

扫描关注一起学嵌入式,一起学习,一起成长
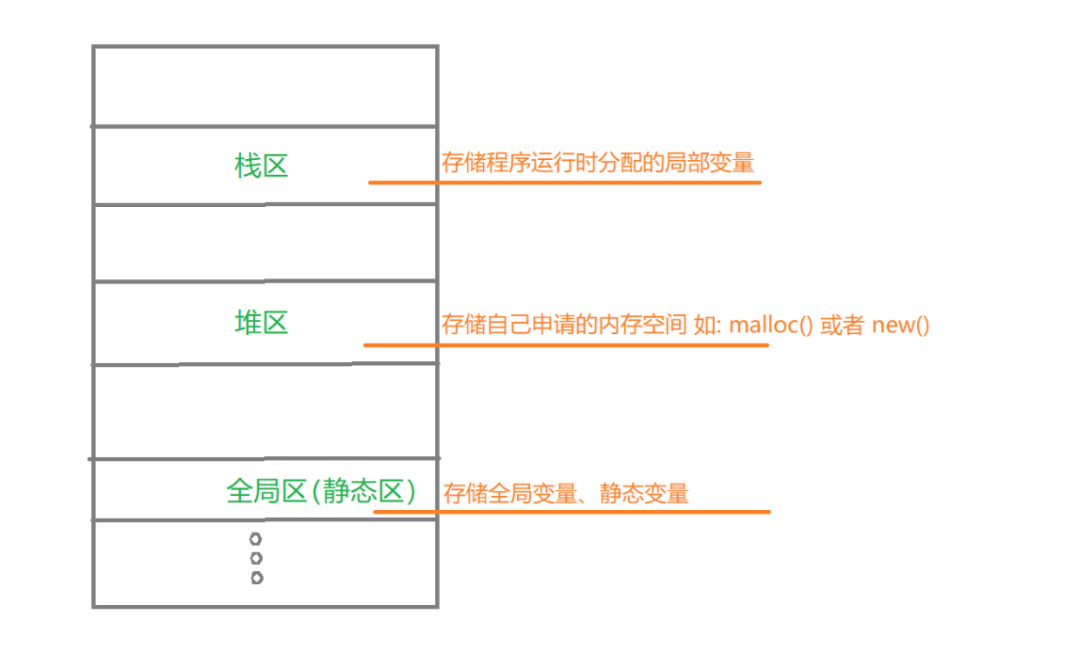 对比理解堆栈与堆的结构!
对比理解堆栈与堆的结构!
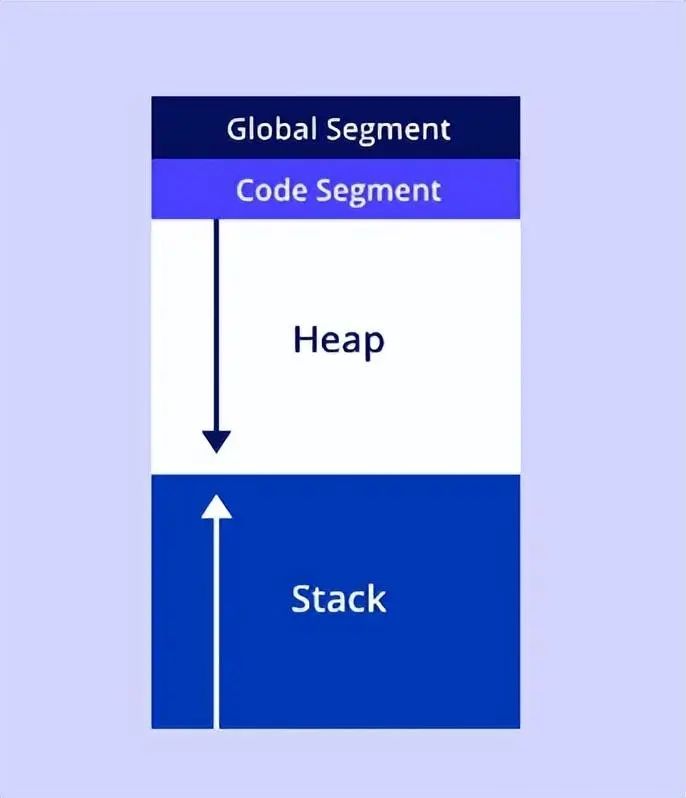
内存分配
堆(Heap)
全局段,负责存储全局变量和静态变量,这些变量的生命周期等于程序执行的整个持续时间。
代码段,也称为文本段,包含组成我们程序的实际机器代码或指令,包括函数和方法。
堆栈段,用于管理局部变量、函数参数和控制信息(例如返回地址)。
堆段,提供了一个灵活的区域来存储大型数据结构和具有动态生命周期的对象。堆内存可以在程序执行期间分配或释放。
注意:值得注意的是,内存分配上下文中的堆栈和堆不应与数据结构堆栈和堆混淆,它们具有不同的用途和功能。
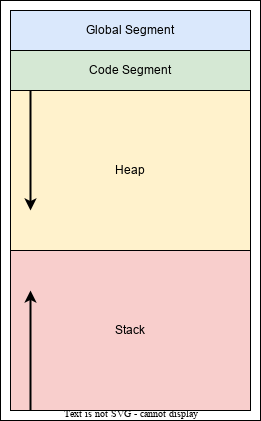
程序代码的大小。
全局变量的数量和大小。
程序所需的动态内存分配量。
public class Main {
// Global Segment:全局变量存放在这里
static int globalVar = 42;
// 代码段:这里存放函数和方法
public static int add(int a, int b) {
return a + b;
}
public static void main(String[] args) {
// 代码段:调用add函数
int sum = add(globalVar, 10);
System.out.println("Sum: " + sum);
}
}globalVar在这些代码示例中,我们有一个值为 的全局变量42,它存储在全局段中。我们还有一个函数add,它接受两个整数参数并返回它们sum;该函数存储在代码段中。该main函数(或 Python 中的脚本)调用该add函数,传递全局变量和另一个整数值10作为参数。

代码中的全局和代码段(未显示堆和堆栈段)
需要强调的是,管理堆栈和堆段对于代码的性能和效率起着重要作用,使其成为编程的一个重要方面。因此,程序员在深入研究它们的差异之前应该充分理解它们。
下面不同编程语言的代码实例演示了堆栈在各种情况下的使用。
public class StackExample {
// 一个简单的函数来添加两个数字
public static int add(int a, int b) {
// 局部变量(存储在栈中)
int sum = a + b;
return sum;
}
public static void main(String[] args) {
// 局部变量(存储在栈中)
int x = 5;
// 函数调用(存储在堆栈中)
int result = add(x, 10);
System.out.println("Result: " + result);
}
}调用函数时会创建称为堆栈帧的内存块。堆栈帧存储与局部变量、参数和函数的返回地址相关的信息。该内存是在堆栈段上创建的。

堆栈段为空
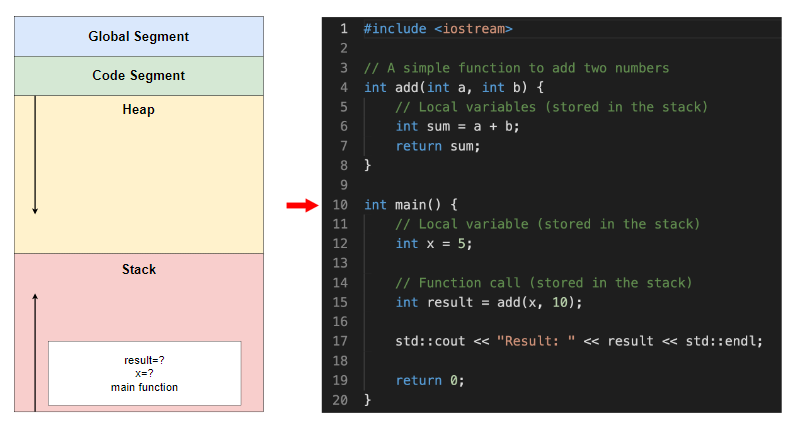
为主函数创建一个新的堆栈帧
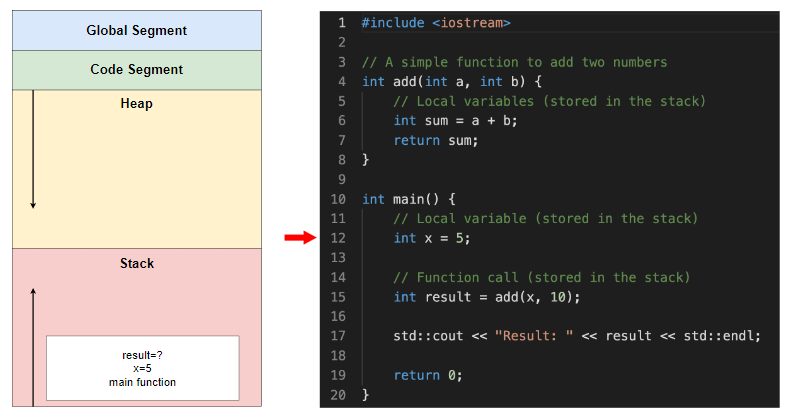
在 main 函数的堆栈帧中,局部变量 x 现在的值为 5
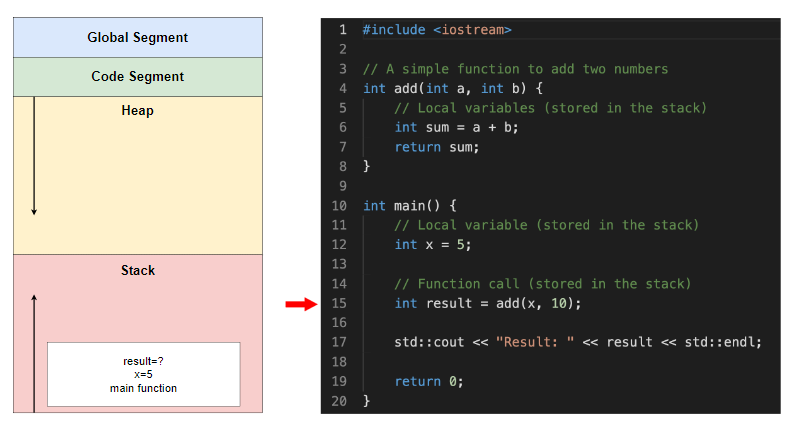
调用 add 函数,实际参数为 (5, 10)
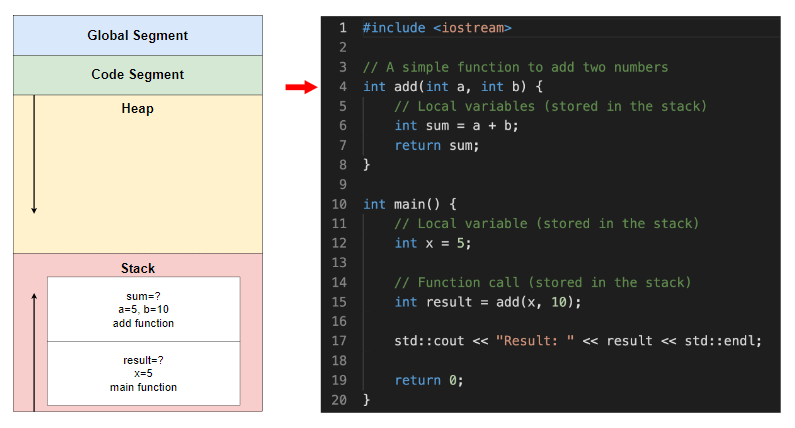
控制权转移到 add 函数,为 add 函数创建一个新的堆栈帧,其中包含局部变量 a、b 和 sum

add 函数的堆栈帧上的 sum 变量被分配 a + b 的结果
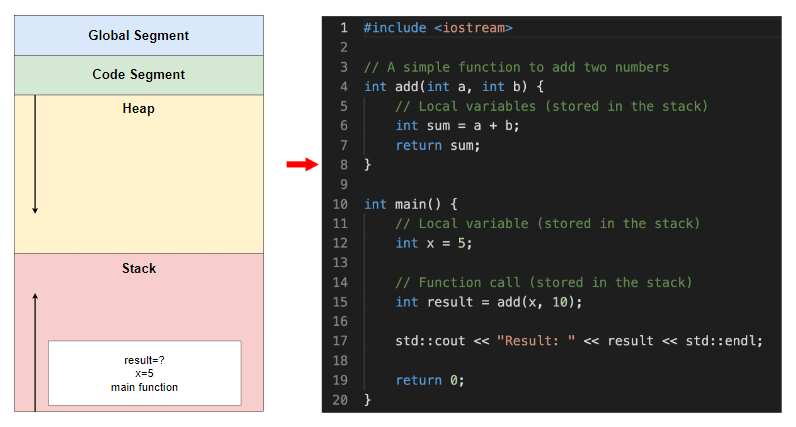
add 函数完成其任务并且其堆栈帧被销毁
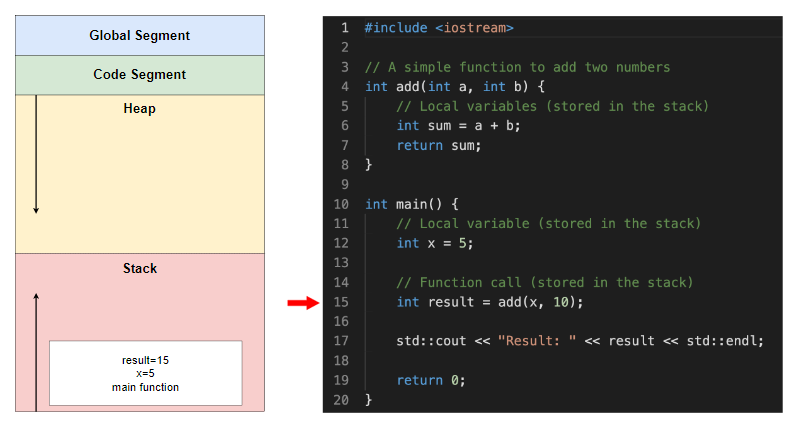
具有可变结果的主函数的堆栈帧存储从 add 函数返回的值

在显示结果值(此处未显示)后,主功能块也被销毁,并且堆栈段再次为空
以下是 C++ 代码按执行顺序的解释:
自动管理:堆栈内存的高效管理由系统本身完成,不需要我们额外的工作。
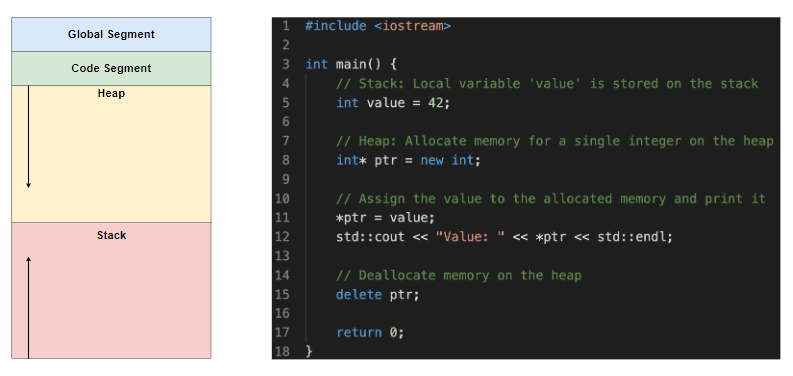
下面不同编程语言的代码实例演示了堆的使用。
public class HeapExample {
public static void main(String[] args) {
// 栈:局部变量“value”存储在 栈中
int value = 42;
// 堆:为堆上的单个 Integer 分配内存
Integer ptr = new Integer(value);
// 将值分配给分配的内存并打印它
System.out.println("Value: " + ptr);
// 在Java中,垃圾收集是自动的,因此不需要 释放内存
}
}演示 Java 中的堆内存分配和使用
注意:在 Java 和 Python 中,垃圾收集会自动处理内存释放,无需手动释放内存,如 C++ 中所示。
栈段和堆段为空
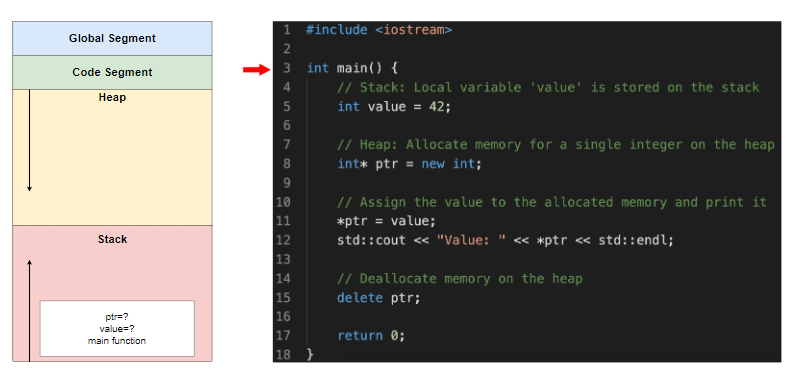
为主函数创建一个新的堆栈帧
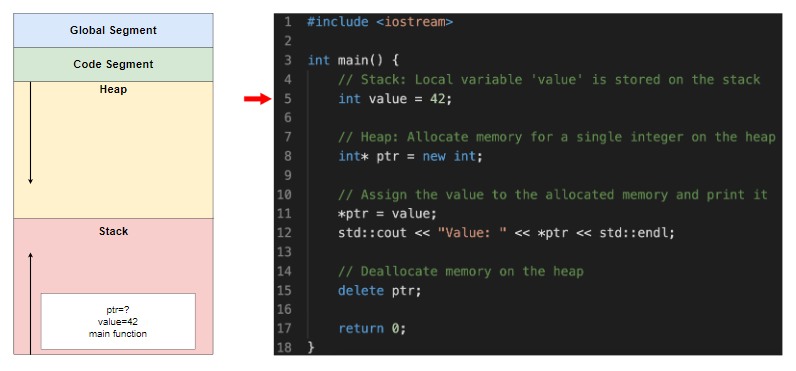
局部变量值被赋予值 42
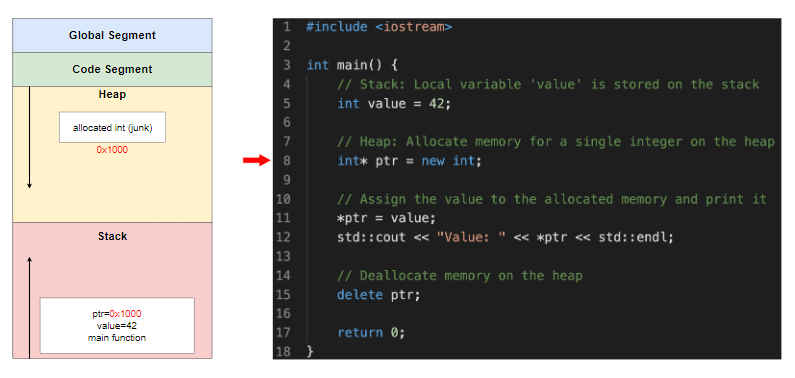
在堆上分配了一个指针变量ptr,指针ptr中存放的是分配的堆内存的地址(即0x1000)
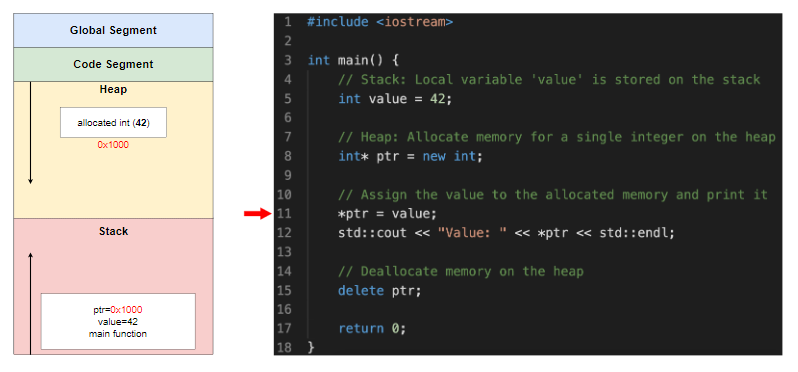
value变量中存储的值(即42)被赋值给ptr指向的内存位置(堆地址0x1000)
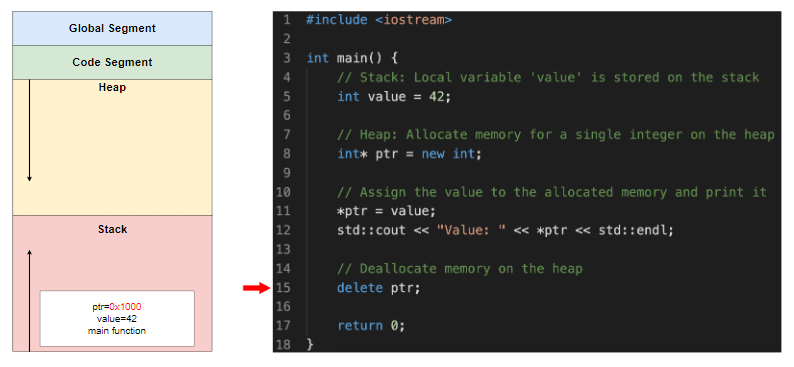
堆上地址 0x1000 处分配的内存被释放
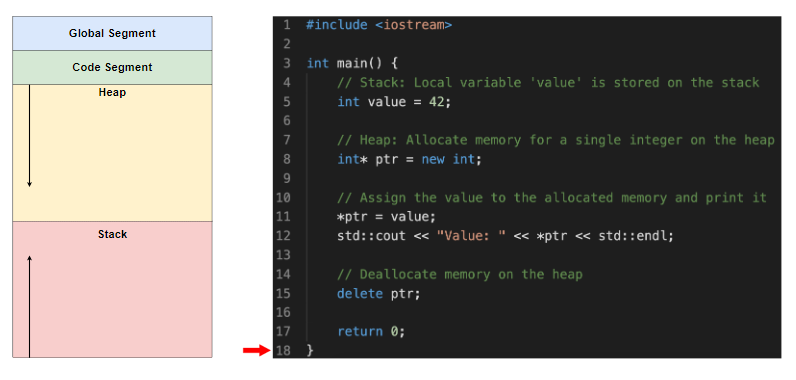
main函数的栈帧从栈中弹出(显示result的值后),栈段和堆段再次清空
以下是 C++ 代码按执行顺序的解释:
注意:C++ 标准库还提供了一系列智能指针,可以帮助自动化堆中内存分配和释放的过程。
以下是需要记住的堆内存的一些显着特征:
现在我们彻底了解了堆栈和堆内存分配的工作原理,我们可以区分它们了。在比较栈内存和堆内存时,我们必须考虑它们的独特特性来理解它们的差异:
下表总结了堆栈内存和堆内存在不同方面的主要区别:
方面对比 | 堆栈内存 | 堆内存 |
尺寸管理 | 固定大小,在程序开始时确定 | 灵活的大小,可以在程序的生命周期中改变 |
速度 | 更快,只需要调整一个参考 | 速度较慢,涉及定位合适的块和管理碎片 |
储存目的 | 控制信息、局部变量、函数参数 | 具有动态生命周期的对象和数据结构 |
数据可访问性 | 仅在活动函数调用期间可访问 | 在手动释放或程序结束之前均可访问 |
内存管理 | 由系统自动管理 | 由程序员手动管理 |
当需要存储对象、数据结构或动态分配的数组时,其生命周期在编译时或函数调用期间无法预测。
当内存需求很大或者我们需要在程序的不同部分之间共享数据时。

关注【一起学嵌入式】,回复“加群”进技术交流群。
觉得文章不错,点击“分享”、“赞”、“在看” 呗!

