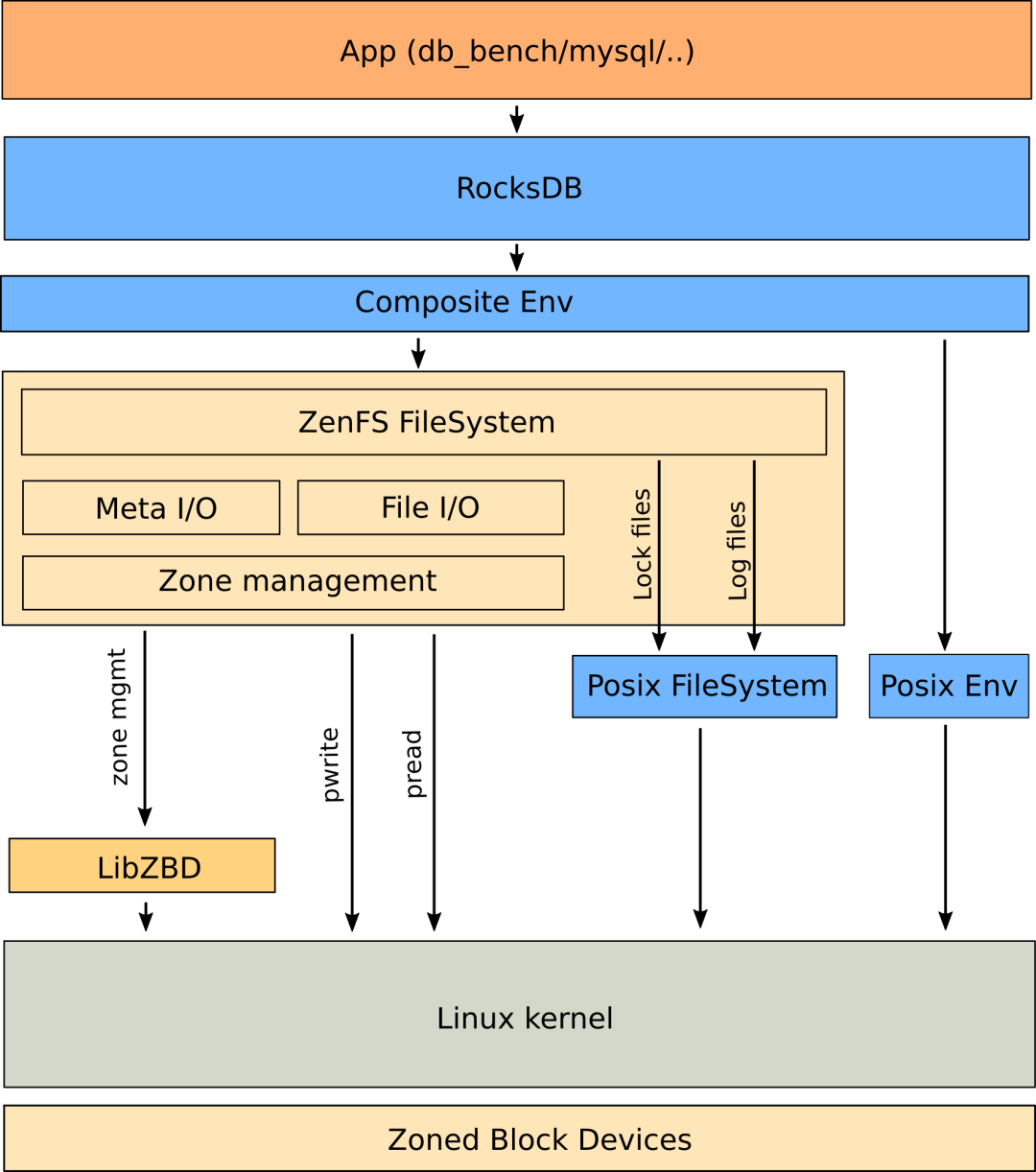
ZenFS文件系统 (来源[5])
4) 性能对比
最后,给出一组RocksDB+ZenFS环境下实测数据[1],当后台写无限制时,ZNS SSD写性能是传统盘的2倍;同样后台写无限制时,ZNS SSD 99.99%读时延是传统盘的1/4。
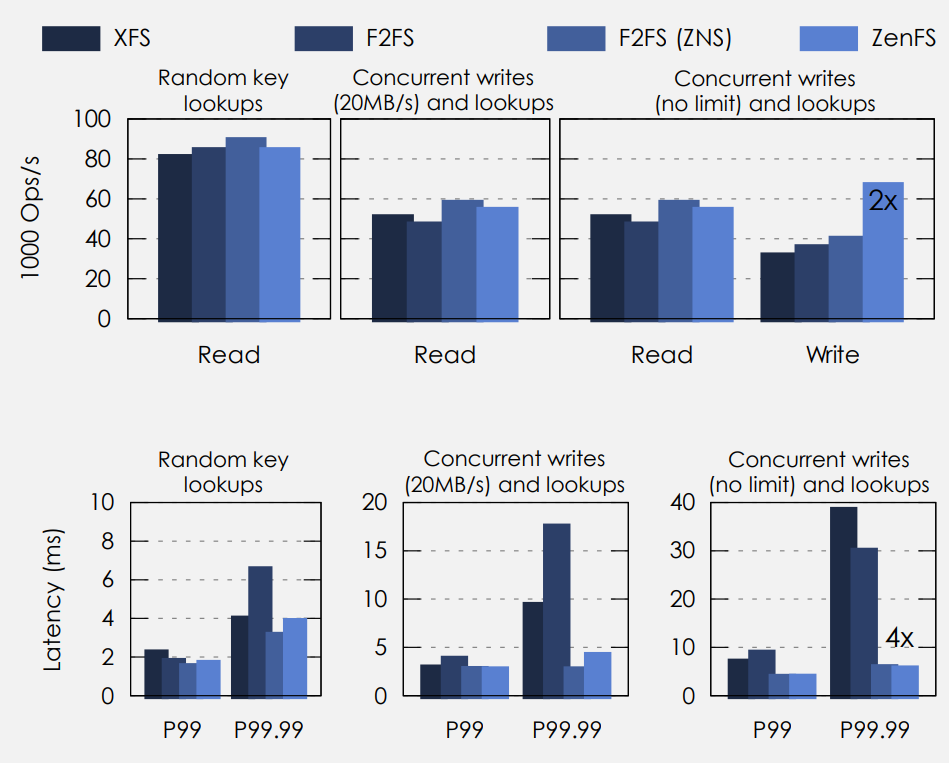
RocksDB+ZenFS+ZNS SSD vs 传统盘性能对比
展望
05
当前ZNS应用生态仍然有较大优化空间,比如在对盘上数据组织方面,由于上层用户数据可能被覆盖写入,必然会出现ZenFS中的extent数据块变为无效,导致盘上Zone空间出现无效数据,虽然RocksDB通过Compaction可以丢弃无效数据,但这些无效数据在一段时间内占用了Zone空间,造成一定程度的空间放大。未来同对ZenFS数据管理逻辑的进一步优化,降低空间放大效应,对Compaction压力将会起到积极的作用。
对于Compaction过程,我们正在探索以Copyback方式实现数据直接在盘内转移,降低RocksDB的负载,提高用户数据的PCIe Bus传输效率。未来版本中,将尝试向ZNS设备中加入可变Zone Size的功能,以更好地迎合RocksDB的LSMT文件存储方式,低level的SST文件通常较少,适合放在Capacity较小的Zone,随着level增加,SST数据变得更多,则更适合放入Size更大的Zone。
ZNS的写入方式消除了盘上GC这一阻碍企业级SSD获得更好Latency QoS的主要障碍,有充足的理由对包括内核、文件系统、数据库等上层应用做更深入的优化。
如F2FS最初是为SMR HDD设计的基于ZBD设备的文件系统,其读写方式也有机会稍做修改,从而应用在ZNS设备上。又如业界已经提出并正在讨论的,将Zone与文件名做Mapping,使得RocksDB或类似数据库可以直接通过驱动访问Zone空间,直接在盘内索引文件,剥离文件系统这一层的Overhead。
另外通过从内核NVMe驱动导出专门的API,向应用直接暴露Zone空间,用户利用io_uring或SPDK等可以从内核态或用户态直接操作ZNS设备,向上提供更大的灵活性。
目前业界已经可以看到初具雏形的中间件产品,如xNVMe,这是一个IO Interface抽象层,提供了多种支持ZNS设备的内核IO Interface,包括Linux和Windows版本。开发者可以面向xNVMe提供的API进行上层应用开发,而不必关心设备访问实现细节,同时只要修改xNVMe配置即可实现不同操作系统的兼容。在xNVMe的基础上,以FlexAlloc作为Backend,向RocksDB提供对象分配器,使得RocksDB可以直接运行在ZNS裸设备上,相比目前商用SSD方案,有希望获得更好的性能体验。
引用:
[1]《ZNS: Avoiding the Block Interface Tax for Flash-based SSDs》@USENIX ATC 2021
[2] SSDFans: 可可读OpenChannelSSD之六_从OpenChannelSSD到ZNS (ssdfans.com)
[3] SSDFans: 一张图了解Open-Channel SSD 2.0 (ssdfans.com)
[4] COONOTE: rocksdb原理与实现-菜鸟笔记 (coonote.com)
[5] CSDN: ZNS : 解决传统SSD问题的高性能存储栈设计(fs-->io-->device)_z_stand的博客-CSDN博客_ssd设计
高端微信群介绍 | |
创业投资群 | AI、IOT、芯片创始人、投资人、分析师、券商 |
闪存群 | 覆盖5000多位全球华人闪存、存储芯片精英 |
云计算群 | 全闪存、软件定义存储SDS、超融合等公有云和私有云讨论 |
AI芯片群 | 讨论AI芯片和GPU、FPGA、CPU异构计算 |
5G群 | 物联网、5G芯片讨论 |
第三代半导体群 | 氮化镓、碳化硅等化合物半导体讨论 |
存储芯片群 | DRAM、NAND、3D XPoint等各类存储介质和主控讨论 |
汽车电子群 | MCU、电源、传感器等汽车电子讨论 |
光电器件群 | 光通信、激光器、ToF、AR、VCSEL等光电器件讨论 |
渠道群 | 存储和芯片产品报价、行情、渠道、供应链 |

< 长按识别二维码添加好友 >
加入上述群聊

带你走进万物存储、万物智能、
万物互联信息革命新时代

