在数字化浪潮的推动下,AI大模型正逐渐成为企业转型升级的重要工具。本次分享深入探讨了AI大模型在企业场景中的落地应用。详细解析了AI大模型的意图理解、数据检索、内容生成三大核心能力,并结合实践案例,展示了这些能力在客服、合规、科研等场景中的具体应用。
分享嘉宾|李喆 爱分析 合伙人兼首席分析师
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

大家好,我是爱分析的合伙人兼首席分析师李喆。我这边会跟大家分享爱分析看到的落地场景和案例。
我们发现大部分的场景落地,是企业的IT部门或者数字化部门在牵头去找业务场景,真正有业务部门深入参与的落地的案例还是相对有限。所以我觉得首先需要了解大模型的核心能力,特别是能够跟企业业务场景结合的能力,只有更熟悉它的能力边界后,才知道在哪些场景可以落地。
01
AI大模型在企业场景落地的核心能力
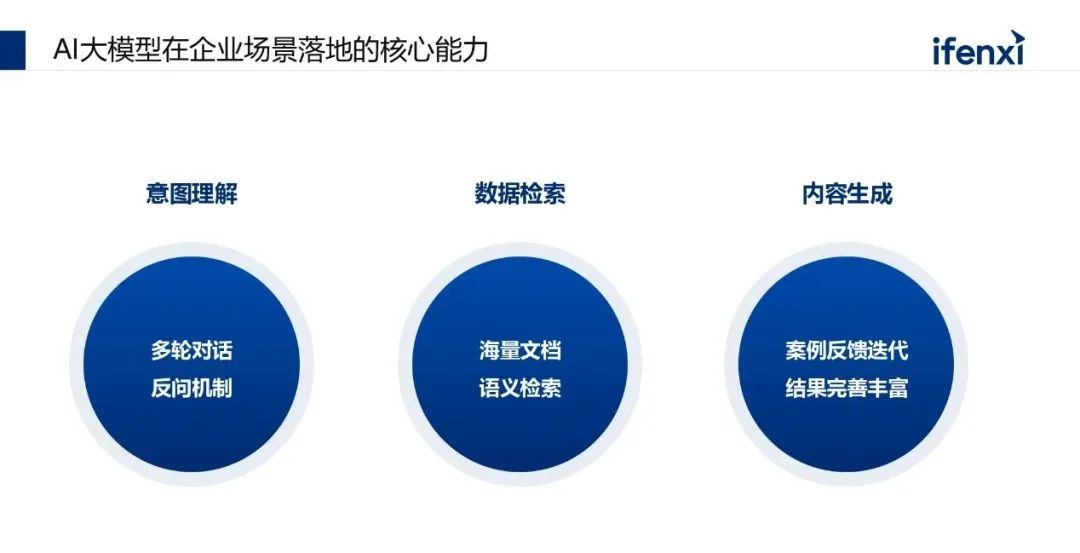
第一个是意图理解,这个大家都比较熟悉,大语言模型很强的能力是做自然语言的语义理解。相比传统 AI 的提升在于,一方面是大模型可以做多轮对话,目前国产大模型的多轮对话的能力基本上也赶上了GPT的能力。另一方面是大语言模型的反问机制,很多时候准确率达不到要求,不一定是模型理解的问题,而是因为用户提供的信息不全,忽略了很多背景条件,人与人交流方式,模型去理解会比较难。今年很多Agent 加了一个能力,就是反问。通过反问的机制让用户把他的问题背景条件补充得更全,能够让模型更容易理解用户的意图,这个是AI大模型在企业落地时比较强的能力。第二个是数据检索,海量文档的处理检索以及语义检索能力。大模型在企业落地时,它的推理能力是和数据检索有很强关联性。基础大模型不太可能具备真正场景化的理解能力,缺乏相应的知识,实际落地是主要依托数据检索。例如,半导体行业有个场景是良率分析,基于晶圆片的良率,反推整个工艺过程中有哪些是需要做改善和改进。过往是需要故障晶圆片达到一定数量(1000片以上)才能去做人工分析。把大模型能力加入后,大模型可以对所有历史结果进行处理,针对现在出现的良率问题,给一些指导方向,指出在工艺端可能会存在哪些问题,这用到的就是大模型的海量文档处理能力。语义检索是大模型具备通识,除了关键词检索之外,对于相关语义的检索能力也比较强,这个胜于传统 NLP 技术。
第三个是内容生成,原来讲比较多的是素材生成方案,在这里想重点强调的是一个案例的反馈迭代。传统AI 模型有一个非常大的问题,就是它的维护成本很高。以客服场景为例,客服机器人上线后,后期持续维护和迭代成本非常高,因为会有新的语料不断生成,把新的政策、新的问答加入到其中,这就意味着知识库需要不断地调整,这个过程中需要大量的人工去做。现在大语言模型有比较好基于用户案例反馈的机制,用户端会看到基于问答答案的点赞或者点踩,这个本质上是给好的反馈。这种好的反馈本身是可以反向生成最佳案例,这些案例进入到知识库当中会让整个案例持续迭代和反馈,这个就体现出大模型具备一定记忆能力,会越用体验越好,再加上它能自动化的生成内容,这块是一个很强的能力。
02
企业端比较好落地的场景
 首先,从刚才讲的AI大模型的核心能力看,知识库在企业场景方面是非常核心的,不管是直接模型调用,还是训练行业垂直模型,都非常依赖企业知识库。这就意味着在选择落地场景时文档相对丰富的场景是比较好落地且能产生效果。第一个落地场景是客服,在绝大多数企业内部,客服的文档是相对比较全的,比如给客服人员的文档、话术等。第二个落地场景是合规,政策制度基本都是成文的,能比较好地去使用。第三个落地场景是科研,科研里面有大量的论文。所以是否可以很好的落地,重点在于是否有丰富的文档,因为大语言模型很擅长处理非结构化数据。
首先,从刚才讲的AI大模型的核心能力看,知识库在企业场景方面是非常核心的,不管是直接模型调用,还是训练行业垂直模型,都非常依赖企业知识库。这就意味着在选择落地场景时文档相对丰富的场景是比较好落地且能产生效果。第一个落地场景是客服,在绝大多数企业内部,客服的文档是相对比较全的,比如给客服人员的文档、话术等。第二个落地场景是合规,政策制度基本都是成文的,能比较好地去使用。第三个落地场景是科研,科研里面有大量的论文。所以是否可以很好的落地,重点在于是否有丰富的文档,因为大语言模型很擅长处理非结构化数据。
其次,刚才也提到在内容生成里面有一个很重要的点是案例迭代。需要在大量使用和迭代当中效果才能越来越好。所以落地的场景一般会找覆盖的用户量比较大,使用比较频繁的场景。所以我们看到的比较多的落地场景有公文写作、数字员工以及像工业场景里面的点巡检这种高频的场景。在实际落地中,让用户主动地和Agent沟通是有难度的,是无法建立起高频使用习惯。现在比较好的方式是推送,每天可以根据用户的关注问题,推送相关的信息。就比如巡检,可以基于巡检的结果,每天给值班长和工程师推送巡检的结果数据,就能够提升它的使用频率。第三是探索性的场景,大语言模型必然是有幻觉问题的。问数是准确率目前做的很高的场景,今年可能做到接近95%,这个准确率看似很高,但是在很确定性的场景中用的时候,它做不到100%,那就是不可用的状态。所以反倒是一些探索性场景,大语言模型作为应用提供启发性的点,而不是提供非常准确的信息,这样相对会容易去使用。比如设备维修场景,当针对一个故障去做维修,大模型给出维修方案和诊断建议的时候,它其实也是一个探索,更多是提供一些相对可行的方向。再比如产品设计场景,基于过往的案例、用户的洞察结果和竞品的分析结果,它会提供一些方向上的指导。03
实践落地案例
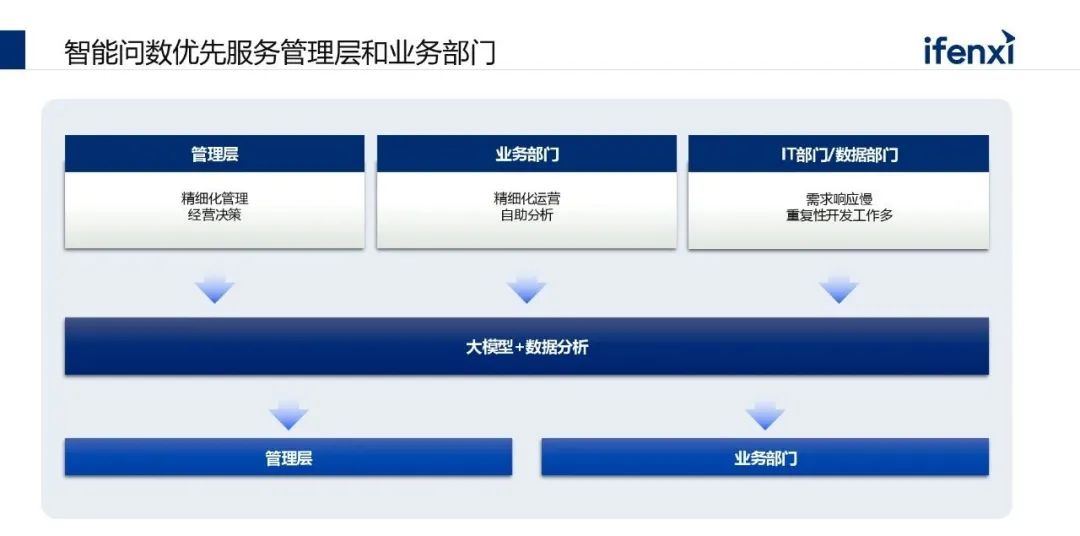
目前落地案例中问数场景还是关注度非常高的。在落地中,最大的挑战是应用场景到底面向谁。因为从用数的需求角度来说,管理层、业务部门、it 部门自身都有相关需求,服务于管理层,可能是落地到和驾驶舱的结合,或是领导看板。支撑于业务部门,不管是业务部门负责人,还是基层的管理者,可以更好满足他的日常自助式分析。从实际落地场景来看更多的还是面向管理层,发起部门也基本上是管理层,很少会是it 部门和数据分析部门发起需求,因为IT部门和数据分析部门一般觉得传统的敏捷式 BI 或者报表工具其实比较好用,而且问数价值比较难讲清楚。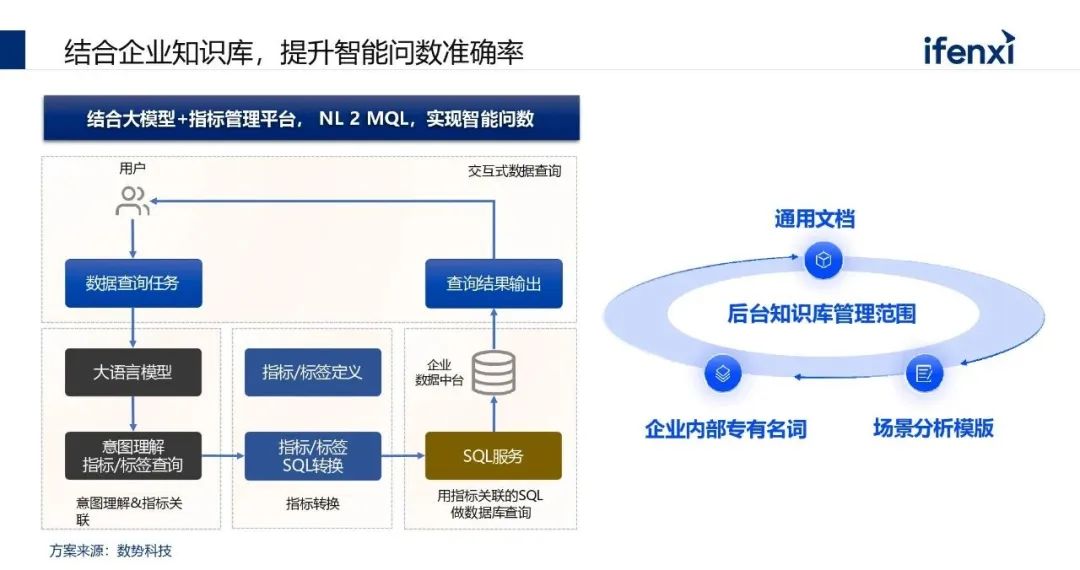
接下来分享一个结合企业知识库,提升智能问数准确率的解决方案,是参考我们的合作伙伴数势科技,这个方案从实现的角度来说,第一个是知识库非常关键,因为企业内部有大量的专有名词,这些名词企业内部人比较熟悉,但是大语言模型比较难去理解。所以最好是挂知识库,才能够使准确性提升。第二个是和指标平台做连接,直接做 NLP to SQL 的准确性实在是太低了,如果是to指标的话相对会比较容易,因为指标基本上都是带有业务语言的,一个用户在做意图理解和业务语言匹配的时候,是比较容易匹配上,指标这层基本上都会有业务属性,所以这个是现在比较常见的一种落地方式。
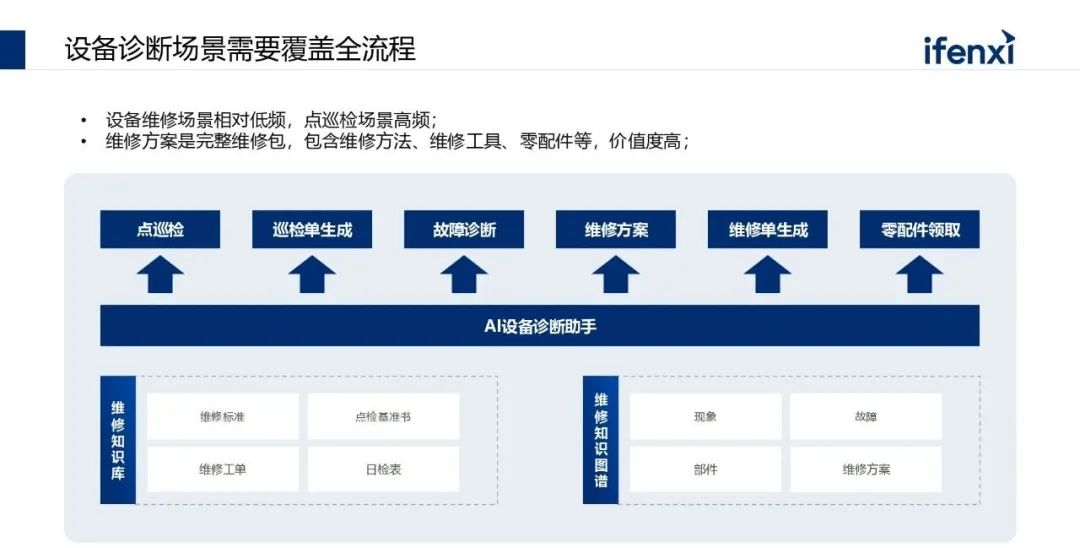
第二个案例是设备诊断,从场景角度来说,设备诊断一定要覆盖全流程,这样数据量比较大且覆盖全。这个场景下最大的问题是数据量不够,积累的故障数量比较有限。因为大量的故障来自于点巡检,所以通过点巡检可以发现更多的潜在故障和潜在信息。另一方面,维修工程师有一个很大痛点是点巡检前期拿到的数据信息不够全。通过设备诊断助手场景帮巡检员补全数据,这样才能把点巡检、设备故障这件事做好。故障诊断,到维修方案生成,再到最后的零配件,这才是一个完整的流程。从客户的角度来说,他要的不仅仅只是一个维修方案,要的是一个完整维修工作包,包含维修方法、维修工具、零配件领取等。
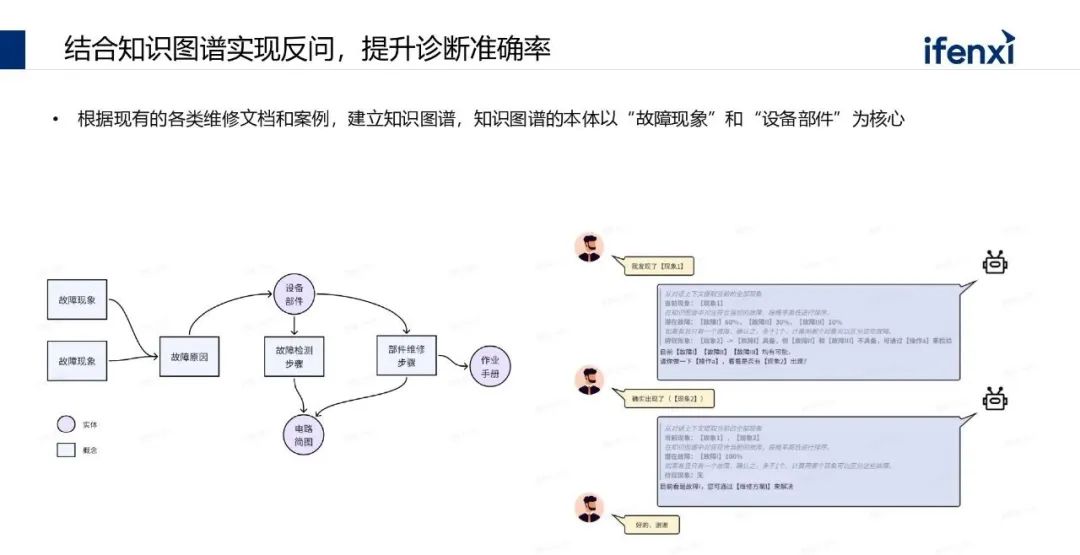
另外一方面是需要强调下知识库构建知识图谱的重要性,还是以设备诊断场景为例,基于故障现象做分析来判断故障的原因,如果前期做了整体的知识图谱构建,就可结合大语言模型的反问能力来快速的判断。比如出现了现象一后,现象1背后的知识图谱可能关联了三个故障,比如故障一、故障二、故障三。这个时候从图谱本身看到现象二和故障一是高度关联的,那可以做反问确认“用户有没有出现现象2”,如果确认出现现象2,则可准确地判断到底是哪个故障原因。所以它通过结合知识图谱之后,就具备了一定的推理能力,同时能够去提升整个诊断效果。从这两个案例可以看出来,大语言模型最后能在一个垂直场景中能发挥多大价值是非常依赖长久的知识和案例,知识和案例积累得越全,最终的应用效果和智能化水平才能够越高。以上就是我们觉得大语言模型接下来在 2025 年落地的时候,大家可能会重点关注的方向,希望后续跟各位可以再做更深入的探讨和交流。
⩓
毕业于清华大学,之前任职于亿利集团等上市公司金融事业部,近10 年金融与私募股权投资领域分析咨询经验,专注于科技研究,对于云计算、大数据、人工智能等众多领域有着深入的研究与思考。注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。