

2023年大炼模型兴起,全球范围内都出现了算力供不应求、一卡难求的情况。各地纷纷兴建数据中心、智算中心,来解决国产大模型的算力短缺问题。
今年算力市场又倒向了另一个方向,算力开始过剩和大量闲置了。
主要体现在,高端显卡囤积居奇的生意不好做了,“GPU倒爷”的朋友圈已经从“欲购从速,过时不候”,变成了“A100/H100滞销,帮帮我们”。而算力租赁市场,理想情况下的上架率应该是80%,但很多集群只能达到30%甚至更低,投入大量资金建设的算力闲置,租不出去。

于是一种声音开始甚嚣尘上,认为算力荒已经缓解了,供过于求,应该放慢自主化智算的建设。还有人说,智算中心建的太多了,大模型都用不完了。
发展自主化智算,到底还有没有必要?

还记得2023年算力荒焦灼、智算建设突飞猛进的时候,倪光南院士曾提到过:各地盲目建设各种低水平智算中心,让人唏嘘不已,一定要警惕“技术房地产”和“数字烂尾楼”。所谓“技术房地产”,就是算力资源卖不出去,只能变成一堆放着服务器的砖头水泥房子,闲置在那里。
短短一年多时间,从算力短缺到算力过剩,究竟是怎么发生的?目前来看,闲置算力主要集中在三种情况:
1.用不起。英伟达的高端显卡GPU是AI训练的首选,2023年一度一卡难求。以N卡为主的智算资源闲置,一是因为巨头们此前已经大量囤积采购了GPU,需求减少;二是炒作之后价格昂贵,即使价格回落,中小企业还是用不起。在很多讨论“算力过剩”的评论区,我们总能看到“降价试试”的留言,说明高端AI算力的需求仍在,只是昂贵的N卡被价格劝退了。

2.不好用。国产卡组成的算力集群,也存在上架率不高、资源闲置的问题,主要是不好用。因为国产卡的集中度不高,一个千卡或万卡集群,往往是由各类国产算力卡组成的,异构算力之间的协同调度,涉及大量工程化细节,没有做好就无法开箱即用。勉强用了,又时不时出现业务中断、算效不高、恢复训练慢等各种问题,导致客户流失。这类被迫闲置的国产算力,正是没有考虑配套,盲目建设的低水平智算中心。
3.用不上。“百模大战”之后,企业不再大炼模型,预训练的算力需求也就大幅下降,算力市场开始转向以推理算力为主。但推理市场的爆发,需要一个过程,目前AI的行业渗透率还比较低,总体不到10%,很多企业对AI的投入以尝试为主,还没有大规模爆发。所以,训练用算力开始出现闲置,而推理用算力还未大规模崛起,因此短缺问题尚未完全显现。
低水平算力的闲置与过剩,再一次警醒我们:一个繁荣健康的算力市场,关键不是建出来,而是用起来。

这种情况下,仍然大力发展自主化智算,还有必要吗?
我们认为,这个问题的答案不该有犹豫,要旗帜鲜明地,鼓励自主化智算基础设施的继续建设、加速建设。
首先,从长期看,国内智算属于后发,基础仍然薄弱。
中国智算的进步速度是很快的,但也要客观看到,美国这样的IT先行者,从20世纪90年代以来就在IT建设上大力投入。根据彼得森国际经济研究所的消息,在2024年美国在电子制造业建设方面(主要是芯片)的投资,就超过了1996年至2020年(24年的时间跨度)的总投资。而产业界,xAI、Meta、OpenAI等海外AI巨头,都在积极布局十万卡、五十万卡规模的智算集群。

所以,国内自主化智算近年来的发展虽然迅猛,也是在积极补课,打牢基础。这时候如果停止,不仅会前功尽弃,还会让中美在AI基础设施上的差距进一步拉大。
从近期看,自主化AI算力需求仍然没有得到充分满足,算力荒仍在。
一方面,海外AI算力进口受到限制,极不稳定。目前,国内AI训练芯片市场英伟达占据了80%~80%的市场份额,要避免威胁供应链安全,这种情况必须尽快改变。上海的“算力浦江”智算行动实施方案(2024—2025年)要在2025年,实现新建智算中心的国产算力芯片使用占比超过50%;《北京市算力基础设施建设实施方案(2024—2027年)》则提出,2027年要具备100%自主可控智算中心建设能力。
三年左右,从不到20%发展到100%。所以,如今的自主化智算不是太多了,而是还不够。
与此同时,算力需求仍在增长。大模型的规模法则仍在继续,以Sora为代表的视频生成模型对算力的需求量是LLM大模型的数倍,已经出现了“一栋楼放不下一个模型”“一个模型需要多个集群”的情况,超万卡智算中心是必不可少的基础设施,目前国内的十万卡集群还远远不足。
此外,大炼模型的阶段虽然结束了,但基础模型的市场集中度提高和能力提高,又会释放AI应用需求,促进AI的行业渗透率、普及率,导致AI推理算力的需求爆发,急需要更多高质量算力来满足。目前部分国产AI算力集群的利用率极高,西安昇腾智能科技有限公司的人工智算中心算力使用率就高达98.5%;曙光在长沙的5A级智算中心,也吸引上百家企业入驻,实现万余个商业应用接入。因此,随着产业智能化升级的继续推进,国产AI算力荒不是已经解决,而是从现在开始重视和应对。

互联网产业的核心,当然不是宽带和机房,但没有“宽带高速公路”,就没有美国互联网经济的爆发;移动互联网的核心,也不是基站,但没有广泛覆盖的4G基站,就没有智能手机和移动应用软件的兴起。AI大模型也是一样, AI作为一种依附在基础设施之上的软件技术,核心不是智算,但没有自主化智算,国内AI绝不可能独善其身、独自蓬勃发展。
因此,自主化智算并不存在过剩,更不该就此放慢发展。

综上,“国内AI算力过剩”,是个假问题,“如何合理地推进自主化智算的建设”,才是真问题。
解决这个真问题,国内智算产业已经来到了承上启下的新阶段。不仅要追求把智算中心“建起来”,还要能运营好、用起来。
因此,智算厂商的竞争,也从售卖硬件资源与智算解决方案,转变为多维度、综合性、长期服务的竞争。比如华为昇腾AI全栈、中科曙光的“立体计算”、宁畅的“全局智算”、联想的“万全生态”,新华三的“1+N”智算等,以更全面的能力,支撑自主化智算的建设运营。

追求全面,并不意味着胡子眉毛一把抓,目前来看,智算厂商们主要集中解决自主化AI算力的几个痛点问题:
1.异构问题。目前,国产AI芯片还无法规模化出货,市场集中度较低,因此都是以混合算力的形式,来加入智算集群。多元异构算力的协同调度、管理、算效、业务可靠性等,面临很多技术挑战。如果一个企业或开发者,要针对ABCD不同厂商的卡进行适配开发,是不可能的。所以,就需要智算厂商提供相应的系统平台,屏蔽底层异构硬件的复杂性,让大家用好国产算卡。比如联想的万全异构智算平台,实现异构化AI算力的管理与调配;新华三面向异构智算的智能管理平台,一站式应对多样化的AI应用场景。

2.算效问题。解决“低质量算力过剩,自主化高质量算力不足”的结构性问题,需要进一步提高国产AI的性能。面对工艺制程的限制,可以通过软硬件系统的无缝配合,从而实现国产算卡性能的充分释放。以昇腾为例,就与昇思紧密结合,为各类智算场景提供高性能的自主化AI算力,深圳鹏城实验室的“鹏城云脑Ⅱ”就依托昇腾实现了中国首个自主可控的E级智能算力平台,可以提供不低于1000Pops的整机AI计算能力。

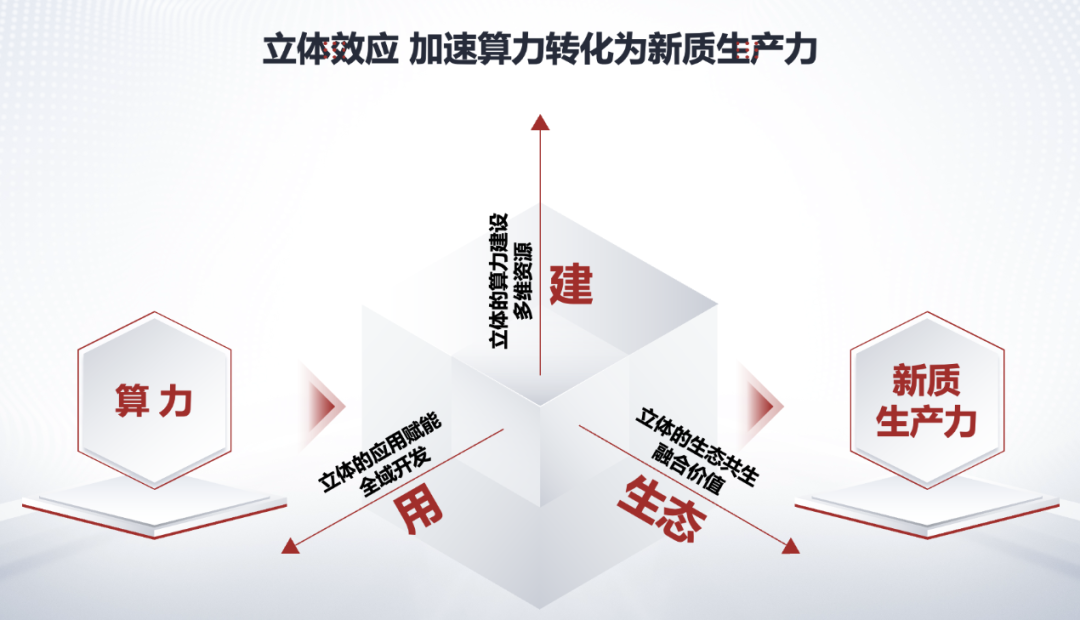
3.运营问题。如今,一些地方在智算中心建设之前,开始提出上架率、收益率等要求,需要保证项目投运后有一定的使用率。同时,也会要求建设方提供设计、使用、运营等一体化服务,避免智算中心因无人运营而成为“数字烂尾楼”。以用促建、以服促用,已经是自主化智算发展的必然潮流。比如新华三与杭州市合作,打造“图灵小镇”,培育AIGC产业和数字人才;中科曙光“立体计算”主张“算力建设、应用赋能、生态共生”三位一体,推动多元算力向新质生产力转化,目前已经在5A级智算中心落地实践。
回顾这一年多来,国内智算的发展突飞猛进,取得了举世瞩目的成绩,我们不必再为算力荒而忧心忡忡。但人无远虑必有近忧,AI算力的自主化之路不能就此戛然而止,而要一鼓作气,再加把劲,把已经取得的成果夯实,为接下来的智能浪潮做好准备。
避免低质量算力过剩,与加速自主化智算发展,这两件事可以并行不悖,也应该理性分开看待。

