
点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 新智元 授权
当今AI届的繁荣,很大程度上要归功于Transformer模型,2017年的开山之作,把「注意力机制」(attention)带入了大众的视野,此后七年中,在AI模型中占据了绝对的主导地位,甚至Attention is All You Need这个名字都让之后的论文在起标题时纷纷效仿,逐渐走向狂野。
但「正统」注意力机制其实来源于2014年Bengio的论文,ACM还在图灵奖颁奖时,为Bengio写的贡献为「引入了一种注意力机制,带来了机器翻译的突破,并形成了深度学习顺序处理的关键组成部分」。

论文链接:https://arxiv.org/pdf/1409.0473
最近,Andrej Karpathy在社交媒体上公开了与第一作者Dzmitry两年前的联络邮件,详细叙述了这段发明注意力的故事,顿时又掀起网友热议。
不过,LSTM作者Jürgen Schmidhuber却不认可这段故事,而是表明自己才是真正的创造者,1991年就已经提出线性复杂度Transformer,并且在两年后提出术语「注意力」,他在2023年12月还发表过一篇报告,控诉图灵奖三巨头抄袭自己的研究成果。

关于「Attention起源」的辩论进展火热,仿佛现代AI完全构建在注意力机制的理论之上,关于Transformer、系统实现的重要性却被忽视了。
虽然Attention is All You Need论文的核心贡献是引入Transformer神经网络,删除了除各种注意力机制之外的所有模块,并且基本上只是将其与多层感知机堆叠在ResNe中,但其实论文中还是有相当多的贡献和独特想法,包括位置编码、缩放注意力、多头注意力、极简设计等等,并且被广为接受。
即便是到了今天,业内普遍使用的模型架构仍然大体遵循2017年的原始版本,只是在部分模块进行了简单的修改,比如更好的位置编码方案(RoPE家族)等等。
谷歌杰出科学家、计算成像、机器学习和视觉领域的专家Peyman Milanfar说的很中肯:
我——或者我认为任何成像领域的人——都不能合理地宣称机器学习背景下的注意力概念有任何功劳。但记录、追溯完整的历史渊源是有价值的,如果不从更广泛的角度来理解「依赖于数据的加权平均运算」的重要性和普遍性,那追溯的历史也是不完整的。
最极端的例子莫过于一位网友的评价,「其实,算术的出现要比这些论文都早。」

「注意力」的起源故事

当时他跟Yoshua表示干什么都行,然后Yoshua便让他开始与Kyunghyun Cho的团队合作开发机器翻译模型。
当时自然语言处理届的主流思路是「把单词序列转为一个向量」,比如经典的word2vec都是当时常用的算法,但Dzmitry却对这种想法表示怀疑,不过为了获得博士的入学offer,他也只能听从导师的话,从写代码、修复Bug等最基本的工作入手。
逐步熟悉团队的工作内容之后,Yoshua就对他发起了攻读博士学位的邀请,当时AI届还没有现在这么卷,这些工作已经足以让这位硕士生开始他的博士生涯了,Dzmitry至今仍表示庆幸、怀念。
博士offer稳了之后,据Dzmitry的说法是,可以享受科研乐趣,并充分发挥自己的创造力了!

Dzmitry开始思考如何避免RNN模型中Encoder和Decoder之间的信息瓶颈,第一个想法是建立一个带有两个「光标」(cursor)的模型:其中一个由BiRNN编码,在源序列中移动;另一个在目标序列中移动;光标轨迹使用动态规划进行边际化。
但Kyunghyun Cho认为这种做法和Alex Graves的RNN Transducer模型没什么两样。
读完Graves的手写识别论文后,Dzmitry也认可这种方法法对于机器翻译来说不太合适,并且实习也只剩5周了,很难在短时间内完成代码实现,所以就尝试了更简单的方法,让两个光标同时、同步移动,实际上相当于硬编码的对角注意力(hard-coded diagonal attention)。
这种方法虽说有点效果,但不够优雅。
某一天,Dzmitry受到了英语翻译练习中的启发,人类在翻译时,目光会在源序列和目标序列之间来回移动,将软搜索表示为softmax,然后对BiRNN状态进行加权平均,就能让Decorder RNN学会在源序列中搜索放置光标的位置。
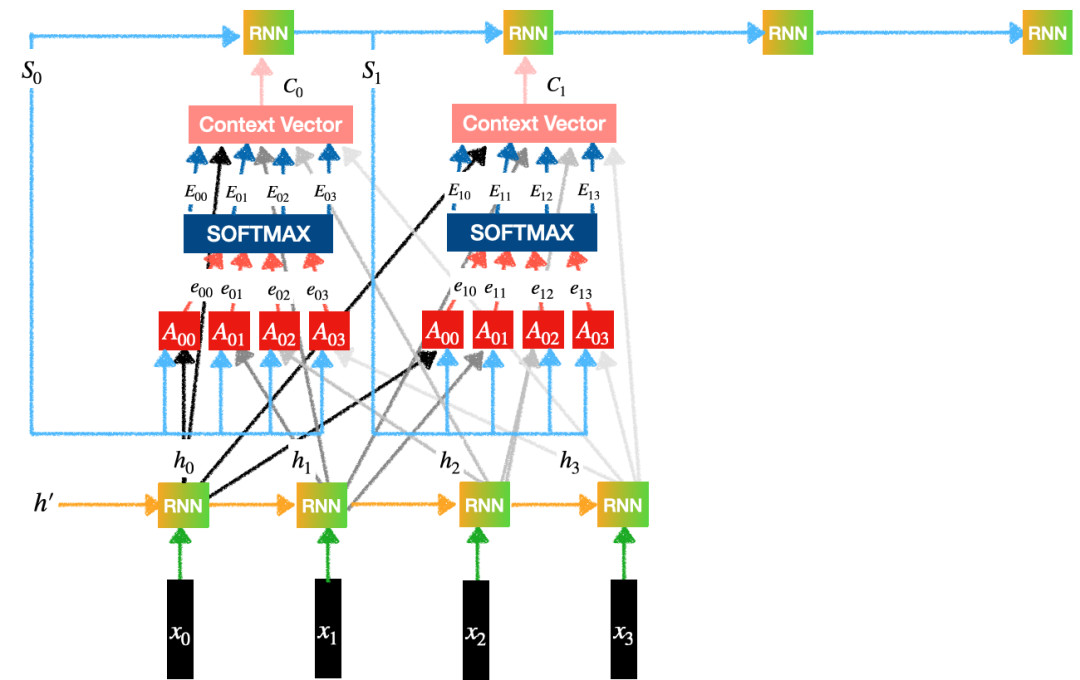
团队把这个架构叫做RNNSearch,第一次尝试效果就很好,只需要1个GPU就能运行。
当时,谷歌的Ilya(OpenAI前首席科学家Ilya Sutskever)团队使用8个GPU的LSTM模型在某些指标上仍然领先,所以团队赶紧在ArXiV上发表了一篇论文。
后来团队发现,这个架构的名字其实并不好,Yoshua在最后的一次修改中确定了「注意力机制」,直观地看,让解码器来决定源语句中的哪些部分需要受到关注,减轻了编码器将源语句中的所有信息编码为固定长度向量的负担。通过这种新方法,信息可以分布在整个标注序列中,解码器可以有选择地进行检索。

一个半月后,团队又看了Alex Graves发表的关于NMT论文,想法完全相同,但出发点完全不同。
Dzmitry发明新算法是需求驱动的,Alex那边或许是出于连接神经学派和符号学派的目的;Jason Weston团队的Memory Networks论文也有类似的机制。
Dzmitry表示没有预见到注意力机制作为表征学习的核心算法,其实可以在更低的层次上使用。
所以当Transformer论文发表时,Dzmitry就立刻跟实验室的同事说,RNN已经死了。
总之,在蒙特利尔Yoshua的实验室中「可微且数据依赖的加权平均」(differentiable and data-dependent weighted average operation)的发明与神经图灵机、Memory Networks以及90年代(甚至 70 年代)的一些相关认知科学论文无关,主要来源于Yoshua的领导,Kyunghyun Cho在管理由初级博士生和实习生组成的大型机器翻译项目方面的出色技能,以及Dzmitry多年来在编程竞赛中磨练出的创造力和编程技能。
即使Dzmitry、Alex Graves和其他人当时没有从事深度学习工作,这个想法也会由其他人发表出来。注意力机制只是深度学习中实现灵活空间连接的自然方式,只要GPU的运算速度足够快,让科研人员有动力并认真对待深度学习,就会自然而然出现。
良好的研发工作可以为基础技术的进步做出更多贡献,而不是通常意义上、所谓「真正的」人工智能研究的花哨理论。
九十年代的「注意力」机制
最早的「可微加权平均操作」甚至并不来源于机器学习领域,而是图像处理中常用的「滤波器」(filter)。
比如最著名的是1998年Tomasi和Manduchi的双边滤波器,以及1997年Smith和Brady提出的SUSAN滤波器;后面还出现过许多变体形式,包括2005年的Buades、Coll和Morel提出的非局部均值,以及2007年Peyman Milanfar提出的更通用的核回归滤波器。
论文链接:https://ieeexplore.ieee.org/abstract/document/4060955
阿卜杜拉国王科技大学 (KAUST) 人工智能研究所所长、瑞士人工智能实验室IDSIA科学主任、LSTM作者、现代人工智能之父Jürgen Schmidhube也参与到这场推特大战之中。

2023年12月,Jürgen就曾发布过一篇报告,控诉三位图灵奖得主Bengio, Hinton和LeCun各有相关工作参考于他之前的工作,但并没有标注引用,「抄袭」罪状中,Bengio七条、Hinton六条、LeCun四条。

报告链接:https://people.idsia.ch/~juergen/ai-priority-disputes.html
Jürgen在报告中指出,1991年3月,他就已经提出了所谓的具有「线性自注意力」的非归一化线性Transformer(unnormalized linear Transformer with linearized self-attention),只不过当时的名字叫做「快速权重编程器」(Fast Weight Programmers)和「快速权重控制器」(Fast Weight Controllers),类似传统计算机将存储和控制分开的方式,以端到端可微分、自适应、完全神经的方法,只不过当时Key/Value被称为From/To

虽然名字不一样,但两个模型背后的数学原理大致相同。
1991年发表的模型原理类似于:为了回答接收到的query,通过梯度下降来学习生成key和value的模式,对自身的某些部分进行重新编程,从而根据上下文将注意力引导到重要的事情上;现代Transformer也采用了同样的原理。
2021年,Jürgen在ICML上发表了一篇论文,进一步证明了二者的等价性。

论文链接:https://arxiv.org/pdf/2102.11174
在1991年,当时的计算成本比现在高出数百万倍,所以计算效率很重要,Transformer的计算复杂度为二次方,所以无法扩大数据处理规模,而快速权重编程器的计算复杂度只有线性,据Jürgen所说,当年几乎没有期刊会接受二次缩放的神经网络。
1993年,Jürgen对线性Transformer进行循环扩展时,使用了术语「注意力」。


论文链接:https://sferics.idsia.ch/pub/juergen/ratio.pdf
正如文章开头所说,Bengio团队因注意力机制获图灵奖,之后的工作都以Bengio 2014年的论文作为注意力机制起源。
Jürgen还表示,在2010年代,ACM所谓的关键「机器翻译的突破」也不是Bengio的功劳,而是LSTM的功劳,在2016年极大地改进了Google 翻译,甚至直到 2017 年,Facebook用户每周还要进行300亿次基于LSTM的翻译请求。
总之,技术起源的是是非非很难辩个清楚,拿出小板凳,理性吃瓜!
OpenCV4系统化学习


推荐阅读
OpenCV4.8+YOLOv8对象检测C++推理演示
ZXING+OpenCV打造开源条码检测应用
攻略 | 学习深度学习只需要三个月的好方法
三行代码实现 TensorRT8.6 C++ 深度学习模型部署
实战 | YOLOv8+OpenCV 实现DM码定位检测与解析
对象检测边界框损失 – 从IOU到ProbIOU
初学者必看 | 学习深度学习的五个误区

