对于 AI 技术,大家热聊的话题超 90% 都是围绕大模型,而知识图谱则是上一波 AI 浪潮中比较热门的技术。今天特邀行业专家,探讨关于大模型和知识图谱在工业领域的一些落地实践。主要分为四个部分展开:大模型和知识图谱的关系、大模型+知识图谱双擎的原理、大模型+知识图谱双擎的工业应用场景、大模型+知识图谱双擎在工业领域的成功案例。分享嘉宾|杨成彪 柯基数据 CTO
内容已做精简,如需获取专家完整版视频实录和课件,请扫码领取。

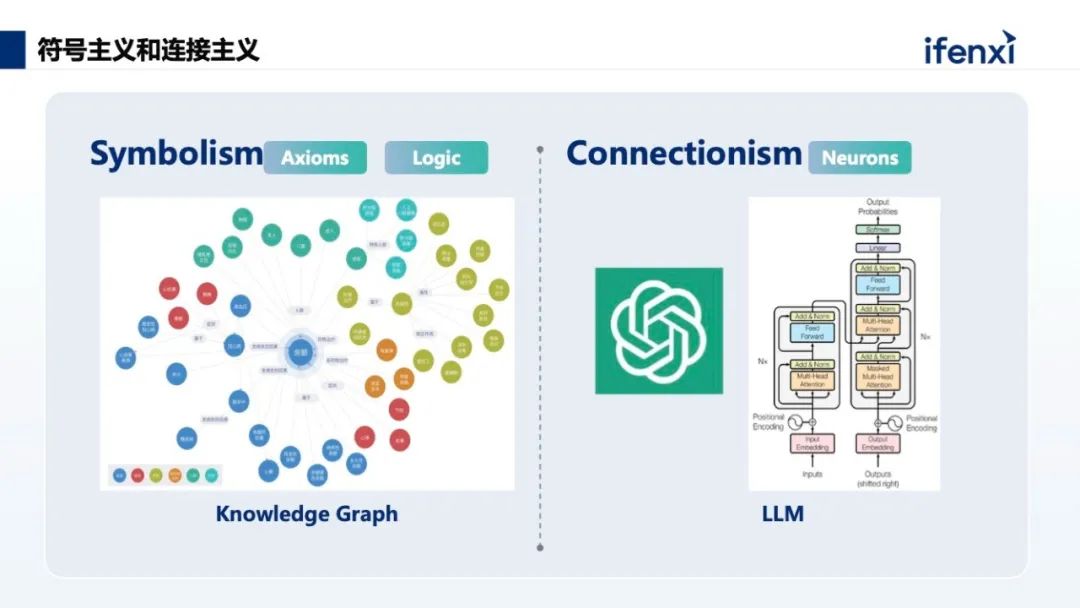
人类有两种主要的思维模式,一种是快速而直觉的,另一种是缓慢而深思熟虑的,这种说法起源于并广泛存在于古老的哲学和心理学著作中。通常用“系统 1 ”和“系统 2 ”来表示以上两种类型的认知过程,诺贝尔奖获得者心理学家丹尼尔·卡尼曼(Daniel Kahneman)在其著作《思考,快与慢》中详细介绍了两种认知系统的区别之处,系统 1 是直觉性、快速、大容量、并行、无意识、情境化和自动化的,其依赖情感、记忆和经验迅速作出判断,是类似于动物认知的内隐知识;系统 2 则是分析性、缓慢、有限容量、串行和抽象的,其受到规则的约束,依赖认知能力的运作,是人类进化后期习得的外显知识。目前深度学习包括大模型都在做系统1的工作,而知识图谱擅长做系统 2 的工作。人工智能的发展有两大经典的流派,一个叫符号主义,一个叫连接主义。知识图谱是经典的符号主义,把知识符号化,通过三元组描述知识和知识之间的关系,再构建成巨大的知识网络,这是知识的显性表达。大模型是连接主义的最新成果,但是它的知识是隐性表达,知识直接存储到模型的神经网络参数中,人不可读。这两种知识表达方式有巨大的差别,也有各自的优势。- 大语言模型的专业领域知识有限,特别是工业领域有大量的数据还未清晰甚至数字化;
- 大语言模型存在幻觉问题,这个问题基本无法通过训练从模型训练上解决;
- 大语言模型的知识运维困难,训练成本高且校验成本高;
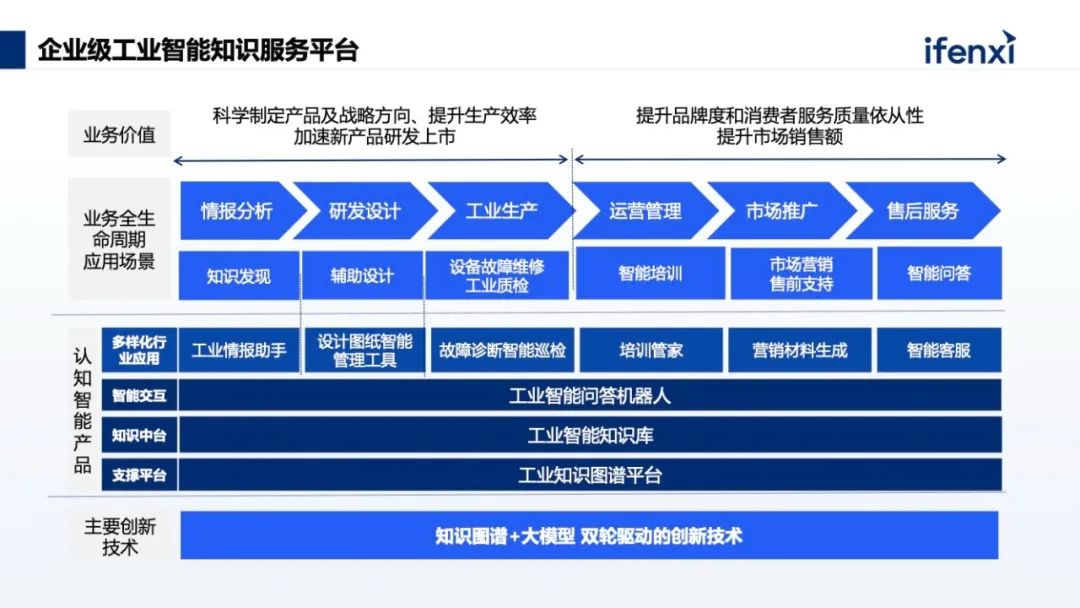
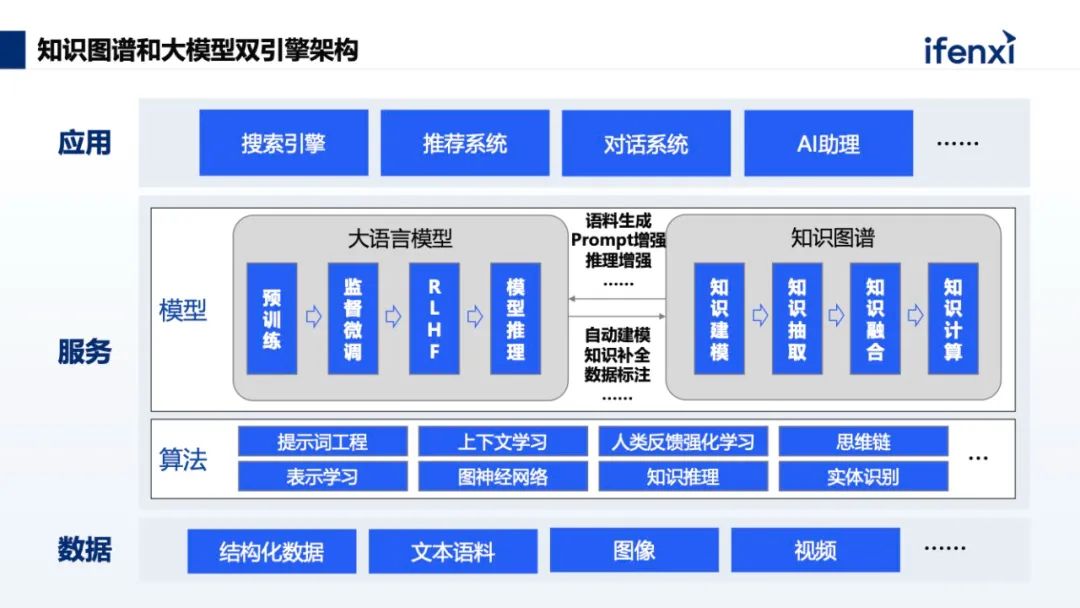
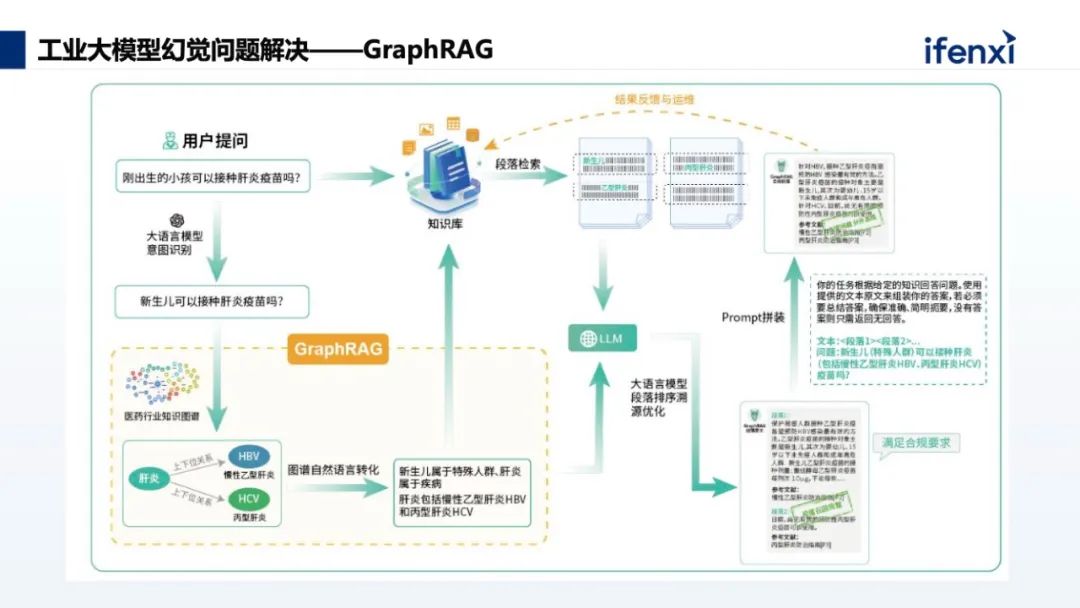
我们的想法是将两者结合起来,用知识图谱解决领域知识缺失、领域知识运维、领域知识推理和大模型幻觉的问题,用大模型解决知识图谱构建成本高的问题,实现大模型和知识图谱双擎互相增强。知识图谱和大模型两个技术的结合,会产生 1 + 1 >2 的效果。基于这样的技术思路,我们提出了企业级的工业智能知识服务平台,核心的两大底层技术就是知识图谱和大模型。上图是整个知识服务平台的技术架构,围绕业务全生命周期,包含情报分析、研发设计、工业生产、运营管理、市场推广、售后服务的业务完整链条,因为底层的技术架构是相通的,知识图谱把各个部门的知识进行统一的关联,所以就能产生 1 + 1 > 2 的效果。这个知识服务平台除了大模型和知识图谱双擎,还有两大核心业务能力。第一个核心是数据集成。可以将多模态的数据集中化的管理,包括文档、视频、图片等等,只要是企业内部能够积累的数据,都可以通过平台采集,再做自动知识抽取,可以大大降低员工的使用门槛。第二个核心是持续学习。底层的知识图谱和大模型之间能够互相的增强,而且是一个持续学习的过程。这里学习包括两个方面,一个是大模型的迭代,另一个是知识图谱的迭代。前者一是基于知识库中数据做模型微调,二是通过用户反馈不断优化提示词;后者主要是基于新增数据的变化,自动更新知识图谱本体,由本体驱动图谱的更新。当前大模型在应用过程中,对于幻觉问题的解决,知识图谱与大模型结合是一个比较有效的解决思路,就是 GraphRAG 。我们知道大模型应用于知识库场景,目前最有价值的就是 RAG ,这种方式能通过知识外挂最有性价比的解决大模型领域知识有限的问题。RAG 的工作流程是,当大模型接收到用户提问后,会先去外挂的知识库里找到相关的文本分片,再把文本分片输入给大语言模型,最后大语言模型再结合文本分片内容回答问题。受限于分文分片的召回方式, RAG 能利用的知识粒度只能是段落级别,这会导致两个问题,一是很难找到一个合适的段落分片策略兼顾准确率和召回率,二是仅能回答基于有限段落原文的简单问题。GraphRAG 可以把文档的知识粒度从段落级别拆成实体级别,其中的关键就是将文档知识构建成知识图谱。用户提问后,先在知识图谱中找到问题相关的实体,通过知识图谱更精准的找到相关的知识内容。对于专业技术要求比较高的领域,GraphRAG 的方式能更好地获取到到更专业的结果,原因就在于知识的颗粒度更细,能够更好地通过用户的问题找到相关的、准确的知识点,再把这些知识点作为提示词,输入到大语言模型中,输出的结果往往就会更精准。我们在 GraphRAG 的实践过程中,相比于常规的 GraphRAG ,我们还加入了用户意图推理和第三方知识图谱利用两部分内容。例如用户提问“刚出生的小孩可以接种肝炎疫苗吗”,这里包含两个重要的语义,一个是“刚出生的小孩”在专业用语中是“新生儿”;另外一个是“肝炎”,肝炎其实是一类疾病的总称,也分很多不同类型的疾病,比如说叫甲肝、乙肝、丙肝等等。通过知识图谱增强,把“刚出生的小孩”变成规范化的描述“新生儿”,把“肝炎”做知识推理得到肝炎包含“慢性乙型肝炎”、“丙型肝炎”等,然后把这些知识合并到一起,实现对用户意图的拓展,然后再用拓展的意图走 GraphRAG 的流程,就能得到一个更好的结果。
大模型+知识图谱的工业应用场景
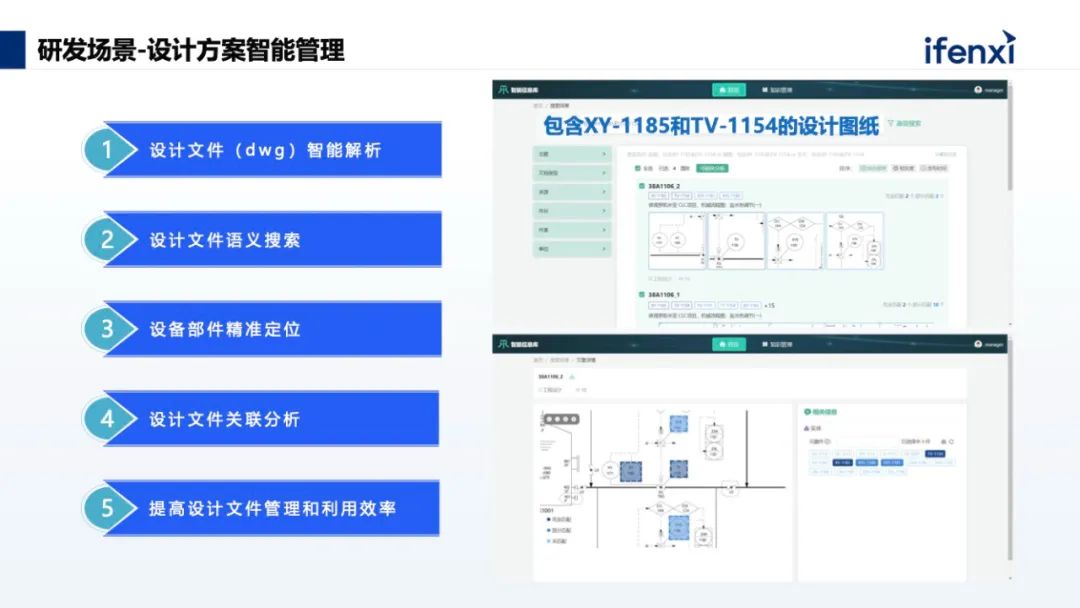
不少工业企业都有非常多的设计文档、设计方案等文档,可能是 CAD 文件,也可能是一些文档等等,尤其是研发型的单位,内部可能有几万份、几十万份甚至上百万份的图纸内容。常规的检索只能通过文件名、文件简介等进行全文检索,如果需要深入到 CAD 文件的内容中查找,例如查找“同时包含某两个零部件的设计方案”就非常困难。我们通过知识图谱加上大语言模型的方式,可以很好地解决这一问题,提前把 CAD 文件中的关键部件构建成知识图谱,这样在搜索包含某个部件的设计图纸,就可以直接对图纸内容进行定位,非常高效。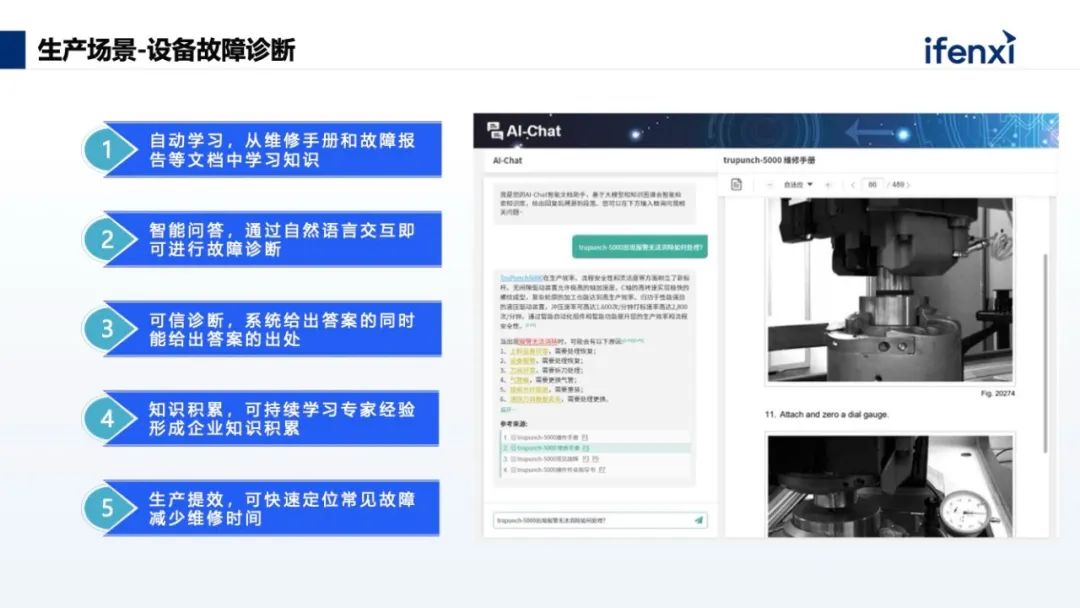
工业型企业中,产线的任何一个故障,对生产的影响是非常大的,哪怕能缩短一点故障诊断的时间,对企业的帮助也是非常大。所以可以结合产品的运维手册,以及前期积累的故障报告等,把这些作为知识库,当出现新的故障时,通过大模型的交互,逐渐把故障现象和故障原因结合起来,然后推荐相关的故障解决思路,可以帮助运检人员更快地对故障进行排除。这是在工业场景中,非常典型的一类大模型与知识图谱结合的应用。
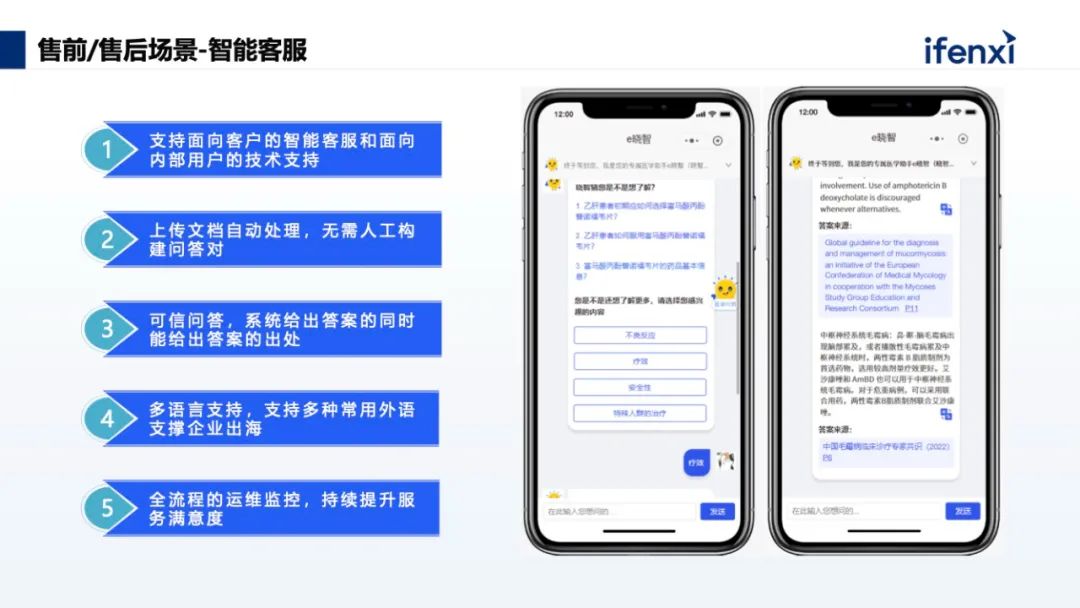
对于做非标产品的企业,产品的组合类型往往非常办法,销售往往无法全部了解。当销售接到客户的需求单,需要判断是否能做,以及用哪些产品能匹配,有时需求单会很长,可能几页纸,甚至十几页纸,经验稍浅的销售对需求的把握不是特别准确,那么就可以通过 AI 技术对销售订单的每个功能项、需求项做具体的分析,匹配需求与产品,同时对兼容性、库存等风险因素做出预警。智能客服主要是售前和售后场景。售前实现智能导购,售后实现设备使用的回答,或者是故障的简单排除等等,这些都是比较典型的应用场景。特别是有出海业务的企业,涉及到多语言的处理能力,企业不可能在搭建售后团队时,每个小语种都招一个人,通过大语言模型,企业只需要维护一套标准知识库,大语言模型可以自动地理解各语种的问题,再基于标准的中文手册,自动以对应语种来进行回复,不仅可以提高效率,同时可以极大地降低成本。
04
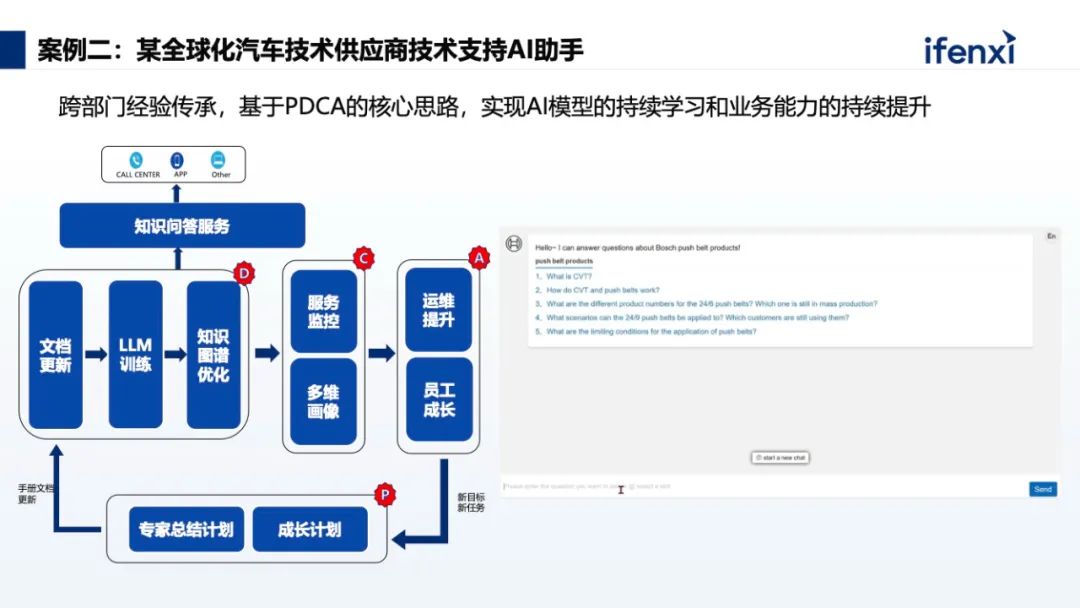
第一个案例是技术售前场景实践。
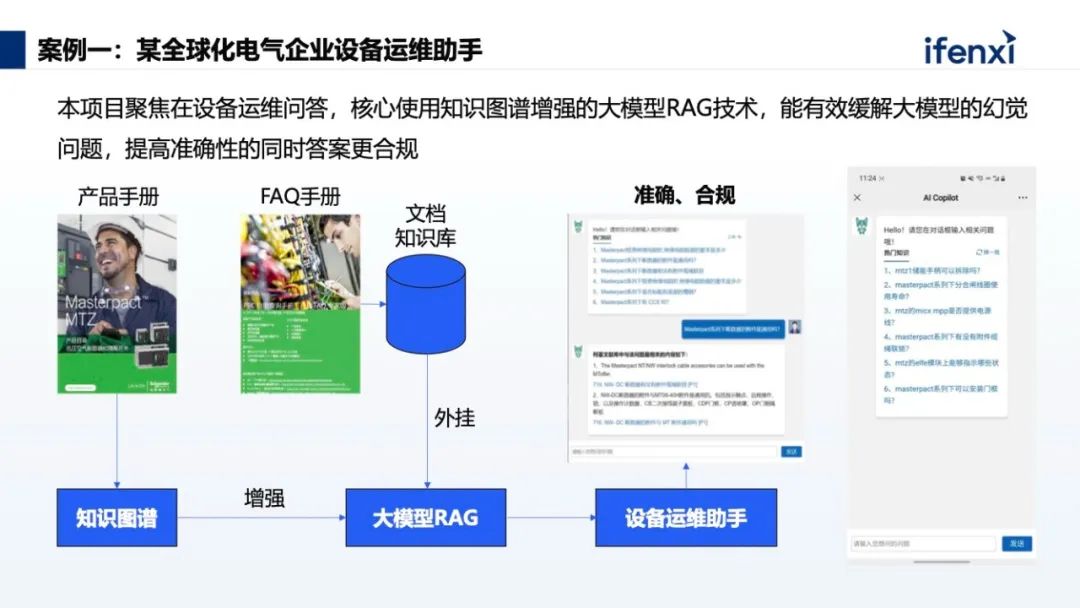
基于产品手册构建知识图谱,再把各类手册录入到知识库中进行外挂,最终实现设备运维助手的构建。可以看到这里有很多问题,如果只是用常规大模型 RAG 形式进行回答,很难回答得很全面,核心原因在于没有对用户问题中蕴含的领域知识进行推理。例如用户提问某系列产品断路器的附件能否通用,如果不通过知识推理知道某系列产品包含的所有产品型号,那模型回答的答案通常是不准确或者不全面的,所以优先通过知识图谱进行推理是非常重要的环节。 知识库的一个大核心的价值点就是实现企业经验或者知识的积累。案例中的企业要去做跨部门的经验传承,海外部门在零部件生产和设计上有非常多的经验,但现在随着业务转移,海外工厂业务迁到国内工厂,那么相关的经验就需要由海外的老师傅传递到新的工人身上。结合 Agent 技术,可以完成只有人类专家才能掌握的复杂问题解决。我们用了“PDCA”的核心思路,PDCA 对于工业企业来说用得非常多,所以在知识库建设时,同样可以用这套指导思路来进行建设。最后再给大家展示一个虚拟技术专家的视频,主要针对产品推荐、数据分析、产品选型三类问题。⩓
东南大学博士,主要研究方向是知识图谱和自然语言处理。发表高水平论文十余篇,同时获得知识图谱和大模型相关发明专利十余项。曾担任网易杭研NLP负责人、摄星智能技术总监,成功研发多款现象级AI产品,荣获了“江苏省优秀人工智能产品金奖”、“十佳优秀人工智能软件产品”等奖项。研发的知识图谱增强大模型产品目前成功落地二十余家世界500强企业。注:点击左下角“阅读原文”,领取专家完整版实录和分享课件。