

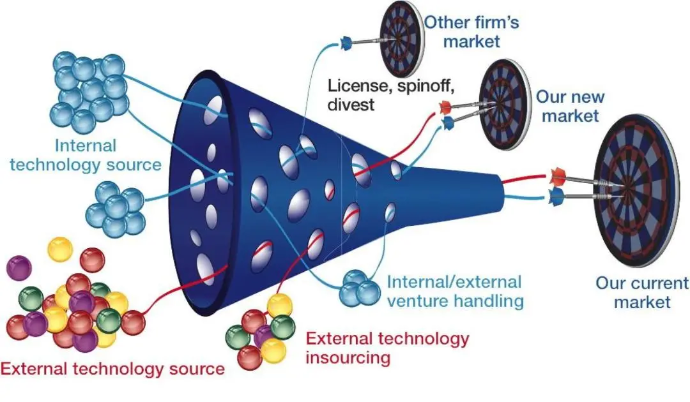
Henry Chesbrough在著作《通过技术创新盈利势在必行》中,曾提出过一个创新的“漏斗模型”。开放式创新一开始鼓励百花齐放,但最终只有10%的技术能够通过这个漏斗,成功抵达目标市场target market,进入到商业化与产业化的下一个阶段,而其余的90%的技术,逐渐淡出人们的视野。
大模型的2024,就经历了漏斗秩序的残酷检验。
2023年初,业界最关注的问题是“中国能不能孕育出顶尖的大模型”。随后一年,国产大模型数量的井喷式增长,完成备案并上线服务的大模型数量已达100多个。
于是到了2024年初,大家最关注的问题已经变为“这么多的大模型,我们该怎么消化和利用?”
如今来看,经过百模大战,基础大模型已“去九存一”,只有约10%的具有市场活力、用户活跃度高的大模型脱颖而出,进入到了决赛圈。大模型的商业市场,也从百家争鸣,收束为两股势力:
一是以互联网、云计算企业为代表的科技巨头,包括百度的文心大模型、阿里的通义大模型、腾讯的混元大模型、字节跳动的豆包大模型、华为的盘古大模型。
二是以“AI六小虎”为代表的头部创企,比如智谱AI的智谱清言、零一万物的Yi大模型家族。

可以说,大模型在2024年,走过了一个完整的“漏斗模型”。但重资产的大模型行业,竞争也远比一般技术更残酷。我们预计,99%的大模型都会丧失产业空间。所以,这场模型淘汰赛并未到终局。接下来,基础模型的创新漏斗还会进一步收窄,最终仅留下三四个产品,作为AI基础设施。
我们还是有必要花一点篇幅,来回溯一下2024年的大模型淘汰赛,留下了哪些种子选手。

2024国内外的大模型格局,都呈现出鲜明的马太效应。在海外,OpenAI、谷歌、微软等巨头屹立不倒,而众多大模型初创公司,诸如Stability AI、Adept、Humane、Reka AI等,则排队寻求出售。
国内的情况也大致相似。以互联网和云厂商为代表的科技巨头(百度、阿里、腾讯、华为、京东、字节跳动),以及融资能力出众的AI创企(AI六小虎),成为大模型商业市场中具备活力的竞争者。
潮水退去,暴露出沙滩上的礁石,而产学各界炼大模型的热情消退,我们得以在2024年看到更清晰的大模型商业模式。具体来说,大模型成功穿过漏斗,需要三种动力:
1.可持续的资源投入。AI大模型是一个重资产行业,2024年Scaling Law仍未失效,随着模型不断变大,训练新模型所需要的高质量数据量与计算量也在增加。这就像登山,百尺竿头更进一步。而头部企业在资金、技术、数据等方面的优势日益凸显,代表就是字节跳动。

字节跳动2024年才开始全力押注大模型,5月推出的豆包大模型很快就在业内崭露头角,日均Tokens使用量从5月份的1200亿,9月突破了1.3万亿。凭借此前的火山云基础设施和人才团队积累,以及这一年大举挖人、增加投入,在几个月内就建立了优势壁垒。
2.快速迭代的模型能力。字节跳动的后来居上、快速超车,也说明AI大模型并没有特别安全的护城河。模型能力在不断贬值,有了新的更高级的模型版本,旧模型就不值钱了;有了开源模型,能力接近的闭源模型就会被开发者放弃。这就要求模厂不断开发更强大的新模型,迭代旧模型。
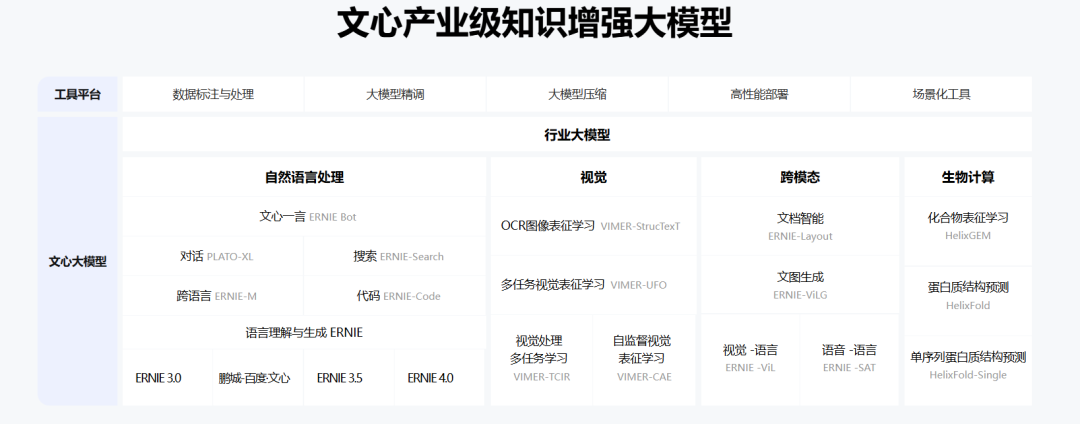
比如文心大模型,得益于百度在芯片、框架、模型和应用上的全栈布局,以及飞桨深度学习平台和文心的联合优化,文心大模型的迭代速度,一直处于业内领先水平。2024年百度在文心大模型4.0的基础上,相继推出了文心大模型4.0工具版、文心大模型4.0 Turbo,推理速度和效果进一步提升。而模型的迭代速度快,有助于增强用户和开发者的信心,增加使用黏性和付费意愿。

3.可变现的商业通道。模厂的竞争,不仅表现在基础模型的研发上,而体现在后续的商业推广。
2024年,大模型从“价格战”杀到了“免费战”,5月字节跳动将国内大模型的市场价格带入“厘时代”,随后文心大模型就宣布两大主力模型ENIRESpeed和ENIRELite全面免费。随着模型进入免费时代,模厂就必须有其他商业通道来实现营收,收回自己在大模型上的前期投入。
其中,科技巨头大多直接掌握着用户数据、应用产品和渠道资源,可以让AI大模型触达最终用户,为价值付费。比如百度文库app,就通过AI改造,上线了基于文心大模型的智能PPT、智能画本等一系列AI功能,付费用户快速增长,目前已有数千万AI月活用户。
而AI创企则有望凭借新锐的技术和产品解决方案,在商业市场中脱颖而出。“六小虎”中,零一万物明确表示不会放弃预训练模型。目前,零一万物正基于Yi 系列基座模型的标准化能力,深入业务场景的垂直精细化切口,推出了数字人解决方案“如意”、营销短视频解决方案“万视”。
总的来说,2024的大模型产业,就是一个又一个的大模型被推向市场之后,不得不面对一个狭窄的“漏斗”出口,经历一场艰难的淘汰赛。互联网与云计算巨头和极少数AI独角兽,成功穿过漏斗,抵达下一阶段。

2024年的淘汰赛洗礼,让大模型去九存一,产业格局更加合理,只留下了约10%的大模型进入决赛圈。
从结果看,大模型呈现出“强者恒强”的马太效应。那么,这些强者是怎么从战场中厮杀出来的呢?如果说2023年,大模型的关键一战,是基础设施攻坚战,各个模厂都不遗余力地建设训练大模型所需要的算力集群和高端硬件资源,那么2024年,大模型的关键一战,则转向了商业市场的争夺战。
争夺活跃用户,这一年大模型的商业市场有两个主题:
主题一,烧钱营销。
基于大模型的生成式AI(AIGC)产品,可以通过为用户提供服务来完成商业转化,这也成为大模型最直接、最快速的商业化路径。2024年,AIGC产品爆发,根据《生成式人工智能服务已备案信息》显示,截至2024年11月,我国共有309个生成式人工智能产品完成备案。而如此繁多的AIGC产品,存在大量重叠的功能,于是,模厂不得不通过大规模、高频次的市场推广和营销活动,来争夺活跃用户,提高用户基数。

月之暗面、智谱等都被报道过在营销上砸了重金,kimi智能助手的平均单个用户获客成本高达30元。
这些烧钱营销的AIGC产品,切实提升品牌知名度和用户基数,但也必须承认,最终能够激活多大的商业价值尚不明确。
主题二,走向应用。
不烧钱买流量,不赔本赚吆喝,大模型有可能赚到钱吗?那就需要向应用走。走向产业,走向广大用户和开发者,通过价值付费、项目付费等实现商业化,2024年,“大模型致用”已经是事实。
首先是智能体,让大模型更有用。大模型的应用从AI助手,转向了智能体,比如豆包、kimi、文小言等,能够自动拆解指令并执行一些简单的操作,“自动驾驶”水平更好,极大地提升了技术的可用性。

其次是工具链,让大模型更好用。文心智能体平台、字节跳动扣子、阿里通义千问等,都推出了智能体技术及工具链的支撑能力,普通人也能快速低成本地制作属于自己的智能体。其中,押注“AI应用化”的百度在智能体生态上布局最全,推出了APP builder、Agent builder等开发平台,以及本地部署一体机等硬件,支持C端和行业用户开发专属智能体。字节跳动的扣子也极易上手,用户可以复制官方的高质量模板,结合私有数据快速完成智能体开发,并发布到字节系等产品中使用。
“砸钱买量”“以用换量”,这两大主题交织在2024年的大模型商业化之战中,一家模厂可能综合运用这两种手段,来确保大模型的用户基数与市场活力,稳固住这一阶段的领航地位。

消费级技术,有一个基本规则:将复杂技术简单化,从而解锁突破性应用。就像我们平时发邮件,不需要探究背后的SMTP协议,使用手机支付,也不必弄懂背后的加密技术。这种“藏起代码”的简化,使得技术更加易用,因此能够更快普及和扩展。
由此,我们可以预测一下,底层模型的“决赛圈”可能发生哪些变化:
模型数量变少。科技巨头和AI创企领航的大模型们,还将继续洗牌,最终只留下3—4个基础模型,作为基础设施来支撑丰富多样的下游应用。这个过程中,投入的可持续性、迭代速度、商业化能力依然会发挥关键影响,互联网公司和云厂商的胜算更大。

使用进一步简化。目前来看,大模型技术的使用还有继续简化的空间。比如智能体开发,仍然没有实现低代码或零代码,一旦涉及个性化场景的专业插件、知识库、数据处理等,开发工程的复杂度就又会变高,阻拦一些行业专家开发专业性更强的智能体,这限制了大模型在B端的爆发。所以2025年,智能体开发与专属模型训练,应该会变得更简单、傻瓜式,想上手AI开发的零基础读者不妨期待一下。
生态变大。人人都能上手AI开发,涉及对私有敏感数据的训练分析,以及多种多样的个性化功能需求,因此基础模厂不能只提供对一个底层模型的简单封装,而要支持本地训练与部署,多种模型的调用与组合,更多元的发布渠道,这些要求基础模厂能够将AI硬件、AI终端、垂类模厂、渠道伙伴等都纳入自身的生态体系内,共同满足用户的定制化需求。“朋友圈”有多大,也是2025年的一个大模型赛点。

2024年,底层模型的中场战事宣告结束,进入决赛圈。随着大模型的漏斗被收束到最小,AI应用的漏斗才刚刚开始喷发。你听,“人人皆可AI”的2025离我们越来越近了。

