


目前主流的目标检测算法都是用CNN来提取数据特征,而CNN的计算复杂度比传统算 法高出很多。同时随着CNN不断提高的精度,其网络深度与参数的数量也在飞快地增长, 其所需要的计算资源和内存资源也在不断增加。目前通用CPU已经无法满足CNN的计算需 求,如今主要研究大多通过专用集成电路(ASIC),图形处理器(GPU)或者现场可编程门 阵列(FPGA)来构建硬件加速电路,来提升计算CNN的性能。
其中 ASIC 具备高性能、低功耗等特点,但 ASIC 的设计周期长,制造成本高,而 GPU 的并行度高,计算速度快,具有深度流水线结构,非常适合加速卷积神经网络,但与之对 应的是 GPU 有着功耗高,空间占用大等缺点,很多场合对功耗有严格的限制,而 GPU 难 以应用于这类需求。近些年来 FPGA 性能的不断提升,同时 FPGA 具有流水线结构和很强 的并行处理能力,还拥有低功耗、配置方便灵活的特性,可以根据应用需要来编程定制硬 件,已成为研究实现 CNN 硬件加速的热门平台。
综上所述,使用功耗低、并行度高的 FPGA 平台加速 CNN 更容易满足实际应用场景中 的低功耗、实时性要求。而且目标检测算法发展迅速,针对 CNN 的硬件加速研究也大有可 为。所以本项目计划使用 PYNQ-Z2 开发板设计一个硬件电路来加速目标检测算法。
本项目设计的目标检测算法硬件加速电路可以应用在智能导航、视频监测、手机拍照、 门禁识别等诸多方面,比如无人汽车驾驶技术,高铁站为方便乘客进站而普遍采用的人脸 识别系统,以及警察抓捕潜逃罪犯而使用的天网系统等都可以应用本项目的设计,加速目 标检测算法的运算速度以及降低系统的功耗。

在本次项目的设计开发过程中,我们参考 DAC 2019 低功耗目标检测系统设计挑战赛
GPU、FPGA 组双冠军方案,学习到了基于 SkyNet 和 iSmart2 设计一个轻量级神经网络的 技巧,尤其是他们采用的自底向上的硬件电路设计思路给我们带来了巨大的启发。我们在将训练好的神经网络部署在硬件平台的过程中,加深了对 HLS 的理解,开始初步掌握使用 HLS 进行并行性编程的方法。我们学习了 PYNQ 框架,在 PYNQ-Z2 上实现神经网络加速 电路,有了软硬件协同开发的经历。除此之外,我们还学习了 Vitis AI,虽然在项目中并没 有使用到 Vitis Ai,但是对它的学习扩宽的我们的视野。
本项目针对DAC2019 System Design Contest测试集,计划采用PYNQ-Z2开发板加速目标 检测网络,综合考虑数据访问、存储、并行计算等问题进行优化处理,设计出高速高精度 且低功耗的加速方案,并完成相关仿真和FPGA平台的验证,实现一个可以框选出图像中行 人或其他物体位置的硬件电路。
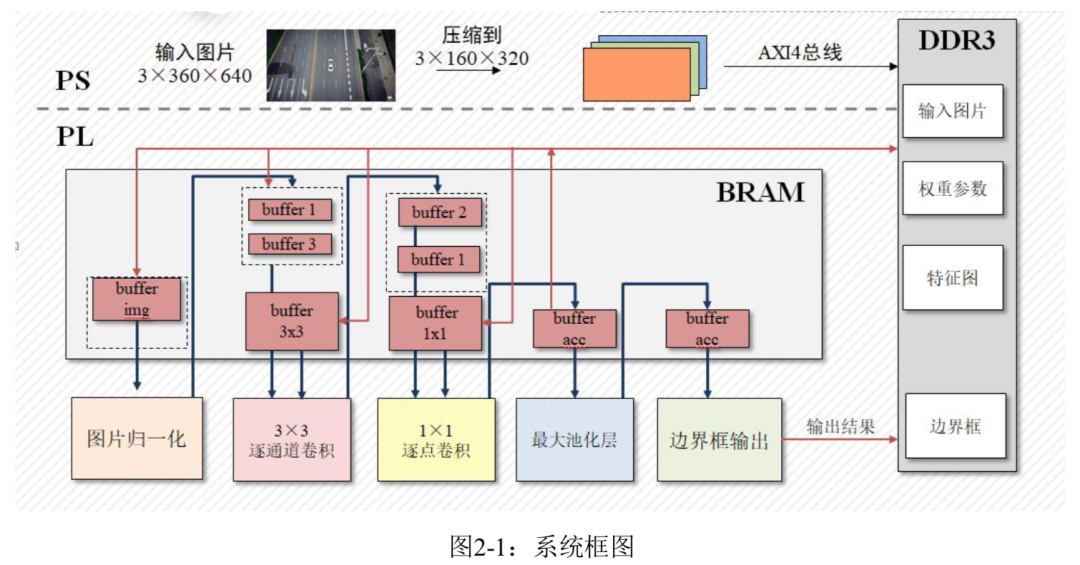
本项目的系统框图如图2-1所示,首先PS端从SD卡读取图片并压缩,之后将图片和参 数权重一起传输到 DRAM中,PL端再从DRAM中读取数据并归一化,经过卷积和池化将输 出特征图传回到DRAM中,再进行下一层卷积运算;直到网络最后一层输出送入到边界框 输出模块中选择置信度最高的边界框传输到DRAM中,供PS端读取。
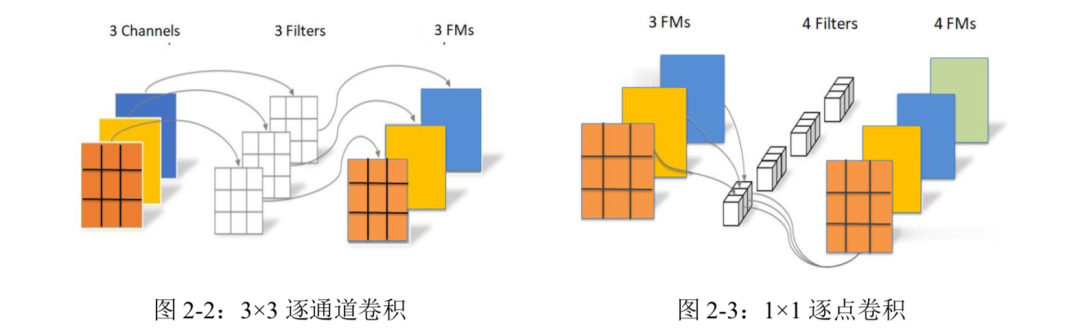
针对 DAC-SDC 数据集并结合 SkyNet 和 iSmart2 网络设计原理,挑选出的基本单元Bundle 由 3×3 逐通道卷积(Depthwise Convolution),1×1 逐点卷积(Pointwise Convolution)和 激活函数 ReLU6 组成。
其中 3×3 逐通道卷积和 1×1 逐点卷积的参数量和计算量远远少于传统的卷积。如图 2-2 和 2-3 所示,首先每个 3×3 逐通道卷积核与各自对应的输入通道数据进行卷积运算,所以 输出通道数等于输入通道数;然后上一步运算得到的特征图继续进行 1×1 逐点卷积,每个 1×1 逐点卷积核对输入的所有通道进行卷积运算,并将结果相加得到一个输出特征图,所以输出通道数等于逐点卷积核的数量。
ReLU6 激活函数与传统的 Relu 激活函数相比,当 ReLU6 函数的输入值大于等于 6 时 输出值恒为 6,可以使模型更快地收敛。同时网络采用大小为 2×2,步长也为 2 的最大池化 层(Max pooling)来降低运算量并防止过拟合,特征图每经过一次最大池化层其宽和高都减小一半。
综上所述本项目构建的神经网络模型如图 2-4 所示:
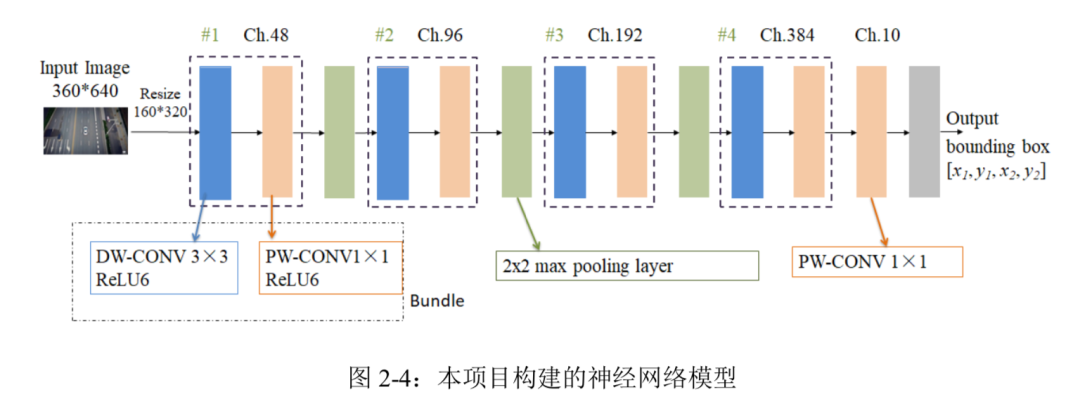
本项目构建的网络模型主要由四个 Bundle 基本单元和三个 Max pooling 层组成,其中每个 Bundle 由 3×3 逐通道卷积,ReLU6 激活函数,1×1 逐点卷积,ReLU6 激活函数依次排 列组成。通过每个 Bundle 中的 1×1 逐点卷积实现输出特征图通道数翻倍,通过 Bundle 其 后紧接着的 Max pooling 层实现输出特征图的尺寸减半。因为数据集内的样本图片分辨率均 为 3×360×640,为了降低计算量就选择将图片压缩到 3×160×320,这个尺寸既可以尽量保 留图片的信息以防止目标检测准确率下降,又可以在神经网络运算过程中很方便地通过 Max pooling 进行降采样。经过三层 Max pooling 后特征图的大小为 20×40,再经过最后一 层 1×1 逐点卷积后输出为 10×20×40,是将输入图片分为 20×40 个分块,又因为输出通道数 为 10,即每个分块将会得到两个边界框和对应的置信度,本项目设计的算法会遍历所有分 块的边界框,选择置信度最大的边界框输出。
本项目设计的硬件电路主要有两个模块模块:数据读取与传输模块。首先需要读取图片和模型参数的数据,并对输入的图片数据进行归一化处理,然后送入到卷积运算模块中 进行计算,接着将计算结果送入到边界框输出模块,最后将得到的边界框结果传输到DDR3内存中。
优化设计一个高效的数据读取与传输模块是完成目标检测任务的前提。首先考虑到FPGA 自身 BRAM 资源有限,所以在数据读取模块中会将每一层的特征图切分成多个数据 块逐次送入到运算模块中进行运算。每个数据块的大小为 20×40,例如将大小为 3×160×320 的输入图片分成 64 个 3×20×40 的数据块。
数据读取时每次读取 3×3 逐通道卷积核参数的大小为 16×3×3,读取 1×1 逐点卷积核参 数的大小则为 16×16,两者均为 16 通道,是因为卷积运算模块为提升运算速度采用了 16 通道并行计算的结构。数据传输过程中将特征图,网络参数通过指针连续地存储在 DDR3 内存中,方便数据存取,提高传输效率。
PYNQ-Z2 的 PS 端通过 AXI4 总线与 PL 端进行通信,AXI4 总线协议具有高性能,高 频率等优势。在 Vivado HLS 中编写硬件代码时需要将输入图片,模型参数和边界框等 PS 端与 PL 端传递数据的接口定义为主或从接口,之后在 Vivado 中自动连线时软件会添加 AXI Interconnect 用于管理总线,并自动为接口分配地址。
在硬件代码编写完成后,需要进行 C 仿真和 C 综合等步骤,最后导出 RTL,可以在导 出的 IP 核驱动的头文件中找到接口的地址,然后在 PS 端开发时将图片和网络参数数据写 入对应地址即可,并从相应的接口地址读取输出数据。
设计卷积运算模块来加速卷积运算是 FPGA 加速电路的关键,卷积运算模块由 3×3 逐 通道卷积运算模块和 1×1 逐点卷积运算模块组成。
首先为了让设计的 3×3 逐通道卷积运算模块能够在不同的卷积层间复用,需要保持 3×3 逐通道卷积前后数据块大小不变,这需要对输入和输出数据块进行填充(padding)。输入数 据块原始大小为 20×40,本项目选择 padding=1,则输入数据块大小变为 22×42,经过 3×3 逐通道卷积后高和宽分别为 20 和 40,即输出数据块大小依旧为 20×40。如果接下来还需要 进行 3×3 逐通道卷积,则再对输出进行填充使输出数据块大小也为 22×42,以保持运算过 程中数据块大小不变,这样就能很方便地复用 3×3 逐通道卷积运算模块来节约硬件资源。
因为卷积运算过程中特征图的通道数逐步变为 48,96,192,384,均为 16 的倍数, 所以综合考虑 FPGA 的并行性优点和 PYNQ-Z2 自身资源情况,设计卷积运算模块为 16 个 通道并行计算来提升运算速度。16 通道 3×3 逐通道卷积的输入数据块为 16×22×42,卷积核 为 16×3×3,输出数据块经填充后也为 16×22×42。
因为 3×3 逐通道卷积由乘法和加法运算构成,所以其运算模块需要乘法器,加法器和 寄存器。针对 3×3 逐通道卷积运算模块,以第一个通道为例,首先把偏置𝑏11 放入寄存器 中,接着在第一个时钟周期内,送入数据块的输入𝑖11和卷积核参数𝑤11并相乘,将结果与寄 存器内的𝑏11相加并送入寄存器中。第二个时钟周期内送入𝑖12和参数𝑤12重复上述操作,经 过九个时钟周期后输出𝑂11,所以需要 9 个时钟周期来完成一次 3×3 逐通道卷积,期间共进行了 9 次相乘并累加操作。则 16 通道并行计算共需要 16 个乘法器和 16 个加法器,即需要 16 个 DSP 资源。
同理可以设计 16 通道 1×1 逐点卷积运算模块,以第一个通道为例, 1×1 逐点卷积运 算时可以不需要计算 padding 部分,直接从原始输入数据块开始计算,输入数据块第一个 通道的𝑖11与卷积核参数𝑤11相乘并将结果保存在寄存器mul1中,则 16 个通道得到 mul1~mul16共 16 个乘积值,接着乘积值两两相加得到add1~add8共 8 个累加值,再将得到 的结果不断两两相加直到仅有一个累加值add15,最后再加上偏置得到输出O11,所以完成 一次 16 通道 1×1 逐点卷积共需要 16 次乘法和加法运算。
本项目设计的硬件电路针对 1×1 逐点卷积运算模块提供了最大 16 通道并行的计算方 式。考虑到 PYNQ-Z2 的 DSP 资源共 220 个,且 3×3 逐通道卷积运算模块和边界框输出模 块均占用 DSP 资源,所以最多可以例化 9 个 16 通道 1×1 逐点卷积运算模块,需要乘法器 和加法器的数量均为 144 个,即需要 144 个 DSP 资源。
本项目使用的 PYNQ-Z2 的 PS 端安装了 Linux 操作系统,配置好了 Python 开发环境,
并预装了 Numpy 等常用库和专用于 PYNQ 架构的 PYNQ 开发库。本项目通过 Micro SD 卡 启动 PYNQ-Z2,借助网线将路由器与 PYNQ-Z2 相连,登陆路由器管理界面可以查看分配 给 PYNQ-Z2 的 IP 地址,让电脑也连接路由器,使两者的网络段相同,就可以通过浏览器 登陆这个 IP 地址来访问 PS 端自带的 Jupyter Notebook 并进行 Python 编程开发。
PS 端首先通过 PYNQ 库中的 Xlnk 类来为输入图片,卷积核参数,偏置,池化层输出 和预测框等分配连续内存,接着使用图像库 PIL 中的 Image 类从 Micro SD 卡中读取 3×360×640 大小的输入图片,并将图片压缩为 3×160×320,再将压缩后的图片转化为 numpy 数组后传入 DDR3 内存中。之前训练好的两种卷积核参数和偏置数据都保存在了二进制文件中,也需要从 SD 卡中分别读取这些数据并按照卷积运算模块数据块的大小和运算顺序 重新排列后送入 DDR3 内存中。
数据传输完成后 PS 端通过 PYNQ 库中的 Overlay 类烧写比特流文件和 tcl 文件来配置 PYNQ-Z2,然后当输入图片和网络参数写入到对应地址时硬件电路就开始工作,全部运算 完成后 PS 端从相应的地址读取边界框的值并在图片上画出边界框。
为了提升神经网络的训练效率,本次实验把本地编写好的 PyTorch 代码和数据集一起 传输到云服务器中重复进行训练直到满足精度要求,接着在测试集上测试网络的识别精度, 如果能够满足要求就将训练好的网络参数保存下来,并将格式转化为二进制文件。
本项目首先随机选出几张数据集中的图片通过编程转换成二进制 bin 文件,进行 C 仿 真时 Test bench 先是读取二进制图片文件和训练好的网络模型参数,然后送入编写好的 Test bench 网络模型中计算并输出结果,为了对比 Test bench 和硬件代码的输出结果,还需要将 网络参数重排序后和图片一起送入硬件代码中计算并输出结果,同时将重新排序后的网络 参数保存成新的二进制文件供给之后在 PS 端调用。对比 Test bench 和硬件代码的输出来判 断硬件代码逻辑功能的正确性。
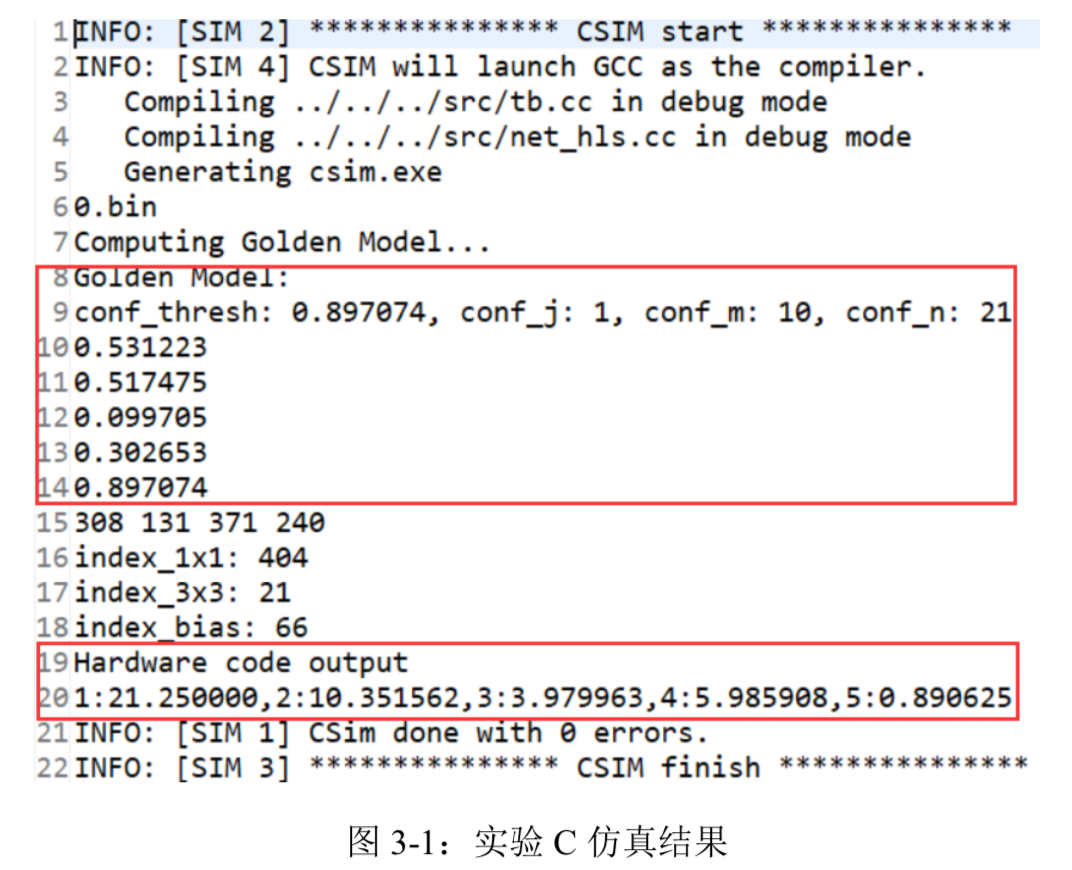
实验 C 仿真结果的报告如图 3-1 所示,第 6 行显示本次输入图片的编号为 0,第 9 行显示输入图片第 10 行第 21 列这个数据块的第二个边界框的置信度最大,第 14 行显示其值 近似为 0.897,第 10 至 13 行显示了 Test bench 输出边界框归一化后的坐标和宽高,将这四 个值与数据块的宽高 40 和 20 对应相乘后得 21.24,10.34,3.99,6.04,与第 20 行显示的 硬件代码输出边界框的预测结果十分相近,同时硬件代码输出边界框的置信度近似为 0.891, 与 Test bench 的结果也十分接近。可以看到 Test bench 和硬件代码两者输出的边界框和置信 度都非常相近,且经过与真实输入图片中目标的位置对比发现三者的结果基本一致,可以认为硬件代码的逻辑功能正确,能够完成目标检测任务。C 仿真通过后接着进行 C 综合,C 综合可以根据实验一开始选择的 PYNQ-Z2 的芯片型号,编写的硬件代码和 directives 指令自动为硬件电路分配资源,并生成 Verilog 代码。如 图 3-2 所示,C 综合结果的报告给出了硬件电路运行所用的时间。
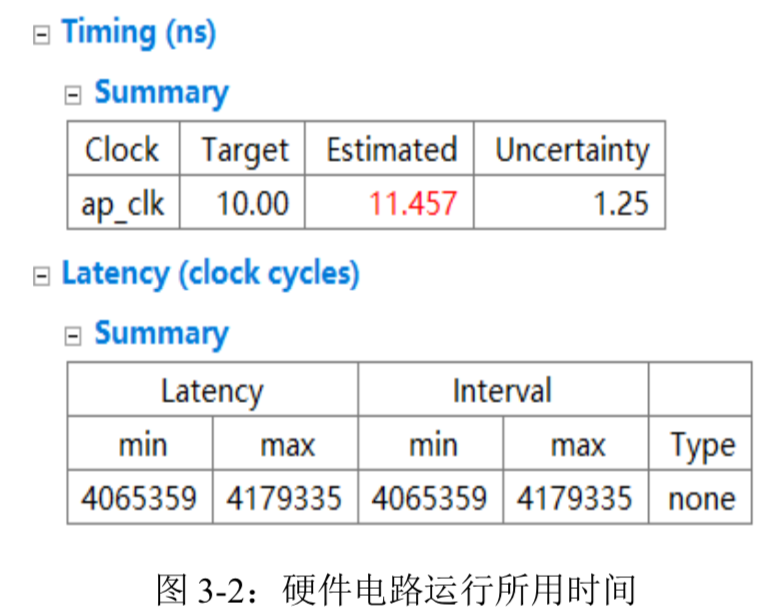
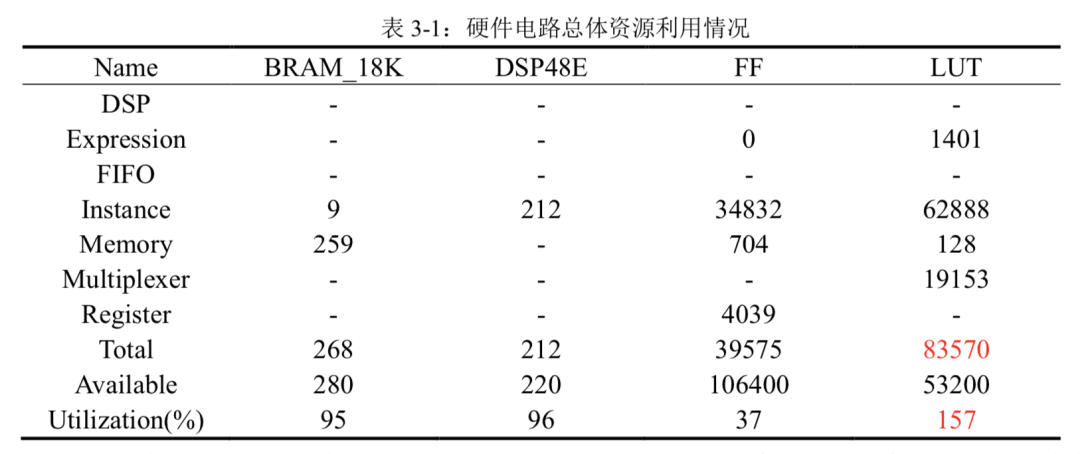
表 3-1 则给出了整个硬件电路所需要的 BRAM,DSP 等资源情况,可以根据 C 综合报告修改各个模块的硬件代码或者 directives 指令来调整资源利用率,直到满足要求。可以看到本项目设计的硬件代码已经几乎利用了全部 DSP 和 BRAM 资源。又因为 C 综合时往往对所需 LUT 的资源预测值远超实际值,所以报告显示 LUT 资源超出总额,更加真实的资源利用情况需要在 Vivado 中生成比特流文件后的报告中查看。
硬件代码 C 综合通过之后就可以开始进行 C/RTL 协同仿真,协同仿真主要是从时序角 度检测硬件代码是否正确,仿真结果会得到一个波形文件,可通过观察波形来判断硬件代 码的执行时序是否正确。通过观察仿真波形可以确认本项目设计的硬件代码时序正确,仿真可以通过。
硬件代码的仿真与综合都通过之后就可以将硬件代码封装成 IP 导出,打开 Vivado 并选择 PYNQ-Z2 开发板新建工程,调用封装好的 IP 和开发板上的 RAM 芯片 ZYNQ7000。
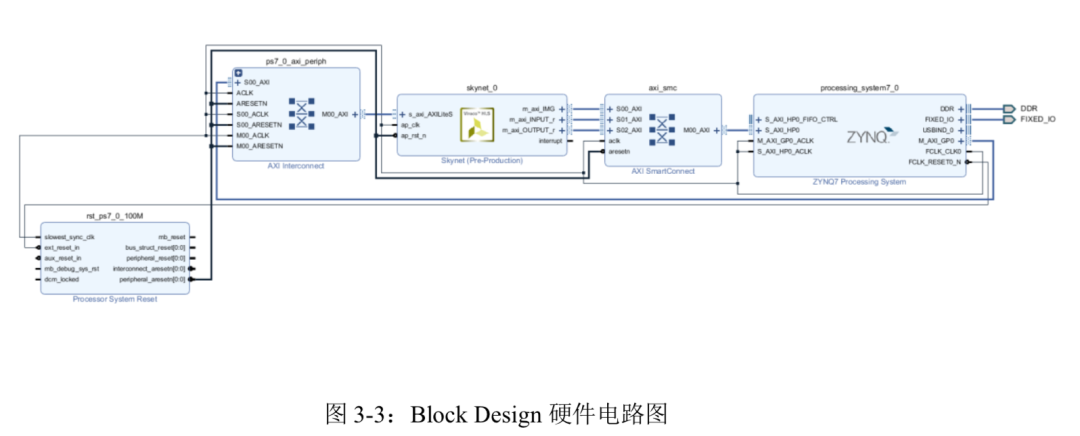
因为 ZYNQ7000 的从 AXI_HP 接口默认不使用,所以需要手动配置好这个端口。PS 端还需 要引出一个时钟信号提供给 PL 端,其他参数在添加 PYNQ-Z2 开发板时已经基本设置妥当, 通过自动连线生成的电路如图 3-3 所示。
电路连接完成后即可开始生成比特流 bit 文件,接着导出 Block Design 来生成 tcl 文件,之后的 PS 端调试需要调用这两个文件来配置 PYNQ-Z2。图 3-4 是生成比特流后的报告, 可以得到比 C 综合报告更为真实的资源利用情况,此时 LUT 资源利用率从 157%降至 71%, 所以 PYNQ-Z2 能够满足本论文设计的硬件电路的要求。
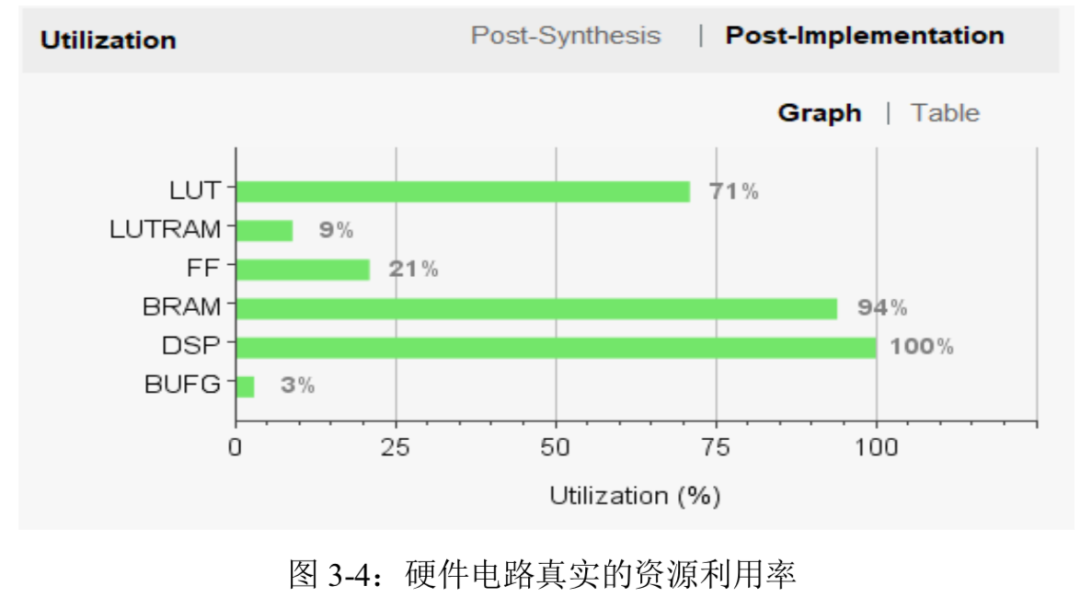
图 3-5 显示硬件电路的总片上功耗为 2.322W,功耗表现满足预设目标。图 3-6 则具体显示了片上各部分的功耗情况,其中总功耗中动态功耗占了绝大部分,而 RAM 芯片功耗 则占据了 60%左右的动态功耗。

在生成比特流文件和导出 Block Design 之后,即可开始本次实验的最后一步,在 PS 端 编程来验证硬件代码在 PYNQ-Z2 上能否完成目标检测任务。首先用网线将 PYNQ-Z2 与路 由器相连并通过 USB 线供电,这样 PYNQ-Z2 能够联网,可以随时从网上下载各种开发包 和环境。由于 PYNQ-Z2 可以通过 Samba 服务来共享文件夹,所以可以很方便地将比特流 文件,tcl 文件,输入图片和重新排序的网络参数二进制文件直接传到 SD 卡上的 Jupyter Notebook 文件夹内。
实验可以准确地识别出图 3-8 中的行人和图 3-9 中的游客,证明本项目设计的硬件电路能够完成目标检测任务。

本项目 PYNQ-Z2 开发板加速目标检测网络,可以在输入图片上标出边界框。又因为 PYNQ-Z2 的资源有限,本项目设计的硬件电路运算速度还不到 200MFLOPS。但是该电路 可以根据所选开发板的资源情况来例化适合的 1×1 逐点卷积运算模块数量,以此来提升运 算速度。
从生成比特流的报告中可知硬件电路的总片上功耗为 2.322W,远小于预设的功耗 8W, 所以本论文优化设计的 FPGA 加速电路在功耗方面满足预期目标。
接着需要考察另一个指标 IoU,也称为交并比,需要通过“预估的边界框”与“实际 的边界框”之间交集和并集的比值来计算。又因其要求严格,所以一般认为目标检测结果IoU 大于 0.5 即可满足精度要求。本次实验利用 DAC-SDC 训练集来训练网络参数,接着用 准备的测试集图片对训练好的网络进行测试,得到 IoU 约等于 0.573,所以本项目构建的网 络模型的准确率也满足预设目标。
本项目依据 SkyNet 和 iSmart 网络的设计原理,合理地构建了一个主要由 3×3 逐通道卷积和 1×1 逐点卷积组成的轻量级卷积神经网络用来完成目标检测任务,并专门为这两类卷积优化设计了 FPGA 硬件加速电路模块来提升卷积运算速度,同时通过对卷积运算模块 的充分复用较好地节约了开发板资源。
本项目在 PYNQ-Z2 开发板上设计的硬件加速电路可以很好地完成目标检测任务,输出 的边界框能够准确地框选出图片中的行人或者物体。硬件电路总片上功耗只有 2.322W,而 IoU 可以达到 0.573,基本满足了设计目标。
群号:173560979,进群暗语:FPGA技术江湖粉丝。
多年的FPGA企业开发、培训经验,各种通俗易懂的学习资料以及学习方法,浓厚的交流学习氛围,QQ群目前已有6000多名志同道合的小伙伴,无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
现微信交流群已建立14群,人数已达数千人,欢迎关注“FPGA技术江湖”微信公众号,可获取进群方式。
往期精选




FPGA技术江湖广发江湖帖
无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,QQ微信双选,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
FPGA技术江湖微信交流群

加群主微信,备注姓名+学校/公司+专业/岗位进群
FPGA技术江湖QQ交流群

备注姓名+学校/公司+专业/岗位进群

