



2017 年谷歌将注意力机制引入神经网络,提出了新一代深度学习底层算法 Transformer。由于其在物体分类、语义理解等多项任务中准确率超过 CNN、RNN 等传统算法,且能应用于 CV、NLP 等多个模态,Transformer 的提出使得多任务、多模态的底层算法得到统一目前主流大模型均采用 Transformer 作为底层骨干网络,但在编码器\解码器选择、多模态融合、自注意力机制等方面有所创新。
人工智能基础知识
算法:骨干网络Transformer架构
目前主流大模型可以根据骨干网络架构的差异分 Encoder-only、Encoder-Decoder、Decoder-only 共 3 类,如下图:
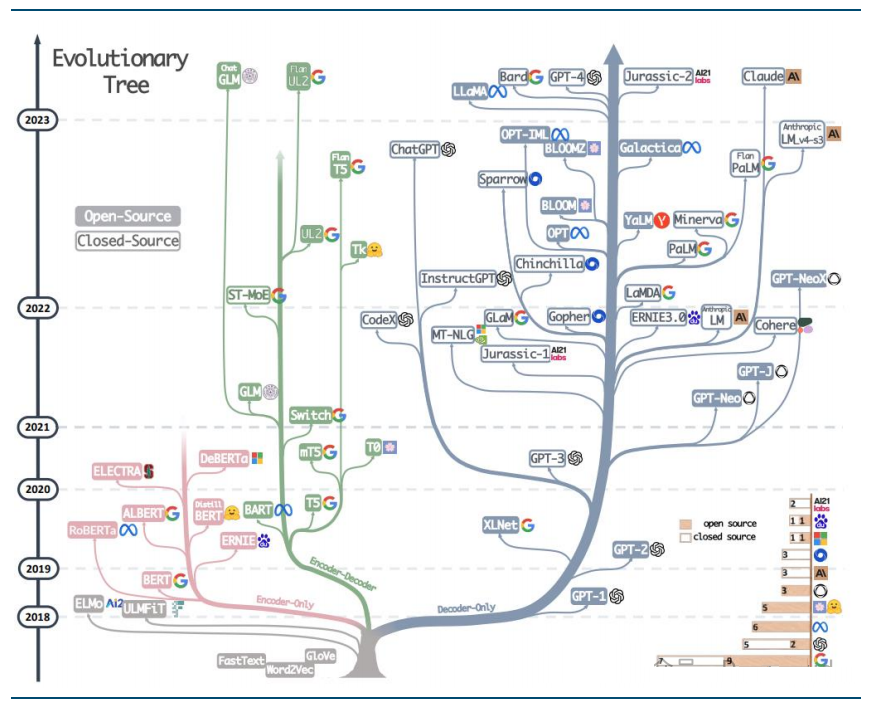
其中 Encoder-only 主要为谷歌的 Bert 及其衍生优化版本;
使用 Encoder-Decoder 架构的模型有谷歌的 T5 以及清华智谱的 GLM 等;
OpenAI 的GPT 系列、Anthropic 的 Claude 系列、Meta 的 LLaMA 系列等均采用 Decoder-Only架构。
Decoder-Only 架构更适合生成类任务且推理效率更高,为大模型厂商所青睐:
功能方面:Encoder-Only 架构更擅长理解类而非生成类任务,以采用 Encoder-Only 架构的 Bert 为例,其学习目标包括 Masked LM(随机遮盖句子中若干 token 让模型恢复)和 Next Sentence Prediction(让模型判断句对是否前后相邻关系),训练目标与文本生成不直接对应;
推理效率方面:Encoder-Decoder 和 Decoder-Only 架构均能够用于文本生成,但在模型效果接近的情况下,后者的参数量和占用的计算资源更少,且具有更好的泛化能力。
三种骨干网络特点对比如下图:

Transformer 模型结构及自注意力机制原理如下图:
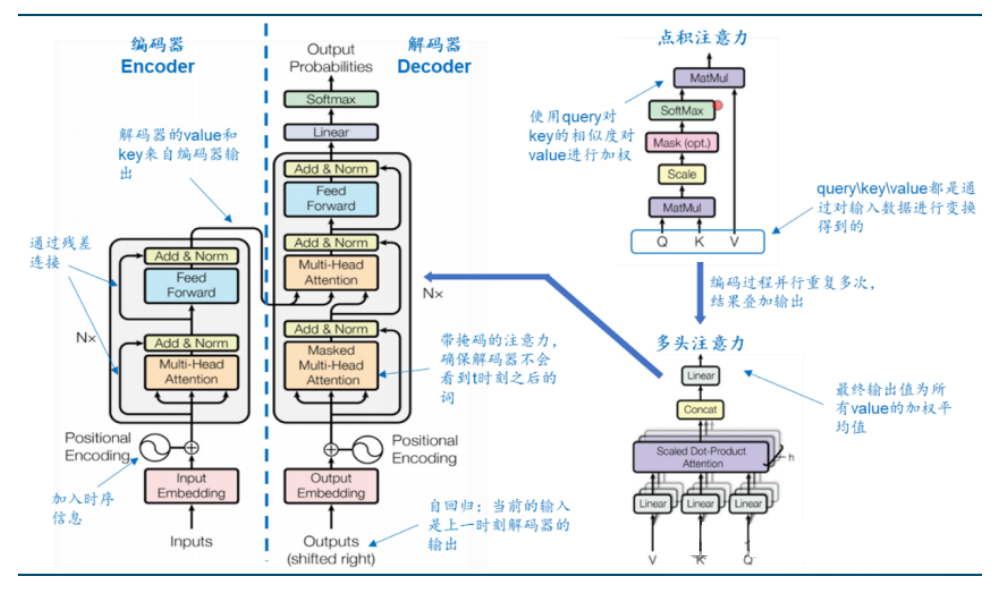
Transformer 模型采用编码器-解码器结构:
其中编码器负责从输入内容中提取全部有用信息,并使用一种可以被模型处理的格式表示(通常为高维向量);
而解码器的任务是根据从编码器处接收到的内容以及先前生成的部分序列,生成翻译后的文本或目标语言。
自注意力机制(Self-Attention)使得 Transformer 架构能够处理多模态任务。自注意力机制将输入数据进行线性映射创建三个新向量,分别为 Q/K/V
其中 Q 向量可以看作是某个人的关注点
V 向量可以看作是具体的事物
而 K 向量可以看作是人对不同事物的关注程度。
通过计算 Q 向量和 K 向量的点乘,可以得出一个值,表示这个人对某个事物的关注程度,然后将这个关注程度与 V 向量相乘,以表示事物在这个人眼中的表现形式。
这种方式使得模型能够更好地捕捉长序列中不同部分的关联性和重要性,而各种模态的信息均可以通过一定方式转化为一维长序列,因而Transformer 具备处理多模态问题的能力。
以上海 AI Lab 和香港大学联合推出的 Meta-Transformer 为例,该模型通过一个多模态共享的分词器,将不同模态的输入映射到共享的数据空间中,进而实现了处理 12种非成对的模态数据,包括文本、图像、点云、音频、视频、X 光、红外等。
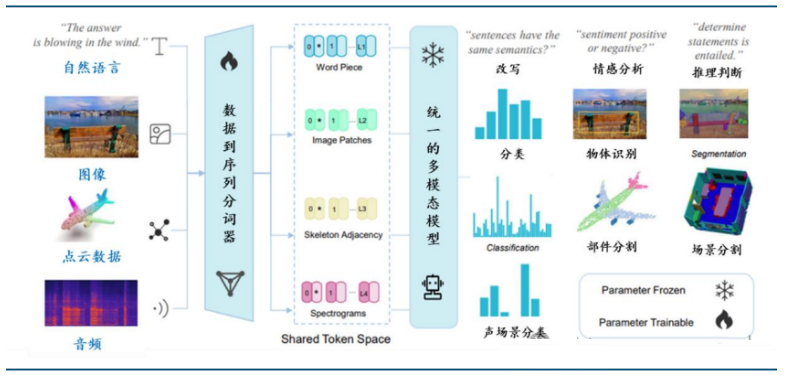
将 Transformer 与其他模态领先算法融合,能够显著提升多模态处理能力,有望加速大模型多模态融合趋势。
24 年 2 月 OpenAI 发布文生视频大模型 Sora,主要根据Diffusion Transformer(DiT)框架设计而成。其中,扩散模型(Diffusion)是一种图像生成方法,通过逐步向数据集中添加噪声,然后学习如何逆转这一过程。
扩散模型能够生成高质量的图像和文本,但仍存在可扩展性低、生成效率低等问题。
DiT 模型在扩散模型基础上引入 Transformer 架构,通过将图像分割成小块(patches),并将这些块作为序列输入到 Transformer 中,DiT 能够有效地处理图像数据,同时保持了Transformer 在处理序列数据时的优势,能够显著改善扩散模型的生成效率。此外,将自动驾驶领域的 BEV(鸟瞰视图)模型与 Transformer 相结合,已经成为目前自动驾驶领域主流感知框架,并在众多辅助驾驶产品中量产应用。
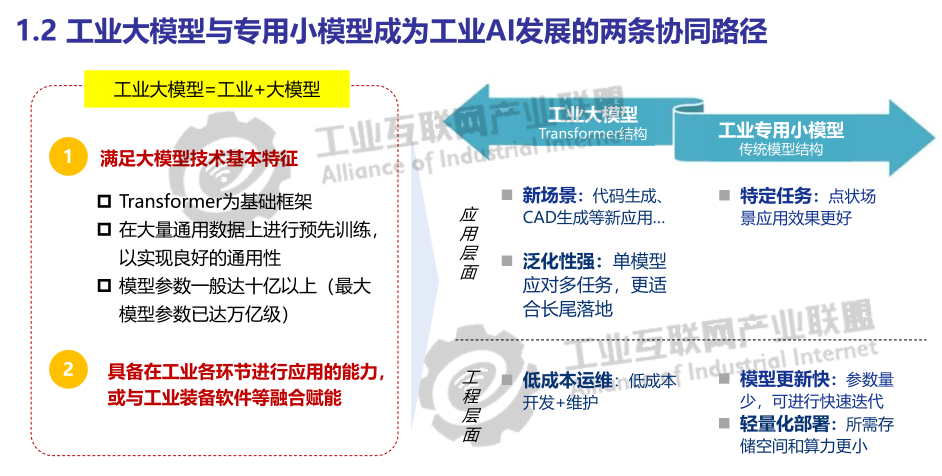
大模型和小模型在工业领域将长期并存且分别呈现 U 型和倒 U 型分布态势
从工业智能化的发展历程可以看出,在大模型出现之前,人工智能技术在工业领域已有较多应用。在前期阶段,工业人工智能的应用主要是以专用的小模型为主,而大模型开启了工业智能化的新阶段。结合两者不同的技术特点和应用能力,目前在工业领域形成了不同的分布态势。
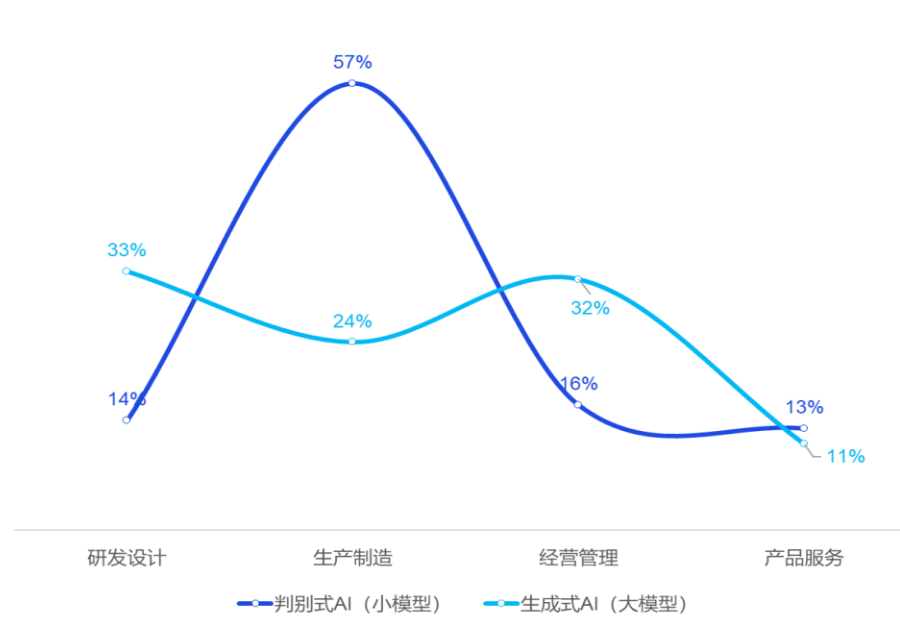
1. 以判别式 AI 为主的小模型应用呈现倒 U 型分布
根据中国信通院2对 507 个 AI 小模型应用案例的统计分析,这些应用主要集中在生产制造领域,占比高达 57%,而在研发设计和经营管理领域的应用则相对较少。这种分布呈现出明显的倒 U 型。
小模型的核心特点是学习输入与输出之间的关系。小模型通过学习数据中的条件概率分布,即一个样本归属于特定类别的概率,再对新的场景进行判断、分析和预测。它的优点是通常比大模型训练速度更快,而且可以产生更准确的预测结果,尤其适用于对特定任务进行快速优化和部署的场景。以工业质检领域为例,小模型能够从海量的工业产品图片数据中,学习到产品的外观特征、质量标准和缺陷模式等关键信息。
当面对新的样本时,小模型能够迅速判断样本是否合格,从而实现对产品质量的快速检测。同样在设备预测性维护方面,小模型通过对设备运行数据的分析,能够学习到设备正常运行的模式和潜在的故障特征。一旦监测到异常情况,小模型能够及时发出预警,提醒工作人员进行检修或维护。
小模型的能力更适合工业生产制造领域。首先,小模型能够基于有限数据支撑精准的判别和决策,而生产过程需要针对不同场景进行精准的分析和决策,这两者间的契合使得小模型在生产制造领域具有独特的优势。其次,生产制造过程对准确性和稳定性有着极高的要求,任何微小的误差都可能导致产品质量下降或生产线停工。小模型在训练过程中,能够针对具体场景进行精细化的调整和优化,从而确保模型的准确性和稳定性,这使得小模型在生产制造领域的应用更为可靠和有效。最后,小模型在成本投入方面相对较低,使得其在生产制造现场的应用更具经济性,并在有限的硬件条件下,能够稳定运行。
小模型的定制化需求制约了其进一步渗透。尽管小模型在生产制造领域表现出色,但其应用过程中也面临着一些挑战。以判别式 AI 为代表的小模型通常需要依靠个性化的业务逻辑进行数据采集、模型训练与调优,往往只能处理单一维度的数据。这一过程不仅消耗大量的算力和人力,而且训练后的模型往往无法在多行业通用。例如,工业缺陷检测领域的视觉模型往往需要针对一个产品或者一个设备训练一个模型,产品或设备不同,就要对模型进行重新训练,这种定制化的需求在一定程度上制约了小模型在工业领域的进一步渗透。
2. 以生成式 AI 为主的大模型应用呈现 U 型分布
根据对 99 个工业大模型应用案例的统计分析,大模型在研发设计和经营管理领域的应用相对更多,整体上呈现出 U 型分布。这表明大模型当前的能力更适配于研发设计和经营管理,在生产制造环节的能力和性能还需进一步提升。
大模型通过构建庞大的参数体系来深入理解现实世界的复杂关系。大模型的核心在于学习数据中的联合概率分布,即多个变量组成的向量在数据集中出现的概率分布,进而通过使用深度学习和强化学习等技术,能够生成全新的、富有创意的内容。与传统的数据处理方法不同,大模型并不简单地区分自变量与因变量,相反,它致力于在庞大的知识数据库中提炼出更多的特征变量。
这些特征变量不仅数量庞大,而且涵盖了多个维度和层面,从而更全面地反映现实世界的复杂关系。以自然语言处理为例,大模型通过学习大量的文本数据,能够掌握语言的规律和模式。当给定一个句子或段落时,大模型能够基于联合概率分布生成与之相关的新句子或段落。这些生成的内容不仅符合语法规则,而且能够保持语义上的连贯性和一致性。此外,大模型还能够根据上下文信息理解并回答复杂的问题,展现出强大的推理和创造能力。
大模型更适合综合型和创造类的工业场景。在综合型工业场景中,由于涉及到多个系统、多个流程的协同工作,需要处理文档、表格、图片等多类数据,变量之间的关系往往错综复杂,难以用传统的分析方法进行精确描述。大模型通过深度学习和复杂的网络结构,可以捕捉并模拟这些关系,从而实现对复杂系统的全面理解和优化。在创造类工业场景中,大模型的优势体现在其强大的内容生成能力上。例如,在产品外观设计方面,传统的设计方法往往依赖于设计师的经验和灵感,设计周期长且难以保证设计的创新性。而大模型通过学习大量的设计数据,能够掌握设计领域的规律和模式,进而生成符合要求的全新设计内容,提升产品设计的效率和质量。
大模型在工业领域的应用潜力仍有待释放。首先,大模型技术本身正处于快速发展的阶段,尽管已取得了显著进步,但在成本、效率和可靠性等方面仍有待进一步提升,以适应工业领域日益复杂的需求。其次,工业场景众多且各具特色,大模型作为新技术,需要逐步与各个工业场景紧密结合,在逐步提升技术渗透率的过程中,挖掘可利用的场景,并根据行业特定需求提供定制化的解决方案。最后,工业领域自身的数据分散且缺少高质量的工业数据集,同时在实际生产中如何确保工业数据的隐私和安全也是企业关注的重点,这些现实问题也限制了大模型的推广应用。
3. 大模型与小模型将长期共存并相互融合
目前大模型在工业领域还未呈现出对小模型的替代趋势。尽管以生成式 AI 为代表的大模型被视为当前 AI 的热点,但在工业领域的实际应用中,大模型的能力和成本问题导致其尚不能完全取代以判别式 AI 为代表的小模型。
一方面,小模型在工业领域具有深厚的应用基础和经验积累,其算法和模型结构相对简单,易于理解和实现,其稳定性和可靠性得到了验证。
另一方面,大模型在成本收益比、稳定性和可靠性等方面存在问题,其在工业领域的探索还处在初级阶段。小模型以其高效、灵活的特点,在特定场景和资源受限的环境中发挥着重要作用;
而大模型则以其强大的泛化能力和处理复杂任务的优势,在更广泛的领域展现着巨大潜力,两者将长期共存。
大模型与小模型有望融合推动工业智能化发展。对于小模型而言,利用大模型的生成能力可以助力小模型的训练。
小模型训练需要大量的标注数据,但现实工业生产过程可能缺少相关场景的数据,大模型凭借强大的生成能力,可以生成丰富多样的数据、图像等。例如,在质检环节,大模型可以生成各种可能的产品缺陷图片,为小模型提供丰富的训练样本,从而使其能够更准确地识别缺陷和异常。
此外,大模型可以通过 Agent等方式调用小模型,以实现灵活性与效率的结合。例如,在某些场景下,大模型可以负责全局的调度和决策,而小模型可以负责具体的执行和控制。这样既能保证系统的整体性能,又能提高响应速度和灵活性。
参考资料
全球视野 !工业AI大模型案例及发展深度分析 2024
AGI大模型现状及发展路径研究 2024
工业大模型技术应用与发展报告1.0
ChatGLM开源生态项目和大模型微调技术
来源:https://www.cnblogs.com/tgzhu/p/18174432
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。


