


----追光逐电 光赢未来----
光学系统以极高速率和效率,执行线性矩阵运算,激发了低延迟矩阵加速器和光电图像分类器的最新实验演示。然而,证明深度神经网络的相干、超低延迟光学处理,仍然是主要挑战之一。
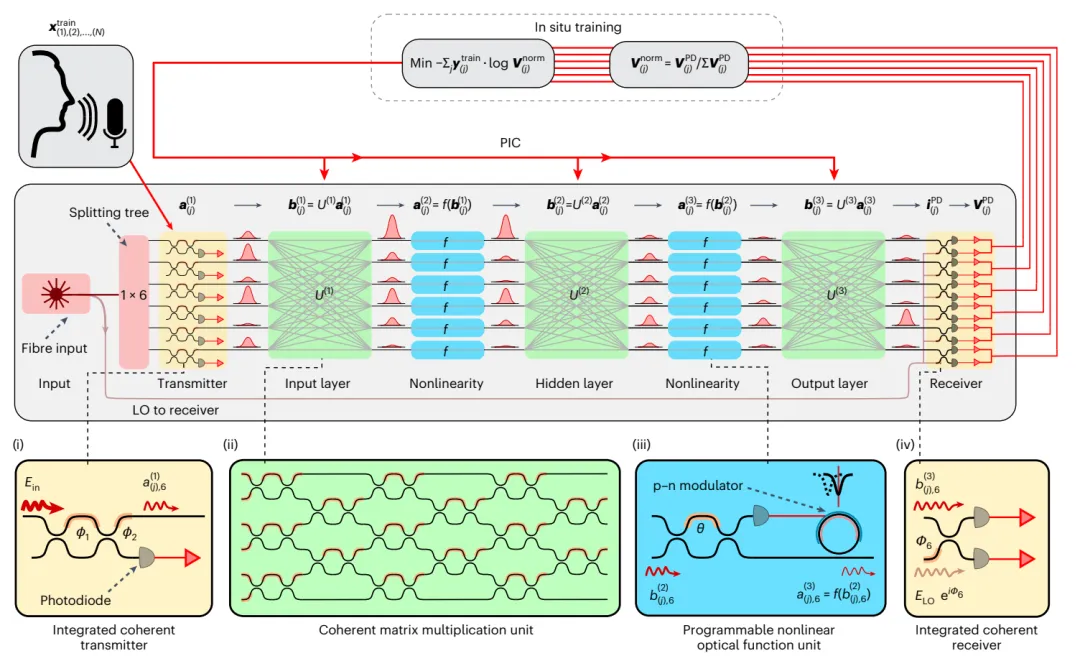
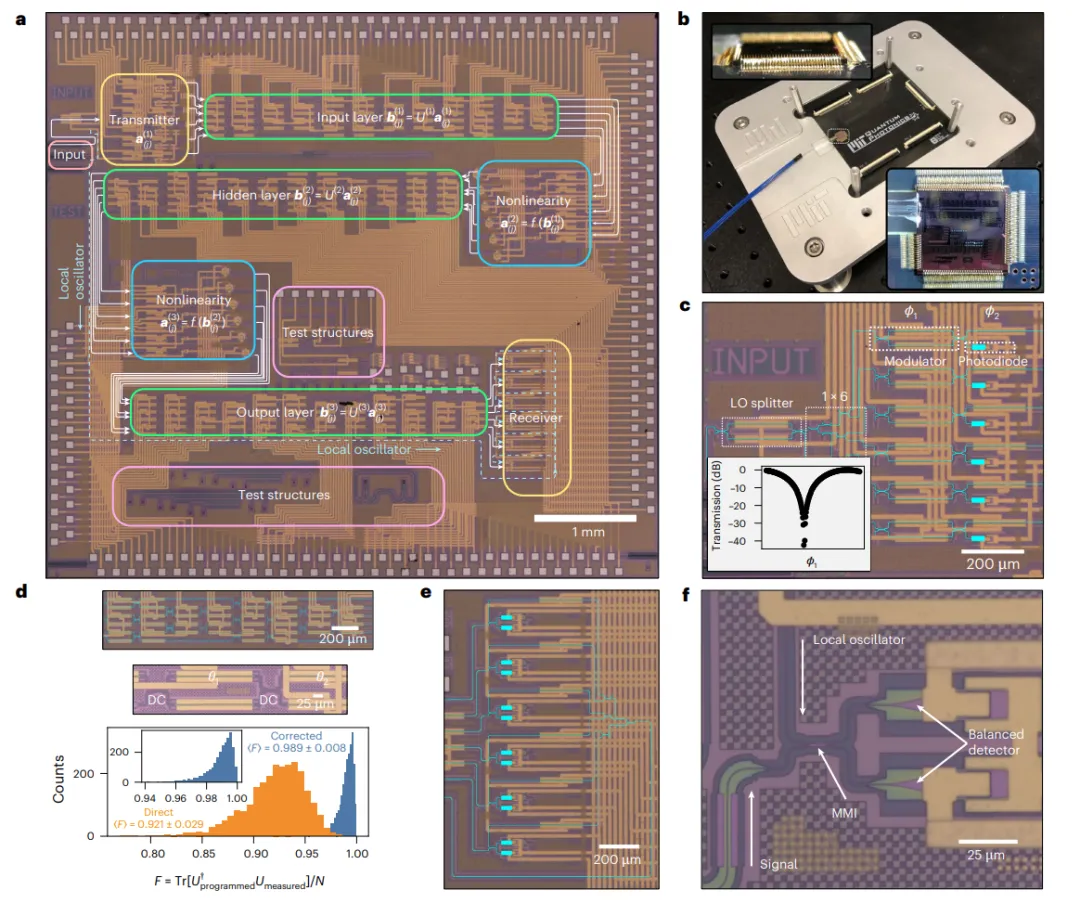
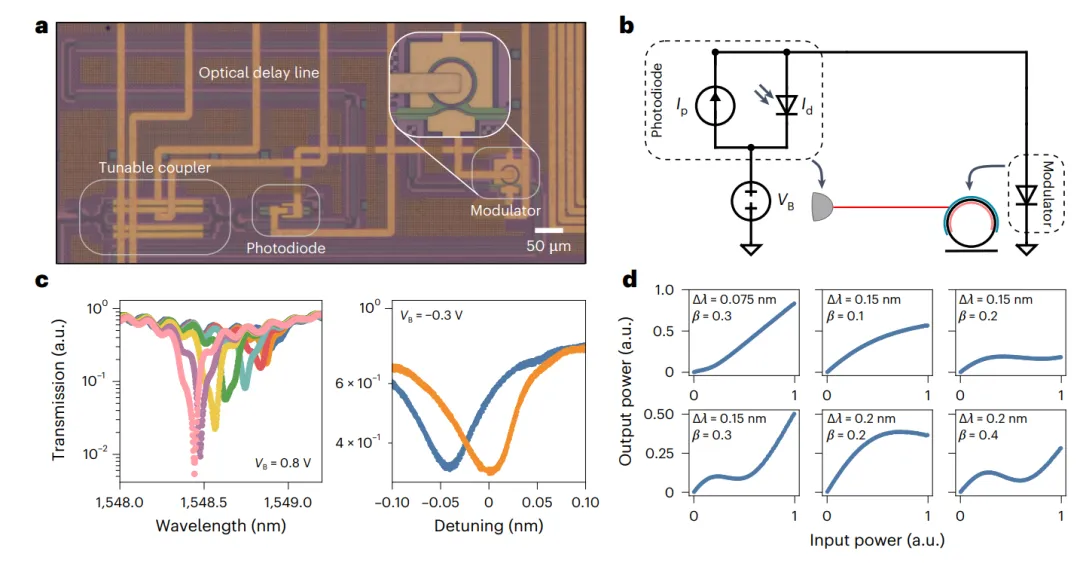
今日,美国 麻省理工学院(Massachusetts Institute of Technology,MIT)Saumil Bandyopadhyay,Dirk Englund等,在Nature Photonics上发文,在可扩展光子集成电路中,实现了这样的光学系统,将用于矩阵代数和非线性激活函数的多个相干光学处理器单元,单片集成到单个芯片中。
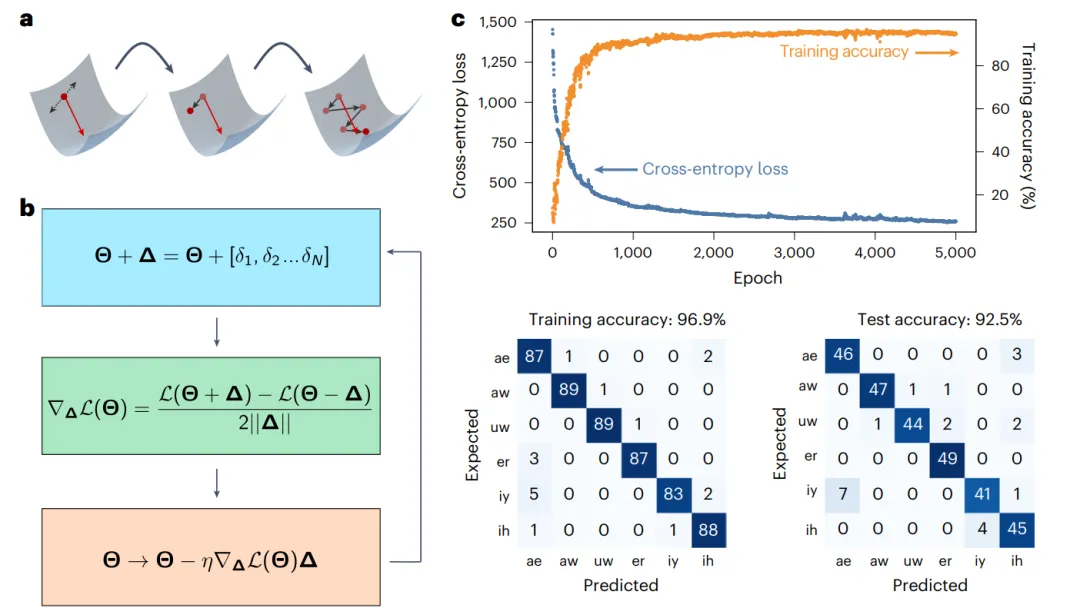
实验表明,这种完全集成的相干光学神经网络架构,适用于具有六个神经元和三层的深度神经网络,可光学计算线性和非线性函数,延迟为410ps,从而开启了超快、直接处理光学信号的新应用。在这种系统上,实现了无反向传播的原位训练,在六类元音分类任务上,达到了92.5%准确率,这相当于在数字计算机上获得的准确率。
这项工作,为原位训练的理论建议,提供了实验证据,使训练数据的吞吐量提高了几个数量级。完全集成的相干光学神经网络,实现了以纳秒延迟和每操作毫微微焦耳能量效率进行推理。

具有前向训练的单芯片光子深度神经网络。
文献链接
Bandyopadhyay, S., Sludds, A., Krastanov, S. et al. Single-chip photonic deep neural network with forward-only training. Nat. Photon. 18, 1335–1343 (2024).
https://doi.org/10.1038/s41566-024-01567-z
https://www.nature.com/articles/s41566-024-01567-z
本文译自Nature。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。

----与智者为伍 为创新赋能----

联系邮箱:uestcwxd@126.com
QQ:493826566


